




本篇博文基本不涉及PCA的任何数学过程,仅讲解在sklearn中如何调用相关类实现PCA降维
1.维度和降维的定义
1.1维度的定义
对普通数组和Series来说,维度就是shape返回的结果,shape中返回了几个数字,就是几维

数组中的每一张表,都可以是一个特征矩阵,针对每一个特征矩阵,维度一般指的都是特征的数量,一个特征是一维,二个特征是两维,n个特征是n维

对于图像来说,维度就是图像中特征向量的数量。特征向量可以理解为是坐标轴,一个特征向量定义一条直线,是一维,两个相互垂直的特征向量定义一个平面,即一个直角坐标系,就是二维,三个相互垂直的特征向量定义一个空间,即一个立体直角坐标系,就是三维。三个以上的特征向量相互垂直,定义人眼无法看见,也无法想象的高维空间。

1.2降维的含义

假设原始的数据集是3D的,它们有3个坐标轴x1x2x3,但是绝大部分的数据点都在同一个2D平面的周围,我们将此3D数据在2D平面上进行投影,这意味着我只需要2个数z1和z2就可以代表这些点在平面中的位置

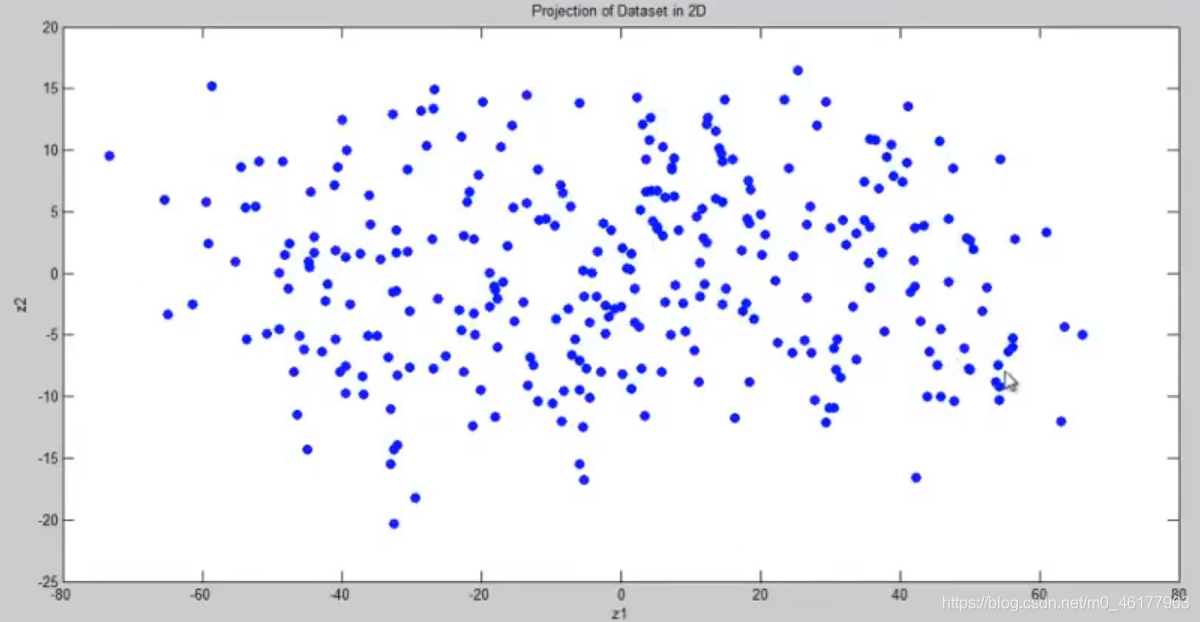
这时候,我们将三维的样本点的数据压缩到的二维上,即实现了三维变二维,并且尽可能保留原始数据的信息,一个成功的降维,就实现了。
降维算法中的”降维“,指的是降低特征矩阵中特征的数量,降维的目的是为了让算法运算更快,效果更好,另外是为了数据可视化,三维及以下的特征矩阵,是可以被可视化的,这可以帮助我们很快地理解数据的分布,而三维以上特征矩阵的则不能被可视化,数据的性质也就比较难理解。
在降维过程中,我们会减少特征的数量,这意味着删除数据,数据量变少则表示模型可以获取的信息会变少,模型的表现可能会因此受影响。
高维数据中,必然有一些特征是不带有有效的信息的(比如噪音),或者有一些特征带有的信息和其他一些特征是重复的(比如一些特征可能会高度线性相关)。我们希望能够找出一种办法来帮助我们衡量特征上所带的信息量,让我们在降维的过程中,能够即减少特征的数量,又保留大部分有效信息,即将那些带有重复信息的特征合并,并删除那些带无效信息的特征,逐渐创造出能够代表原特征矩阵大部分信息的,特征更少的,新特征矩阵
1.3降维的步骤
将一个n维特征矩阵降为k维特征矩阵,大致有如下几个步骤:
- 输入原数据,结构为(m,n)。找出原本的n个特征向量构成的n维空间V
- 决定降维后的特征数量K
- 通过某种变化,找出n个新的特征向量以及它们构成的新n维空间
- 找出原始数据在新特征空间V中的n个特征向量上对应的值,即将原始数据映射到新空间中
- 选取前k个信息量最大的特征,删掉没有选中的特征,成功将n维空间V降为k维
2.PCA和SVD
在上述的步骤3中,我们用来找出n个新特征向量,让数据能够被压缩到少数特征上并且总信息量不损失太多的技术就是矩阵分解。PCA和SVD是两种不同的降维算法,但他们都遵从上面的过程来实现降维,只是两种算法中矩阵分解的方法不同,信息量的衡量指标不同罢了。
PCA使用方差作为信息量的衡量指标(方差很小或者为0的特征不带有有效信息了,因为它对样本没有区分度),并且特征值分解来找出空间V。样本方差,又称可解释性方差,方差越大,特征所带的信息量越多。降维完成之后,PCA找到的每个新特征向量就叫做“主成分”,而被丢弃的特征向量被认为信息量很少,这些信息很可能就是噪音。
