




项目落地二
- 1、python装饰器
- 2、c++中的智能指针
- 3、c++中stl
- 4、c++中回调函数 怎么样的?并举例
- 5、 类(class) vs 结构体(struct)区别
- 6、c++中指针和引用
- 7、c++中关于模版常考的问题
- 8、 c++中 关于类 多态,继承等面试常问问题
- 9、c++中关于const 面试相关问题
- 11、yolo系列哪些可以提升小目标?措施
- 12、YOLO 系列所有关键模块:C2f、C3、C3F、ELAN/E-ELAN、CSP、FPN、PAN、BiFPN、SPP、SPPF,
- 13、解释一下,IOU,GIoU,DIoU,CIoU,EIoU,DFL
- 14、 yolo1-yolo11的模型结构,neck,检测头,loss,backbone
- 14、 unet,deeplabv3,maskrcnn等语义分割模型结构,loss
- 15、mobilenet系列,还有其他常用分类系列网络的模型结构,loss
- 16、卷积、池化的尺度,计算量、参数的计算公式
- 17、tensorrt
- 18、openvino
- 19、可形变注意力机制transformer
- 20、tensorrt自定义算子
1、python装饰器
装饰器本质上是一个函数(或类),用于在不修改原函数代码的情况下给函数增加功能。
● 有一个原函数 func()。
● 你希望在它执行前或执行后做一些额外的事情,比如打印日志、权限检查、计时等。
● 装饰器可以帮你“包裹”这个函数,给它加上额外功能。
def decorator(func):
def wrapper(*args, **kwargs):
print("执行前的操作")
result = func(*args, **kwargs)
print("执行后的操作")
return result
return wrapper
@decorator
def say_hello(name):
print(f"Hello, {name}!")
say_hello("Alice")
带参数的装饰器
如果装饰器本身需要参数,可以再多一层函数:
def repeat(times):
def decorator(func):
def wrapper(*args, **kwargs):
for _ in range(times):
func(*args, **kwargs)
return wrapper
return decorator
@repeat(3)
def greet(name):
print(f"Hi, {name}!")
greet("Bob")
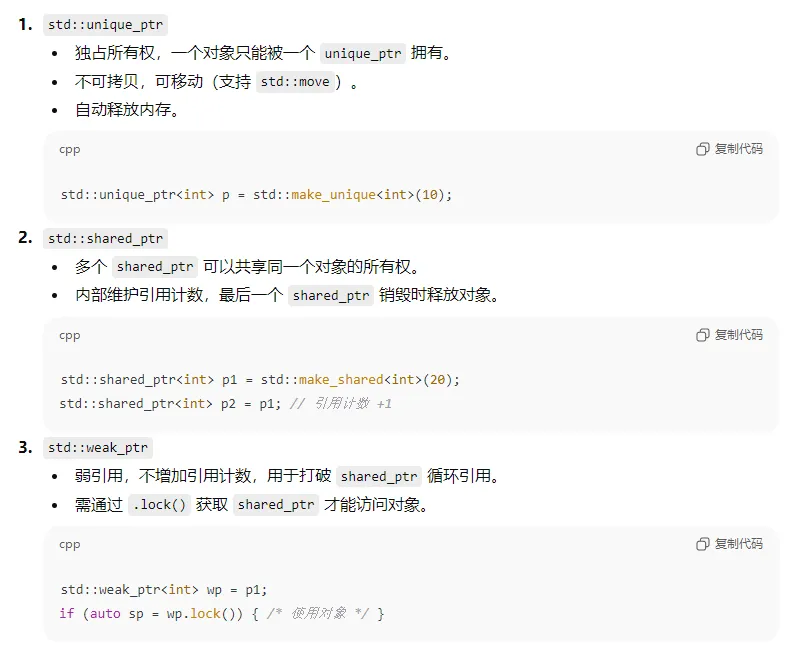
2、c++中的智能指针
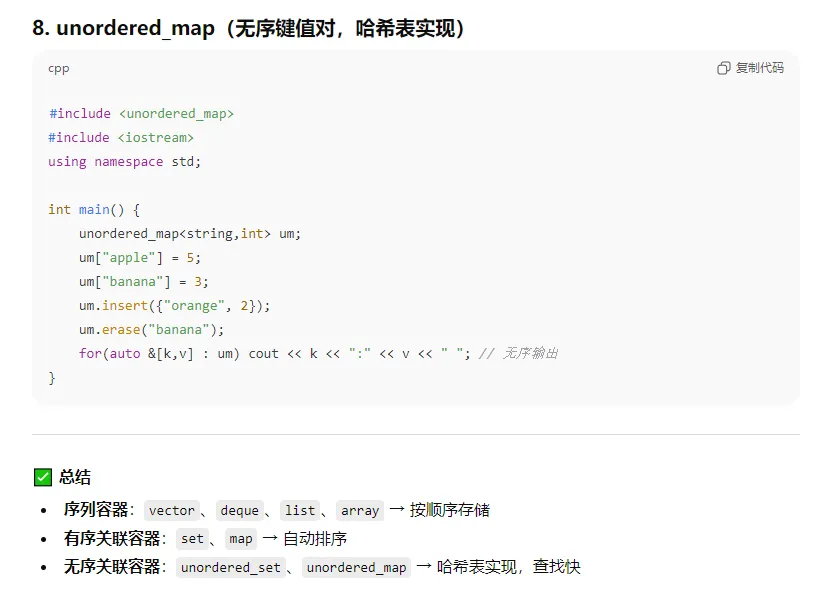
3、c++中stl







