






论文阅读笔记(7):Self-Attention Between Datapoints: Going Beyond Individual Input-Output Pairs in Deep Learning,数据点之间的自注意力机制:超越深度学习中的单个输入-输出对
文章arxiv如下
https://arxiv.org/abs/2106.02584
摘要
我们挑战了大多数有监督深度学习的一个普遍假设:模型预测只依赖于其参数和单个输入的特征。为此,我们引入了一个通用的深度学习体系结构,它将整个数据集作为输入,而不是一次处理一个数据点。我们的方法使用自我注意来明确地推理数据点之间的关系,这可以看作是使用参数注意机制来实现非参数模型。然而,与传统的非参数模型不同,我们让模型从数据中学习如何利用其他数据点进行预测。经验上,我们的模型解决了传统深度学习模型无法解决的跨数据点查找和复杂推理任务。我们在CIFAR-10上展示了早期的结果,并深入理解模型如何利用点之间的相互作用。
简介
从CNN到注意力模型,绝大多数有监督学习依赖这样一种参数化模型:它从一组从数据特征到标签的数据对学习到参数 θ \theta θ来最大化似然函数 p ( y ∣ x ; θ ) p(y|x;\theta) p(y∣x;θ)。这种模型训练后只需要通过参数 θ \theta θ和输入就可以预测出输出。可以说,这种训练方式只依赖单个数据点。
本文向这一在深度学习中被奉为圭臬的参数化模型提出挑战。基于相同的端到端的支持深度学习的方式,**通过直接训练数据集本身,**我们为模型添加的额外灵活性,即通过最大化 p ( y ∗ ∣ x ∗ ; D t r a i n ; θ ) p(y^*|x^*;\mathcal D_{train};\theta) p(y∗∣x∗;Dtrain;θ)作出预测。
具体来说,我们引入了非参数transformer(NPT):一种通用的深度学习架构。它将整个数据集作为输入,并通过显式学习数据点之间的interactions来预测(图1)。

NPT同时利用参数和非参数预测机制,通过端到端的训练,使得模型能够自然地从数据中学习如何平衡两者。也就是说,NPT不仅可以学习从特征到独立数据点目标的预测函数,还可以学习推理输入之间的一般关系。我们表明,这些模型学习从其他数据点查找信息,并在半合成环境中捕获生成数据的因果机制。然而,与传统的非参数模型不同的是,NPT不被迫只能这种方式进行预测:它们还可以利用传统参数深度学习的能力。我们使用多头自我注意机制(multi-head self-attention)来模拟数据点之间的关系,并根据自然语言处理领域最近的工作的启发,利用随机遮挡机制(stochastic masking mechanism)为NPT构建一个训练目标。
本文的一个关键贡献是打开了一扇大门,让人们更普遍地了解深度学习模型如何利用数据点之间的依赖关系进行预测。我们的结果表明,NPT在实践中利用了数据点之间的相互作用,并且我们在一些已建立的表格数据集以及早期的图像分类结果上表现出很强的竞争力。此外,我们还证明了NPTs结合表达学习(epresentation learning)和跨数据点查找可以解决复杂的推理问题;由于无法学习数据点之间的关系,这对于传统的深度学习或非参数模型来说是不可能的。
背景
尽管我们质疑深度学习中的参数化建模假设是非常新奇的,但在统计学中,所谓的非参数模型是一个众所周知且由来已久的研究领域。
在机器学习界,这种非参数模型最著名的例子可能是高斯过程。非参数模型通常不需要任何参数训练,而是通常根据固定程序在训练点之间直接插值。输入之间的交互完全由体系结构选择和一组必须仔细选择的超参数定义。传统的非参数模型无法从数据中学习——在深度学习实践者熟悉的意义上——数据的交互,限制了这些模型适应现有数据的灵活性。诸如深高斯过程(Deep Gaussian Processes)、深核学习(Deep Kernel Learning)和神经过程(Neural Processes)等方法都试图将深神经网络的思想应用于非参数模型。与NPT相比,这些方法在很大程度上依赖于随机过程,这导致它们要么不如NPT灵活,要么需对数据进行强有力的假设,使得它们不适用于实际场景。与以前的工作不同,npt显式地学习数据点之间的交互,并且可以应用于一般的有监督机器学习任务。有关这些方法和其他相关方法的概述,请参阅第3章。
