









 本文介绍了TabNet,一种无需预处理的表格数据模型,通过梯度优化与序列注意力机制提升性能。其特有的实例级特征选择和双重视角的可解释性使其在分类和回归任务中表现出色。文章还探讨了模型的结构、编码与解码过程,以及如何通过无监督预训练增强模型效果。
本文介绍了TabNet,一种无需预处理的表格数据模型,通过梯度优化与序列注意力机制提升性能。其特有的实例级特征选择和双重视角的可解释性使其在分类和回归任务中表现出色。文章还探讨了模型的结构、编码与解码过程,以及如何通过无监督预训练增强模型效果。
期刊
AAAI
相关代码
https://github.com/dreamquark-ai/tabnet Pytorch版本(目前star:1.6k)
应用范围
表格数据
贡献
1.TabNet inputs raw tabular data without any preprocessing and is trained using gradient descent-based optimization, enabling flexible integration into end-to-end learning.
2.TabNet uses sequential attention to choose which features to reason from at each decision step, enabling interpretability and better learning as the learning capacity is used for the most salient features. This feature selection is instance-wise, e.g. it can be different for each input, and unlike other instance-wise feature selection, TabNet employs a single deep learning architecture for feature selection and reasoning.
3.Above design choices lead to two valuable properties:
(i)TabNet outperforms or is on par with other tabular learning models on various datasets for classification and regression problems from different domains;
(ii) TabNet enables two kinds of interpretability: local interpretability that visualizes the importance of features and how they are combined, and global interpretability which quantifies the contribution of each feature to the trained model.
4.Finally, for the first time for tabular data, we show significant performance improvements by using unsupervised pre-training to predict masked features .
- 模型可直接使用表格数据,不需要预先处理;使用的基于梯度下降的优化方法,使它能方便地加入端到端(end-to-end)的模型中。
- 在每一个决策时间步,利用序列注意力模型选择重要的特征,学习到最突出的特征,使模型具有可解释性。这是一种基于实例的特征选择(对于每个实例选择的特征不同),且它的特征选择和推理使用同一框架。
- TabNet有两个明显优势,一方面是它在分类和回归中都表现出了比其它模型更优越或者持平的模型效果,另一方面,它具有局部可解释性(特征重要性和组合方法),和全局可解释性(特征对模型的贡献)。
- 对表格数据,使用无监督数据预训练(mask方法),可提高模型性能。
模型
1.作者受决策树判断节点对当前特征进行判断的启发。 下图是一个决策树:

2.TabNet由Encoder和Decoder组成,其中,Encoder包含Feature Transformer和Attentive Transformer,Decoder包含Feature Transformer
3.使用的过程
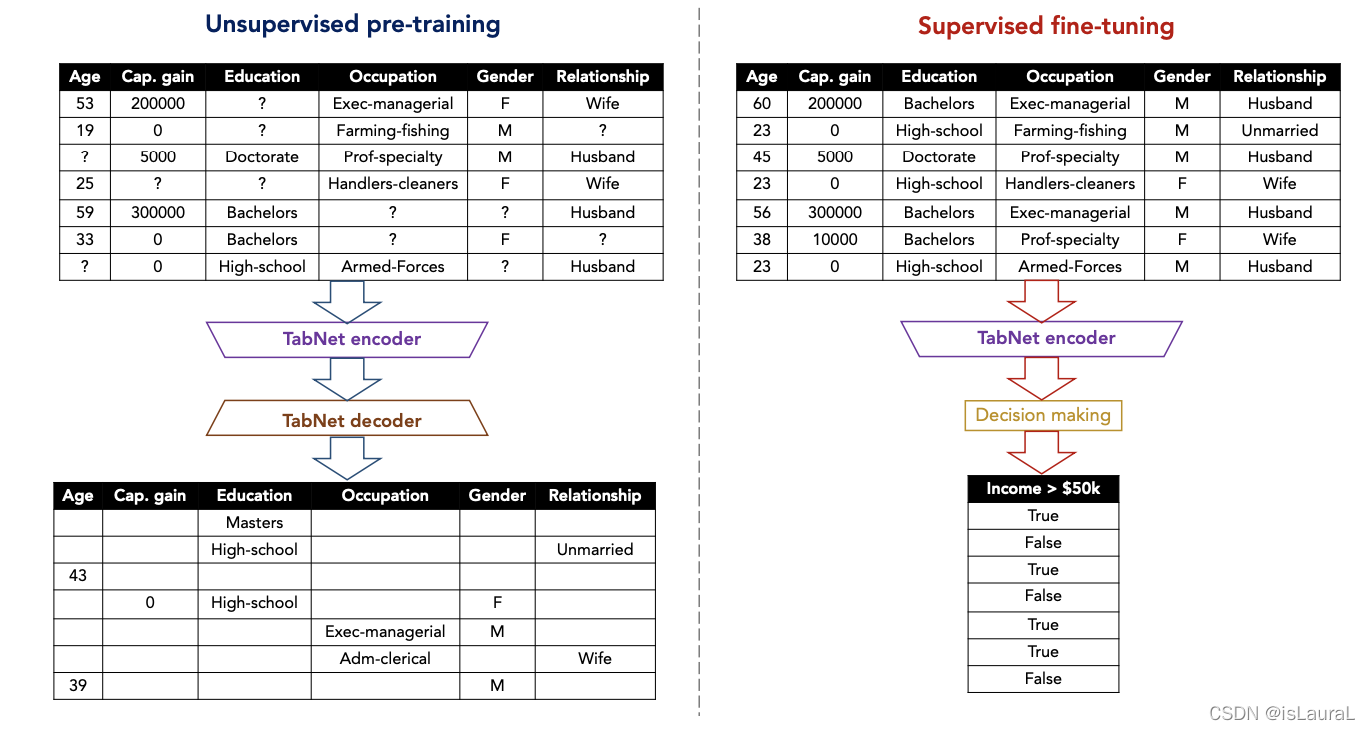
无论是用于填充缺失特征的无监督学习(左),还是用于实际决策的有监督学习(右),都使用编码器TabNet encoder先将输入特征编码;然后根据不同用途分别与decoder连接填充缺失特征,或与全连接层相连实现最终决策。
下面对模型的各个部分进行分析
输入
tab_network.py EmbeddingGenerator类
表格类型的输入数据一般是数值型或者类别型,数据值直接代入模型,而类别型可能涉及N种取值,为简化模型,TabNet使用了可训练的Embedding方式处理类别型数据,即把一个类别型特征转换成几维数值型特征,通过它们的组合来表征,具体实现见EmbeddingGenerator类,它将每个类别型数据映射到数值类型,具体的映射方法通过训练得到。
编码器:TabNet Encoder
1.结构图
其中step相当于是决策树的判断节点,一次选择一组特征(由几个特征组成)

