







线性模型:对数据集的特征求加权和
之前学习的三种线性模型,hypothesis 不同,error function 不同,能否使用易于优化的线性模型处理线性分类问题?能不能就得看这些线性模型的Ein是否接近分类的Ein值。下面,我们将分析这些线性模型Ein间的关系。


有了不同模型Ein的关系,利用vc-bound可以得出Eout与Ein的关系,做一个代换,可以看出,对于分类问题的Eout,如果可以保证使用square function 或是 cross entropy的Ein足够小,那么分类的结果也是可以得到保证的 。

为什么可以使用regression来做classification的 另一种解释:算法求解的w符合做分类条件,利用w求得的s可以很好地应用在sign函数上。
所以说,可以用logistic regression algorithm 或是linear regression algorithm 来求解w ,在计算score 并取出其符号。考虑不同模型的err,通过linear regression ,为了使得Ein值最小,我们求得的w需要尽可能的使得正样本的s接近1,负样本的值接近-1,因此我们对最终求得的s做一个sign就可以进行分类。通过linear regression ,为了使得Ein值最小,我们求得的w需要尽可能的使得正样本的s值越大越大,负样本的值越小越好。因此因此我们对最终求得的s做一个sign就可以进行分类。

二、改进梯度下降
比较之前所学的iteration optimization ,PLA 、pocket、使用GD的linear regression。
其中,PLA迭代更新的过程中,每次只使用一个错误的分类数据来做更新,而pocket和GD需要根据所有的数据确定更新的方向,这样一来,速度就慢了。因此对于GD,我们能否也只是用一个数据点来确定更新方向呢?看着梯度公式,可以发现是均值,根据概率论,我们可知使用一个随机的抽样值可以估计均值。因此我们使用随机选取一个数据点并计算其梯度方式来取代计算出所有数据点的梯度值再取均值。这种做法也称为stochastic gradient descent。


既然我们修改的思路是从PLA出发,那么来对比一下PLA和SGD,可以看出SGD无论选取的数据点是否分类有误,都会做更新,但是更新的程度不同。而PLA是只在错误点上更新。

SGD的实际操作中存在的两个问题:
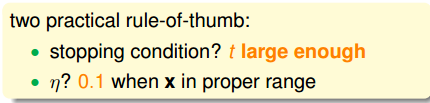
何时停止?在GD中,停止的条件是看平均的梯度值,现在我们就是不想计算所有平均的梯度值,因此,可以使用另一个停止条件:迭代足够次数。
如何选取步长?由于SGD的不稳定性,步长的选取至关重要,经验上选择0.1。
多类别分类问题:
站在巨人的肩膀上看待问题,充分利用我们会的知识,我们会二元分类,可以想想如何使用二元分类做多元分类,一个思路是one versus one,将一个类别作为正类,另一个类别父类,可以组合出Ck2个分类器,对于预测数据,使用每一个分类器的hypothesis 得出结果并进行投票,得出最终预测结果!另一个思路是one versus all ,将一个类别作为一个正类,其余所有的样本作为负类,k个类别k个分类器,预测的数据分别使用k个分类器求可能性最大类别。
多元分类问题拆分为训练多个二元分类器,预测的时候结合多个分类的结果给出最终的分类结果。
二元分类器可使用linear regression 、logistic regression 、binary classification算法。


















 184
184











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









