







深度探讨岭回归
引言
这篇文章的目的是让你更好地使用岭回归,而不仅仅是相关库提供的。“什么是岭回归?”。回答最简单的回答是“ 线性回归的变化”。最糟糕的方式是得从以下数学方程开始,乍一看并不是很多人能够理解的。
β
^
ridge
=
argmin
β
∈
R
∥
y
−
X
B
∥
2
2
+
λ
∥
B
∥
2
2
\hat{\beta}^{\text {ridge}}=\underset{\beta \in \mathbb{R}}{\operatorname{argmin}}\|y-X B\|_{2}^{2}+\lambda\|B\|_{2}^{2}
β^ridge=β∈Rargmin∥y−XB∥22+λ∥B∥22
坏消息是我们仍然要处理它,好消息是我们不会从这样的方程式开始。我想从**普通最小二乘法 (OLS)**开始。如果你碰巧几乎没有关于线性回归的背景知识,那么这段视频将帮助你了解使用“最小二乘法”的工作方式(要梯子和英文基础哦)。现在,你知道OLS就像我们通常所说的“线性回归”一样,我将使用这个术语。
继续前进
你想要记住两件事。一个是我们不喜欢过度拟合。换句话说,我们总是喜欢捕捉一般模式的模型。另一个是我们的目标是从新数据而不是特定数据预测它。因此,模型评估应基于新数据(测试集),而不是给定数据(训练集)。另外,我将交替使用以下术语。
- 独立变量= X.
- 系数= β
- 剩余的平方和= RSS
选择最小二乘法(OLS)
y = β 0 + β 1 x 1 + β 2 x 2 + ⋯ + β p x p + ε y=\beta_{0}+\beta_{1} x_{1}+\beta_{2} x_{2}+\cdots+\beta_{p} x_{p}+\varepsilon y=β0+β1x1+β2x2+⋯+βpxp+ε -----实际模型
y ^ = β ^ 0 + β ^ 1 x 1 + β ^ 2 x 2 + ⋯ + β ^ p x p \hat{y}=\hat{\beta}_{0}+\hat{\beta}_{1} x_{1}+\hat{\beta}_{2} x_{2}+\cdots+\hat{\beta}_{p} x_{p} y^=β^0+β^1x1+β^2x2+⋯+β^pxp ----估计模型
β ^ O L S = ( X T X ) − 1 X T Y \hat{\beta}^{O L S}=\left(X^{T} X\right)^{-1} X^{T} Y β^OLS=(XTX)−1XTY -----矩阵方程
最小二乘法找到最佳和无偏差系数
如此你可能知道最小二乘法找到最适合数据的系数。要添加的另一个情况是:它还可以找到无偏系数。这里无偏差估计意味着OLS不会考虑哪个独立变量比其他变量更重要。它只是找到给定数据集的系数。简而言之,只能找到一组β,从而产生最低的“剩余平方和(RSS)”。那么问题就变成“具有最低RSS的模型真的是最好的模型吗?”。
偏差与方差
上述问题的答案是“不是真的”。正如“无偏差”一词所示,我们也需要考虑“偏差”。偏差意味着模型对其预测因素的关注程度。假设有两种模型可以用两个预测器“甜味”和“光泽”来预测苹果价格; 一个模型是无偏差的,另一个是有偏差的。
首先,无偏模型试图找到两个特征和价格之间的关系,就像OLS方法一样。该模型将尽可能完美地符合观察结果,以最小化RSS。但是,这很容易导致过度拟合问题。换句话说,模型对新数据的表现不佳,因为它是针对给定数据构建的,因此具体说它可能不适合新数据。
有偏差的模型接受其变量不平等地对待每个预测值。回到这个例子,我们只想关心“甜度”来建立一个模型,这应该可以更好地利用新数据。在理解偏差与方差之后,将解释其原因。如果您不熟悉偏差与方差先去这里B站或者其他视频了解下。