2.输入
a[i-1](红线)和全部特征数据(黑线)
3.输出
a[i](红线)和 d[i](黑线)
4.功能
调用者可设定使用多少个Step(一般是3-10,图中示例为2 step)。每个Step接收数据特征(图中黑线)作为输入,并使用上一步的输出(图中红线)对数据特征加权(决定哪些特征更加重要)。而每一步的输出通过累加的方式用于最终决策。
Feature Transformer
1.结构图

2.结构
Feature Transformer采用了两种不同的模块:Shared across decision steps(整个TabNet Encoder共用一份),Decision step dependent(内部创建,只影响单步)。从图中可以看到,先处理了共用部分,又进一步处理了单步相关模块,使用根号5是为了保证模型稳定(具体怎么保证稳定,不甚了解)。
3.功能
feature processing 特征处理
4.后续的split
将处理完的特征分为两部分,一部分供最终预测使用(黑线),写作d[i],另一部分继续向后传递a[i](红线),供Attentive transformer使用。
Attentive Transformer
1.模型

2.作用
Feature selection
3.输入
a[i-1](encoder中的红线)
4.输出
m[i]
5.实现方式
使用Attentive Transformer,通过之间step对特征的处理过程来获得mask
M
[
i
]
=
s
p
a
r
s
e
m
a
x
(
P
[
i
−
1
]
⋅
h
i
(
a
[
i
−
1
]
)
)
M[i] = sparsemax(P[i-1] \cdot h_i(a[i-1]))
M[i]=sparsemax(P[i−1]⋅hi(a[i−1]))
m[i]:可学习的mask hi(a[i-1])是通过FC(fully-connected layer全连接层)和BN(batch normalization)
其中,p[i]代表特征在之间step中的使用情况,
γ
\gamma
γ是松弛参数,若
γ
\gamma
γ是1,则强制该特征只能被1个step使用,若
γ
\gamma
γ大,则该特征可被多个step使用
P
[
i
]
=
∏
j
=
1
i
(
γ
−
M
[
j
]
)
P[i] = \prod_{j=1}^i (\gamma-M[j])
P[i]=∏j=1i(γ−M[j])
解码器:TabNet Decoder
1.结构图

2.功能
用于自监督补充数据
解码器TabNetDecoder用于将编码后的特征进行还原
将一些特征遮盖掉(S),通过将未遮盖的特征(1-S)进行编解码,得到对这该特征的预测值,将预测值与没有残缺的实际值进行比对,调整参数,最终得到缺失数据。
3.补充
表格数据会存在数据缺失的问题,遮蔽训练方法(mask方法)是深度学习在自然语言处理中的一种常用方法,它使用大量无标数据训练,故意遮蔽(masked)一些有效数据,然后通过训练模型弥补数据缺失,间接实现了数据插补,使模型在数据缺失的情况下也能很好地工作。特别是在标注数据较少的情况下,TabNet的效果更加明显。
可解释
从原理上看,mask可以描述单个实例单步的特征重要性,使模型具备局部可解释性,全局可解释性则需要通过系数组合每个单步的重要性
处理示例

示例的两个决策块分别处理与专业职业和投资相关的特征,以便预测收入水平。

















 5564
5564

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









