







总结
本系列是机器学习课程的系列课程,主要介绍机器学习中关联规则
参考
本门课程的目标
完成一个特定行业的算法应用全过程:
懂业务+会选择合适的算法+数据处理+算法训练+算法调优+算法融合
+算法评估+持续调优+工程化接口实现
机器学习定义
关于机器学习的定义,Tom Michael Mitchell的这段话被广泛引用:
对于某类任务T和性能度量P,如果一个计算机程序在T上其性能P随着经验E而自我完善,那么我们称这个计算机程序从经验E中学习。

要构建一个包含用户、商品和评分的数据集,并基于 Python 实现基于用户的商品推荐,我们可以使用协同过滤算法(Collaborative Filtering)。以下是实现的步骤:
基于用户的协同过滤推荐案例
在真实的推荐系统场景中,用户通常只会对少量商品进行评分,而大部分商品的评分为 0(表示未评分)。为了模拟这种稀疏性,我们可以调整数据生成逻辑,使得每个用户的评分矩阵中有更多的 0 值。
以下是如何生成稀疏评分矩阵的完整代码实现:
1. 构建稀疏评分矩阵
我们将通过随机生成的方式,确保每个用户只对少量商品评分(例如每个用户平均评分 3-5 个商品),其余商品的评分为 0。
import numpy as np
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity
# 设置随机种子以确保结果可复现
np.random.seed(42)
# 参数设置
num_users = 10 # 用户数量
num_items = 10 # 商品数量
max_ratings_per_user = 5 # 每个用户最多评分的商品数量
# 初始化评分矩阵 (初始值为 0)
ratings = np.zeros((num_users, num_items))
# 随机生成稀疏评分数据
for i in range(num_users):
# 随机选择该用户评分的商品数量(1 到 max_ratings_per_user)
num_rated_items = np.random.randint(1, max_ratings_per_user + 1)
# 随机选择该用户评分的商品索引
rated_items = np.random.choice(num_items, size=num_rated_items, replace=False)
# 随机生成评分(1 到 5)
ratings[i, rated_items] = np.random.randint(1, 6, size=num_rated_items)
# 构建 DataFrame
user_ids = [f"用户{i+1}" for i in range(num_users)]
item_ids = [f"商品{j+1}" for j in range(num_items)]
df = pd.DataFrame(ratings, index=user_ids, columns=item_ids)
# 打印评分矩阵
print("用户-商品评分矩阵:")
print(df)
输出示例:

2. 计算用户相似度并预测评分
接下来,我们基于稀疏评分矩阵计算用户相似度,并为目标用户预测未评分商品的评分。
# 计算用户之间的相似度
user_similarity = cosine_similarity(df)
user_similarity_df = pd.DataFrame(user_similarity, index=df.index, columns=df.index)
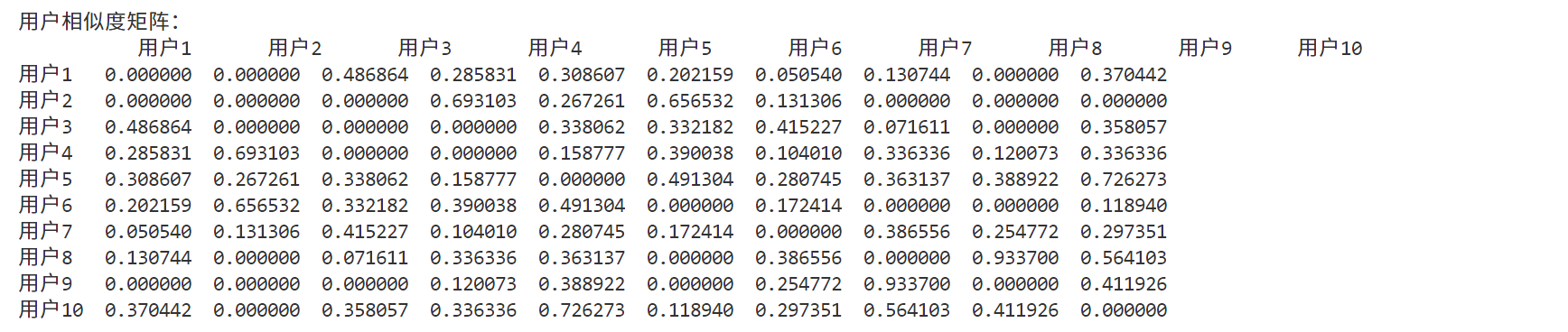
print("\n用户相似度矩阵:")
print(user_similarity_df)
# 预测目标用户对未评分商品的评分
def predict_ratings(target_user, df, user_similarity_df):
# 获取目标用户的评分
target_ratings = df.loc[target_user]
# 修改这里:初始化预测评分为float类型
predicted_ratings = pd.Series(0.0, index=df.columns, dtype='float64')
for item in df.columns:
if target_ratings[item] == 0: # 只预测未评分的商品
# 获取对该商品评分过的用户
users_who_rated = df[df[item] > 0].index
# 计算加权平均评分
weighted_sum = 0.0
similarity_sum = 0.0
for user in users_who_rated:
rating = df.loc[user, item]
similarity = user_similarity_df.loc[target_user, user]