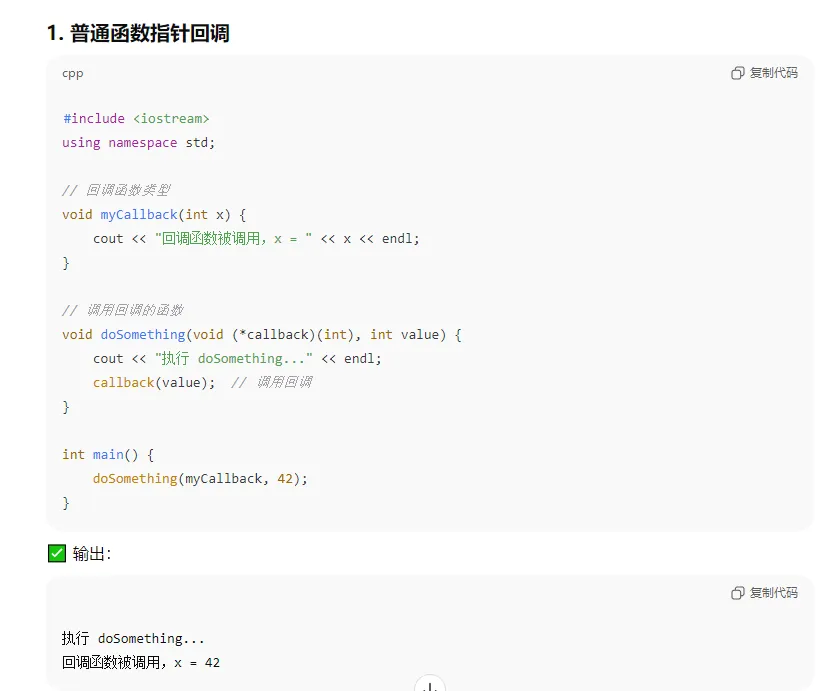
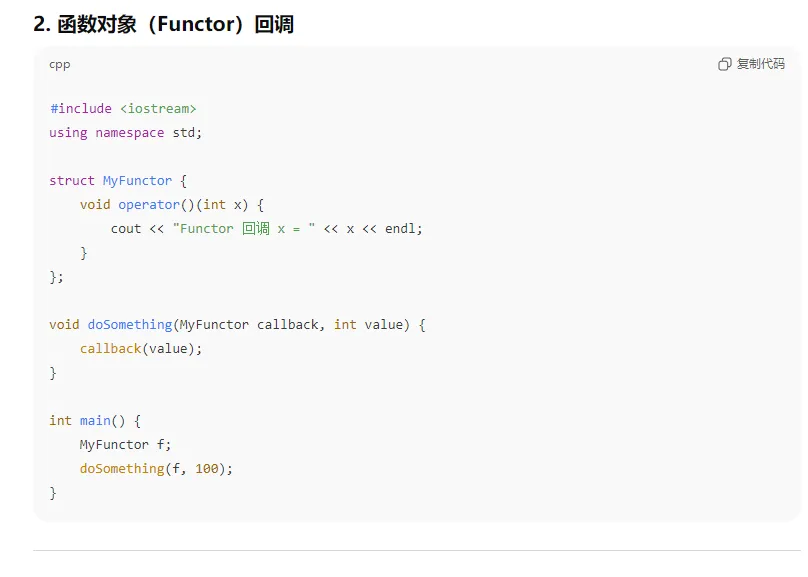
4、c++中回调函数 怎么样的?并举例
C++ 中的 回调函数(Callback),指的是把一个函数作为参数传递给另一个函数,当特定事件发生时再调用它。回调可以通过 普通函数指针、函数对象(functor)、lambda 或 std::function 实现。
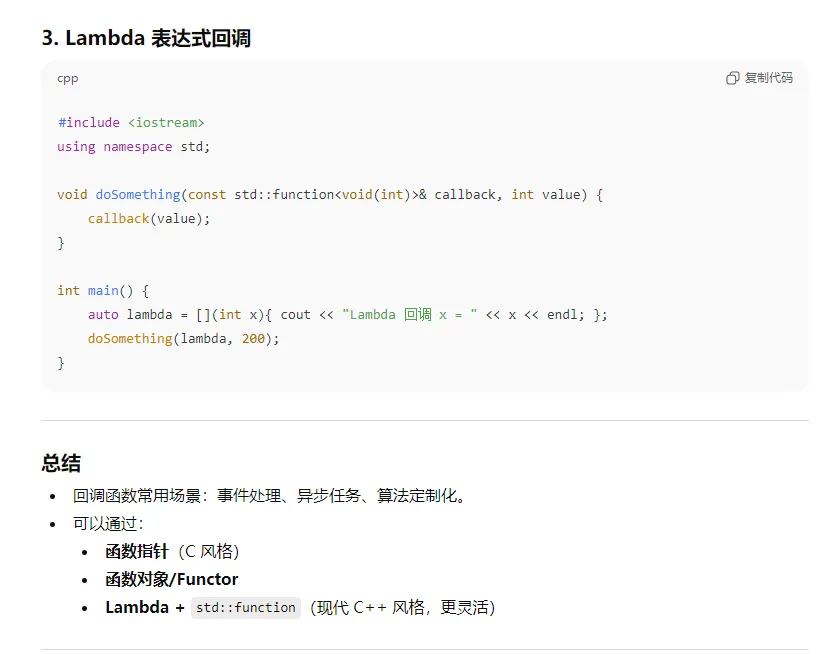
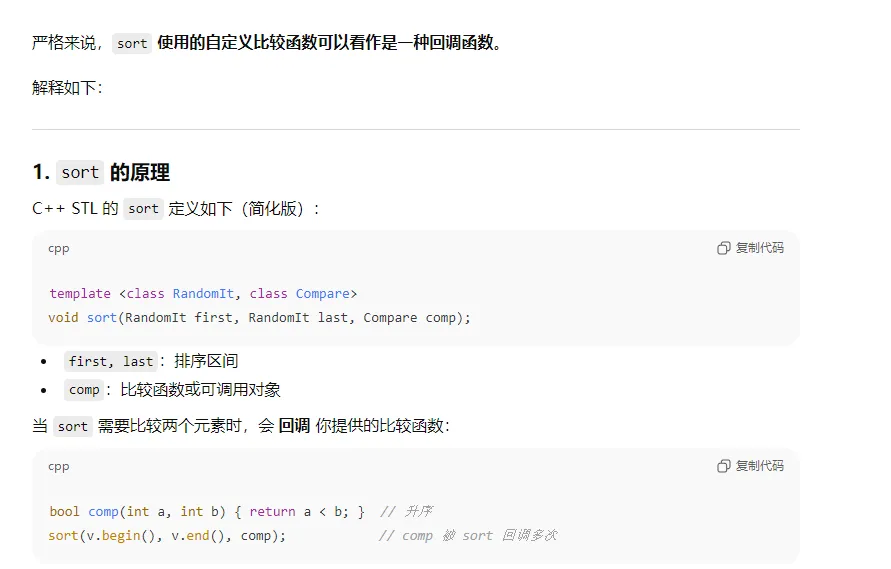
5、 类(class) vs 结构体(struct)区别

