







svm分类:
- 硬间隔 svm(hard margin)
- 软间隔 svm(soft margin)
- 核间隔 svm(kernal margin)
特点:
SVM 有三宝:间隔,对偶,核技巧
SVM分类思想:找到一个超平面,使得该超平面能够正确分割样本,并满足最大化margin分类器,也叫最大化间隔分类器
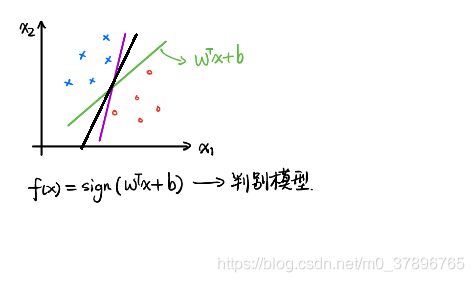
数学描述:
y
=
s
i
g
n
(
w
T
x
+
b
)
,
当
w
T
x
+
b
>
0
时
,
y
=
1
,
w
T
x
+
b
<
0
时
,
y
=
−
1
y=sign(w^Tx+b),当w^Tx+b > 0时,y=1,w^Tx+b < 0时,y=-1
y=sign(wTx+b),当wTx+b>0时,y=1,wTx+b<0时,y=−1
所以原函数可以描述为如下不等式
y
(
w
T
x
+
b
)
>
0
y(w^Tx+b)>0
y(wTx+b)>0
间距函数用distance(x)表示,我们知道点到直线距离公式:
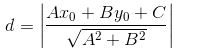
这里点到超平面
w
T
x
+
b
w^Tx+b
wTx+b的距离为:
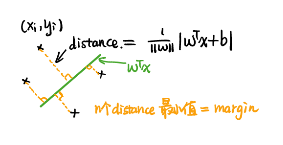
margin分类器定义:点到超平面的最小距离
margin分类器数学描述:
m
i
n
d
i
s
t
a
n
c
e
(
x
i
)
=
m
i
n
(
1
∣
∣
w
∣
∣
∣
w
T
x
i
+
b
∣
)
min \ distance(x_i)=min( \frac{1}{||w||}|w^Tx_i+b|)
min distance(xi)=min(∣∣w∣∣1∣wTxi+b∣)
最大化margin分类器可以描述为:
m
a
x
min
d
i
s
t
a
n
c
e
(
x
i
)
=
m
a
x
min
(
1
∣
∣
w
∣
∣
∣
w
T
x
i
+
b
∣
)
max \min \ distance(x_i)=max \min( \frac{1}{||w||}|w^Tx_i+b|)
maxmin distance(xi)=maxmin(∣∣w∣∣1∣wTxi+b∣)
=
m
a
x
1
∣
∣
w
∣
∣
min
(
∣
w
T
x
i
+
b
∣
)
=max \frac{1}{||w||} \min(|w^Tx_i+b|)
=max∣∣w∣∣1min(∣wTxi+b∣)
由于
∣
w
T
x
i
+
b
∣
|w^Tx_i+b|
∣wTxi+b∣是绝对值函数,这里可以用
y
i
(
w
T
x
i
+
b
)
y_i(w^Tx_i+b)
yi(wTxi+b)代替
所以原问题可以描述为下列优化问题:
m
a
x
1
∣
∣
w
∣
∣
m
i
n
y
i
(
w
T
x
i
+
b
)
max \frac{1}{||w||} \ min \ y_i(w^Tx_i+b)
max∣∣w∣∣1 min yi(wTxi+b)
s
.
t
.
y
i
(
w
T
x
i
+
b
)
>
0
s.t. \quad y_i(w^Tx_i+b)>0
s.t.yi(wTxi+b)>0
令
m
i
n
y
i
(
w
T
x
i
+
b
)
=
1
min \ y_i(w^Tx_i+b)=1
min yi(wTxi+b)=1
m
a
x
1
∣
∣
w
∣
∣
等
价
于
:
max \frac{1}{||w||} 等价于 :
max∣∣w∣∣1等价于:
m
i
n
∣
∣
w
∣
∣
min ||w||
min∣∣w∣∣
等价于:
m
i
n
1
2
w
2
min \frac{1}{2} w^2
min21w2
这时原问题可以描述为
m
a
x
1
∣
∣
w
∣
∣
=
m
i
n
1
2
w
T
w
max \frac{1}{||w||}=min \frac{1}{2}\ w^Tw
max∣∣w∣∣1=min21 wTw
s
.
t
.
