







BLIP 和 BLIP2 的模型结构与训练方式对比
BLIP 和 BLIP2 是两种用于视觉语言任务的预训练模型,它们在模型结构和训练方式上有显著的区别和联系。以下是对两者的详细对比分析:
1. 模型结构对比
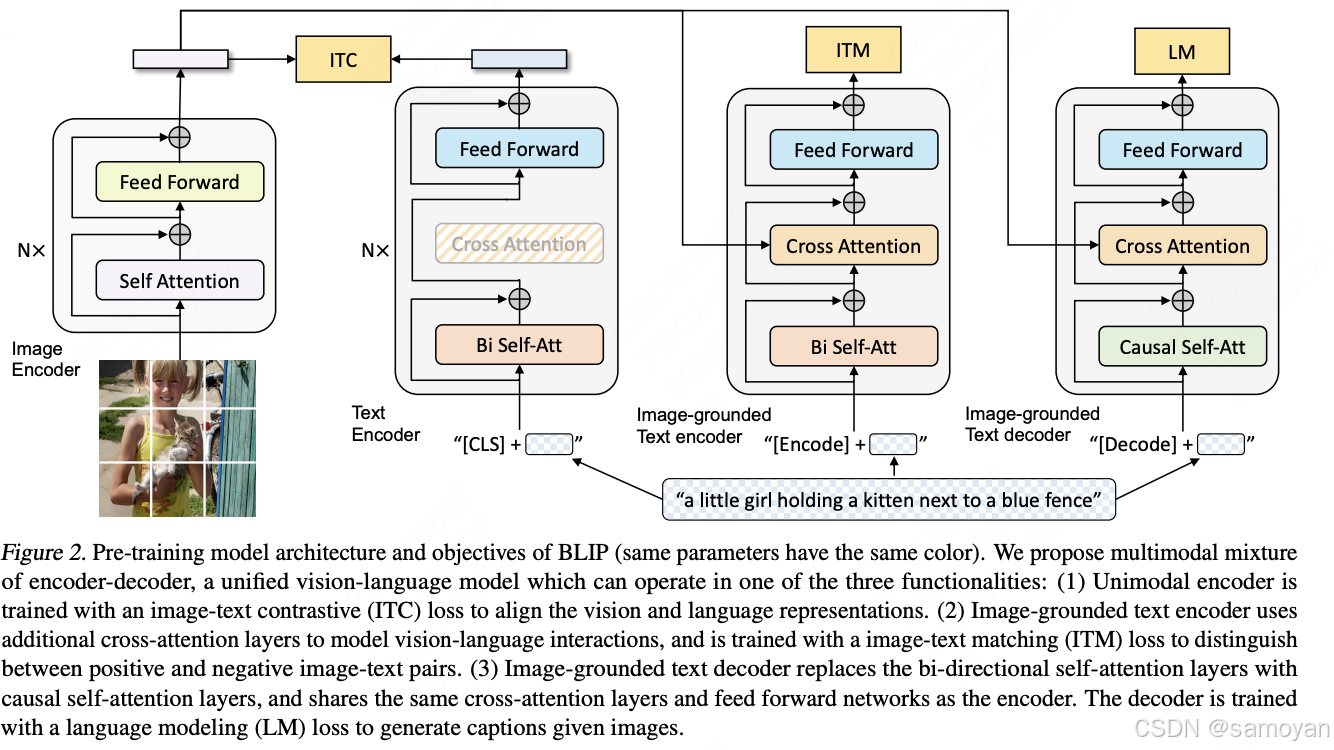
BLIP 的模型结构
- 核心架构:多模态编码器-解码器混合(MED),包含以下三个功能模块:
- 单模态编码器:分别编码图像和文本,通过图像-文本对比损失(ITC)对齐视觉和语言表示。
- 基于图像的文本编码器:在文本编码器中插入交叉注意力层,通过图像-文本匹配损失(ITM)学习图像和文本的细粒度对齐。
- 基于图像的文本解码器:将双向自注意力层替换为因果自注意力层,通过语言建模损失(LM)生成文本描述。
- 特点:
- 统一的视觉语言模型,支持多种任务(理解与生成)。
- 通过共享参数实现多任务学习。
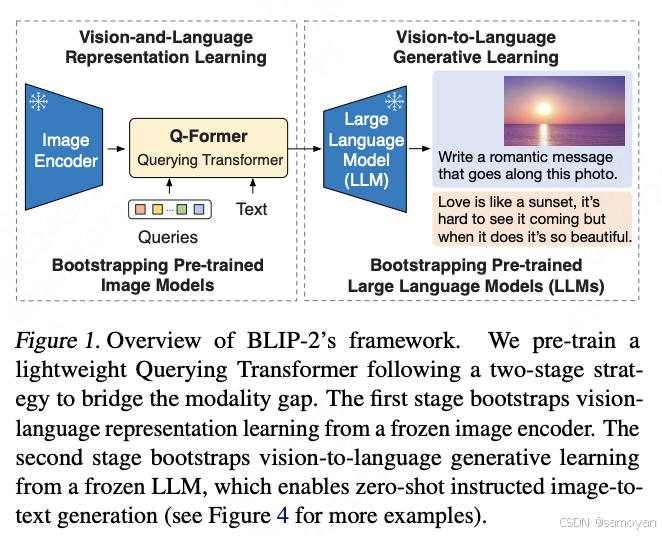
BLIP2 的模型结构
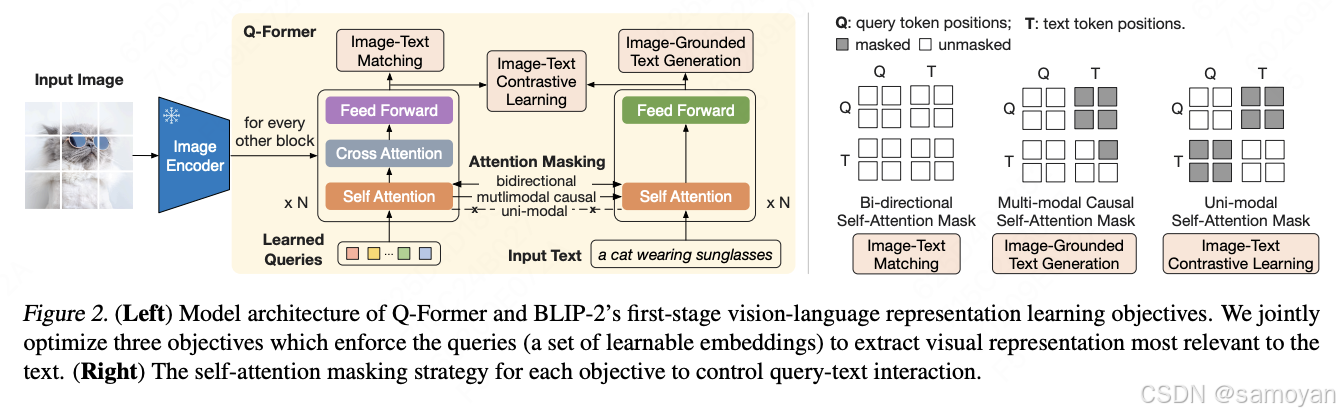
- 核心架构:引入 Querying Transformer (Q-Former) 作为桥接模块,连接冻结的图像编码器和冻结的大语言模型(LLM)。
- Q-Former:包含两个Transformer子模块:
- 图像Transformer:与冻结的图像编码器交互,提取视觉特征。
- 文本Transformer:作为文本编码器和解码器,支持文本生成和理解。
- 冻结的图像编码器:如 ViT-L/14 或 ViT-g/14,用于提取图像特征。
- 冻结的LLM:如 OPT 或 FlanT5,用于生成语言。
- Q-Former:包含两个Transformer子模块:
- 特点:
- 模块化设计,将视觉编码器和语言模型解耦。
- Q-Former 作为信息过滤层,提取与文本最相关的视觉信息。
- 支持多种LLM(基于解码器和基于编码器-解码器)。
模型结构异同
| 特性 | BLIP | BLIP2 |
|---|---|---|
| 核心模块 | 多模态编码器-解码器混合(MED) | Querying Transformer (Q-Former) |
| 图像编码器 | 可训练的视觉Transformer | 冻结的视觉Transformer |