接下来我们将讨论我们模型的细节(§2),然后讨论相关工作(§3)、实验结果(§4),最后讨论局限性、未来工作和结论(§5)。
2. 非参数Transformer
NPT明确地学习数据点之间的关系以改进预测。为了实现这一点,他们依赖于三个主要组成部分:
- 我们提供整个数据集——即所有数据点——作为输入的模型。在测试时,训练和测试数据都被输入到模型中;在训练过程中,模型仅从训练数据中学习预测目标。对于大数据,我们在必要的情况下进行近似计算
- 我们使用数据点间的self-attention来显式地建模它们之间的关系。例如,在测试时,注意机制对训练点之间、测试点之间以及两者之间的关系进行建模
- NPT的训练目标是重建输入数据的损坏集。与BERT类似,我们对特征和目标都应用随机掩蔽,并在输入中掩蔽的条目上最小化NPT预测的损失
2.1 作为输入的数据集
数据集一般是这样的:单个数据点为每一列,按行堆叠形成整个数据集。假设单个数据点的1到d-1维为特征值,d维为标签值,于是传统的单目标分类或回归问题是每个 X i , j X_{i, j} Xi,j作为输入元素,通过 X : , j ≠ d X_{:, j\neq d} X:,j=d去预测 X : , d X_{:, d} X:,d。但是请注意,这与§1中介绍的监督学习的通用符号不同,因为输入X现在同时包括特征和标签,统称为属性(传统的数据矩阵不包括target)。
在掩蔽语言建模中,mask标记表示应该隐藏句子中的哪些单词,以及在训练时模型预测将有损失反向传播的位置。类似地,我们使用二进制矩阵 M ∈ R n × d M∈\mathbb R^{n×d} M∈Rn×d指定mask哪些条目。该矩阵也作为输入传递给NPT。任务是从观测值 X O = { X i , j ∣ M i , j = 0 } X_O=\{X_{i,j} | M_{i,j}=0\} XO={Xi,j∣Mi,j=0}预测掩蔽值 X M = { X i , j ∣ M i , j = 1 } X^M=\{X_{i,j} | M_{i,j}=1\} XM={Xi,j∣Mi,j=1},即预测 p ( X M ∣ X O ) p(X^M | X^O) p(XM∣XO)。
最终,NPT将整个数据集和mask矩阵 ( X , M ) (X,M) (X,M)作为输入,并预测输入时屏蔽的值。这种通用设置只需调整 M M M中mask的位置,就可以适应许多机器学习设置。
我们专注于单目标分类和回归——即掩蔽矩阵M在标签列 X : , d X_{:,d} X:,d的所有条目上都为1(masked)。在附录C.6中概述了多目标设置、插补、使用输入特征的自监督和半监督。接下来,我们将描述NPT体系结构。
2.2 NPT的体系

NPT的概述如图2所示。图(a)中NPT接收数据集和屏蔽矩阵
(
X
,
M
)
(X,M)
(X,M)输入。我们将这些数据叠加,并对每个数据点应用相同的线性嵌入,得到embedding后的输入表示
H
(
0
)
∈
R
n
×
d
×
e
H_{(0)}∈\mathbb R^{n×d×e}
H(0)∈Rn×d×e,如图(b)。接下来,我们应用一系列的multi-head self-attention层。关键的是,我们交替地在数据点之间,和在单个数据点的特征之间应用attention,如图(c-d)。
这些操作允许我们的模型学习数据点之间的关系以及单个数据点的transformation。最后,输出的embedding给出了预测结果 X ^ ∈ R n × d \hat X∈\mathbb R^{n×d} X^∈Rn×d,它在输入屏蔽的条目上有预测值。可参考附录C.3了解详细信息,例如离散变量和连续变量的处理。
NPT有如下重要性质:
Property 1: NPTs对数据点的排列组合等价
换句话说,如果输入数据点的集合被shuffle,NPT产生相同的预测,但是以类似的方式suffle。这明确了这样一个假设:即数据点之间的学习关系不应该依赖于它们的顺序。在较高层次上说,排列等价性(PE)成立,因为NPT的所有组成部分都是PE的,而PE函数的组成部分也是PE的。
我们现在简要回顾一下multi-head self-attention,这是NPT架构中的一项重要操作。
2.3 多头自注意力