PCA,是将已存在的特征进行压缩,降维完毕后的特征不是原本的特征矩阵中的任何一个特征,而是通过某些方式组合起来的新特征。通常来说,在新的特征矩阵生成之前,我们无法知晓PCA都建立了怎样的新特征向量,新特征矩阵生成之后也不具有可读性,我们无法判断新特征矩阵的特征是从原数据中的什么特征组合而来,新特征虽然带有原始数据的信息,却已经不是原数据上代表着的含义了。以PCA为代表的降维算法因此是特征创造的一种
SVD使用奇异值分解来找出空间V,奇异值是SVD中用来衡量特征上信息量的指标
class sklearn.decomposition.PCA
class sklearn.decomposition.PCA(n_components=None, *, copy=True, whiten=False,
svd_solver='auto', tol=0.0, iterated_power='auto',
random_state=None):
2.1重要参数n_components
n_components是我们降维后需要的维度,即降维后需要保留的特征数量,是降维流程中第2步里需要确认的k值,一般输入[0, min(x.shape)]范围中的整数。这是一个需要我们人为去确认的超参数,并且我们设定的数字会影响到模型的表现。如果留下的特征太多,就达不到降维的效果,如果留下的特征太少,那新特征向量可能无法容纳原始数据集中的大部分信息,因此,n_components既不能太大也不能太小。
2.1.1案例:高维数据的可视化
下面看一个鸢尾花数据集(特征是4维)的案例,将n_components取为2,取2的原因是方便可视化。将特征向量为4维的鸢尾花数据集降至2维后,用散点图画出来,看看三种不同的鸢尾花在新的二维特征向量中的分布情况
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
import pandas as pd
#1.数据准备
iris = load_iris()
x = iris.data
y = iris.target
#print(x.shape) #对于数组(150,4)来说是二维的
#print(pd.DataFrame(x)) #对于特征矩阵来说,这是4维的,注意和数组的维度相区分
#2.建立模型,调用PCA
pca = PCA(n_components=2) #实例化
pca = pca.fit(x) #拟合模型
x_new = pca.transform(x) #获取新矩阵。也可以一步到位,x_new = pca.fit_transform(x)。
#现在x_new.shape=(150,2),即数据集由原本的x->x_new,降至了二维可以可视化了,下面看看三种不同的鸢尾花在新的特征矩阵中的分布情况
#3.可视化。这段代码最好用循环实现,为了更清晰,这里重复写三次
plt.figure() #画布。画三个图在同一个画布上
plt.scatter(x_new[y==0 , 0] , x_new[y==0 , 1] , c="red" , label=iris.target_names[0])
plt.scatter(x_new[y==1 , 0] , x_new[y==1 , 1] , c="black" , label=iris.target_names[1])
plt.scatter(x_new[y==2 , 0] , x_new[y== 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1968
1968




 到【灌水乐园】发言
到【灌水乐园】发言