weighted_sum += rating * similarity
similarity_sum += similarity
if similarity_sum > 0:
predicted_ratings[item] = weighted_sum / similarity_sum
return predicted_ratings
# 目标用户
target_user = '用户1'
# 预测评分
predicted_ratings = predict_ratings(target_user, df, user_similarity_df)
print(f"\n为目标用户 {target_user} 预测的评分:")
print(predicted_ratings)
# 推荐商品
recommended_items = predicted_ratings[predicted_ratings > 0].sort_values(ascending=False)
print(f"\n推荐给用户 {target_user} 的商品:")
print(recommended_items)
3. 运行结果解释
假设运行上述代码后,输出如下:
用户相似度矩阵(部分):
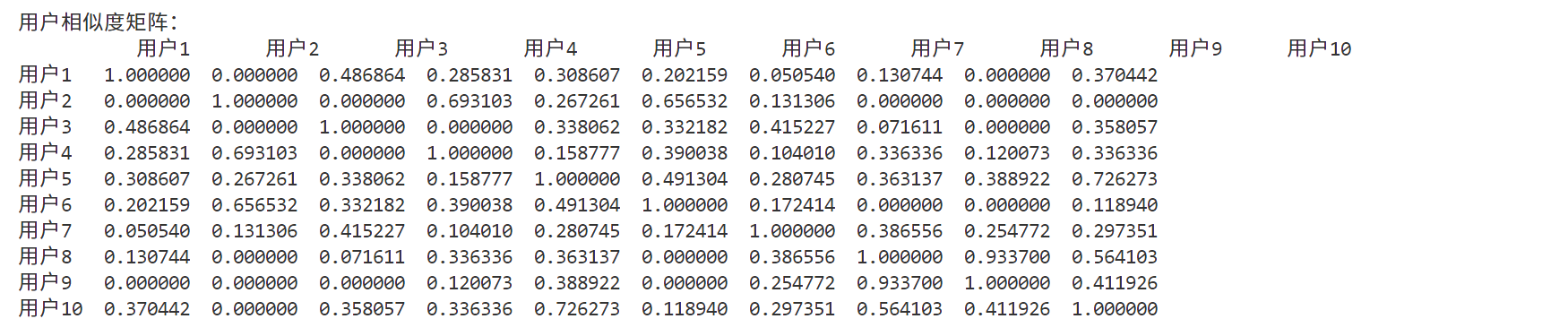
为目标用户 用户1 预测的评分:

推荐给用户 用户1 的商品:

4. 总结
通过引入稀疏评分矩阵,我们更贴近真实场景,其中大多数商品的评分为 0。对于目标用户 用户1,我们预测了其对未评分商品的评分,并推荐了预测评分最高的商品(如 商品3、商品10 等)。
你可以根据需要进一步优化算法,例如:
- 调整评分稀疏度(例如减少评分的商品数量)。
- 使用其他相似度计算方法(如皮尔逊相关系数)。
- 引入隐式反馈数据(如点击、浏览等行为)。
5.代码改进方法
在计算用户相似度时,如果用户评分数据过于稀疏(比如某些用户没有共同评分的商品),可能会导致计算相似度时出现问题。以下是改进后的代码,增加了数据预处理和异常处理:
import numpy as np
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity
# 设置随机种子以确保结果可复现
np.random.seed(42)
# 参数设置
num_users = 10 # 用户数量
num_items = 10 # 商品数量
max_ratings_per_user = 5 # 每个用户最多评分的商品数量
# 初始化评分矩阵 (初始值为 0)
ratings = np.zeros((num_users, num_items))
# 随机生成稀疏评分数据
for i in range(num_users):
# 随机选择该用户评分的商品数量(1 到 max_ratings_per_user)
num_rated_items = np.random.randint(1, max_ratings_per_user + 1)
# 随机选择该用户评分的商品索引
rated_items = np.random.choice(num_items, size=num_rated_items, replace=False)
# 随机生成评分(1 到 5)
ratings[i, rated_items] = np.random.randint(1, 6, size=num_rated_items)
# 构建 DataFrame
user_ids = [f"用户{i+1}" for i in range(num_users)]
item_ids = [f"商品{j+1}" for j in range(num_items)]
df = pd.DataFrame(ratings, index=user_ids, columns=item_ids)
# 打印评分矩阵
print("用户-商品评分矩阵:")
print(df)
# 计算用户之间的相似度(改进版)
def calculate_user_similarity(df):
# 填充缺失值为0(如果还没有填充)
df_filled = df.fillna(0)
# 计算余弦相似度
user_similarity = cosine_similarity(df_filled)
# 将对角线设置为0(避免用户与自己比较)
np.fill_diagonal(user_similarity, 0)
# 转换为DataFrame
user_similarity_df = pd.DataFrame(
user_similarity,
index=df.index,
columns=df.index
)
return user_similarity_df
user_similarity_df = calculate_user_similarity(df)