| 语言模型 | 无独立语言模型,文本编码器/解码器 | 冻结的大语言模型(LLM) |
| 模态桥接 | 交叉注意力层 | Q-Former 作为桥接模块 |
| 参数共享 | 编码器和解码器共享部分参数 | Q-Former 和 LLM 参数独立 |
| 任务支持 | 理解与生成 | 理解与生成,支持更大规模LLM |
2. 训练方式对比
BLIP 的训练方式
- 预训练目标:
- 图像-文本对比损失(ITC):对齐视觉和语言表示。
- 图像-文本匹配损失(ITM):学习图像和文本的细粒度对齐。
- 语言建模损失(LM):生成文本描述。
- 数据集:使用大规模图像-文本对(如 COCO、Visual Genome、CC3M 等)。
- 特点:
- 端到端训练,图像编码器和文本编码器/解码器同时优化。
- 通过多任务学习提升模型性能。
BLIP2 的训练方式
- 预训练目标:
- 第一阶段:视觉语言表示学习,使用冻结的图像编码器,优化 Q-Former。
- 图像-文本对比损失(ITC):对齐视觉和语言表示。
- 图像-文本匹配损失(ITM):学习图像和文本的细粒度对齐。
- 基于图像的文本生成损失(ITG):生成文本描述。
- 第二阶段:视觉到语言的生成学习,使用冻结的LLM,优化 Q-Former。
- 语言建模损失(LM):生成文本描述。
- 前缀语言建模损失(Prefix LM):支持基于编码器-解码器的LLM。
- 第一阶段:视觉语言表示学习,使用冻结的图像编码器,优化 Q-Former。
- 数据集:与 BLIP 相同的大规模图像-文本对。
- 特点:
- 两阶段训练,先优化 Q-Former,再连接 LLM。
- 冻结的图像编码器和 LLM,减少计算负担。
- 通过 Q-Former 过滤信息,提升生成质量。
训练方式异同
| 特性 | BLIP | BLIP2 |
|---|---|---|
| 训练阶段 | 单阶段端到端训练 | 两阶段训练(表示学习 + 生成学习) |
| 图像编码器 | 可训练 | 冻结 |
| 语言模型 | 无独立语言模型 | 冻结的LLM |
| 信息过滤 | 无独立信息过滤模块 | Q-Former 作为信息过滤层 |
| 计算效率 | 计算负担较高 | 计算负担较低,冻结模型 |
| 任务支持 | 理解与生成 | 理解与生成,支持更大规模LLM |
总结
模型结构
- BLIP:采用统一的多模态编码器-解码器混合(MED)架构,支持多种视觉语言任务。