1
−
y
i
(
w
T
x
i
+
b
)
≤
0
s.t. \quad 1-y_i(w^Tx_i+b) \leq 0
s.t.1−yi(wTxi+b)≤0
此时的问题是凸优化问题,可以采样拉格郎日对偶方式处理
问题的拉格朗日函数:
L
(
w
,
b
,
λ
)
=
1
2
w
T
w
+
∑
i
=
1
n
λ
i
(
1
−
y
i
(
w
T
x
i
+
b
)
)
L(w,b,\lambda)=\frac{1}{2}w^Tw+ \displaystyle \sum_{i=1}^n \lambda_i(1-y_i(w^Tx_i+b))
L(w,b,λ)=21wTw+i=1∑nλi(1−yi(wTxi+b))
拉格郎日对偶函数为
g
(
λ
)
=
min
w
,
b
(
L
(
w
,
b
,
λ
)
)
g(\lambda)=\displaystyle \min_{w,b} \ (L(w,b,\lambda))
g(λ)=w,bmin (L(w,b,λ))
对偶问题描述为:
{
m
a
x
g
(
λ
)
=
max
λ
min
w
,
b
(
L
(
w
,
b
,
λ
)
)
λ
≥
0
\begin{cases} max\ g(\lambda)=\displaystyle \max_{\lambda} \ \min_{w,b}(L(w,b,\lambda))\\ \lambda \geq 0 \end{cases}
⎩⎨⎧max g(λ)=λmax w,bmin(L(w,b,λ))λ≥0
m a x g ( λ ) = max λ min w , b ( w T w + ∑ i = 1 n λ i ( 1 − y i ( w T x i + b ) ) ) max\ g(\lambda)=\displaystyle \max_{\lambda} \min_{w,b}(w^Tw+ \displaystyle \sum_{i=1}^n \lambda_i(1-y_i(w^Tx_i+b))) max g(λ)=λmaxw,bmin(wTw+i=1∑nλi(1−yi(wTxi+b)))
先求 min L ( w , b , λ ) \min L(w,b,\lambda) minL(w,b,λ)
对b求偏导
∂
L
(
w
,
b
,
λ
)
b
=
−
∑
i
=
1
n
λ
i
y
i
=
0
\displaystyle \frac{\partial L(w,b,\lambda)}{b}= -\displaystyle \sum_{i=1}^n\lambda_i y_i=0
b∂L(w,b,λ)=−i=1∑nλiyi=0
展开拉格郎日函数有
L
(
w
,
b
,
λ
)
=
1
2
w
T
w
+
∑
i
=
1
n
λ
i
(
1
−
y
i
w
T
x
i
−
y
i
b
)
L(w,b,\lambda)=\frac{1}{2}w^Tw+ \displaystyle \sum_{i=1}^n \lambda_i(1-y_iw^Tx_i-y_ib)
L(w,b,λ)=21wTw+i=1∑nλi(1−yiwTxi−yib)
=
1
2
w
T
w
+
∑
i
=
1
n
λ
i
−
∑
i
=
1
n
λ
i
y
i
w
T
x
i
−
∑
i
=
1
n
λ
i
y
i
b
=\frac{1}{2}w^Tw+ \displaystyle \sum_{i=1}^n \lambda_i- \displaystyle \sum_{i=1}^n \lambda_iy_iw^Tx_i-\displaystyle \sum_{i=1}^n \lambda_iy_ib
=21wTw+i=1∑nλi−i=1∑nλiyiwTxi−i=1∑nλiyib
=
1
2
w
T
w
+
∑
i
=
1
n
λ
i
−
∑
i
=
1
n
λ
i
y
i
w
T
x
i
=\frac{1}{2}w^Tw+ \displaystyle \sum_{i=1}^n \lambda_i- \displaystyle \sum_{i=1}^n \lambda_iy_iw^Tx_i
=21wTw+i=1∑nλi−i=1∑nλiyiwTxi
对w求偏导:
∂
L
(
w
,
b
,
λ
)
w
=
w
−
∑
i
=
1
n
λ
i
y
i
x
i
=
0
\displaystyle \frac{\partial L(w,b,\lambda)}{w}= w-\displaystyle \sum_{i=1}^n\lambda_i y_ix_i=0
w∂L(w,b,λ)=w−i=1∑nλiyixi=0
w
=
∑
i
=
1
n
λ
i
y
i
x
i
w=\displaystyle \sum_{i=1}^n\lambda_i y_ix_i
w=i=1∑nλiyixi
带入原函数有:
L
(
w
,
b
,
λ
)
=
1
2
w
T
w
+
∑
i
=
1
n
λ
i
−
∑
i
=
1
n
λ
i
y
i
w
T
x
i
L(w,b,\lambda)=\frac{1}{2}w^Tw+ \displaystyle \sum_{i=1}^n \lambda_i- \displaystyle \sum_{i=1}^n \lambda_iy_iw^Tx_i
L(w,b,λ)=21wTw+i=1∑nλi−i=1∑nλiyiwTxi
=
1
2
(
∑
i
=
1
n
λ
i
y
i
x
i
)
T
(
∑
j
=
1
n
λ
j
y
j
x
j
)
+
∑
i
=
1
n
λ
i
−
∑
i
=
1
n
λ
i
y
i
(
∑
j
=
1
n
λ
j
y
j
x
j
)
T
x
i