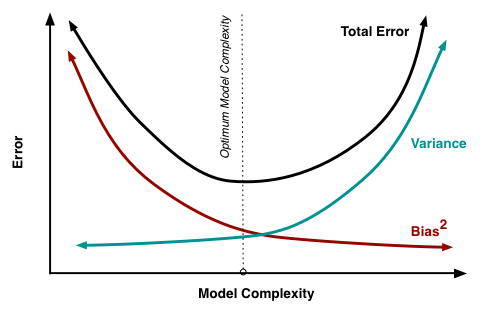
可以说,偏差与不能适应训练集的模型有关,方差与不符合测试集的模型有关。偏差和方差与模型复杂性存在权衡关系,这意味着简单模型将具有高偏差和低方差,反之亦然。在我们的苹果示例中,仅考虑“甜度”的模型不像考虑“甜度”和“光泽”的其他模型那样适合训练数据,但更简单的模型将更好地预测新数据。
这是因为“甜度”是价格的决定因素,而“光泽”不应该是。我们都知道这是常识,但数学模型不像我们一样思考,只计算所给出的内容,直到找到所有预测变量和自变量之间的某种关系来拟合训练数据。
岭回归的几何理解
很多时候,图形有助于了解模型的工作方式,而岭回归也不例外。下图是比较OLS和岭回归的几何解释。
轮廓和OLS估计
每个轮廓是RSS相同的点的连接,以OLS估计为中心,其中RSS是最低的。此外,OLS估计是最适合训练集(低偏差)的点。
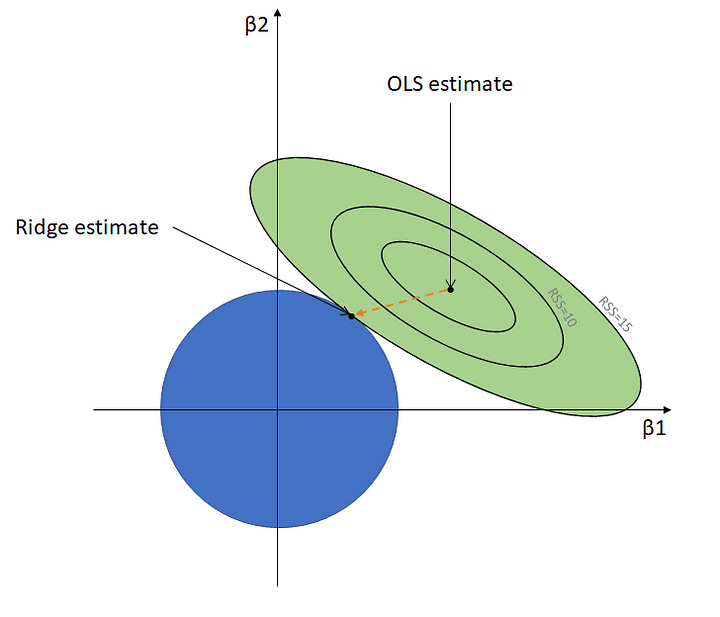
圆和岭估计
与OLS估计不同,岭估计随着蓝色圆的大小改变而改变。它就是圆圈与最外层轮廓相遇的地方。岭回归的工作原理是我们如何调整圆的大小。关键是β的变化处于不同的水平。
假设β1是’光泽’而β2是’甜度’。正如你所看到的,随着圆的增大,脊β 1比脊β 2相对较快下降到零(比较这两个数字)。之所以出现这种情况的原因是因为β的变化由不同RSS决定。直观地看,轮廓不是圆形而是倾斜的椭圆形。
β不可能是零,只能收敛到它,这将在下一个数学公式中解释。虽然像这样的几何表达式很好地解释了一个主要的想法,但也有一个限制,我们无法通过三维表达它。所以,这一切都归结为数学表达式
数学公式
我们已经看到了一般术语和矩阵版本的多元线性回归方程。它可以用另一个版本编写如下。
argmin
β
∈
R
∑
[
y
i
−
y
^
i
]
=
argmin
β
∈
R
[
y
i
−
(
β
0
+
β
1
x
1
+
β
x
2
+
⋯
+
β
x
p
)
]
2
\underset{\beta \in \mathbb{R}}{\operatorname{argmin}} \sum\left[y_{i}-\hat{y}_{i}\right]=\operatorname{argmin}_{\beta \in \mathbb{R}}\left[y_{i}-\left(\beta_{0}+\beta_{1} x_{1}+\beta x_{2}+\cdots+\beta x_{p}\right)\right]^{2}
β∈Rargmin∑[yi−y^i]=argminβ∈R[yi−(β0+β1x1+βx2+⋯+βxp)]2
这里argmin的意思是“最小的参数”,使函数达到最小。在上下文中,它找到最小化RSS 的β。我们知道如何从矩阵公式中得到β。现在,问题变成“这与岭回归有什么关系?”。
β 0 2 + β 1 2 + ⋯ + β p 2 ≤ C 2 \beta_{0}^{2}+\beta_{1}^{2}+\cdots+\beta_{p}^{2} \leq C^{2} β02+β12+⋯+βp2≤C2
同样,岭回归是线性回归的变形。我们上式姑且称作OLS方程的岭回归约束。我们正在寻找β,但他们现在也必须满足上述约束。回到几何图形,C相当于圆的半径,因此,β应该落在圆形区域,可能在边缘的某个地方。
范数
我们仍然想要了解第一个等式。要做到这一点,我们需要了解向量规范,这只是以下定义。
∥
B
∥
2
=
β
0
2
+
β
1
2
+
⋯
+
β
p
2
\|B\|_{2}=\sqrt{\beta_{0}^{2}+\beta_{1}^{2}+\cdots+\beta_{p}^{2}}
∥B∥2=β02+β12+⋯+βp2