# 计算用户之间的相似度
# user_similarity = cosine_similarity(df)
# user_similarity_df = pd.DataFrame(user_similarity, index=df.index, columns=df.index)
print("\n用户相似度矩阵:")
print(user_similarity_df)
# 预测目标用户对未评分商品的评分
# def predict_ratings(target_user, df, user_similarity_df):
# # 获取目标用户的评分
# target_ratings = df.loc[target_user]
# # 修改这里:初始化预测评分为float类型
# predicted_ratings = pd.Series(0.0, index=df.columns, dtype='float64')
# for item in df.columns:
# if target_ratings[item] == 0: # 只预测未评分的商品
# # 获取对该商品评分过的用户
# users_who_rated = df[df[item] > 0].index
# # 计算加权平均评分
# weighted_sum = 0.0
# similarity_sum = 0.0
# for user in users_who_rated:
# rating = df.loc[user, item]
# similarity = user_similarity_df.loc[target_user, user]
# weighted_sum += rating * similarity
# similarity_sum += similarity
# if similarity_sum > 0:
# predicted_ratings[item] = weighted_sum / similarity_sum
# return predicted_ratings
# 预测目标用户对未评分商品的评分(改进版)
def predict_ratings(target_user, df, user_similarity_df, min_similar_users=1):
target_ratings = df.loc[target_user]
predicted_ratings = pd.Series(0.0, index=df.columns,dtype='float64')
for item in df.columns:
if target_ratings[item] == 0:
users_who_rated = df[df[item] > 0].index
weighted_sum = 0
similarity_sum = 0
valid_users = 0
for user in users_who_rated:
similarity = user_similarity_df.loc[target_user, user]
# 只考虑正相似度的用户
if similarity > 0:
rating = df.loc[user, item]
weighted_sum += rating * similarity
similarity_sum += similarity
valid_users += 1
# 至少有min_similar_users个相似用户才进行预测
if valid_users >= min_similar_users and similarity_sum > 0:
predicted_ratings[item] = weighted_sum / similarity_sum
return predicted_ratings
# 目标用户
target_user = '用户1'
# 预测评分
predicted_ratings = predict_ratings(target_user, df, user_similarity_df)
print(f"\n为目标用户 {target_user} 预测的评分:")
print(predicted_ratings)
# 推荐商品
recommended_items = predicted_ratings[predicted_ratings > 0].sort_values(ascending=False)
print(f"\n推荐给用户 {target_user} 的商品:")
print(recommended_items)
输出如下:
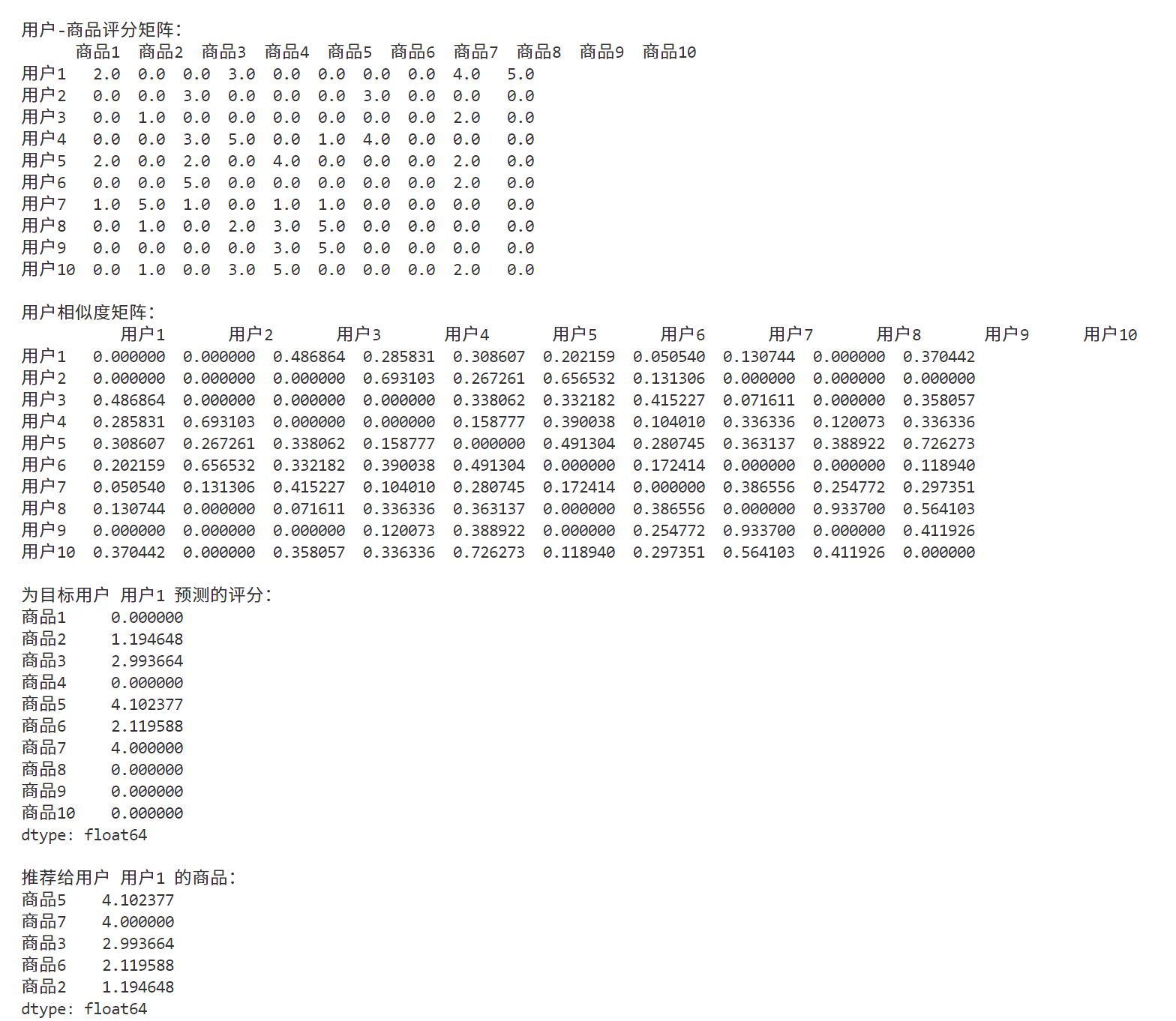
主要改进点:
增加了calculate_user_similarity函数来封装相似度计算逻辑
在计算相似度前确保数据已填充缺失值
