







论文:Fully Convolutional Networks for Semantic Segmentation
一、语义分割
这部分主要参考:FCN
图像语义分割的意思就是机器自动分割并识别出图像中的内容,比如给出一个人骑摩托车的照片,机器判断后应当能够生成右侧图,红色标注为人,绿色是车(黑色表示back ground)。

图像的语义分割另外还有一种示例级别(instance level)的图像语义分割,该类问题不仅需要对不同语义物体进行图像分割,同时还要求对同一语义的不同个体进行分割(例如需要对图中出现的九把椅子的像素用不同颜色分别标示出来)。

语义分割需要解决的一个问题是位置和语义的tension(翻译成矛盾感觉不太准确,或者均衡?),位置对应着局部信息,而语义对应着全局信息。
二、FCN简介
FCN是图像语义分割的开山之作,这是一篇发表在2015 CVPR上的一篇论文,拿到了当年的best paper honorable mention。
传统的基于CNN的语义分割方法:为了对一个像素分类,使用该像素周围的一个图像块作为CNN的输入用于训练和预测。这种方法有几个缺点:一是存储开销很大。例如对每个像素使用的图像块的大小为15x15,然后不断滑动窗口,每次滑动的窗口给CNN进行判别分类,因此则所需的存储空间根据滑动窗口的次数和大小急剧上升。二是计算效率低下。相邻的像素块基本上是重复的,针对每个像素块逐个计算卷积,这种计算也有很大程度上的重复。三是像素块大小的限制了感知区域的大小。通常像素块的大小比整幅图像的大小小很多,只能提取一些局部的特征,从而导致分类的性能受到限制。
本文提出了全卷积网络(FCN)的概念,针对语义分割训练一个端到端,点对点的网络,达到了state-of-the-art。这是第一次训练端到端的FCN 用于像素级的预测;也是第一次用监督预训练的方法训练分割网络。这种FCN能够从任意尺寸的输入图片中得到一个密集型的输出。相比于其它分割网络,这种方法十分高效,不用使用一些复杂的运算,比如patchwise traing。这种方法也没有采用常见分割网络所使用的一些预处理和后处理方法,比如超像素,proposals以及条件随机场等。
三、FCN架构
FCN网络模型如何实现的:
- 将一个用于分类的卷积网络(比如VGG16)转换为全卷积的,也就是将全连接层进行卷积化,得到一个热图(heatmap)
- 通过上采样,或者说反卷积(deconvolution)将热图恢复到输入图片的尺寸得到pixelwise predictions。然后以最大概率为依据逐个像素进行分类。loss就是所有像素上的softmax loss之和。
- 添加skip connections来将浅层精细的语义信息和深层粗糙的语义信息融合起来。也就是解决上面提到的“位置和语义的tension”
下面就围绕这三部分进行详细的解释。
1、分类器的卷积化
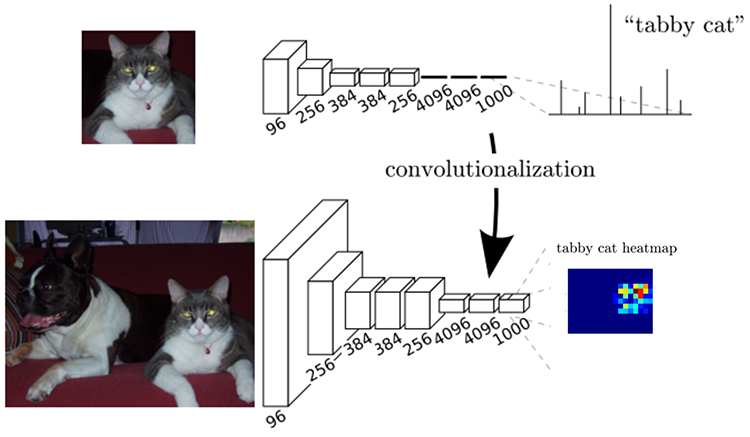
先看论文中给的这张图。上面是一个分类网络(有些像VGG16,但是每一层的通道数对应不上,不太重要不管它),其中画实线的部分是两个输出维度为4096的全连接层接一个输出维度为
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 398
398

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