6、c++中指针和引用



7、c++中关于模版常考的问题
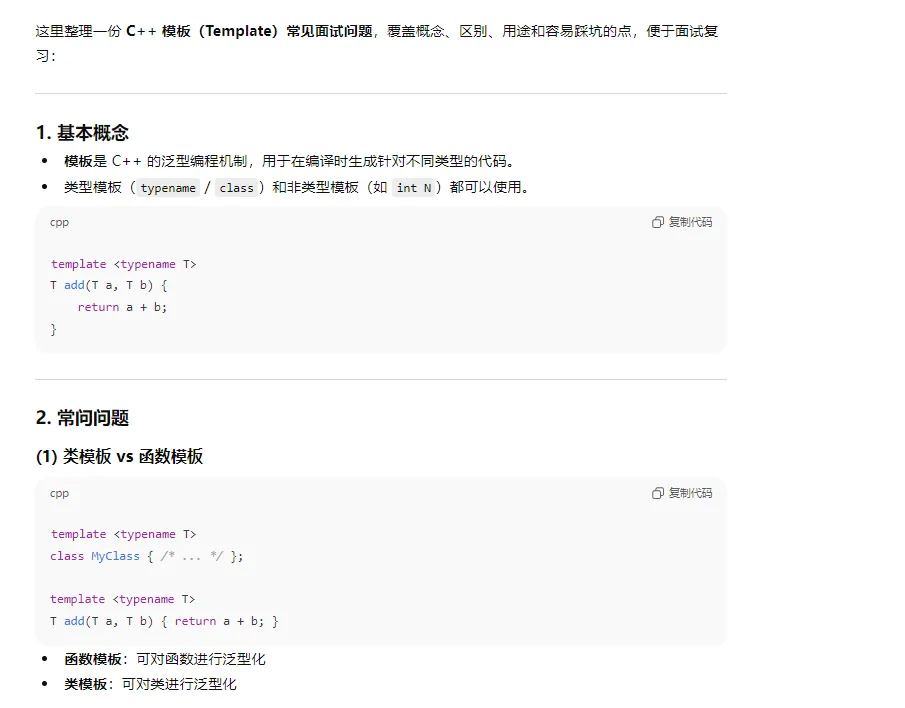
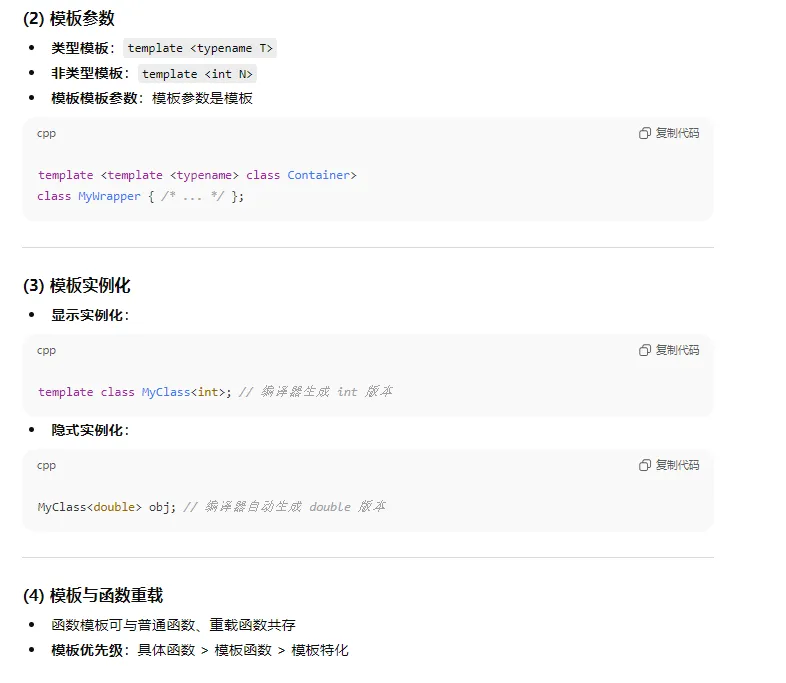
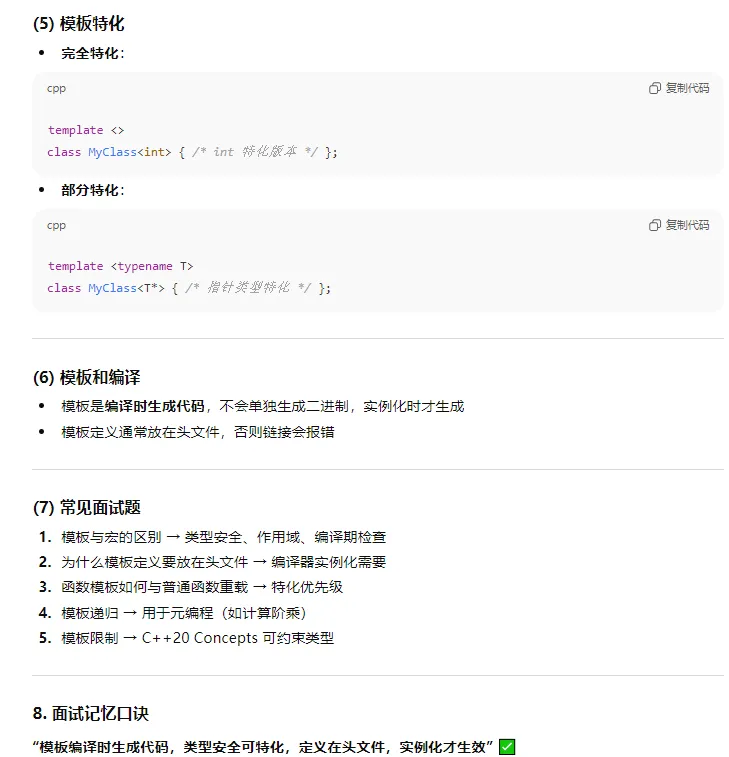
8、 c++中 关于类 多态,继承等面试常问问题