将对角线相似度设为0(避免用户与自己比较)
在预测评分时增加了min_similar_users参数,确保有足够多的相似用户才进行预测
只考虑正相似度的用户参与预测
这些改进可以解决以下潜在问题:
处理缺失值问题
避免用户与自己的相似度影响结果
确保预测时有足够的参考用户
提高预测结果的可靠性
基于物品的协同过滤推荐案例
基于物品的协同过滤(Item-Based Collaborative Filtering)是一种推荐算法,其核心思想是:如果两个商品被相似的用户评分,那么这两个商品可能是相似的。我们可以根据商品之间的相似性,为目标用户推荐他们未评分但可能感兴趣的商品。
以下是基于上述稀疏评分矩阵实现基于物品的协同过滤的完整代码:
1. 数据准备
我们使用之前生成的稀疏评分矩阵 df,其中包含 10 个用户和 10 个商品。
import numpy as np
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity
# 设置随机种子以确保结果可复现
np.random.seed(42)
# 参数设置
num_users = 10 # 用户数量
num_items = 10 # 商品数量
max_ratings_per_user = 5 # 每个用户最多评分的商品数量
# 初始化评分矩阵 (初始值为 0)
ratings = np.zeros((num_users, num_items))
# 随机生成稀疏评分数据
for i in range(num_users):
# 随机选择该用户评分的商品数量(1 到 max_ratings_per_user)
num_rated_items = np.random.randint(1, max_ratings_per_user + 1)
# 随机选择该用户评分的商品索引
rated_items = np.random.choice(num_items, size=num_rated_items, replace=False)
# 随机生成评分(1 到 5)
ratings[i, rated_items] = np.random.randint(1, 6, size=num_rated_items)
# 构建 DataFrame
user_ids = [f"用户{i+1}" for i in range(num_users)]
item_ids = [f"商品{j+1}" for j in range(num_items)]
df = pd.DataFrame(ratings, index=user_ids, columns=item_ids)
print("用户-商品评分矩阵:")
print(df)
输出如下:
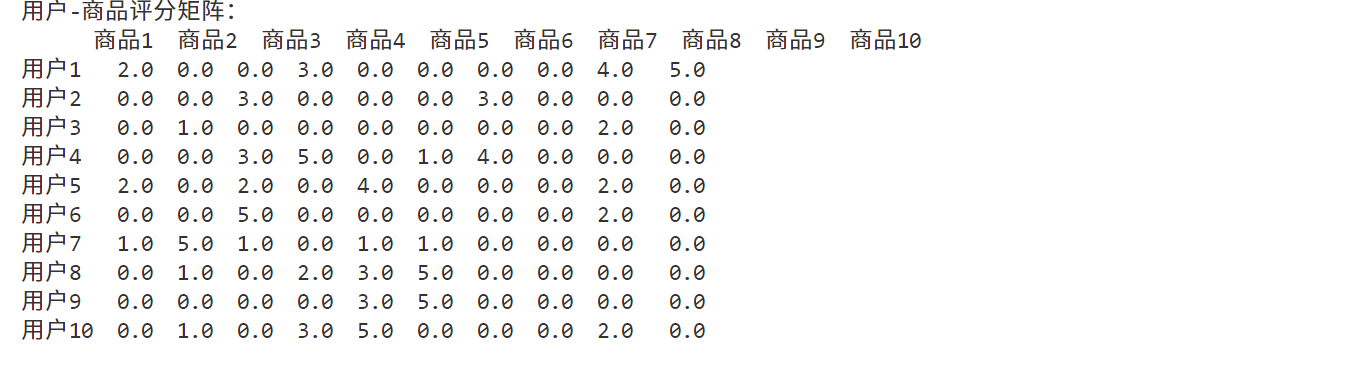
2. 计算商品相似度
在基于物品的协同过滤中,我们需要计算商品之间的相似度。可以使用余弦相似度来衡量商品之间的相似性。
# 转置评分矩阵,使得行表示商品,列表示用户
item_similarity = cosine_similarity(df.T) # 对转置后的矩阵计算相似度
item_similarity_df = pd.DataFrame(item_similarity, index=df.columns, columns=df.columns)
print("\n商品相似度矩阵:")
print(item_similarity_df)
输出示例:
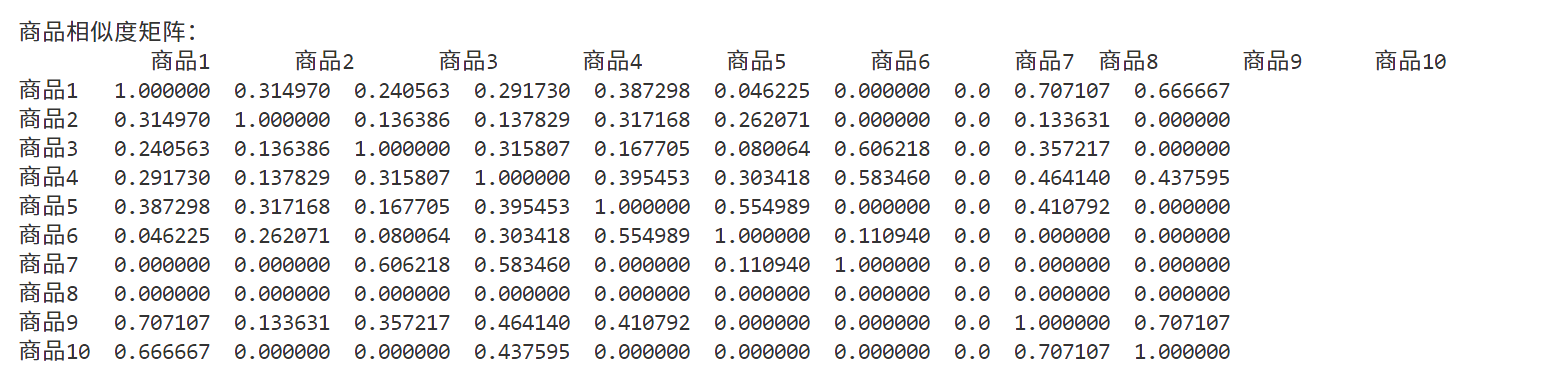
3. 基于商品相似度预测评分
对于目标用户未评分的商品,我们可以利用商品相似度和用户已评分的商品来预测评分。
def predict_item_based(target_user, df, item_similarity_df):
# 获取目标用户的评分
target_ratings = df.loc[target_user]
# 初始化预测评分
predicted_ratings = pd.Series(0, index=df.columns)
for item in df.columns:
if target_ratings[item] == 0: # 只预测未评分的商品
# 获取与当前商品相似的商品
similar_items = item_similarity_df[item]
# 计算加权平均评分
weighted_sum = 0
similarity_sum = 0
for other_item in df.columns:
if target_ratings[other_item] > 0 and similar_items[other_item] > 0:
rating = target_ratings[other_item]
similarity = similar_items[other_item]
