







 超级会员免费看
超级会员免费看
Pyramid Vision Transformer
论文地址: PVT-V1版本论文
源码地址: PVT-v1-torch源码
自从上一次讲解完Conformer之后,最近又看到一篇关于多尺度的Transformer backbone也就是本文中所提及到的Pyramid Vision Transformer(PVT),其实PVT是有两个版本的, 由于时间关系,我仅仅看了PVT-V1的论文以及对应的源码,所以对V1版本做一个讲解。
1. Abstract
不像ViT模型,设计用于图像分类,本文提出的PVT克服了将Transformer引入到密集视觉任务上的困难。相比之前的Transformer backbone,PVT的优点在于:
1)ViT仅仅使用低分辨率的输入图像作为input size,并且会带来高额的计算量和显存消耗,PVT不仅可以自己图像的密集区域上进行训练,以获得高分辨率的输出特征图,这对密集视觉任务其实是有帮助的,而且使用了渐进递减的金字塔来减少大尺度的feature map的计算量。
2)PVT联合了CNN和Transformer的优点,在conv-free的前提下可以对各种密集视觉任务的backbone,可以被当做是传统CNN backbone的另一种替代;
3)通过大量的实验表明,对于目标检测,语义分割等视觉任务上,都获得了可观的性能。如在COCO数据集上,PVT+RetinaNet(40.4AP)实现了相对于ResNet50+RetinaNet(36.3AP)高出4.1个AP值的精度提升。
2. Introduction
尽管ViT对于图像分类任务的性能是不错的,但是对于像素级密集视觉任务却很差,原因在于:
1)ViT最后输出的feature map是单尺度的并且分辨率较低,为什么说分辨率较低,因为ViT中是不能接受细粒度的图像patches的(如4x4 pixel per patch)作为输入的,仅能接受较为粗糙的图像patches(如32x32或者16x16)作为输入,因此带来的输出feature map的分辨率较低;
2)对于检测任务在COCO数据集上的input size,短边通常缩放到800pixel,ViT的self-attention的计算量以及显存消耗是非常大的。
对于传统CNN backbone, ViT以及文中的PVTj结构,如下图:

图a表示的是传统CNN backbone,feature map的尺度是在递减的,即分辨率从大到小,不同尺度的feature map适用于不同的视觉任务,如高语义信息低分辨率的feature map适用于图像分类任务,而低语义信息高分辨率的feature map则适合检测或者分割任务;而图b中的ViT呈现的是一种柱状结构,即每个stage中的feature map尺寸是相同的,不能使用于各种视觉任务;文中的PVT结构如图c,也是呈现出一种递减结构。
总的来说, PVT克服了传统Transformer backbone的缺陷:
1)不再使用固定大小且粗糙的图像patches,而是采用多种尺寸且细粒度的图像patches(e.g. 4x4)作为输入来学习到高分辨率的特征表示,而这对于密集视觉任务是非常重要的;
2)引入一种渐进式递减的金字塔结构,随着网络深度的加深,减少Transformer的序列长度即图像的size是逐渐减小的;
3)采用一种Spatial-Reduction Attention(SRA)layer,用来降低高分辨率feature map做Self-Attention时的高额计算量和显存消耗。
另外,在检测任务上,对比ResNet作为backbone,使用PVT作为backbone的检测效果对比:

以上实验均是在COCO2017 val数据集上进行的,使用的检测器baseline为RetinaNet,上面的PVT-T/S/M/L分别对应PVT的四个版本,在方法中会展开。不难看出,每一个对应的版本,使用PVT作为backbone,都会有检测精度的提升。
老样子,相关工作不展开, 不浪费时间,直接进主体部分。
3. Method
3.1. Overall Architecture
整体的网络模型图如下:

类似于CNN backbone, PVT也有4个stage,得到不同尺度的feature maps,所有的stage结构是类似的,都由一个patch embedding layer(可看成是下采样层,也是使用conv来实现的)和Li个Transformer Encoder layer组成。在第一个stage中,输入图像尺寸为HxWx3,首先将其分割成HW/42 个patches,因为使用的patch size是4x4,相当于将原始输入图像进行下采样4倍,再flatten patches并且将经过一个线性映射层得到embedded patches,其size为HW/42 x C1,将embedded patches与PE位置编码进行相加得到对应的Q,K以及V矩阵,通过L1层Transformer Encoder 的输出feature maps F1进行维度的调整:H/4 x W/4 x C1。同理,前一个stage的输出feature maps作为下一个stage的输入,依次获得feature maps:F2, F3和F4,其图像尺寸相对于原始输入图像的1/8,1/16,1/32。 因此可以得到 不同尺度的特征图{F2,F3,F4},可以应用到下游的各种视觉任务,图像分类,目标检测以及语义分割等。
3.2. Transformer Encoder
与传统的Encoder类似,包括Self-Attention和MLP两部分。由于PVT需要处理高分辨率的feature maps,作者在做Self-Attention之前引入了一个spatial-reduction attention layer用来降低feature map的尺寸,以达到降低计算量的目的。
类似MHA,SRA也会接受Query,Key以及Value作为输入,但不同的是K和V的spatial scale在进行attention之前会进行减少(注意,这里的spatial scale不是降低embedding的维度,而是减少序列长度或者说是feature map的尺寸)。那么在stagei的SRA过程如下:
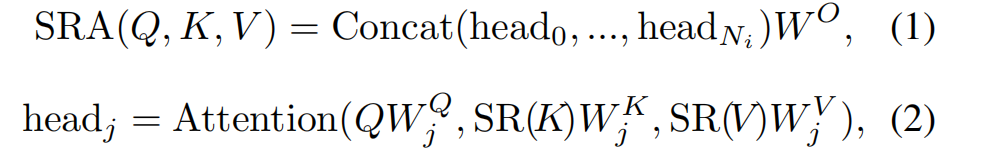
结合下面的Attention图:

这里的公式可能会让人存在歧义,难道得到的Q,K以及V还要分别进行一个线性映射吗?其实不是,Attention里面的三个线性映射其实是作用在输入feature map X上的,得到Q,K以及V。
Ni表示Stagei的attention layer中的head的数目即有几个头。因此每个head的dim为Ci/Ni,Ci表示该stage中的embedding的dim,SR的操作如下:
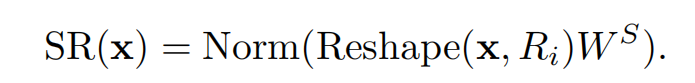
X为输入的feature maps,维度(HiWi)x Ci, Ri是该stage中的Attention中的K和V的下采样倍率因子, 虽然论文中所说的是将X进行维度的reshape,如下:
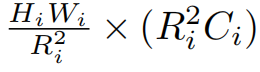
然后使用维度为**(R2iCi)x Ci**的矩阵进行线性映射得到下采样之后的X:HiWi/R2i x Ci
论文中说的是使用reshape+线性映射实现X的spatial scale的降低,其实在代码中,使用的是卷积来实现的,卷积核尺寸为Ri x Ri,stride=Ri。
而Self-Attention的操作是与传统Attention相同的,如下:
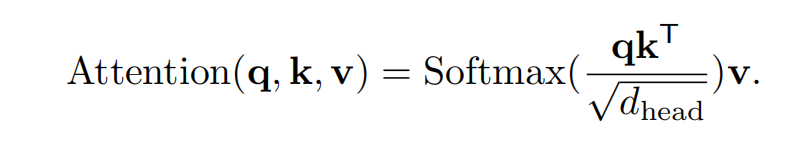
因此,相比于传统MHA,使用SRA机制可以降低Ri x Ri倍的计算量和显存消耗。
3.3. More Details
PVT中设计的超参数包括:
1)Pi :Stagei中的patch size;
2)Ci :Stagei的输出feature map的channel;
3)Li :Stagei中的Encoder layer的层数;
4)Ri :Stagei中的SRA的下采样倍率因子;
5)Ni :Stagei中的SRA进行Self-attention的heads数目;
6)Ei :Stagei中的SRA进行Self-attention之后进行MLP的第一个FC层的hidden units的倍率因子(这里的倍率因子是相对于输入到MLP block的embedding的dim)。
遵循ResNet网络的设计原则,PVT在网络的浅层使用较小的输出channel即embedding dim,随着网络加深,embedding dim也在随之增大;将主要的计算量分配在网络的中间Stage3中。
PVT也分为了4个版本,PVT-Tiny,PVT-Small,PVT-Medium以及PVT-Large,分别对应着ResNet-18/50/101以及152 这4个版本。具体的模型配置参数如下:

具体的实验结果和结论就不再展开了,下面对PVT的代码进行简要的解析。
4. PVT-V1代码解析
4.1. main脚本
main脚本中的书写规则与我之前解析Conformer源码其实是非常相似的,话说回来,Transformer Backbone的代码都是大同小异的,仔细看个一两篇论文的源码,后面再去看相关的源码,就会很快,而且,你知道源码中的主体部分在哪里,哪个脚本是需要去花时间仔细阅读的,而哪些又是可以pass的。这也是我读了许多源码之后分享给大家的一点小建议。
言归正传,main脚本不详细展开,我只提一点,关于数据集加载的问题,之前我使用的是博主劈里啪啦写的加载自定义数据集的方法去改写了main脚本中加载数据的方法,其实是不需要这么麻烦的,今天我提供一个较为简便的方法供大家参考。
因为我之前在debug代码时使用的数据集并不是ImageNet-1k或者是CiFAR数据集,用的是花分类数据集,如下
总共有5个类别,我先将这5个类别的所有图片进行随机分割成train和val,以8:2的比例进行划分;
随后将train中的图片按照类别名进行划分成5个子文件夹,每个文件夹的名字就是上图中的文件名,表示这5个类别的图片,同理val中的图片也这样操作,划分之后的结果如下:


最后在源码中加载数据集的dataset脚本中加上这么几句,如下:
def build_dataset(is_train, args):
transform = build_transform(is_train, args)
if args.data_set == 'CIFAR':
dataset = datasets.CIFAR100(args.data_path, train=is_train, transform=transform)
nb_classes = 100
elif args.data_set == 'IMNET':
if not args.use_mcloader:
root = os.path.join(args.data_path, 'train' if is_train else 'val')
dataset = datasets.ImageFolder(root, transform=transform)
else:
dataset = ClassificationDataset(
'train' if is_train else 'val',
pipeline=transform
)
nb_classes = 1000
elif args.data_set == 'INAT':
dataset = INatDataset(args.data_path, train=is_train, year=2018,
category=args.inat_category, transform=transform)
nb_classes = dataset.nb_classes
elif args.data_set == 'INAT19':
dataset = INatDataset(args.data_path, train=is_train, year=2019,
category=args.inat_category, transform=transform)
nb_classes = dataset.nb_classes
else:
root = os.path.join(args.data_path, 'train' if is_train else 'val')
dataset = datasets.ImageFolder(root, transform=transform)
nb_classes = 5
return dataset, nb_classes
加的内容其实就是最后一个else语句,数据集的路径就更改为你自己的数据集的根目录即可。
其实在源码中的README中作者也说明了,对于图像分类任务,数据集的格式如下:
/path/你自己的数据集的根目录/
train/
class1/
img1.jpeg
class2/
img2.jpeg
val/
class1/
img3.jpeg
class/2
img4.jpeg
只要是这种格式保存的图片,都可以用我上面提供的方法进行加载数据集,就不需要重新去写一个方法或者类来读取数据了。
4.2. pvt脚本
4.2.1. PyramidVisionTransformer类的init
我只说明这个类的init操作,其他类的init,我将会放在网络的forward中一起进行说明。代码如下:
class PyramidVisionTransformer(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_chans=3, num_classes=1000, embed_dims=[64, 128, 256, 512],
num_heads=[1, 2, 4, 8], mlp_ratios=[4, 4, 4, 4], qkv_bias=False, qk_scale=None, drop_rate=0.,
attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1], num_stages=4):
super().__init__()
self.num_classes = num_classes
self.depths = depths
self.num_stages = num_stages
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
cur = 0
for i in range(num_stages):
patch_embed = PatchEmbed(img_size=img_size if i == 0 else img_size // (2 ** (i + 1)),
patch_size=patch_size if i == 0 else 2,
in_chans=in_chans if i == 0 else embed_dims[i - 1],
embed_dim=embed_dims[i])
num_patches = patch_embed.num_patches if i != num_stages - 1 else patch_embed.num_patches + 1
pos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dims[i]))
pos_drop = nn.Dropout(p=drop_rate)
block = nn.ModuleList([Block(
dim=embed_dims[i], num_heads=num_heads[i], mlp_ratio=mlp_ratios[i], qkv_bias=qkv_bias,
qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur + j],
norm_layer=norm_layer, sr_ratio=sr_ratios[i])
for j in range(depths[i])])
cur += depths[i]
setattr(self, f"patch_embed{i + 1}", patch_embed)
setattr(self, f"pos_embed{i + 1}", pos_embed)
setattr(self, f"pos_drop{i + 1}", pos_drop)
setattr(self, f"block{i + 1}", block)
self.norm = norm_layer(embed_dims[3])
# cls_token
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dims[3]))
# classification head
self.head = nn.Linear(embed_dims[3], num_classes) if num_classes > 0 else nn.Identity()
# init weights
for i in range(num_stages):
pos_embed = getattr(self, f"pos_embed{i + 1}")
trunc_normal_(pos_embed, std=.02)
trunc_normal_(self.cls_token, std=.02)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
由于我在调试时使用的模型是PVT-small, 这里的一些配置参数信息我先列举出来:
embed_dims: 每个stage的embed的维度 [64, 128, 320, 512];
num_heads: [1, 2, 5 , 8];
mlp_ratios: [8, 8, 4, 4];
sr_ratios: [8, 4, 2, 1] 每一个stage中在进行Attention操作K和V需要进行下采样的倍率因子。
1) dpr: 按照论文中所说的每个stage的layer数目应为:【3,3,6,3】,但在代码中的PVT-small的实现其实是:3,4,6,3. 如下图中的depths参数:

而传入的drop_path_rate为0.1,layers总和为16,那么将0.1分割成16个等差数值,从0开始,最后一个为0.1。

2)搭建4个stage中的每个bottleneck,这里的PatchEmbed对应着论文中的Patch Embedding layer,如Stage1中的Patch Embedding layer:P1=4,C1=64。代码中是使用conv+layer norm实现的,如下:

在init的时候搭建模型,默认输入图像尺寸是224x224,所以在stage1中Patch Embedding出来的num_patches即224下采样4倍得到的图像尺寸56x56=3136,之后的stage的下采样倍率因子都是2。然后将这个数值赋值给num_patches,这个仅针对stage1-3的,最后一个stage中需要+1,是因为需要加上一个class token。
3)初始化4个stage中的PE位置编码,初始化全是0的tensors,Stage1-4的PE shape依次为:
【1,56x56, 64】;
【1,28x28, 128】;
【1,14x14,320】;
【1,7x7,512】
并且每个stage中的PE是需要再经过正态分布初始化得到的,也就是:
for i in range(num_stages):
pos_embed = getattr(self, f"pos_embed{i + 1}")
trunc_normal_(pos_embed, std=.02)
trunc_normal_(self.cls_token, std=.02)
self.apply(self._init_weights)
4)搭建每一个stage中的Transformer Encoder layer(下面简称bottleneck),每一个bottleneck包括Encoder和MLP block, block类如下:
class Block(nn.Module):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, sr_ratio=1):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(
dim,
num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop, sr_ratio=sr_ratio)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x, H, W):
x = x + self.drop_path(self.attn(self.norm1(x), H, W))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
其中又由Attention类和MLP类组成,如下:
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., sr_ratio=1):
super().__init__()
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.q = nn.Linear(dim, dim, bias=qkv_bias)
self.kv = nn.Linear(dim, dim * 2, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.sr_ratio = sr_ratio
if sr_ratio > 1:
self.sr = nn.Conv2d(dim, dim, kernel_size=sr_ratio, stride=sr_ratio)
self.norm = nn.LayerNorm(dim)
def forward(self, x, H, W):
B, N, C = x.shape
# 输入feature map先经过一个线性映射再拆分成nums_head维度的调整 -> [bs, num_heads, H*W, embed_dim(64)]
q = self.q(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
# 若sr_ratio大于1,则将feature map进行下采样sr_ratio倍,再进行线性映射得到K和V
if self.sr_ratio > 1:
x_ = x.permute(0, 2, 1).reshape(B, C, H, W)
x_ = self.sr(x_).reshape(B, C, -1).permute(0, 2, 1)
x_ = self.norm(x_)
kv = self.kv(x_).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
else:# 若sr_ratio=1,则feature map直接进行线性映射得到Key和Value
kv = self.kv(x).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
k, v = kv[0], kv[1] # [bs, num_heads, h*w/(sr*sr), num_heads_dim(64)]
# attn = Q * K -> [bs, num_heads, H*W, H*W/(sr*sr)]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
# attn * V = [bs, num_heads, H*W, num_heads_dim(64)] -> [bs, HW, embed_dims]
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