这就是L2范数,您可以在此处了解有关范数的更多信息。我们此刻只关心L2范数,因此我们可以构建我们已经看到的等式。以下是最简单但仍然与我们讨论的内容相同。请注意,以下等式中的第一项基本上是OLS,然后使用λ的第二项是使岭回归的原因。
β
^
r
i
d
g
e
=
argmin
β
∈
R
∥
y
−
X
B
∥
2
2
+
λ
∥
B
∥
2
2
\hat{\beta}^{r i d g e}=\underset{\beta \in \mathbb{R}}{\operatorname{argmin}}\|y-X B\|_{2}^{2}+\lambda\|B\|_{2}^{2}
β^ridge=β∈Rargmin∥y−XB∥22+λ∥B∥22
我们真正想要找到的
带有λ的式子的术语通常被称为“惩罚”,因为它增加了RSS。我们将某些值迭代到λ上,并使用诸如“均方误差(MSE)”之类的测量值来评估模型。因此,应选择最小化MSE的λ值作为最终模型。该岭回归模型在预测中通常优于OLS模型。如下面的公式中所示,β与随着λ变化,且如果λ等于零(无罚分)与OLS β相等。
β ^ r i d g e = ( X T X + λ I ) − 1 X T Y \hat{\beta}^{r i d g e}=\left(X^{T} X+\lambda I\right)^{-1} X^{T} Y β^ridge=(XTX+λI)−1XTY
为什么它会收敛而不会变为零
我们之前看到的矩阵公式, λ以分母结束。这意味着如果我们增加λ值,脊β应该减小。但不论值值设置多大,脊β都不能为零。也就是说,岭回归给予特征不同的重要性权重,但不会丢弃不重要的特征。
( ⋯ + 1 λ + ⋯   ) X T Y \left(\cdots+\frac{1}{\lambda}+\cdots\right) X^{T} Y (⋯+λ1+⋯)XTY
使用数据集进行演示
来自sklearn的数据集’Boston House Price’ 用于演示。这个元数据有十几个功能。整个演示中需要以下python库。
完整的代码可以在我的github上找到
现在加载数据集,随后,应该标准化功能。由于岭回归通过惩罚来缩小系数,因此应该对特征进行缩放以使开始条件公平。这篇文章解释了有关此问题的更多详细信息
接下来,我们可以迭代范围从0到199的λ值。注意,λ等于零(λ = 0)的系数与OLS系数相同。
现在,我们可以从数据框中绘制图。仅选择五个属性以实现更好的可视化
在这里插入图片描述

直觉看房间”应该觉的最佳房价指标。这就是为什么红色线不会在迭代中收敛。相反,“高速公路通道”(蓝色)显着减少,这意味着当我们寻求更多的通用模型时,这个指标将失去其重要性(权值)。
从其余部分看到类似的情况, 指标会聚到零,即黑色虚线。如果我们不断增加λ(极度偏向),那么只有’Room’会显著保持
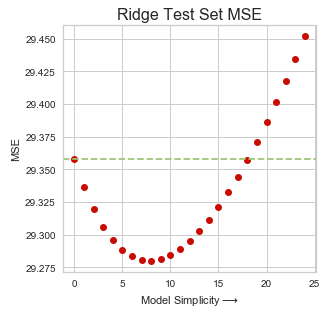
绿色虚线来自上图中的OLS,X轴通过增加λ值绘制。随着λ值的增加,MSE值在开始时减小,这意味着模型预测得到改善(误差较小)到某一点。简而言之,具有一些偏差的OLS模型在预测方面比纯OLS模型更好,我们将这种修改后的OLS模型称为岭回归模型。
结论
我们研究了从数学公式,矩阵格式到几何表达的不同角度的岭回归。通过这些,我们可以理解岭回归基本上是一个带有惩罚的线性回归。通过演示,我们确认没有找到最佳λ的等式。因此,我们需要迭代一系列值并使用MSE评估预测性能。通过这样做,我们发现岭回归模型比预测的普通线性回归模型表现更好。















 11万+
11万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