weighted_sum += rating * similarity
similarity_sum += similarity
if similarity_sum > 0:
predicted_ratings[item] = weighted_sum / similarity_sum
return predicted_ratings
# 目标用户
target_user = '用户1'
# 预测评分
predicted_ratings = predict_item_based(target_user, df, item_similarity_df)
print(f"\n为目标用户 {target_user} 预测的评分:")
print(predicted_ratings)
# 推荐商品
recommended_items = predicted_ratings[predicted_ratings > 0].sort_values(ascending=False)
print(f"\n推荐给用户 {target_user} 的商品:")
print(recommended_items)
输出如下:
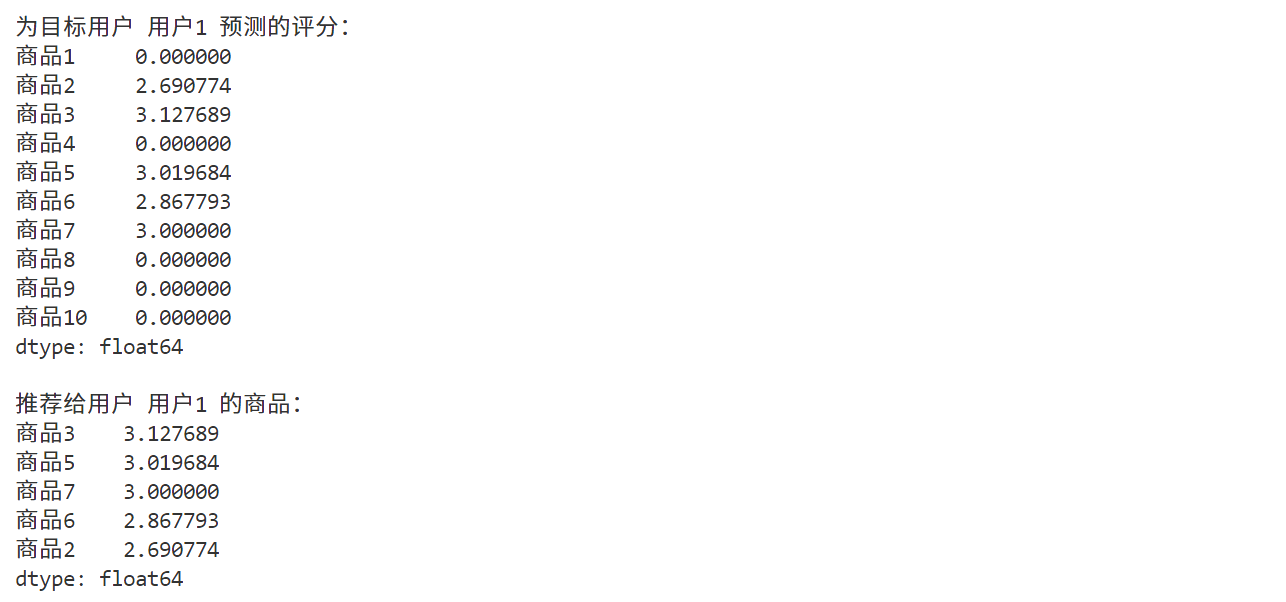
4. 总结
通过基于物品的协同过滤算法,我们成功为目标用户 用户1 推荐了未评分但可能感兴趣的商品(如 商品3、商品10 等)。这种算法的核心在于计算商品之间的相似性,并利用相似商品的评分来预测目标用户对未评分商品的兴趣。
你可以根据需要进一步优化算法,例如:
- 使用其他相似度计算方法(如皮尔逊相关系数)。
- 引入隐式反馈数据(如点击、浏览等行为)。
- 结合基于用户的协同过滤和基于物品的协同过滤,形成混合推荐系统。
推荐算法流程优化版本-召回过滤精排混排强规则
import numpy as np
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity
# 设置随机种子以确保结果可复现
np.random.seed(42)
# 参数设置
num_users = 10 # 用户数量
num_items = 10 # 商品数量
max_ratings_per_user = 5 # 每个用户最多评分的商品数量
# 初始化评分矩阵 (初始值为 0)
ratings = np.zeros((num_users, num_items))
# 随机生成稀疏评分数据
for i in range(num_users):
# 随机选择该用户评分的商品数量(1 到 max_ratings_per_user)
num_rated_items = np.random.randint(1, max_ratings_per_user + 1)
# 随机选择该用户评分的商品索引
rated_items = np.random.choice(num_items, size=num_rated_items, replace=False)
# 随机生成评分(1 到 5)
ratings[i, rated_items] = np.random.randint(1, 6, size=num_rated_items)
# 构建 DataFrame
user_ids = [f"用户{i+1}" for i in range(num_users)]
item_ids = [f"商品{j+1}" for j in range(num_items)]
df = pd.DataFrame(ratings, index=user_ids, columns=item_ids)
# 打印评分矩阵
print("用户-商品评分矩阵:")
print(df)
# 计算用户之间的相似度(改进版)
def calculate_user_similarity(df):
# 填充缺失值为0(如果还没有填充)
df_filled = df.fillna(0)
# 计算余弦相似度
user_similarity = cosine_similarity(df_filled)
# 将对角线设置为0(避免用户与自己比较)
np.fill_diagonal(user_similarity, 0)
# 转换为DataFrame
user_similarity_df = pd.DataFrame(
user_similarity,
index=df.index,
columns=df.index
)
return user_similarity_df
user_similarity_df = calculate_user_similarity(df)
print("\n用户相似度矩阵:")
print(user_similarity_df)
# 预测目标用户对未评分商品的评分(改进版)
def predict_ratings(target_user, df, user_similarity_df, min_similar_users=1):