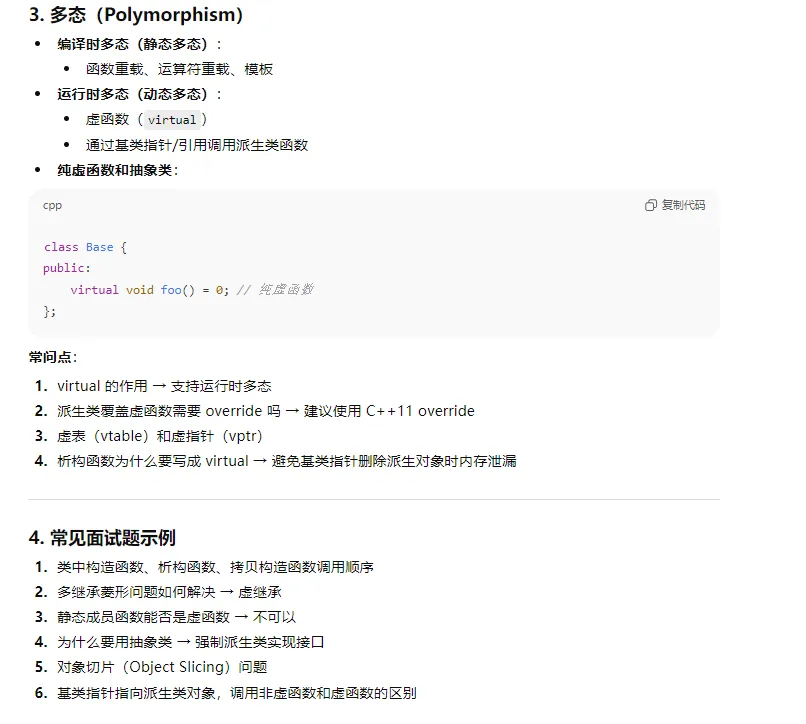

9、c++中关于const 面试相关问题
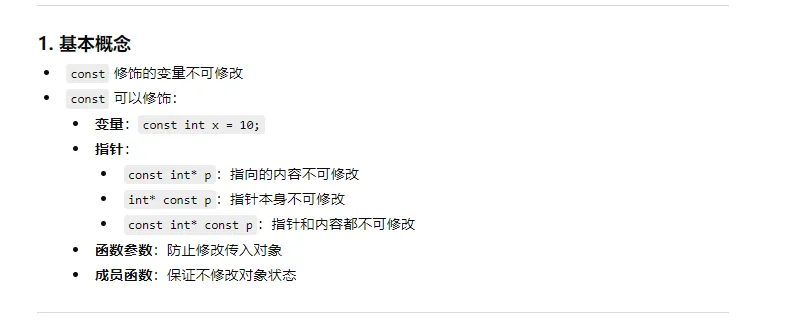
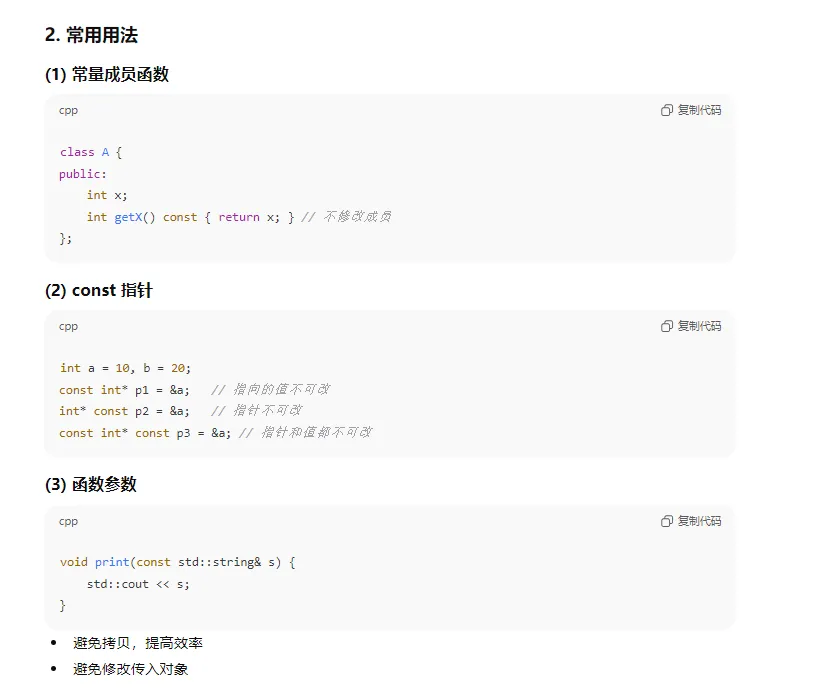

11、yolo系列哪些可以提升小目标?措施





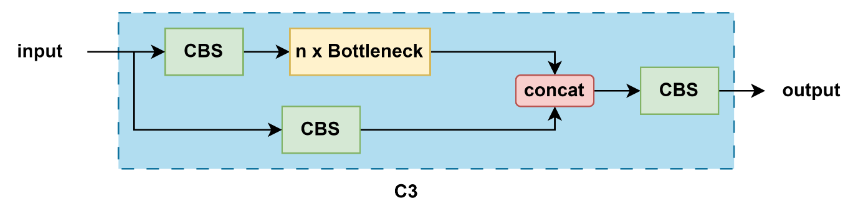
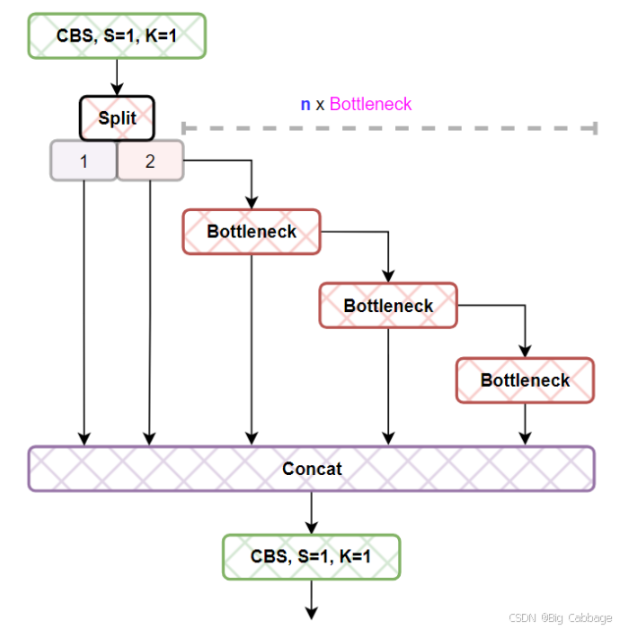
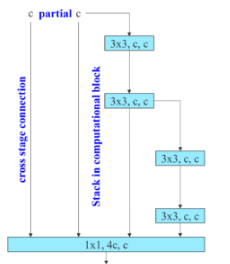
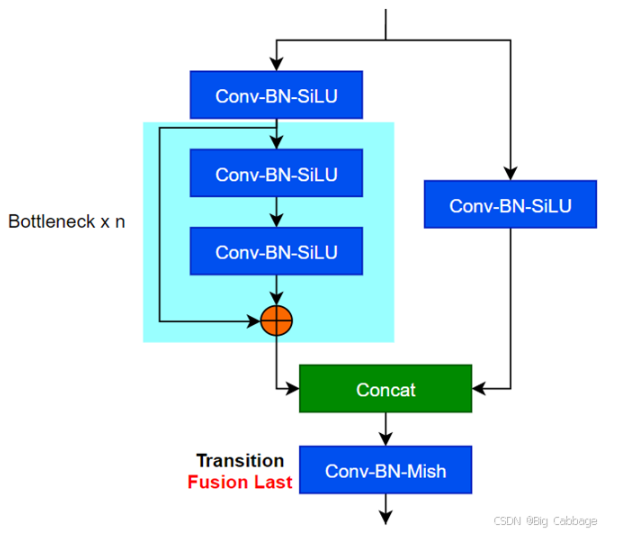
12、YOLO 系列所有关键模块:C2f、C3、C3F、ELAN/E-ELAN、CSP、FPN、PAN、BiFPN、SPP、SPPF,