关于Attention类,我只提一点,那就是SRA是怎么做的。如果sr_ratio大于1,那么就会定义一个conv layer+layer norm层来进行下采样。以stage1为例,此时的sr_ratio=8,那么卷积核的参数为依次为:64,64,8,8。即使用8x8,s=8的卷积来进行K和V的下采样,对于输入的feature map的shape为(bs, 56, 56, 64)经过SR layer之后,K和V的shape变为:(bs, 7, 7, 64)。在进行后续的Self-Attention操作,这里的Self-Attention与传统Attention是一样的,就不再展开。
仔细的小伙伴可以发现,stage1-3中的K和V经过SR layer之后的序列长度都是一致的即7x7;还有一个有意思的地方是,每个stage的head dim也是一致的,都是64。
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
MLP block也没有改变,首先在block的init函数中根据embed dim和mlp ratio得到该stage中MLP的FC1的hidden units。以stage1为例,输入的embed dim为64,此时的倍率因子为8,那么MLP block如下:
FC1 (64,512) -> GELU -> Dropout -> FC2 (512, 64)-> Dropout。
4.2.2. PyramidVisionTransformer类的forward
由于每个stage中的操作都是类似的,所以我具体解析Stage1中的操作,后续的stage如法炮制。
我使用的输入图像尺寸是384x384,首先给出PVT的forward函数的实现:
def forward_features(self, x):
B = x.shape[0]
for i in range(self.num_stages):
patch_embed = getattr(self, f"patch_embed{i + 1}")
# 每个stage中的PE(针对224为输入初始化为全0):stage1 [1,56*56,64]; stag2 [1,28*28,128];stage3 [1,196,320]
pos_embed = getattr(self, f"pos_embed{i + 1}")
pos_drop = getattr(self, f"pos_drop{i + 1}")
block = getattr(self, f"block{i + 1}")
# 每个stage中的Patch Embed layer: [bs, H*W/s*s, embed_dim],H和W保存的是该stage中的feature map的尺寸
x, (H, W) = patch_embed(x)
# 下面的if语句仅针对最后一个stage: 初始化一个全为0的class token [1,1,512] -> [16, 1, 512]
if i == self.num_stages - 1:
cls_tokens = self.cls_token.expand(B, -1, -1)
x = torch.cat((cls_tokens, x), dim=1) # class token和x在维度为1的位置上进行concat
pos_embed_ = self._get_pos_embed(pos_embed[:, 1:], patch_embed, H, W)
pos_embed = torch.cat((pos_embed[:, 0:1], pos_embed_), dim=1)
else: # 如果输入图像为224,那么每个stage中的PE即为pos_embed;否则将PE进行双线性插值到对应的H和W尺寸
pos_embed = self._get_pos_embed(pos_embed, patch_embed, H, W)
# Patch embedding输出的feature map与PE进行add -> dropout
x = pos_drop(x + pos_embed)
# 经过每个stage的Transformer Encoder Module, 每一个Encoder layer的输出都是下一个layer的输入
for blk in block:
x = blk(x, H, W)
# 只针对前三个stage的输出, 调整feature map的维度 [bs,HW,embed_dim] -> [bs, embed_dim, H, W]
if i != self.num_stages - 1:
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
# 最后一个stage的输出feature map进行layer norm [bs, HW+1, 512], 返回class token所在的值
x = self.norm(x)
# [bs, 512]
return x[:, 0]
遍历每一个stage(共4个),获取每一个stage的Patch_embed,也就是每一个stage中的Patch Embedding layer;获取每一个stage的PE位置编码(已经经过正态分布初始化的),注意在init过程中是默认输入图像为224x224的,而我的输入图像尺寸是384,那么PE位置编码也需要进行修改,这个下面再说;接着获取每一个stage的drop rate以及block。
- Patch Embedding
def forward(self, x):
B, C, H, W = x.shape # batchsize, 3, 图像的输入尺寸(256x256)
# stage1中的Patch embedding的卷积核为4x4,s=4,卷积核个数为64 -> [bs, 64*64, 64] 之后的stage的卷积尺寸为2,s=2
x = self.proj(x).flatten(2).transpose(1, 2)
x = self.norm(x)