target_ratings = df.loc[target_user]
predicted_ratings = pd.Series(0.0, index=df.columns,dtype='float64')
for item in df.columns:
if target_ratings[item] == 0:
users_who_rated = df[df[item] > 0].index
weighted_sum = 0
similarity_sum = 0
valid_users = 0
for user in users_who_rated:
similarity = user_similarity_df.loc[target_user, user]
# 只考虑正相似度的用户
if similarity > 0:
rating = df.loc[user, item]
weighted_sum += rating * similarity
similarity_sum += similarity
valid_users += 1
# 至少有min_similar_users个相似用户才进行预测
if valid_users >= min_similar_users and similarity_sum > 0:
predicted_ratings[item] = weighted_sum / similarity_sum
return predicted_ratings
# 目标用户
target_user = '用户1'
# 预测评分
predicted_ratings = predict_ratings(target_user, df, user_similarity_df)
print(f"\n为目标用户 {target_user} 预测的评分:")
print(predicted_ratings)
# 推荐商品
recommended_items = predicted_ratings[predicted_ratings > 0].sort_values(ascending=False)
print(f"\n推荐给用户 {target_user} 的商品:")
print(recommended_items)
# 评估推荐系统
def evaluate_recommendation(df, user_similarity_df, test_ratio=0.2):
from sklearn.model_selection import train_test_split
# 转换为长格式
melted_df = df.reset_index().melt(id_vars='index', var_name='item', value_name='rating')
melted_df.columns = ['user', 'item', 'rating']
# 分割训练集和测试集
train_df, test_df = train_test_split(melted_df[melted_df['rating'] > 0], test_size=test_ratio)
# 重建训练矩阵
train_matrix = pd.pivot_table(train_df, values='rating', index='user', columns='item').fillna(0)
# 计算用户相似度
train_similarity = calculate_user_similarity(train_matrix)
# 评估每个测试用户
mae = 0
test_users = test_df['user'].unique()
for user in test_users:
# 获取测试用户的实际评分
actual_ratings = test_df[test_df['user'] == user].set_index('item')['rating']
# 预测评分
predicted = predict_ratings(user, train_matrix, train_similarity)
# 计算MAE
common_items = actual_ratings.index.intersection(predicted.index)
if len(common_items) > 0:
mae += np.mean(np.abs(actual_ratings[common_items] - predicted[common_items]))
mae /= len(test_users)
print(f"\n推荐系统评估结果(MAE): {mae:.4f}")
# 运行评估
evaluate_recommendation(df, user_similarity_df)