C3
C2F
ELAN

CSP
SPP
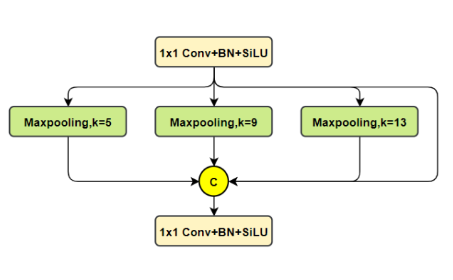
SPPF
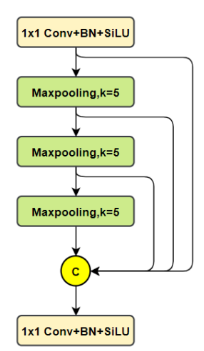
13、解释一下,IOU,GIoU,DIoU,CIoU,EIoU,DFL



14、 yolo1-yolo11的模型结构,neck,检测头,loss,backbone
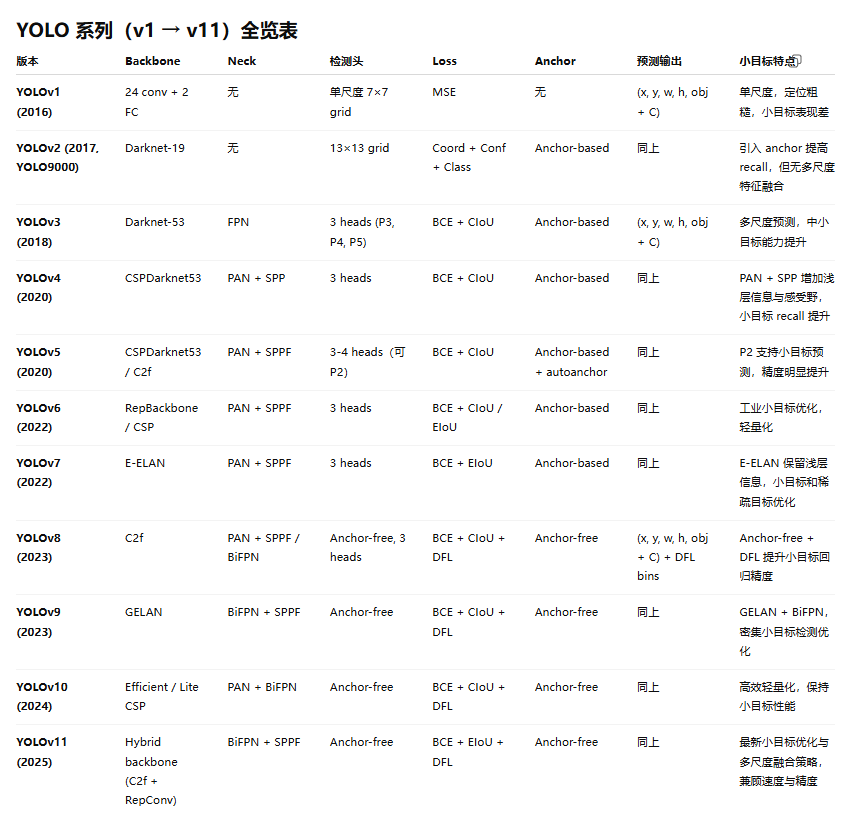



14、 unet,deeplabv3,maskrcnn等语义分割模型结构,loss



15、mobilenet系列,还有其他常用分类系列网络的模型结构,loss



16、卷积、池化的尺度,计算量、参数的计算公式



17、tensorrt
- TensorRT 是什么?主要作用?
答:NVIDIA 提供的 GPU 推理加速库,能把深度学习模型转换为高效推理引擎,支持 FP32/FP16/INT8 加速。 - TensorRT 支持哪些精度?区别?
答:FP32(全精度,最准确)、FP16(半精度,速度快,占用少)、INT8(整数量化,速度最快,需要校准保证精度)。 - Engine 和 Builder 的作用?
答:Builder 用于构建优化后的模型(Engine),Engine 是最终可以直接部署的推理模型。 - 什么是层融合(Layer Fusion)?
答:把连续操作(如 Conv + BN + ReLU)合并成一个 GPU 内核,减少内存和计算,提高速度。 - 如何做 INT8 量化?
答:需要校准数据集,通过校准生成量化表,将 FP32 权重和激活映射为 INT8。 - 动态 shape 是什么?
答:支持不同输入大小的推理,而不需要为每个大小单独构建 Engine。 - 什么情况下需要自定义 Plugin?
答:当模型里有 TensorRT 不支持的操作时,用 Plugin 写自定义 GPU 内核。 - 如何把 PyTorch/TensorFlow 模型转换为 TensorRT?
答:先导出为 ONNX,再用 TensorRT Builder 或 trtexec 生成 Engine。
1、构建阶段
主要步骤:
创建 Builder
创建 Network
创建 Config
创建 parser
解析 ONNX 模型
设置 输入维度
设置 动态维度(可选)
构建并 序列化 Engine
2、部署阶段
主要步骤:
onnx转engine
创建推理引擎
反序列化加载 Engine
创建推理上下文 ExecutionContext
分配 输入输出缓冲区(cudaMalloc)
拷贝 输入数据到 GPU
执行 推理(executeV2)
拷贝 输出结果回 CPU
18、openvino
- OpenVINO 是什么?
答:Intel 提供的深度学习模型推理优化工具,支持 CPU、Intel GPU、VPU 加速。 - IR(Intermediate Representation)是什么?为什么需要?
答:模型的中间表示(xml + bin),便于优化和跨设备部署。 - OpenVINO 支持哪些精度?
答:FP32、FP16、INT8,可通过 POT 工具进行后训练量化。 - 异构执行(Heterogeneous Execution)是什么?
答:同一模型不同层可以在 CPU + GPU 等不同设备执行,提高性能。 - 层融合和图优化是什么?
答:自动合并冗余操作,减少计算量,提高推理速度。 - OpenVINO 推理流程?
答:模型 → Model Optimizer → IR → Inference Engine → 推理执行。 - 如何处理动态输入?
答:通过动态 shape 设置,使模型支持不同大小的输入。
主要步骤:
1️⃣ 模型转换:
2️⃣ 初始化 Core:
3️⃣ 读取并编译模型:
4️⃣ 创建推理请求:
5️⃣ 设置输入并执行推理:
19、可形变注意力机制transformer

