






第一章 矩阵与线性方程组(十三)
1.向量的相似度
模式分类
考虑M个类型的模式,它们分别记作
w
1
,
w
2
,
⋅
⋅
⋅
,
w
M
w_1,w_2,···,w_M
w1,w2,⋅⋅⋅,wM,编号随意。假定通过已知类型属性的观测样本,业已抽取出M个样本模式向量
s
1
,
s
2
,
⋅
⋅
⋅
,
s
M
s_1,s_2,···,s_M
s1,s2,⋅⋅⋅,sM。给定一任意的未知模式向量
x
x
x,希望判断它归属于哪一类模式。这个问题称为模式分类,它是模式识别的基本问题之一。
模式分类的基本思想是将未知模式向量
x
x
x同M个样本模式向量进行比对,看$x$4与哪一个样本模式向量最相似,并据此作出模式分类的判断。
- 假定
(
x
,
s
1
)
,
(
x
,
s
2
)
,
⋅
⋅
⋅
,
(
x
,
s
M
)
(x,s_1),(x,s_2),···,(x,s_M)
(x,s1),(x,s2),⋅⋅⋅,(x,sM)分别作为未知模式向量
x
x
x和已知样本模式向量
s
1
,
s
2
,
⋅
⋅
⋅
,
s
M
s_1,s_2,···,s_M
s1,s2,⋅⋅⋅,sM之间的相似关系的符号。以
x
x
x与
s
1
,
s
2
s_1,s_2
s1,s2的相似关系为例,若
&&(x,s_1)≤(x,s_2)&&
则称未知模式向量 x x x与样本模式向量 s 1 s_1 s1更相似。为了建立相似关系,需要定义相似度(similarity)或相异度(dissimilarity)。
距离函数
- 最简单和最直观的相似度是两个向量之间的Euclidean距离。未知模式向量
x
x
x与第i个原象模式向量
s
i
s_i
si之间的Euclidean距离记作
D
(
s
i
,
x
)
D(s_i,x)
D(si,x),定义为
D ( s i , x ) = ∣ ∣ x − s i ∣ ∣ 2 = ( x − s ; ) T ( æ − s i ) D(s_i,x)=||x-s_i||_2=(x-s;)T(æ-si) D(si,x)=∣∣x−si∣∣2=(x−s;)T(æ−si)
称 s i ∈ s 1 , s 2 , … , s M s_i∈{s_1,s_2,…,s_M} si∈s1,s2,…,sM是到 x x x的近邻(即最近的邻居),若
D ( s i , x ) = m i n D ( s k , x ) , k = 1 , 2 , … , M D(s_i,x)=minD(s_k,x),k=1,2,…,M D(si,x)=minD(sk,x),k=1,2,…,M - 作为一种广泛使用的分类法,近邻分类(nearestneighborclassification)法将未知类型的模式向量 x x x归为它的近邻所属的模式类型。
除了Enclidean距离外,另外一个有用的距离函数是Mahalanobis距离。令
m
=
1
/
N
∑
k
=
1
N
s
i
m=1/N\sum_{k=1}^Ns_i
m=1/Nk=1∑Nsi
代表N个样本模式向量的均值向量,并使用
C
=
1
/
N
∑
i
=
1
N
(
s
i
−
m
)
(
s
i
−
m
)
T
C=1/N\sum{i=1}^N(s_i-m)(s_i-m)^T
C=1/N∑i=1N(si−m)(si−m)T
表示N个样本模式向量的协方差矩阵。
- 从未知模式向量
x
x
x到均值向量
m
m
m之间的Mahalanobis距离定义为
D ( m , x ) = ( x − m ) T C ( x − m ) D(m,x)=(x-m)^TC(x-m) D(m,x)=(x−m)TC(x−m)
类似地,从第 i i i个样本模式向量 s i s_i si到均值向量 m m m的Mahalanobis距离定义为
D ( m , s i ) = ( s i − m ) T C ( s i − m ) D(m,s_i)=(s_i-m)^TC(s_i-m) D(m,si)=(si−m)TC(si−m)
根据近邻分类法,将未知模式向量 x x x归为满足
D ( s i , x ) = m i n ∣ D ( s k , x ) − D ( m , x ) ∣ , k = 1 , 2 , … , N D(s_i,x)=min|D(s_k,x)-D(m,x)|,k=1,2,…,N D(si,x)=min∣D(sk,x)−D(m,x)∣,k=1,2,…,N
的近邻 s i s_i si所属的模式类型。
余弦函数
两个向量之间的相似度的测度不一定局限于距离函数。两个向量的夹角的余弦函数
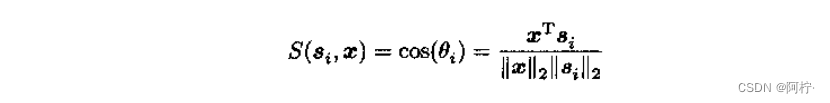
也是相似度的一种有效测度。若
c
