







主题:
Generative Image Inpainting with Contextual Attention是2018年的CVPR,在图像修复领域算是经典论文,个人觉得作者提出的上下文注意模块还是很牛的!
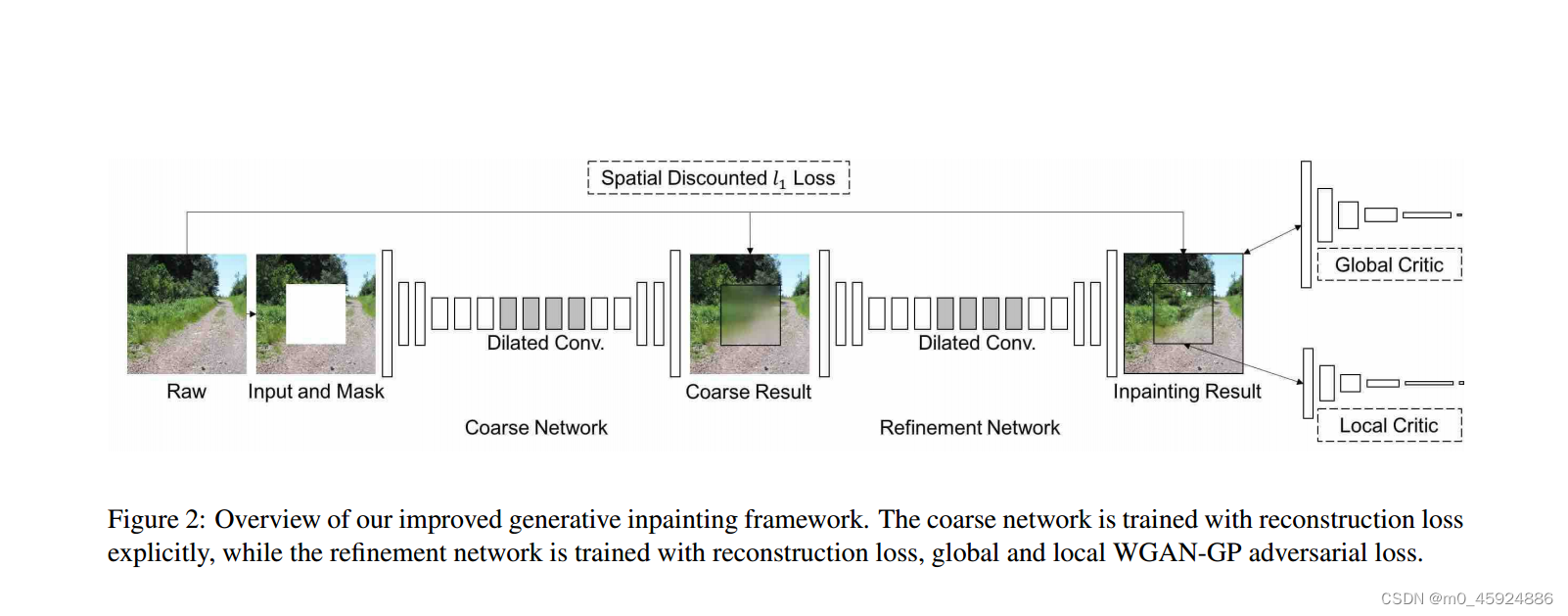
开源代码:
1,tensorflow:https://github.com/JiahuiYu/generative_inpainting/tree/v1.0.0
2.pytorch:https://github.com/DAA233/generative-inpainting-pytorch
当然官方版本是tensorflow版本,pytorch版本是其他大佬改的
上下文注意力模块:
理论解释:

该模块的整体思想是:首先提取前景和背景,利用卷积计算前景与背景的匹配分数(作为卷积滤波器),也就是前景作为卷积核,对划分成3*3大小的背景块进行卷积操作,但是卷积核是自定义的背景块。然后应用softmax进行比较,得到每个像素的注意力分数。最后,通过对注意分数进行反卷积,用背景块重建前景块。
说白了这个注意力块有什么用呢?通过这个模块首先可以得到背景任何块和前景任何块的一个相似度,也可以是两张图,如果是两张图的话就是计算图a所有3*3补丁快和图b任何补丁快的一个相似度,通过这个相似度就可以匹配到对应的地方,然后通过反卷积可实现图像修复或者转换。那么怎么反卷积就能实现呢?说到这里还是要稍微看一下反卷积或者转置卷积的一个计算原理。作者将上一步得到的注意力分数当作被卷积的对象,将背景组成的补丁快当作卷积核(这个卷积核不是前面计算注意力的卷积核,虽然都来自同一个地方按大小不一样,前面是3*3,这里的是4*4)然后通过反卷积(说白了就是通过线性变换,像素值*注意力分数得到当前位置的像素值,谁的相似度高谁的权重高,那么最后反卷积取它的值就越多)。
代码解释:
想了想还是用官方代码,挑一些代码讲解一下,一是就当给自己讲解以下,加深映像,还有就是如果刚好有想做图像修复或者图像生成,刚好又看到了这篇比较经典的论文,又刚好看了代码,又刚好对上下文注意模块有些迷糊的的小伙伴提供一些思路希望能有所帮助:
def contextual_attention(f, b, mask=None, ksize=3, stride=1, rate=1,
fuse_k=3, softmax_scale=10., training=True, fuse=True):f:前景,假设是[1,3,256,256],b背景,[1,3,256,256],是两张图,mask是掩码,作者对于掩码的处理还是很牛的,跟部分卷积有点像softmax_scal可以理解为注意力分数平滑度吧,通过代码修改就知道干啥的了,fuse是是否使用自定义的全是1的卷积核对图像进行一个平滑处理,有点像高斯模糊的意思,就是该点像素值也会受到周围像素的影响,这里这么做就是提取周围的像素做到全局或者局部一致性。
raw_w = tf.extract_image_patches(
b, [1,kernel,kernel,1], [1,rate*stride,rate*stride,1], [1,1,1,1], padding='SAME')这里是提取背景b的补丁,这一行代码会将b变成[1,128,128,48]大小的张量。原因:extract_image_patches会以大小kernel*kernel的滑动窗口对b进行提取补丁块,吧每一次提取的补丁块沿着通道的方向展开,128是通过卷积计算原理得到的输出大小(256-4+2)/2+1得到的,不太理解的话看看卷积输出大小的计算公式,48是3*4*4得到的,3是三通道,4是滑动窗口滑动一次获取的像素,然后沿着通道方向展开所以变成大小为16 的一维向量,然后一共三个通道.
raw_w = tf.reshape(raw_w, [raw_int_bs[0], -1, kernel, kernel, raw_int_bs[3]])
raw_w = tf.transpose(raw_w, [0, 2, 3, 4, 1])这两句是将上面得到的进行变形,以便后面做卷积核使用,通过这两个操作就得到大小[1,4,,4,3,16384]张量,批量1,大小4*4,通道3,补丁快个数16384,至于为什么这么做,因为要凑出与输入通道一致所以是3通道,大小4*4是定下来的卷积核大小。
f = resize(f, scale=1./rate, func=tf.image.resize_nearest_neighbor)
b = resize(b, to_shape=[int(raw_int_bs[1]/rate), int(raw_int_bs[2]/rate)], func=tf.image.resize_nearest_neighbor)下采样,别问为什么,就是为了减小大小,不然计算开支太大了,再者为后面的反卷积做准备,因为输出要和输入一样的大小,反卷积是上采样,那么前面旧的有下采样,加上还可以减少计算量的开销。
if mask is not None:
mask = resize(mask, scale=1./rate, func=tf.image.resize_nearest_neighbor)按照同样的方式对mask进行裁剪
fs = tf.shape(f)
int_fs = f.get_shape().as_list()
f_groups = tf.split(f, int_fs[0], axis=0)将批量分解为单个张量,为了后面方便计算
w = tf.extract_image_patches(
b, [1,ksize,ksize,1], [1,stride,stride,1], [1,1,1,1], padding='SAME')
w = tf.reshape(w, [int_fs[0], -1, ksize, ksize, int_fs[3]])
w = tf.transpose(w, [0, 2, 3, 4, 1]) 同样的对b进行去补丁快,准备卷积核,但是这次的大小是3*3用作计算相似度的卷积核,上面的是4*4用于反卷积
if mask is None:
mask = tf.zeros([1, bs[1], bs[2], 1])
m = tf.extract_image_patches(
mask, [1,ksize,ksize,1], [1,stride,stride,1], [1,1,1,1], padding='SAME')
m = tf.reshape(m, [1, -1, ksize, ksize, 1])
m = tf.transpose(m, [0, 2, 3, 4, 1]) # transpose to b*k*k*c*hw
m = m[0]对于mask=none的情况,创建一个mask,但是对结果没什么影响,因为全是0,
mm = tf.cast(tf.equal(tf.reduce_mean(m, axis=[0,1,2], keep_dims=True), 0.), tf.float32)这句话就是运用mask的灵魂语句吧我觉得是这样,在前三个维度上计算平均值,为啥前三通道,因为只需要保留mask补丁块的个数,然后每一个mask是0还是不是0,然是对0 进行比较是0为True不是则为fulse,因为大于零就是mask掩膜。equal()会得到大小[1,1,1,16384]的布尔值张量,然后cast转为0,1的张量
fuse_weight = tf.reshape(tf.eye(k), [k, k, 1, 1])前面还有几句都是一样的意思,这里是定义一个卷积核,作用就是上面提到的,用于对周围元素的提取,让整个或者局部更加一致,(不太理解的话就用卷积的方式计算一下就知道啥意思了)
.............................到点了该回宿舍了,有空再写,有错指出还请指出!















 89
89











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