H, W = H // self.patch_size[0], W // self.patch_size[1]
return x, (H, W)
input images经过conv以及layer norm之后返回feature map以及对应的图像尺寸 (H,W),那么这里的输出x的shape为:[bs,96x96,64],(H,W)=(96,96)。
- pos_drop
由于与默认的尺寸是不一致的,在init中生成的PE位置编码是[1, 56x56, 64]与[bs,96x96,64]在HxW维度上不匹配的,所以需要将initial生成的PE进行调整,如下:
def _get_pos_embed(self, pos_embed, patch_embed, H, W):
if H * W == self.patch_embed1.num_patches:
return pos_embed
else:
return F.interpolate(
pos_embed.reshape(1, patch_embed.H, patch_embed.W, -1).permute(0, 3, 1, 2),
size=(H, W), mode="bilinear").reshape(1, -1, H * W).permute(0, 2, 1)
将initial生成的PE位置编码使用双线性插值得到与该stage的feature map的HxW一致的PE,然后将feature map与PE相加得到Transformer Encoder的输入。
- block
由于stage1中的bottleneck有三个,那么需要重复做三次,每一次的操作如下:
def forward(self, x, H, W):
x = x + self.drop_path(self.attn(self.norm1(x), H, W))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
Self-Attention中的操作中,使用两个线性映射分别得到Q,K和V,注意K和V首先是将输入进行下采样,也就是上面所提交到的,然后在使用一个[embed_dim, embed_dimx2]的线性映射同时获得K以及V。之后的attention操作很简单,不说了。
def forward(self, x, H, W):
B, N, C = x.shape
# 输入feature map先经过一个线性映射再拆分成nums_head维度的调整 -> [bs, num_heads, H*W, embed_dim(64)]
q = self.q(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
# 若sr_ratio大于1,则将feature map进行下采样sr_ratio倍,再进行线性映射得到K和V
if self.sr_ratio > 1:
x_ = x.permute(0, 2, 1).reshape(B, C, H, W)
x_ = self.sr(x_).reshape(B, C, -1).permute(0, 2, 1)
x_ = self.norm(x_)
kv = self.kv(x_).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
else:# 若sr_ratio=1,则feature map直接进行线性映射得到Key和Value
kv = self.kv(x).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
k, v = kv[0], kv[1] # [bs, num_heads, h*w/(sr*sr), num_heads_dim(64)]
# attn = Q * K -> [bs, num_heads, H*W, H*W/(sr*sr)]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
# attn * V = [bs, num_heads, H*W, num_heads_dim(64)] -> [bs, HW, embed_dims]
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
- Stage4
三次bottleneck结束之后,输出feature map的维度: 【bs,96x96,64】,再进行维度的调整得到:【bs,64,96,96】作为下一个stage的输入。直至到Stage4,经过正态分布初始化得到的class token 【1,1,512】,在第一个维度上进行扩充到batch size倍,得到一个batch size的class token:【bs,1,512】。
将这个class token与stage3的输出在第二个维度上进行concat得到:【bs,145,512】;
那么对应的PE怎么得到呢?首先将初始化的PE进行上采样得到对应H和W的尺寸:【1,144,512】,
再获取初始化PE的第二个维度中的第一个值即为【1,1,512】,最后将这两个PE进行在第二个维度上concat:【1,145,512】,得到x的PE。
经过stage4的操作,得到的输出经过layer norm,feature maps的shape :【bs,145,512】;
获取第二个维度第一个位置的值,即取出class token所在的值:【bs,512】。
最后经过一个class head,使用线性映射实现,得到最终的类别分数预测:【bs,5】。
另外,关于loss和后处理实现类似我之前讲解的Conformer源码,这里就不再过多的展开,不清楚的小伙伴可以去看看我之前的博客。















 2028
2028











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