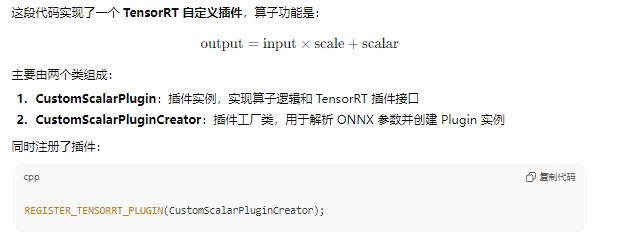
20、tensorrt自定义算子
- 定义 PyTorch 自定义算子(Autograd Function)
class CustomScalarImpl(torch.autograd.Function):
@staticmethod
def symbolic(g, x, r, s):
return g.op("custom::customScalar", x, scalar_f=r, scale_f=s)
@staticmethod
def forward(ctx, x, r, s):
return (x + r) * s
- 在 nn.Module 中封装算子
class CustomScalar(nn.Module):
def __init__(self, r, s):
super().__init__()
self.scalar = r
self.scale = s
def forward(self, x):
return CustomScalarImpl.apply(x, self.scalar, self.scale)
- 构建模型(包含自定义算子)
torch.onnx.export(
model,
args=(input,),
f="sample_customScalar.onnx",
input_names=["input0"],
output_names=["output0"],
opset_version=15,
)
python示例代码
import torch
import torch.onnx
import torch.nn as nn
import onnxruntime
import onnx
import onnxsim
import os
from collections import OrderedDict
class CustomScalarImpl(torch.autograd.Function):
@staticmethod
def symbolic(g, x, r, s):
return g.op("custom::customScalar", x, scalar_f=r, scale_f=s)
@staticmethod
def forward(ctx, x, r, s):
return (x + r) * s
class CustomScalar(nn.Module):
def __init__(self, r, s):
super().__init__()
self.scalar = r
self.scale = s
def forward(self, x):
return CustomScalarImpl.apply(x, self.scalar, self.scale)
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv = nn.Conv2d(1, 3, (3, 3), padding=1)
self.act = CustomScalar(1, 10)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, mean=0., std=1.)
if isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1.05)
nn.init.constant_(m.bias, 0.05)
def forward(self, x):
x = self.conv(x)
x = self.act(x)
return x
def setup_seed(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
def export_norm_onnx(input, model):
current_path = os.path.dirname(__file__)
file = current_path + "/../../models/onnx/sample_customScalar.onnx"
torch.onnx.export(
model = model,
args = (input,),
f = file,
input_names = ["input0"],
output_names = ["output0"],
opset_version = 15)
print("Finished normal onnx export")
# check the exported onnx model
model_onnx = onnx.load(file)
onnx.checker.check_model(model_onnx)
# use onnx-simplifier to simplify the onnx
print(f"Simplifying with onnx-simplifier {onnxsim.__version__}...")
model_onnx, check = onnxsim.simplify(model_onnx)
assert check, "assert check failed"
onnx.save(model_onnx, file)
def eval(input, model):
output = model(input)
print("------from infer------")
print(input)
print("\n")
print(output)
if __name__ == "__main__":
setup_seed(1)
input = torch.tensor([[[
[0.7576, 0.2793, 0.4031, 0.7347, 0.0293],
[0.7999, 0.3971, 0.7544, 0.5695, 0.4388],
[0.6387, 0.5247, 0.6826, 0.3051, 0.4635],
[0.4550, 0.5725, 0.4980, 0.9371, 0.6556],
[0.3138, 0.1980, 0.4162, 0.2843, 0.3398]]]])
model = Model()
model.eval()
# 计算
eval(input, model)
# 导出onnx
export_norm_onnx(input, model);
C++代码,解析自定义算子
cu文件
#include <cuda_runtime.h>
#include <math.h>
__global__ void customLeakyReLUKernel(
const float* input, float* output,
const float alpha, const int nElements)
{
const int index = blockIdx.x * blockDim.x + threadIdx.x;
if (index >= nElements)
return;
output[index] = input[index] > 0 ? input[index] : input[index] * alpha;
}
void customLeakyReLUImpl(const float* inputs, float* outputs, const float alpha, const int nElements, cudaStream_t stream)
{
dim3 blockSize(256, 1, 1);
dim3 gridSize(ceil(float(nElements) / 256), 1, 1);
customLeakyReLUKernel<<<gridSize, blockSize, 0, stream>>>(inputs, outputs, alpha, nElements);
}
hpp
#ifndef __CUSTOM_LEAKY_RELU_PLUGIN_HPP__
#define __CUSTOM_LEAKY_RELU_PLUGIN_HPP__
#include "NvInferRuntime.h"
#include "NvInferRuntimeCommon.h"
#include <NvInfer.h>
#include <string>
#include <vector>
using namespace nvinfer1;
namespace custom
{
static const char* PLUGIN_NAME {"customLeakyReLU"};
static const char* PLUGIN_VERSION {"1"};
class CustomLeakyReLUPlugin : public IPluginV2DynamicExt {
public:
CustomLeakyReLUPlugin() = delete;
CustomLeakyReLUPlugin(const std::string &name, float alpha);
CustomLeakyReLUPlugin(const std::string &name, const void* buffer, size_t length);
~CustomLeakyReLUPlugin();
const char* getPluginType() const noexcept override;
const char* getPluginVersion() const noexcept override;
int32_t getNbOutputs() const noexcept override;
size_t getSerializationSize() const noexcept override;
const char* getPluginNamespace() const noexcept override;