o
s
(
θ
i
)
<
c
o
s
(
θ
j
)
,
∀
j
≠
i
cos(θ_i)<cos(θ_j), \forall j≠i
cos(θi)<cos(θj),∀j=i成立,则认为未知模式向量
x
x
x与样本模式向量
s
i
s_i
si最相似。
上式的变型:
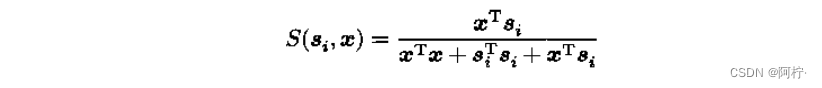
称为Tanimoto测度,它泛应用于信息恢复、疾病分类、动物和植物分类等。
- 待分类的信号称为目标信号,分类通常是根据某种物理或几何概念进行的。令
X
X
X为目标信号,
A
i
A_i
Ai代表第
i
i
i类目标的分类概念。于是,可以有类似于式的关系:
( X , A i ) ≤ ( X , A j ) , ∀ i , j (X,A_i)≤(X,A_j),\forall i,j (X,Ai)≤(X,Aj),∀i,j
这类有效关系一般用目标-概念距离(object-conceptdistance) D ( X , A i ) D(X,A_i) D(X,Ai)描述。因此,若目标-概念距离 D ( X , A i ) D(X,A_i) D(X,Ai)最小,则将X归为第i类目标 C i C_i Ci。
以上介绍了五种相似度:Euclidean距离、Mahalanobis距离、夹角余弦、Tanimoto测度以及目标-概念距离。
正交向量在移动通信中的应用
在移动通信中,总是有很多用户希望能够同亨一个发射媒介,进行无线通信。这种通信方式称为多址通信。多址通信的理论基础是若用户之间的信号可以做到正交,这些用户就可以同时共享一个发射媒介。
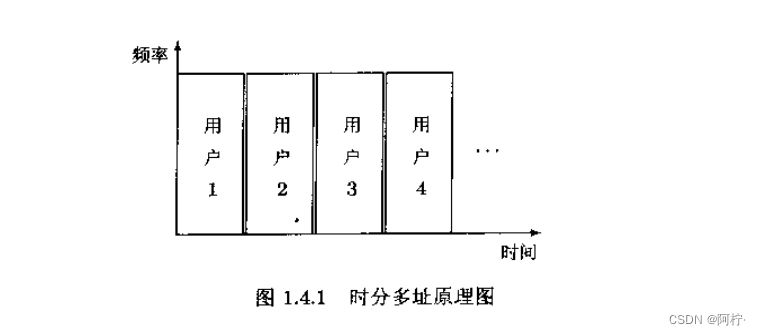
1.时分多址(TDMA)
用户共享整个频率信道,但每个用户被基站分配以不同的时区,并且相邻用户之间插有保护时隙,以使得他们的信号在时域没有任何重叠,从而实现用户信号之间(在时域)的正交,即有
<
s
i
(
t
)
,
s
j
(
t
)
>
=
0
,
∀
i
≠
j
<s_i(t),s_j(t)>=0,\forall i≠j
<si(t),sj(t)>=0,∀i=j,参见图14.1。由丁在用户i工作的时区,只有用户i的离散信号向量
s
i
=
[
s
i
(
1
)
,
s
i
(
2
)
,
…
,
s
i
(
N
)
]
T
s_i=[s_i(1),s_i(2),…,s_i(N)]^T
si=[si(1),si(2),…,si(N)]T不为零,其他用户的离散信号均为零向量,所以时分多址实际上依靠向量正交
<
s
i
,
s
j
>
=
0
<s_i,s_j> = 0
<si,sj>=0实现多址通信。
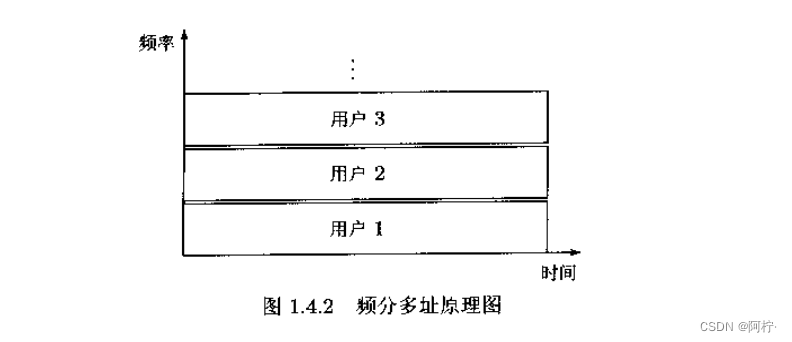
2.频分多址(FDMA)
所有用户可以同时进行通信,但每个用户被基站分配以不同的通信频道。即是说,所有用户信号在频域没有重叠,并且相邻用户的频道之间插有保护频隙,从而实现用户信号之间(在频域)的正交,即有 < S i ( f ) , S j ( f ) > = 0 , ∀ i ≠ j <S_i(f),S_j(f)>=0,\forall i≠j <Si(f),Sj(f)>=0,∀i=j,如图1.4.2所示。
在用户i工作的频段,经过频率域的采样,只有用户i的频域信号为非零向量形式8=[S,(1),s;(2),…S(M)]T,其他用户的频域信号为零向量。因此,频分多址实际上依靠向量正交()=0实现多址通信。
3.跳频-码分多址(CDMA)
在同一个时区,每个用户被分配不同的频道,并目相邻频道之间播有保护额院。不同的时区,分配给用户的频道不同,即同一个用户的频道是跳跃变化的。图1.4.3以5个用户为例,画出了4次跳频的分配,其中,省画了相邻频道之间的保护频隙。

显然,只要能够保证在同一时区,各个用户的频道不重叠,其他各种形式的跳频都是可行的。
4直接序列-码分多址(DS-CDMA)
所有用户不仅可以同时进行通信,并且共享整个通信频道,但每个用户被基站分配以不同的扩频码向量 s i = [ s i ( 1 ) , s i ( 2 ) , … , s i ( L ) ] T s_i=[s_i(1),s_i(2),…,s_i(L)]^T si=[si(1),si(2),…,si(L)]T,其中,L代表扩频增益。虽然这些扩频码在时间域或者频率域都是重叠的,但由于各个用户的扩频码为伪随机码,相互正交故码分多址依靠扩频码向量间的正交实现多址通信。















 2222
2222











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









