







Code: https://github.com/whai362/PVT
目录
Pyramid Vision Transformer(PVT)
文章动机
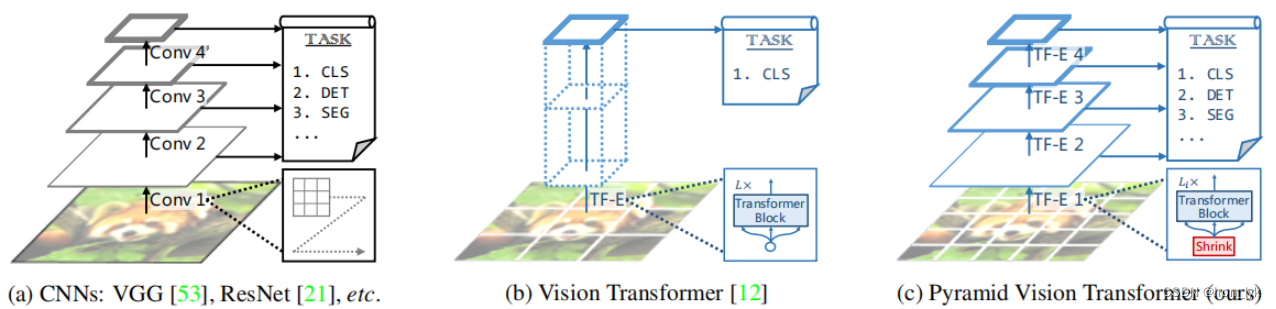
许多CNN Backbones使用金字塔结构来完成目标检测、实例分割等任务,本文将CNN中的金字塔结构引入到Transformer中去,来生成multi-scale(多尺度)的特征图,来更好的完成这些任务。
Pyramid Vision Transformer(PVT)

金字塔的结构如上图所示,由于本文方法对目前想做的研究没有太大的帮助,所以没细看。
启发
比较有意思的是在Encoder部分,作者在进行multi-head attention之前,将K和V的空间尺寸进行了缩减,目的是为了减小计算量。

启发于本文中如下左图的机制,对于一个query,更新时可以并不是对所有的query进行attention,而是对欧氏空间中距离最近的local进行attention,其他的不care。(ps : 这种想法很直接,可能已有人做)















 3008
3008











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