- BLIP2:引入 Q-Former 作为桥接模块,连接冻结的图像编码器和 LLM,模块化设计更灵活。
训练方式
- BLIP:单阶段端到端训练,图像编码器和文本编码器/解码器同时优化。
- BLIP2:两阶段训练,先优化 Q-Former,再连接 LLM,冻结模型减少计算负担。
BLIP2 在 BLIP 的基础上进行了显著改进,通过模块化设计和两阶段训练,提升了模型的灵活性和效率,同时支持更大规模的语言模型。
BLIP 和 BLIP2 的数据处理对比
BLIP 和 BLIP2 在数据处理方面有一些共同点,但也存在显著差异。以下是两者在数据处理上的详细对比分析:
1. 数据处理共同点
(1) 数据集来源
- BLIP 和 BLIP2 都使用了大规模图像-文本对数据集,包括:
- 人工标注数据集:如 COCO(Lin等,2014)、Visual Genome(Krishna等,2017)。
- 网络数据集:如 Conceptual Captions(CC3M、CC12M)、SBU captions(Ordonez等,2011)、LAION400M(Schuhmann等,2021)。
- 数据规模:BLIP 和 BLIP2 都使用了数百万到数亿规模的图像-文本对。
(2) 数据增强
- 图像增强:两者都使用了随机裁剪、水平翻转等图像增强技术。
- 文本处理:文本数据通常经过标准化处理(如分词、去除特殊字符等)。
(3) 数据噪声处理
- BLIP 和 BLIP2 都面临网络数据中的噪声问题(如不准确的替代文本),并通过特定方法进行过滤或修正。
2. 数据处理差异
(1) 数据过滤方法
- BLIP:
- 使用 CapFilt 方法过滤噪声数据:
- Captioner:生成合成标题。
- Filter:通过图像-文本匹配(ITM)损失过滤噪声文本。
- 最终将过滤后的图像-文本对与人工标注数据结合,形成高质量的训练数据集。
- 使用 CapFilt 方法过滤噪声数据:
- BLIP2:
- 继承了 BLIP 的 CapFilt 方法,但进一步优化了过滤策略。
- 在更大规模的数据集(如 LAION400M)上应用 CapFilt,以提升数据质量。
(2) 数据规模与多样性
- BLIP:
- 主要使用中等规模的数据集(如 14M 图像-文本对)。
- 数据集包括 COCO、Visual Genome、CC3M、CC12M、SBU 等。