DataType getOutputDataType(int32_t index, DataType const* inputTypes, int32_t nbInputs) const noexcept override;
DimsExprs getOutputDimensions(int32_t outputIndex, const DimsExprs* input, int32_t nbInputs, IExprBuilder &exprBuilder) noexcept override;
size_t getWorkspaceSize(const PluginTensorDesc *inputs, int32_t nbInputs, const PluginTensorDesc *outputs, int32_t nbOutputs) const noexcept override;
int32_t initialize() noexcept override;
void terminate() noexcept override;
void serialize(void *buffer) const noexcept override;
void destroy() noexcept override;
int32_t enqueue(const PluginTensorDesc* inputDesc, const PluginTensorDesc* outputDesc, const void* const* ionputs, void* const* outputs, void* workspace, cudaStream_t stream) noexcept override; // 实际插件op执行的地方,具体实现forward的推理的CUDA/C++实现会放在这里面
IPluginV2DynamicExt* clone() const noexcept override;
bool supportsFormatCombination(int32_t pos, const PluginTensorDesc* inOuts, int32_t nbInputs, int32_t nbOutputs) noexcept override;
void configurePlugin(const DynamicPluginTensorDesc* in, int32_t nbInputs, const DynamicPluginTensorDesc* out, int32_t nbOutputs) noexcept override;
void setPluginNamespace(const char* pluginNamespace) noexcept override;
void attachToContext(cudnnContext* contextCudnn, cublasContext* contextCublas, IGpuAllocator *gpuAllocator) noexcept override;
void detachFromContext() noexcept override;
private:
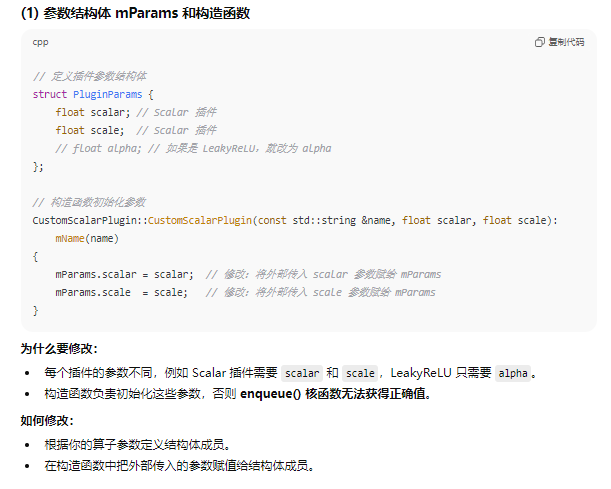
const std::string mName;
std::string mNamespace;
struct {
float alpha;
} mParams;
};
class CustomLeakyReLUPluginCreator : public IPluginCreator {
public:
CustomLeakyReLUPluginCreator();
~CustomLeakyReLUPluginCreator();
const char* getPluginName() const noexcept override;
const char* getPluginVersion() const noexcept override;
const PluginFieldCollection* getFieldNames() noexcept override;
const char* getPluginNamespace() const noexcept override;
IPluginV2* createPlugin(const char* name, const PluginFieldCollection* fc) noexcept override;
IPluginV2* deserializePlugin(const char* name, const void* serialData, size_t serialLength) noexcept override;
void setPluginNamespace(const char* pluginNamespace) noexcept override;
private:
static PluginFieldCollection mFC;
static std::vector<PluginField> mAttrs;
std::string mNamespace;
};
} // namespace custom
#endif __CUSTOM_LEAKY_RELU_PLUGIN_HPP__
cpp
#include "custom-leakyReLU-plugin.hpp"
#include "utils.hpp"
#include <map>
#include <cstring>
/******************************************************************/
/******************** CustomLeakyReLU的核函数接口部分 ****************/
/******************************************************************/
void customLeakyReLUImpl(const float* inputs, float* outputs, const float alpha, const int nElements, cudaStream_t stream);
using namespace nvinfer1;
namespace custom
{
REGISTER_TENSORRT_PLUGIN(CustomLeakyReLUPluginCreator);
PluginFieldCollection CustomLeakyReLUPluginCreator::mFC {};
std::vector<PluginField> CustomLeakyReLUPluginCreator::mAttrs;
/******************************************************************/
/*********************CustomLeakyReLUPlugin部分*********************/
/******************************************************************/
CustomLeakyReLUPlugin::CustomLeakyReLUPlugin(const std::string &name, float alpha):
mName(name)
{
mParams.alpha = alpha;
if (alpha < 0.0F) LOGE("ERROR detected when initialize plugin");
}
CustomLeakyReLUPlugin::CustomLeakyReLUPlugin(const std::string &name, const void* buffer, size_t length):
mName(name)
{
memcpy(&mParams, buffer, sizeof(mParams));
}
CustomLeakyReLUPlugin::~CustomLeakyReLUPlugin()
{
return;
}
const char* CustomLeakyReLUPlugin::getPluginType() const noexcept
{
return PLUGIN_NAME;
}
const char* CustomLeakyReLUPlugin::getPluginVersion() const noexcept
{
return PLUGIN_VERSION;
}
int32_t CustomLeakyReLUPlugin::getNbOutputs() const noexcept
{
return 1;
}
size_t CustomLeakyReLUPlugin::getSerializationSize() const noexcept
{
return sizeof(mParams);
}
const char* CustomLeakyReLUPlugin::getPluginNamespace() const noexcept
{
return mNamespace.c_str();
}
DataType CustomLeakyReLUPlugin::getOutputDataType(int32_t index, DataType const* inputTypes, int32_t nbInputs) const noexcept
{
return inputTypes[0];
}
DimsExprs CustomLeakyReLUPlugin::getOutputDimensions(int32_t outputIndex, const DimsExprs* inputs, int32_t nbInputs, IExprBuilder &exprBuilder) noexcept
