







CBNetV2论文解读
论文地址:CBNetV2:A Composite Backbone Network Architecture for Object Detection
什么是CBNetV2?
CBNetV2使用开源的预训练好的主干网络组成高性能的检测器。
这篇论文的主要贡献在于:
1.提出了更一般、更高效的网络CBNetV2。
2.提出了Dense Higher-Level Composition (DHLC)风格的连接方式和Assistant Supervision(辅助监督)模块,能够更高效的使用预训练权重。
3.Dual-Swin-L在COCO数据集上单模型单尺度的表现超过了Swin-L
CBNetV2的结构

CBNetV2的主干网络分为两个部分:Assisting Backbones 和 Lead Backbone。这里我将其称为辅助主干和主导主干。主导主干仅包含一个主干网络,辅助主干由多个主干网络组成。
如上图所示,辅助主干的每一个stage的输出流入到其继承主干(即连接在其后的下一个主干网络)的低层级作为输入。最后主导主干的特征将被“喂”进Neck和Detection Head用于回归和分类预测。与简单的更深或者更宽的网络相比,CBNetV2整合了多个主干网络的高层级和低层级特征,并且将感受野扩展到更高效的目标检测。值得注意的是,每一个主干网络都由已知的开源预训练权重进行初始化。
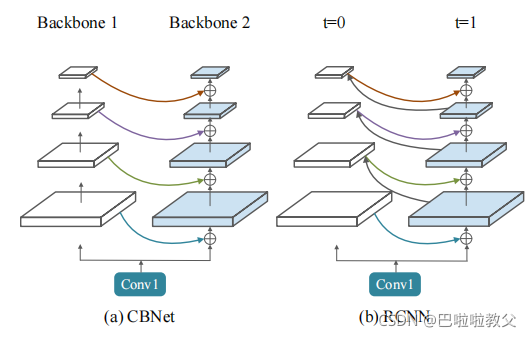
CBNetV2由K个相同的主干网络构成,其中K ≥ 2 \geq2 ≥2,当K=2时,我们称其为Dual-Backbone(DB),K=3时称其为Triple-Backbone(TB)。
如图1所示,两个类型的主干:Lead Backbone B k B_k Bk 和 Assistant Backbone B 1 、 B 2 、 . . . . B k − 1 B_1、B_2、....B_{k-1} B1、B2、....Bk−1。每个主干网络包含L个stage(通常L=5)。并且每个stage包含若干个卷积层能够输出相同大小的特征图以便输入。第 l − t h l-th l−thstage具有非线性转换 F l F^l Fl()。
第
l
l
l层的输出:
x
l
=
F
l
(
x
l
−
1
)
,
l
≥
2
x^l=F^l(x^{l-1}),l\geq2
xl=Fl(xl−1),l≥2
不同的是我们采用辅助主干来提高主导主干的表达能力,因此,等式为:
x
k
l
=
F
k
l
(
x
k
l
−
1
+
g
l
−
1
(
x
k
−
1
)
)
,
l
≥
2
,
k
=
2
,
3
,
.
.
.
,
K
x^l_k=F^l_k(x^{l-1}_k+g^{l-1}(x_{k-1})),l\geq2,k=2,3,...,K
xkl=Fkl(xkl−1+gl−1(xk−1)),l≥2,k=2,3,...,K
g
l
−
1
(
)
g^{l-1}()
gl−1()代表连接方式,
x
k
−
1
x_{k-1}
xk−1代表着辅助主干
B
k
−
1
B_{k-1}
Bk−1的输出,经过连接转换的
x
k
−
1
x_{k-1}
xk−1和第K个主干的第l-1层stage的输出共同作为第l层stage的输入,通过非线性转换
F
k
l
F^l_k
Fkl得到第K个主干的第l层stage的输出
x
k
l
x^l_k
xkl。
值得注意的是每个主干网络的第一个stage是权重共享的。
对于检测任务,仅仅主导主干的输出特征会输入到neck和head,辅助主干的输出输入到它的继承主干(即它的下一个主干)。值得注意的是辅助主干 B 1 、 B 2 、 . . . 、 B k − 1 B_1、B_2、...、B_{k-1} B1、B2、...、Bk−1能够用于不同的主干结构(比如:ResNet、ResNeXt、Res2Net和Swin Transformer,并且它们能够从预训练权重中进行初始化)
Possible Composite Styles
对于主干网络之间的连接方式,提出了以下五种风格:
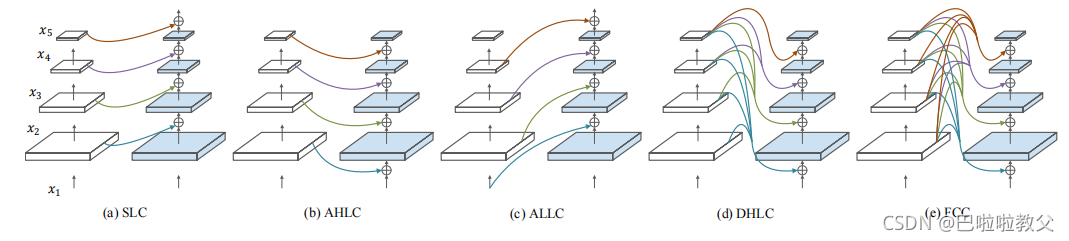
style1.Same Level Composition(SLC)
这是最简单最直接的连接方式,将每个stage的输出接到下一个主干的同层级的stage。比如将第k-1个主干的第二个stage的输出接到第k个主干的第二个stage后面一起作为第三个stage的输入。
g
l
(
x
)
=
w
(
x
l
)
,
l
≥
2
g^l(x)=w(x^l),l\geq2
gl(x)=w(xl),l≥2
其中
w
w
w代表一个1x1的卷积层和一个BN层。
style2.Adjacent Higer-Level Composition(AHLC)
这个灵感来自于FPN。top-down方式上丧失一些空间上的信息,但是具有更强的语义信息,高层级特征能够增强bottom-up中的低层级特征。即将第k-1个主干的第l+1个stage的输出接到第k个主干的第l个stage的后面一起作为第l+1个stage的输入。
g
l
(
x
)
=
U
(
w
(
x
l
+
1
)
)
,
l
≥
1
g^l(x)=U(w(x^{l+1})),l\geq1
gl(x)=U(w(xl+1)),l≥1
其中U()代表上采样操作。
style3.Adjacent Lower-Level Composition(ALLC)
与AHLC有点类似,ALLC是将低层信息“喂”到高层。即将第k-1个主干的第l个stage的输出接到第k个主干的第l+1个stage的后面一起作为第l+2个stage的输入。
g
l
(
x
)
=
D
(
w
(
x
l
−
1