- BLIP2:
- 使用更大规模的数据集(如 129M 图像-文本对)。
- 增加了 LAION400M 数据集,进一步扩展了数据规模和多样性。
(3) 数据预处理
- BLIP:
- 图像分辨率在预训练阶段为 224×224,在微调阶段提升到 384×384。
- 文本处理使用 BERT 的分词器。
- BLIP2:
- 图像分辨率与 BLIP 相同(224×224 预训练,384×384 微调)。
- 文本处理根据使用的 LLM(如 OPT 或 FlanT5)选择相应的分词器。
(4) 数据与模型匹配
- BLIP:
- 数据直接用于训练 MED 模型,图像编码器和文本编码器/解码器同时优化。
- BLIP2:
- 数据用于训练 Q-Former,同时与冻结的图像编码器和 LLM 结合。
- 在第二阶段,数据用于优化 Q-Former 和 LLM 的交互。
3. 数据处理异同总结
| 特性 | BLIP | BLIP2 |
|---|---|---|
| 数据集来源 | COCO、Visual Genome、CC3M、CC12M、SBU | 增加 LAION400M,数据规模更大 |
| 数据规模 | 中等规模(如 14M) | 更大规模(如 129M) |
| 数据过滤方法 | CapFilt(Captioner + Filter) | 继承并优化 CapFilt |
| 图像分辨率 | 224×224(预训练),384×384(微调) | 与 BLIP 相同 |
| 文本处理 | BERT 分词器 | 根据 LLM 选择分词器(如 OPT、FlanT5) |
| 数据与模型匹配 | 直接用于训练 MED 模型 | 用于训练 Q-Former 和 LLM 交互 |
总结
BLIP 和 BLIP2 在数据处理上有许多共同点,如使用大规模图像-文本对数据集、数据增强和噪声过滤。然而,BLIP2 在以下方面进行了改进:
- 数据规模:使用更大规模的数据集(如 LAION400M),扩展了数据多样性。
- 数据过滤:优化了 CapFilt 方法,进一步提升数据质量。
- 文本处理:根据使用的 LLM 选择相应的分词器,增强模型与数据的匹配性。


















 3411
3411

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