MHSA是学习输入序列中元素间复杂相互作用的一种有效机制。基于MHSA的模型在自然语言处理中得到了推广,并成功地应用于机器学习的许多领域(参见§3)。
点积attention通过比较query Q i ∈ R 1 × h k ∣ i ∈ 1 , ⋯ n Q_i\in \mathbb R^{1\times h_k}|i\in 1,\cdots n Qi∈R1×hk∣i∈1,⋯n与key { K i ∈ R 1 × h k ∣ i ∈ 1 , ⋯ m } \{K_i\in \mathbb R^{1\times h_k}|i\in 1,\cdots m\} {Ki∈R1×hk∣i∈1,⋯m},最终通过注意力权重聚合的values { V i ∈ R 1 × h v ∣ i ∈ 1 , ⋯ m } \{V_i\in \mathbb R^{1\times h_v}|i\in 1,\cdots m\} {Vi∈R1×hv∣i∈1,⋯m}来更新query的表达 。我们将query,key和value分别堆叠到矩阵 Q ∈ R n × h k Q\in \mathbb R^{n\times h_k} Q∈Rn×hk, K ∈ R m × h k K\in \mathbb R^{m\times h_k} K∈Rm×hk和 V ∈ R n × h v V\in \mathbb R^{n\times h_v} V∈Rn×hv中,通常为方便起见,假设 h k = h v = h h_k=h_v=h hk=hv=h,计算点积注意力:
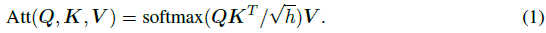
多头注意力就是concat多个(k个)独立的(independent)注意力头:
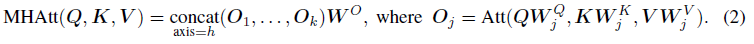
我们学习到的是对每个head
j
j
j的embedding矩阵
W
j
Q
,
W
j
K
,
W
j
V
W_j^Q,W_j^K,W_j^V
WjQ,WjK,WjV,然后
W
j
O
∈
m
a
t
h
b
b
R
h
×
h
W_j^O\in mathbb R^{h\times h}
WjO∈mathbbRh×h混合了所有head的输出。对于多头自注意力,query,key和value的输入是相同的,即:
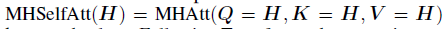
我们首先添加一个残差分支(residual branch),然后接着一个应用了层归一化之后(layer normalization, LN)的MHSelfAtt:
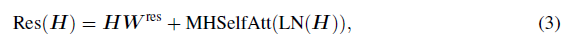
W
R
e
s
∈
R
h
×
h
W^{Res}∈\mathbb R^{h×h}
WRes∈Rh×h为可学习权重矩阵。然后,我们添加另一个带有LN的残差分支和一个row-wise前馈网络(row-wised feed-forward network, rFF),最后给出我们的完整的多头自注意力(MHSA)层:
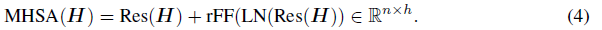
2.4 数据点之间的attention(ABD)
数据点之间的注意力(ABD)层是NPT的关键操作。它通过推理所有数据点之间的pairwise关系来显式转换数据,见图2c。作为ABD的输入,我们将上一层H的输出从
R
n
×
d
×
e
\mathbb R^{n×d×e}
Rn×d×e"展平"到
R
n
×
h
,
h
=
d
⋅
e
\mathbb R^{n×h},h=d·e
Rn×h,h=d⋅e。然后,我们在数据点之间
{
H
i
(
ℓ
)
∈
R
1
×
h
∣
i
∈
1
,
⋯
,
n
}
\{H^{(\ell)}_i∈\mathbb R^{1×h} | i∈1,\cdots ,n\}
{Hi(ℓ)∈R1×h∣i∈1,⋯,n}执行多头自我注意力(MHSA)层:
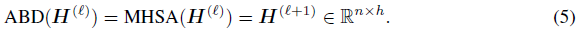
第一层ABD的输入也就是线性embedding的输入数据,在ABD输出需要再次reshape把展平的数据再按照
R
n
×
d
×
e
\mathbb R^{n×d×e}
Rn×d×e复原。