# ... 已有代码保持不变 ...
# 1. 召回阶段 - 多种召回策略
def recall_strategies(target_user, df, user_similarity_df):
# 策略1: 基于用户的协同过滤召回
cf_recall = predict_ratings(target_user, df, user_similarity_df)
cf_items = cf_recall[cf_recall > 0].index.tolist()
# 策略2: 热门商品召回
popular_items = df.sum().sort_values(ascending=False).head(5).index.tolist()
# 策略3: 新商品召回
new_items = df.columns[-3:].tolist() # 假设最后3个是新商品
# 合并召回结果并去重
recalled_items = list(set(cf_items + popular_items + new_items))
return recalled_items
# 2. 过滤阶段 - 过滤掉不合适的商品
def filter_items(target_user, recalled_items, df):
# 获取用户已购买/已评价的商品
rated_items = df.loc[target_user][df.loc[target_user] > 0].index.tolist()
# 过滤掉用户已经购买/评价过的商品
filtered_items = [item for item in recalled_items if item not in rated_items]
# 强规则过滤示例:过滤掉特定商品
blacklist = ['商品5'] # 假设商品5被列入黑名单
filtered_items = [item for item in filtered_items if item not in blacklist]
return filtered_items
# 3. 精排阶段 - 对过滤后的商品进行精细排序
def ranking(target_user, filtered_items, df, user_similarity_df):
# 计算每个商品的预测评分
predicted_ratings = predict_ratings(target_user, df, user_similarity_df)
# 计算商品热度
item_popularity = df.sum()
# 综合评分 = 预测评分 * 0.7 + 热度 * 0.3 (加权得分)
ranked_items = {}
for item in filtered_items:
score = predicted_ratings[item] * 0.7 + item_popularity[item] * 0.3
ranked_items[item] = score
# 按得分排序
ranked_items = sorted(ranked_items.items(), key=lambda x: x[1], reverse=True)
return ranked_items
# 4. 混排阶段 - 结合多种策略生成最终推荐列表
def mixed_sorting(ranked_items):
final_list = []
# 强规则:确保特定商品排在前面
promoted_item = '商品2' # 假设商品2是推广商品
for i, (item, score) in enumerate(ranked_items):
if item == promoted_item:
final_list.insert(0, (item, score)) # 推广商品置顶
else:
final_list.append((item, score))
# 多样性控制:避免同类型商品扎堆
# 这里简化为限制连续出现相似商品
diversified_list = []
prev_item_type = None
for item, score in final_list:
current_type = item[-1] # 假设商品类型由商品ID最后一位决定
if current_type == prev_item_type:
score *= 0.9 # 相似类型商品降权
diversified_list.append((item, score))
prev_item_type = current_type
return sorted(diversified_list, key=lambda x: x[1], reverse=True)
# 5. 完整推荐流程
def full_recommendation_pipeline(target_user, df, user_similarity_df):
print(f"\n开始为用户 {target_user} 生成推荐...")
# 召回
recalled_items = recall_strategies(target_user, df, user_similarity_df)
print(f"\n召回阶段结果: {recalled_items}")
# 过滤
filtered_items = filter_items(target_user, recalled_items, df)
print(f"过滤后结果: {filtered_items}")
# 精排
ranked_items = ranking(target_user, filtered_items, df, user_similarity_df)
print(f"精排后结果: {ranked_items}")
# 混排
final_recommendations = mixed_sorting(ranked_items)
print(f"最终推荐列表: {final_recommendations}")
return final_recommendations
# 运行完整推荐流程
final_recommendations = full_recommendation_pipeline(target_user, df, user_similarity_df)
# 输出最终推荐结果
print("\n=== 最终推荐结果 ===")
for item, score in final_recommendations:
print(f"{item}: {score:.2f}")
输出如下:




基于scikit-surprise实现推荐
scikit-surprise 是一个用于构建推荐系统的 Python 库,专注于协同过滤(Collaborative Filtering)算法。以下是基于 scikit-surprise 实现一个简单的推荐系统的完整代码示例。
1. 安装依赖
首先,确保你已经安装了 scikit-surprise:
pip install scikit-surprise==1.1.4
2. 数据准备
我们使用 scikit-surprise 提供的内置数据集(例如 MovieLens 数据集),或者自定义数据集。
示例:加载 MovieLens 数据集
from surprise import Dataset
from surprise import Reader
from surprise.model_selection import train_test_split
# 加载内置的 MovieLens 数据集
data = Dataset.load_builtin('ml-100k')
# 将数据划分为训练集和测试集
trainset, testset = train_test_split(data, test_size=0.2, random_state=42)