=\frac{1}{2}(\displaystyle \sum_{i=1}^n\lambda_i y_ix_i)^T(\displaystyle \sum_{j=1}^n\lambda_j y_jx_j)+ \displaystyle \sum_{i=1}^n \lambda_i- \displaystyle \sum_{i=1}^n \lambda_iy_i(\displaystyle \sum_{j=1}^n\lambda_j y_jx_j)^Tx_i
=21(i=1∑nλiyixi)T(j=1∑nλjyjxj)+i=1∑nλi−i=1∑nλiyi(j=1∑nλjyjxj)Txi
=
−
1
2
∑
i
=
1
n
∑
j
=
1
n
λ
i
λ
j
y
i
y
j
x
i
T
x
j
+
∑
i
=
1
n
λ
i
=-\frac{1}{2}\displaystyle \sum_{i=1}^n\displaystyle \sum_{j=1}^n\lambda_i \lambda_j y_iy_jx_i^Tx_j+\displaystyle \sum_{i=1}^n \lambda_i
=−21i=1∑nj=1∑nλiλjyiyjxiTxj+i=1∑nλi
m a x g ( λ ) = m a x ( − 1 2 ∑ i = 1 n ∑ j = 1 n λ i λ j y i y j x i T x j + ∑ i = 1 n λ i ) max\ g(\lambda)=max(-\frac{1}{2}\displaystyle \sum_{i=1}^n\displaystyle \sum_{j=1}^n\lambda_i \lambda_j y_iy_jx_i^Tx_j+\displaystyle \sum_{i=1}^n \lambda_i) max g(λ)=max(−21i=1∑nj=1∑nλiλjyiyjxiTxj+i=1∑nλi)
于是有下列对偶优化问题:
{
min
g
(
λ
)
=
1
2
∑
i
=
1
n
∑
j
=
1
n
λ
i
λ
j
y
i
y
j
x
i
T
x
j
−
∑
i
=
1
n
λ
i
λ
≥
0
∑
i
=
1
n
λ
i
y
i
=
0
\begin{cases} \min \ g(\lambda)=\frac{1}{2}\displaystyle \sum_{i=1}^n\displaystyle \sum_{j=1}^n\lambda_i \lambda_j y_iy_jx_i^Tx_j-\displaystyle \sum_{i=1}^n \lambda_i \\ \lambda \geq 0 \\ \displaystyle \sum_{i=1}^n\lambda_i y_i=0 \end{cases}
⎩⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎧min g(λ)=21i=1∑nj=1∑nλiλjyiyjxiTxj−i=1∑nλiλ≥0i=1∑nλiyi=0
由于原问题是凸问题,满足staler 条件,所以满足强对偶关系,也就是原问题最优解=对偶问题最优解,
从而也满足KKT条件:
{
1
−
y
i
(
w
T
x
i
+
b
)
≤
0
原
问
题
满
足
约
束
λ
i
≥
0
对
偶
问
题
满
足
约
束
λ
i
(
1
−
y
i
w
T
x
i
−
y
i
b
)
=
0
互
补
松
弛
∂
L
(
w
,
b
,
λ
)
b
=
0
,
∂
L
(
w
,
b
,
λ
)
w
=
0
,
∂
L
(
w
,
b
,
λ
)
λ
=
0
\begin{cases} 1-y_i(w^Tx_i+b) \leq 0 \ 原问题满足约束\\ \\ \lambda_i \geq 0 \ 对偶问题满足约束 \\ \\ \lambda_i(1-y_iw^Tx_i-y_ib)=0 \ 互补松弛 \\ \\ \displaystyle \frac{\partial L(w,b,\lambda)}{b}=0 ,\ \frac{\partial L(w,b,\lambda)}{w}=0,\frac{\partial L(w,b,\lambda)}{\lambda}=0 \end{cases}
⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎧1−yi(wTxi+b)≤0 原问题满足约束λi≥0 对偶问题满足约束λi(1−yiwTxi−yib)=0 互补松弛b∂L(w,b,λ)=0, w∂L(w,b,λ)=0,λ∂L(w,b,λ)=0
令
1
−
y
i
w
T
x
i
−
y
i
b
=
0
,
有
y
i
b
=
1
−
y
i
w
T
x
i
1-y_iw^Tx_i-y_ib=0,有y_ib=1-y_iw^Tx_i
1−yiwTxi−yib=0,有yib=1−yiwTxi
两边同时乘以
y
i
有
b
=
y
i
−
w
t
x
i
=
y
i
−
∑
i
=
1
n
λ
i
y
i
x
i
T
x
i
y_i有b=y_i-w^tx_i=y_i-\displaystyle \sum_{i=1}^n\lambda_i y_ix_i^Tx_i
yi有b=yi−wtxi=yi−i=1∑nλiyixiTxi
也就是最优的w,b满足
w
∗
=
∑
i
=
1
n
λ
i
y
i
x
i
w^*=\displaystyle \sum_{i=1}^n\lambda_i y_ix_i
w∗=i=1∑nλiyixi
b
∗
=
y
i
−
w
t
x
i
=
y
i
−
∑
i
=
1
n
λ
i
y
i
x
i
T
x
i
b^*=y_i-w^tx_i=y_i-\displaystyle \sum_{i=1}^n\lambda_i y_ix_i^Tx_i
b∗=yi−wtxi=yi−i=1∑nλiyixiTxi















 4943
4943











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