请注意,这与文献中通常应用MHSA的方式不同,因为我们计算不同数据点之间,而不是单个数据点特征之间的注意力。例如,在自然语言处理中,注意力通常应用于句子(数据点)的token(特征)之间,而不是不同的句子之间。通过堆叠许多ABD层,NPT可以学习数据点之间的高阶interactions。
2.5 特征之间的attention(ABA)
Attention Between Attributes 总是在ABD之后执行。ABA层可以帮助模型更好地学习数据点之间交互的每个数据点表示,见图2(d)。在ABA中,我们将MHSA独立地应用于输入
H
i
(
ℓ
)
∈
R
d
×
e
,
i
=
{
1
,
⋯
,
n
}
H^{(\ell)}_i\in \mathbb R^{d\times e}, i=\{1,\cdots ,n\}
Hi(ℓ)∈Rd×e,i={1,⋯,n}中的每一行(对应于单个数据点),给定:

ABA用于独立转换单个数据点的属性表示。为了有效地计算ABA,我们在n维上进行批处理。通过在ABD和ABA之间进行交替,NPT可以对点之间的复杂依赖关系建模,也可以单独学习数据点的合适transformer。接下来,我们将描述在NPT训练和测试期间mask机制的使用。
2.6 Masking and optimization
Masking
我们使用Masking来指示NPT需要预测的值,并阻止模型访问它的真值,被mask的值可以是特征也可以是标签,通常,mask在语言建模中用于对句子的一系列token执行自监督学习。在训练过程中,stochastic feature masking以
p
f
e
a
t
u
r
e
s
p_{features}
pfeatures的概率随机mask特征值。而stochastic target masking以
p
t
a
r
g
e
t
p_{target}
ptarget的概率去mask标签。注意,避免测试集泄漏,并且从不向NPT透露测试集的target。
NPT objectives
训练时对于taget我们使用负对数似然函数(negative log-likelihood loss,nll_loss),记为 L t a r g e t \mathcal L^{target} Ltarget;对于被mask掉的features使用辅助Loss(auxiliary loss,aux),记为 L f e a t u r e s \mathcal L^{features} Lfeatures。NPT的总损失为 L = ( 1 − λ ) L t a r g e t + λ L f e a t u r e s \mathcal L=(1-\lambda) \mathcal L^{target}+\lambda \mathcal L^{features} L=(1−λ)Ltarget+λLfeatures。在测试时,我们仅mask并计算target上的loss。
这一目标有几个值得注意的因素。特征的mask要求NPT对所有属性进行预测,从而鼓励模型学习整个数据集的表示。这增加了任务的难度,并增加了更多的监督,我们发现这是有益的规范化效果。有趣的是,stochastic target masking意味着许多target在模型训练时并未被mask。这使得在每个epoch中,NPT能够学习使用其他训练数据点的target以及所有训练数据特征预测某些训练数据点的屏蔽的target。
NPTs不再需要记忆其参数 θ θ θ以训练输入和输出之间的映射,相反,他们可以利用自己的表征能力,通过其他训练特征和目标作为输入来学习拟合函数。例如,NPT可以学习将测试数据点分配给训练数据点的clusters,并使用各自cluster中训练target的插值来预测这些点。
处理大数据集
为了避免MHSA过高的时间和空间复杂性,一旦数据变得太大,我们求助于使用近似值的方法。例如,标准NPT型号的GPU内存在8000个数据点左右达到24GB。我们发现,在模型训练和预测的随机子集中处理数据,即小批量,是一种简单而有效的解决方案。我们构造小批量,以便在测试时,训练和测试数据都存在于同一批中,以允许NPT关注训练数据点。
3 相关工作
深度非参数模型