)
)
,
l
≥
2
g^l(x)=D(w(x^{l-1})),l\geq2
gl(x)=D(w(xl−1)),l≥2
其中D()代表了下采样操作。
style4.Dense Higher-Level Composition(DHLC)
在DenseNet中,每一层都与其随后的所有层相连来构建庞大的特征。
g
l
(
x
)
=
∑
i
=
l
+
1
L
U
(
w
i
(
x
i
)
)
,
l
≥
1
g^l(x)=\sum_{i=l+1}^{L}U(w_i(x^i)),l\geq1
gl(x)=i=l+1∑LU(wi(xi)),l≥1
正如图中所示,K=2时,我们将前一个主干的所有高层级特征组合在一起接到后面主干的低层级中。
style5.Full-connected Composition(FCC)
FCC是将前一个主干的所有层级特征组合在一起接到后面主干的每一个stage。与DHLC相比,在低层级中实现了连接。
g
l
(
x
)
=
∑
i
=
2
L
I
(
w
i
(
x
i
)
)
,
l
≥
1
g^l(x)=\sum_{i=2}^{L}I(w_i(x^i)),l\geq1
gl(x)=i=2∑LI(wi(xi)),l≥1
其中
I
(
)
I()
I()代表scale-resizing。
当
i
≥
l
时
,
I
(
)
=
D
(
)
,
当
i
≤
l
时
,
I
(
)
=
U
(
)
当i\geq l时,I()=D(),当i\leq l时,I()=U()
当i≥l时,I()=D(),当i≤l时,I()=U()
Assistent Supervision
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fjcWH32N-1635857983320)(C:\Users\Wangby\AppData\Roaming\Typora\typora-user-images\image-20211102185436776.png)]](https://i-blog.csdnimg.cn/blog_migrate/e032f42ff76d88458e8d764e189133dc.png)
可以看到两个主干网络都与neck相连,前面的主干(辅助主干)连接的是Detection Head1,后面的主干(主导主干)连接的是Detection Head 2 。Detection Head 2使用辅助主干作为输入,产生辅助监督。其中FPN和Detection Head共享相同的权重。
所以关于Loss的定义为:
L
=
L
L
e
a
d
+
∑
i
=
1
K
−
1
(
λ
i
⋅
L
A
s
s
i
s
t
i
)
L=L_{Lead}+\sum_{i=1}^{K-1}(\lambda_i\cdot L^i_{Assist})
L=LLead+i=1∑K−1(λi⋅LAssisti)
其中
L
l
e
a
d
L_{lead}
Llead是lead backbone的损失,
L
A
s
s
i
s
t
L_{Assist}
LAssist是Assist backbone的损失,
λ
i
\lambda_i
λi是第i个辅助主干所占的权重。
Pruning Strategy for CBNetV2
为了减少模型的复杂度,提出了删减的策略,即在第2,3,…,K个backbone中删除不同数量的stage
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iCwXLqi0-1635857983322)(C:\Users\Wangby\AppData\Roaming\Typora\typora-user-images\image-20211102204631909.png)]](https://i-blog.csdnimg.cn/blog_migrate/073cb5e246cc41317838a9ec08a2e63c.png)
以DB为例,其中 s i s_i si代表中在Lead Backbone中stage的数量{ x 6 − i , x 7 − i , . . . , x 5 ∣ i = 0 , 1 , 2 , 3 , 4 x_{6-i},x_{7-i},...,x_5|i=0,1,2,3,4 x6−i,x7−i,...,x5∣i=0,1,2,3,4}。
Performance
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bIXsRnoW-1635857983323)(C:\Users\Wangby\AppData\Roaming\Typora\typora-user-images\image-20211102205328350.png)]](https://i-blog.csdnimg.cn/blog_migrate/db70e4efbb6b26d77354c3f4811b527a.png)
Dual-Res2Net101-DCN在COCO上数据集超越了先前所有的anchor-base和anchor-free方法,创造了新的记录。
![[外链图片转存中...(img-LBwVUD3h-1635857983323)]](https://i-blog.csdnimg.cn/blog_migrate/f67f7d7db29ab7c013c7fdf244b56817.png)
在检测和实例分割任务上,Dual-Swin-L在训练较少的epoch的情况下超越了先前所有的anchor-base和anchor-free方法,创造了新的记录。

















 764
764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