{
return inputs[0];
}
size_t CustomLeakyReLUPlugin::getWorkspaceSize(const PluginTensorDesc *inputs, int32_t nbInputs, const PluginTensorDesc *outputs, int32_t nbOutputs) const noexcept
{
return 0;
}
int32_t CustomLeakyReLUPlugin::initialize() noexcept
{
return 0;
}
void CustomLeakyReLUPlugin::terminate() noexcept
{
return;
}
void CustomLeakyReLUPlugin::serialize(void *buffer) const noexcept
{
memcpy(buffer, &mParams, sizeof(mParams));
return;
}
void CustomLeakyReLUPlugin::destroy() noexcept
{
delete this;
return;
}
int32_t CustomLeakyReLUPlugin::enqueue(
const PluginTensorDesc* inputDesc, const PluginTensorDesc* outputDesc,
const void* const* inputs, void* const* outputs,
void* workspace, cudaStream_t stream) noexcept
{
int nElements = 1;
for (int i = 0; i < inputDesc[0].dims.nbDims; i++){
nElements *= inputDesc[0].dims.d[i];
}
customLeakyReLUImpl(
static_cast<const float*>(inputs[0]),
static_cast<float*>(outputs[0]),
mParams.alpha,
nElements,
stream);
return 0;
}
IPluginV2DynamicExt* CustomLeakyReLUPlugin::clone() const noexcept
{
try{
auto p = new CustomLeakyReLUPlugin(mName, &mParams, sizeof(mParams));
p->setPluginNamespace(mNamespace.c_str());
return p;
}
catch (std::exception const &e){
LOGE("ERROR detected when clone plugin: %s", e.what());
}
return nullptr;
}
bool CustomLeakyReLUPlugin::supportsFormatCombination(int32_t pos, const PluginTensorDesc* inOut, int32_t nbInputs, int32_t nbOutputs) noexcept
{
switch (pos) {
case 0:
return inOut[0].type == DataType::kFLOAT && inOut[0].format == TensorFormat::kLINEAR;
case 1:
return inOut[1].type == DataType::kFLOAT && inOut[1].format == TensorFormat::kLINEAR;
default:
return false;
}
return false;
}
void CustomLeakyReLUPlugin::configurePlugin(const DynamicPluginTensorDesc* in, int32_t nbInputs, const DynamicPluginTensorDesc* out, int32_t nbOutputs) noexcept
{
return;
}
void CustomLeakyReLUPlugin::setPluginNamespace(const char* pluginNamespace) noexcept
{
mNamespace = pluginNamespace;
return;
}
void CustomLeakyReLUPlugin::attachToContext(cudnnContext* contextCudnn, cublasContext* contextCublas, IGpuAllocator *gpuAllocator) noexcept
{
return;
}
void CustomLeakyReLUPlugin::detachFromContext() noexcept
{
return;
}
/******************************************************************/
/*********************CustomLeakyReLUPluginCreator部分********************/
/******************************************************************/
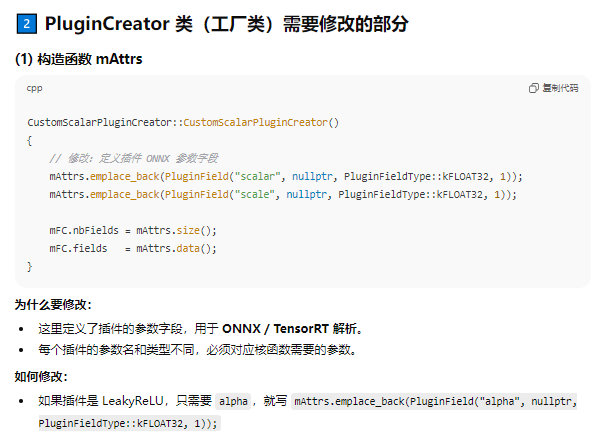
CustomLeakyReLUPluginCreator::CustomLeakyReLUPluginCreator()
{
mAttrs.emplace_back(PluginField("alpha", nullptr, PluginFieldType::kFLOAT32, 1));
mFC.nbFields = mAttrs.size();
mFC.fields = mAttrs.data();
}
CustomLeakyReLUPluginCreator::~CustomLeakyReLUPluginCreator()
{
}
const char* CustomLeakyReLUPluginCreator::getPluginName() const noexcept
{
return PLUGIN_NAME;
}
const char* CustomLeakyReLUPluginCreator::getPluginVersion() const noexcept
{
return PLUGIN_VERSION;
}
const char* CustomLeakyReLUPluginCreator::getPluginNamespace() const noexcept
{
return mNamespace.c_str();
}
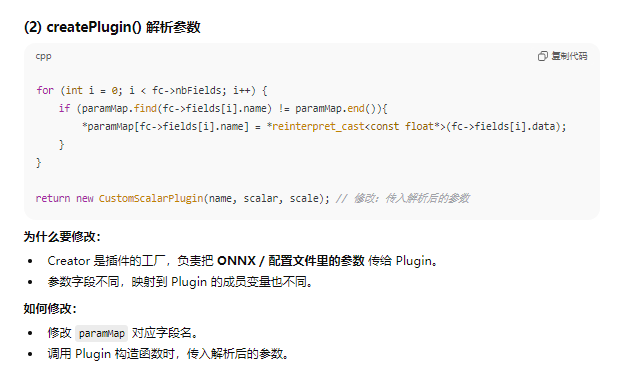
IPluginV2* CustomLeakyReLUPluginCreator::createPlugin(const char* name, const PluginFieldCollection* fc) noexcept
{
try{
float alpha = 0;
std::map<std::string, float*> paramMap = {{"alpha", &alpha}};
for (int i = 0; i < fc->nbFields; i++) {
if (paramMap.find(fc->fields[i].name) != paramMap.end()){
*paramMap[fc->fields[i].name] = *reinterpret_cast<const float*>(fc->fields[i].data);
}
}
return new CustomLeakyReLUPlugin(name, alpha);
}
catch (std::exception const &e){
LOGE("ERROR detected when create plugin: %s", e.what());
}
return nullptr;
}
IPluginV2* CustomLeakyReLUPluginCreator::deserializePlugin(const char* name, const void* serialData, size_t serialLength) noexcept
{
try{
return new CustomLeakyReLUPlugin(name, serialData, serialLength);
}
catch (std::exception const &e){
LOGE("ERROR detected when deserialize plugin: %s", e.what());
}
return nullptr;
}
void CustomLeakyReLUPluginCreator::setPluginNamespace(const char* pluginNamespace) noexcept
{
mNamespace = pluginNamespace;
return;
}
const PluginFieldCollection* CustomLeakyReLUPluginCreator::getFieldNames() noexcept
{
return &mFC;
}
} // namespace custom






















 2266
2266

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









