







非常好的一篇文章,链接:http://www.cppblog.com/sunrise/archive/2012/08/06/186474.html
总结
1)svm分为两大类,线性分类和非线性分类。
2)线性分类:示例函数y=wx+a,注意这里的w指的是向量不是横坐标的点,如(3,8)T,一般都是指列向量,假设依据y值为1与-1进行分类,(-1表示否),则H=wx+b=0,

首先,我们要知道误差数次k<=R^2/w,R 表示的是某样本点到H的最长距离,h指的是分类的线(超平面),对y函数做归一化,则系数为1/w,等价为1/w^2,
max 1/w^2 等价于 求min w^2,
间隔:δ=y(wx+b)=|g(x)|
几何间隔:![]()
可以看出δ=||w||δ几何。注意到几何间隔与||w||是成反比的,因此最大化几何间隔与最小化||w||完全是一回事。而我们常用的方法并不是固定||w||的大小而寻求最大几何间隔,而是固定间隔(例如固定为1),寻找最小的||w||。
而凡是求一个函数的最小值(或最大值)的问题都可以称为寻优问题(也叫作一个规划问题),又由于找最大值的问题总可以通过加一个负号变为找最小值的问题,因此我们下面讨论的时候都针对找最小值的过程来进行。一个寻优问题最重要的部分是目标函数,顾名思义,就是指寻优的目标。例如我们想寻找最小的||w||这件事,就可以用下面的式子表示:
![]()
但实际上对于这个目标,我们常常使用另一个完全等价的目标函数来代替,那就是:
![]() (式1)
(式1)
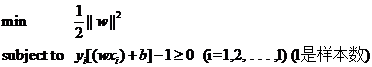
3)非线性,对于非线性的分类,我们应该使用kernel函数,不满足线性分类的data_set变为线性可分的,
这里涉及到低维data到高维data的映射,映射的效果是由选定的kernel决定的,所以建议大家多了解一下常用的一些kernel,比较常用而且效果较好的是径向基核函数。
4)关于松弛向量,我们发现数据集中往往会出现噪声,这些噪声可能将线性可分的data_set变为了,线性不可分,而导致无限的求解,我们应该设置后松弛向量,规避噪声的影响
5)说到松弛向量我们也要提提惩罚因子,对于惩罚因子,我们可以简单的把它当做是SVM对data的一个权重,在处理松弛向量的时候,我们可以将比较重要的样本加大C值,以保障,在取舍的时候,数据的model能够向它倾斜。
6)非线性可分的数据集问题,请注意低维到高维的作用,kernel的转换使得低维不可分变成了高维线性可分,如一下的例子:
二维空间向四维空间的转换:
例子是下面这张图:

我们把横轴上端点a和b之间红色部分里的所有点定为正类,两边的黑色部分里的点定为负类。试问能找到一个线性函数把两类正确分开么?不能,因为二维空间里的线性函数就是指直线,显然找不到符合条件的直线。
但我们可以找到一条曲线,例如下面这一条:

显然通过点在这条曲线的上方还是下方就可以判断点所属的类别(你在横轴上随便找一点,算算这一点的函数值,会发现负类的点函数值一定比0大,而正类的一定比0小)。这条曲线就是我们熟知的二次曲线,它的函数表达式可以写为:
问题只是它不是一个线性函数,但是,下面要注意看了,新建一个向量y和a:
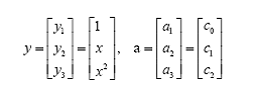
这样g(x)就可以转化为f(y)=<a,y>,你可以把y和a分别回带一下,看看等不等于原来的g(x)。用内积的形式写你可能看不太清楚,实际上f(y)的形式就是:
g(x)=f(y)=ay 这里的y是三维变量,再加上一位变量g(x),则该函数代表的是四维变量,这就说明,以上的线段可以通过从二维向四维空间的转换而使得该非线性不可分的问题转成了四维空间中线性可分的问题。
在任意维度的空间中,这种形式的函数都是一个线性函数(只不过其中的a和y都是多维向量罢了),因为自变量y的次数不大于1。
看出妙在哪了么?原来在二维空间中一个线性不可分的问题,映射到四维空间后,变成了线性可分的!因此这也形成了我们最初想解决线性不可分问题的基本思路——向高维空间转化,使其变得线性可分。
而转化最关键的部分就在于找到x到y的映射方法。遗憾的是,如何找到这个映射,没有系统性的方法(也就是说,纯靠猜和凑)。具体到我们的文本分类问题,文本被表示为上千维的向量,即使维数已经如此之高,也常常是线性不可分的,还要向更高的空间转化。其中的难度可想而知。
小Tips:为什么说f(y)=ay是四维空间里的函数?
大家可能一时没看明白。回想一下我们二维空间里的函数定义
g(x)=ax+b
变量x是一维的,为什么说它是二维空间里的函数呢?因为还有一个变量我们没写出来,它的完整形式其实是
y=g(x)=ax+b
即
y=ax+b
可以这样理解:变量x,y分别代表各自的维
python代码实现:
import numpy as np import numpy.random as npr | |
| import pylab | |
| from cvxopt import solvers, matrix | |
| from utils import plot_line # gist: https://gist.github.com/2778598 | |
| def svm_slack(pts, labels, c = 1.0): | |
| """ | |
| Support Vector Machine using CVXOPT in Python. SVM with slack. | |
| """ | |
| n = len(pts[0]) | |
| m = len(pts) | |
| nvars = n + m + 1 | |
| # x is a column vector [w b]^T | |
| # set up P | |
| P = matrix(0.0, (nvars, nvars)) | |
| for i in range(n): | |
| P[i,i] = 1.0 | |
| # q^t x | |
| # set up q | |
| q = matrix(0.0,(nvars,1)) | |
| for i in range(n,n+m): | |
| q[i] = c | |
| q[-1] = 1.0 | |
| # set up h | |
| h = matrix(-1.0,(m+m,1)) | |
| h[m:] = 0.0 | |
| # set up G | |
| print m | |
| G = matrix(0.0, (m+m,nvars)) | |
| for i in range(m): | |
| G[i,:n] = -labels[i] * pts[i] | |
| G[i,n+i] = -1 | |
| G[i,-1] = -labels[i] | |
| for i in range(m,m+m): | |
| G[i,n+i-m] = -1.0 | |
| x = solvers.qp(P,q,G,h)['x'] | |
| return P, q, h, G, x | |
| def svm(pts, labels): | |
| """ | |
| Support Vector Machine using CVXOPT in Python. This example is | |
| mean to illustrate how SVMs work. | |
| """ | |
| n = len(pts[0]) | |
| # x is a column vector [w b]^T | |
| # set up P | |
| P = matrix(0.0, (n+1,n+1)) | |
| for i in range(n): | |
| P[i,i] = 1.0 | |
| # q^t x | |
| # set up q | |
| q = matrix(0.0,(n+1,1)) | |
| q[-1] = 1.0 | |
| m = len(pts) | |
| # set up h | |
| h = matrix(-1.0,(m,1)) | |
| # set up G | |
| G = matrix(0.0, (m,n+1)) | |
| for i in range(m): | |
| G[i,:n] = -labels[i] * pts[i] | |
| G[i,n] = -labels[i] | |
| x = solvers.qp(P,q,G,h)['x'] | |
| return P, q, h, G, x | |
| if __name__ == '__main__': | |
| def create_overlapping_classification_problem(n=100): | |
| import gmm | |
| n1 = gmm.Normal(2, mu = [0,0], sigma = [[1,0],[0,1]]) | |
| n2 = gmm.Normal(2, mu = [0,3], sigma = [[1,0],[0,1]]) | |
| class1 = n1.simulate(n/2) | |
| class2 = n2.simulate(n/2) | |
| samples = np.vstack([class1,class2]) | |
| labels = np.zeros(n) | |
| labels[:n/2] = -1 | |
| labels[n/2:] = 1 | |
| return samples, labels | |
| def create_classification_problem(n=100): | |
| class1 = npr.rand(n/2,2) | |
| class2 = npr.rand(n/2,2) + np.array([1.3,0.0]) | |
| theta = np.pi / 8.0 | |
| r = np.cos(theta) | |
| s = np.sin(theta) | |
| rotation = np.array([[r,s],[s,-r]]) | |
| samples = np.dot(np.vstack([class1,class2]), rotation) | |
| labels = np.zeros(n) | |
| labels[:n/2] = -1 | |
| labels[n/2:] = 1 | |
| return samples, labels | |
| if True: | |
| samples, labels = create_overlapping_classification_problem() | |
| c = ['red'] * 50 + ['blue'] * 50 | |
| pylab.scatter(samples[:,0], samples[:,1], color = c) | |
| #import pdb | |
| #pdb.set_trace() | |
| P,q,h,G,x = svm_slack(samples, labels, c = 2.0) | |
| #print P, q, h, G | |
| line_params = list(x[:2]) + [x[-1]] | |
| xlim = pylab.gca().get_xlim() | |
| ylim = pylab.gca().get_ylim() | |
| print xlim,ylim | |
| plot_line(line_params, xlim, ylim) | |
| print line_params | |
| pylab.show() | |
| if False: | |
| samples,labels = create_classification_problem() | |
| P,q,h,G,x = svm(samples, labels) | |
| print x | |
| if False: | |
| c = ['red'] * 50 + ['blue'] * 50 | |
| pylab.scatter(samples[:,0], samples[:,1], color = c) | |
| xlim = pylab.gca().get_xlim() | |
| ylim = pylab.gca().get_ylim() | |
| print xlim,ylim | |
| plot_line(x, xlim, ylim) | |
| pylab.show() | |















 494
494











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}