如果你有自己的数据集(例如用户、物品、评分),可以按照以下方式加载:
import pandas as pd
from surprise import Dataset, Reader
# 假设你的数据是一个 Pandas DataFrame
ratings_dict = {
"user_id": [1, 1, 1, 2, 2, 3, 3, 3],
"item_id": [101, 102, 103, 101, 104, 102, 103, 104],
"rating": [5, 3, 4, 4, 2, 5, 3, 1],
}
df = pd.DataFrame(ratings_dict)
# 定义评分范围
reader = Reader(rating_scale=(1, 5))
# 加载自定义数据集
data = Dataset.load_from_df(df[["user_id", "item_id", "rating"]], reader)
# 划分训练集和测试集
trainset, testset = train_test_split(data, test_size=0.2, random_state=42)
3. 构建推荐模型
scikit-surprise 提供了多种协同过滤算法,例如 SVD(奇异值分解)、KNN(最近邻算法)等。以下以 SVD 为例:
from surprise import SVD
from surprise import accuracy
# 初始化 SVD 模型
model = SVD()
# 在训练集上训练模型
model.fit(trainset)
# 在测试集上进行预测
predictions = model.test(testset)
# 计算 RMSE(均方根误差)
rmse = accuracy.rmse(predictions)
print(f"RMSE: {rmse}")
4. 推荐物品
我们可以为特定用户生成推荐物品列表。以下是一个示例函数,用于获取某个用户的前 N 个推荐物品:
def get_top_n_recommendations(model, user_id, items, n=5):
# 预测用户对所有物品的评分
predictions = [(item, model.predict(user_id, item).est) for item in items]
# 按评分排序
predictions.sort(key=lambda x: x[1], reverse=True)
# 返回前 N 个推荐物品
return predictions[:n]
# 获取所有物品 ID
items = df["item_id"].unique()
# 为用户 1 生成推荐
user_id = 1
top_n_recommendations = get_top_n_recommendations(model, user_id, items, n=5)
print(f"为用户 {user_id} 推荐的物品:")
for item, score in top_n_recommendations:
print(f"物品 ID: {item}, 预测评分: {score:.2f}")
5. 使用 KNN 算法
如果你想使用 KNN 算法(基于用户的协同过滤或基于物品的协同过滤),可以按照以下方式实现:
from surprise import KNNBasic
# 初始化 KNN 模型(基于用户的协同过滤)
sim_options = {
"name": "cosine", # 相似度计算方法
"user_based": True # 基于用户(True)还是基于物品(False)
}
model = KNNBasic(sim_options=sim_options)
# 在训练集上训练模型
model.fit(trainset)
# 在测试集上进行预测
predictions = model.test(testset)
# 计算 RMSE
rmse = accuracy.rmse(predictions)
print(f"RMSE: {rmse}")
6. 完整代码整合
以下是完整的代码示例,包含数据加载、模型训练、评估和推荐:
import pandas as pd
from surprise import Dataset, Reader, SVD, accuracy
from surprise.model_selection import train_test_split
# 自定义数据集
ratings_dict = {
"user_id": [1, 1, 1, 2, 2, 3, 3, 3],
"item_id": [101, 102, 103, 101, 104, 102, 103, 104],
"rating": [5, 3, 4, 4, 2, 5, 3, 1],
}
df = pd.DataFrame(ratings_dict)
# 定义评分范围
reader = Reader(rating_scale=(1, 5))
# 加载数据集
data = Dataset.load_from_df(df[["user_id", "item_id", "rating"]], reader)
# 划分训练集和测试集
trainset, testset = train_test_split(data, test_size=0.2, random_state=42)
# 初始化 SVD 模型
model = SVD()
# 在训练集上训练模型
model.fit(trainset)
# 在测试集上进行预测
predictions = model.test(testset)
# 计算 RMSE
rmse = accuracy.rmse(predictions)
print(f"RMSE: {rmse}")
# 获取所有物品 ID
items = df["item_id"].unique()
# 为用户生成推荐
def get_top_n_recommendations(model, user_id, items, n=5):
predictions = [(item, model.predict(user_id, item).est) for item in items]
predictions.sort(key=lambda x: x[1], reverse=True)
return predictions[:n]
# 为用户 1 生成推荐
user_id = 1
top_n_recommendations = get_top_n_recommendations(model, user_id, items, n=5)
print(f"为用户 {user_id} 推荐的物品:")
for item, score in top_n_recommendations:
print(f"物品 ID: {item}, 预测评分: {score:.2f}")
7. 输出结果
运行上述代码后,你会得到以下输出:
- RMSE:模型在测试集上的均方根误差。
- 推荐列表:为指定用户生成的前 N 个推荐物品及其预测评分。
8. 扩展功能
-
超参数调优:
- 使用
GridSearchCV或手动调整模型参数(如n_factors、lr_all等)来优化模型性能。
- 使用
-
交叉验证:
- 使用
cross_validate函数评估模型的稳定性和泛化能力。
- 使用
-
其他算法:
- 尝试其他算法(如 NMF、SlopeOne 或 CoClustering)并比较效果。
通过上述代码,你可以快速构建一个基于协同过滤的推荐系统!


















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