深度高斯过程(Deep GP)和深度核学习(DKL)将概念从高斯过程扩展到表征学习。Deep GPs将标准GPs进行堆叠,以期了解输入数据点之间更好的表征关系。然而,与NPT不同,Deep GPs在实践中很难使用,需要复杂的近似推理方案。DKL在将点传递到标准高斯过程之前,将神经网络独立apply到每个数据点,直接基于embedding空间的相似性进行预测,而不是学习interactions本身。
神经过程(neural processes,NPs)
与GPs类似,神经过程(NPs)定义了函数的分布。他们使用由神经网络参数化的潜变量模型,满足特定的结构约束,以近似地保持有限维边缘的一致性。注意力神经过程(ANPs)扩展了NPs,允许在上下文集和target之间进行直接使用注意力。然而,正如作者自己所强调的,“NPs和GPs有不同的训练体系”。GPs可以在单个数据集上进行训练,但ANPs则需要数据集的多种认识。作者进一步指出,“两者之间的直接比较通常是不合理的”,这就是为什么我们不能在标准任务中将ANPs与NPT进行比较的原因。
Attention
NPT是最近一系列工作的一部分,它探索了自然语言处理之外基于transformer的架构的使用,例如,计算机视觉中的transformer或利用理想不变性或等效性的架构。与NPT一样,Set Transformer关注一组输入点。然而,与NPT不同,Set Transformer依赖于多个独立集进行训练,并且只对每个集进行一次预测。此外Set Transformer也没有关注数据点之间的attention。
最近的工作还改进了神经网络在表格数据上的性能。AutoInt是对表格数据的MHSA的直接应用,而TabNet则依次关注受基于树的模型启发的特征的稀疏子集。这两种方法都没有考虑数据点之间的相互作用,这是我们在这项工作中介绍的NPT的一个关键贡献。
Few-Shot Learning, Meta-Learning, and Prompting
我们将NPT应用于需要学习训练数据上数据点之间关系结构的任务,以在新的测试输入上获得良好的泛化性能。这种设置与Meta-Learning有着共同的动机,在Meta-Learning中,模型对各种任务进行预训练,这样它就可以只使用新任务中的少量额外训练点来学习新任务。然而,不像最近的Meta-Learning方法,我们考虑没有任何附加梯度更新的评估,因此不适用于此设置。
最近关于使用文本提示的Few-Shot Learning的研究提供了一个经过训练的基于transformer的语言模型,在预测时在提示符中显示一些新关系的示例,并观察到强泛化。类似地,我们考虑数据的“上下文”之间的注意。虽然ground truth的输入-输出对提供提示,我们考虑在预测时没有给出ground truth的设置,如果该模型已经学会了底层的关系结构,它依然可以解决任务。
由于NPT的独特性质,我们相信还有许多其他令人兴奋的联系有待挖掘。我们在附录D中讨论了一些可能的应用领域,包括半监督学习、图形神经网络和关系学习,并将其他领域,如缺失数据预测、半监督学习和持续学习留给未来的研究
4 实验
开源代码:github.com/OATML/Non-Parametric-Transformers
在benchmark上的竞争性
我们在UCI存储库的表格数据,以及CIFAR-10和MNIST图像分类数据集上评估NPT。表格数据在现实世界的机器学习中无处不在,但对于一般用途的深度神经网络来说,这是一个众所周知的挑战,因为深度神经网络的性能一直低于boosting模型,在实践中很少使用。
表格数据集、实验设置和baseline
我们在10个数据集上评估了NPT,这些数据集在数据点的数量、特征的数量、特征的组成(分类或连续)以及任务方面都有所不同。10个分类中有4个是二元分类,2个是多类分类,4个是回归分类。我们将NPT与一系列标准或最先进的baseline进行比较:Random Forests, Gradient Boosting Trees, XGBoost, CatBoost, LightGBM, MLPs, k-NN,和TabNet。我们在验证集上调整所有模型的参数,并使用10折交叉验证。
略
局限性
局限性
NPT与所有naive的非参数方法和图卷积网络都有scalable的限制。虽然我们已经看到了微型批处理(§2.6)的成功,但NPT证明了原则性注意近似的未来工作是合理的,例如学习代表性输入点、核化或其他稀疏诱导方法。
今后的工作
我们相信NPT独特的预测机制使其成为其他任务的有趣研究对象,包括持续学习、多任务学习、few-shot泛化和领域适应。例如,数据点和属性之间的一般关系可能仍然有效,并允许NPT更好地适应此类场景。此外,未来的工作可以探索与随机过程的联系,例如,将NPT扩展为近似一致,类似于神经过程。
结论
我们引入了非参数转换器(Non-parametric transformers,NPTs),这是一种新的深度学习体系结构,它将整个数据集作为输入,并使用自我关注来建模数据点之间的复杂关系。NPT挑战并自然扩展了参数化建模作为深度学习的主导范式。他们有额外的灵活性,可以通过直接关注其他数据点来学习预测。值得注意的是,NPT从手头的数据中了解到了这一点。从经验上看,NPT在各种基准测试中都取得了极具竞争力的性能,另外的实验证明了它们能够解决数据点上的复杂推理任务。此外,我们还表明,在真实数据上,NPT学习依赖于数据点之间的注意力进行预测。我们相信NPT的特性将使其成为一个令人兴奋的进一步研究对象。
附录C 6 NPT Masking
C 6.1 处理丢失数据
现实世界的数据——特别是表格数据——通常包含缺失的条目。许多流行的表格数据监督预测模型不能将缺失值作为输入。相反,它们要求对缺失特征进行插补,即一个额外的模型预测缺失值可能用什么的替代值,这样受监督的模型就会收到一个“干净”的数据集作为输入。
例如,所有sklearn的算子,包括梯度提升和随机森林,在训练之前都需要明确的插补步骤。通常,在实践中使用非常简单的插补方法。例如,TabNet删除了缺失项超过10%的数据点,并用单变量平均插补;CatBoost将缺失的连续条目视为该特征的最小值或最大值(单变量最小值/最大值插补)。虽然理论上可以将更复杂的插补方法用作预处理,但插补步骤和预测模型之间始终存在不一致性。此外,更复杂的插补方法通常需要训练和超参数选择,因此插补和预测过程变得繁琐。出于实际和性能原因,希望有一个单一的模型可以直接处理缺失数据,从数据中学习复杂的内部插补操作,同时从特征到目标学习所需的预测函数。
这正是NPT实现的目标。它们能够优雅地适应缺失值的输入,而不需要任何插补预处理步骤,因此可以对缺失值的数据进行端到端建模。在标准NPTs中,我们可以通过简单地设置masking来把这些值当作缺失值来预测,从而忽略输入时的缺失值。
此外,无需选择NPT的固定插补算法。相反,NPT直接从数据中学习如何在给定缺失值的情况下进行预测。数据点之间的attention对学习如何通过关注其他数据点来插补缺失值的一般机制可能特别有用。因此,我们猜测NPT可能是预测缺失值数据的有力竞争者。此外,与普通插补预处理不同,NPT不会丢弃缺失属性的信息。未来的工作还可以探索NPT对数据缺失模式下的任意相关性建模的能力,即数据集中的值不是随机缺失的。
C 6.2处理常见的机器学习设置
多目标检测预测
在多目标分类或回归中,数据集的多个列包含目标。标准的监督模型通常不支持多输出设置,必须训练多个模型,每个目标一个模型。NPT可以简单地适应多目标预测,因为它们学习在任何masked的输入上进行预测。对于多目标设置中的预测,我们只需在具有目标的所有列上应用目标掩蔽。
自监督
在自监督学习中,我们通常对从未标记数据中学习生成模型或有用编码感兴趣。作为stochastic feature masking的一部分,受损输入特征的重建可以看作是自监督学习。随机mask机制允许NPT学习预测输入中任何被mask的位置。理论上,NPT应该能够以这种方式学习数据集的完全生成模型。
半监督
我们希望在无标记的小数据集上使用半监督学习功能。通常,这涉及两个步骤,例如从所有数据中学习一个强大的自动编码器,然后使用所学习的编码器和一小部分标记数据来训练预测器。NPT可以在不改变体系结构的情况下适应半监督学习。具体地说,我们可以通过简单地将这些特征值附加到带标签的输入数据集中来包含大量未标记的数据。NPT可以在数据点之间使用attention,以利用来自未标记数据点特征的信息。
插补
对于插补,我们指的是主要任务是预测任意属性和数据点的缺失值的场景。与自监督类似,NPT已经从默认启用的随机掩蔽机制学习如何做到这一点。















 4799
4799











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









