







Emotion-Cause Pair Extraction: A New Task to Emotion Analysis in Texts
文章目录
Abstract
Emotion cause extraction (ECE): the task aimed at extracting the potential causes behind certain emotions in text
ECE - 提取文本中特定情绪的潜在原因
two shortcomings:
- the emotion must be annotated before cause extraction in ECE, which greatly limits its applications in real-world scenarios
- the way to [first annotate emotion and then extract the cause] ignores the fact that they are mutually indicative
该论文提出 emotion-cause pair extraction (ECPE) - aims to extract the potential pairs of emotions and corresponding causes in a document
提取:(情绪 - 相应原因)
a 2-step approach to address this new ECPE task:
- Performs individual emotion extraction and cause extraction via multi-task learning
- conduct emotion-cause pairing and filtering.
Introduction
The ECE task was first proposed and defined as a word-level sequence labeling problem in Lee et al. (2010).
最早的 ECE 任务都是词级别的
To solve the shortcoming of extracting causes at word level, Gui et al. (2016a) released a new corpus which has received much attention in the following study and become a benchmark dataset for ECE research.
- emotion clause: a clause that contains emotions
- cause clause: a clause that contains causes
The ECE task was formalized as a clause-level binary classification problem in Gui et al. (2016a).
Gui et al. (2016a) 将 ECE 任务规范化为一个从句级别的二分类问题
goal: detect for each clause in a document, whether this clause is a cause given the annotation of emotion.
目标
two shortcomings:
- the emotion must be annotated before cause extraction in ECE, which greatly limits its applications in real-world scenarios
- the way to [first annotate emotion and then extract the cause] ignores the fact that they are mutually indicative
缺陷
emotion cause pair extraction (ECPE) - aims to extract all potential pairs of emotions and corresponding causes in a document.
提取:(情绪 - 相应原因)
The goal of ECE is to extract the corresponding cause clause of the given emotion. In addition to a document as the input, ECE needs to provide annotated emotion at first before cause extraction. In contrast, the output of our ECPE task is a pair of emotioncause, without the need of providing emotion annotation in advance.
改进之处:ECPE 不再需要提前提供情绪标注
To address this new ECPE task, we propose a two-step framework:
- converts the emotion-cause pair extraction task to two individual subtasks (emotion extraction and cause extraction respectively) via two kinds of multi-task learning networks, with the goal to extract a set of emotion clauses and a set of cause clauses.
- performs emotion-cause pairing and filtering.
- combine all the elements of the two sets into pairs
- train a filter to eliminate the pairs that do not contain a causal relationship.
第一步:将 ECPE 任务分解为两个独立的子任务 —— 提取“情绪”集合与“原因”集合
第二步:将两个集合相结合,并过滤没有相关因果的元素对
Related Work
……
Task
Given a document consisting of multiple clauses
d
=
[
c
1
,
c
2
,
.
.
.
,
c
∣
d
∣
]
d=[c_{1}, c_{2}, ...,c_{|d|}]
d=[c1,c2,...,c∣d∣], the goal of ECPE is to extract a set of emotion-cause pairs in
d
d
d:
P
=
{
⋯
,
(
c
e
,
c
c
)
,
⋯
}
P=\{ \cdots , (c^e, c^c), \cdots \}
P={⋯,(ce,cc),⋯}
where
c
e
c^e
ce is an emotion clause and
c
c
c^c
cc is the corresponding cause clause.
Approach
-
Individual Emotion and Cause Extraction.
Convert the emotion-cause pair extraction task to two individual subtasks (emotion extraction and cause extraction respectively). Two kinds of multi-task learning networks are proposed to model the two sub-tasks in a unified framework, with the goal to extract:
- a set of emotion clauses E = { c 1 e , ⋅ ⋅ ⋅ , c m e } E = \{c^e_1, · · · , c^e_m\} E={c1e,⋅⋅⋅,cme} for each document
- a set of cause clauses C = { c 1 c , ⋅ ⋅ ⋅ , c n c } C = \{c^c_1, · · · , c^c_n\} C={c1c,⋅⋅⋅,cnc} for each document
-
Emotion-Cause Pairing and Filtering.
We then pair the emotion set E and the cause set C by applying a Cartesian product to them. This yields a set of candidate emotion-cause pairs. We finally train a filter to eliminate the pairs that do not contain a causal relationship between emotion and cause.
Step 1: Individual Emotion and Cause Extraction
Independent Multi-task Learning
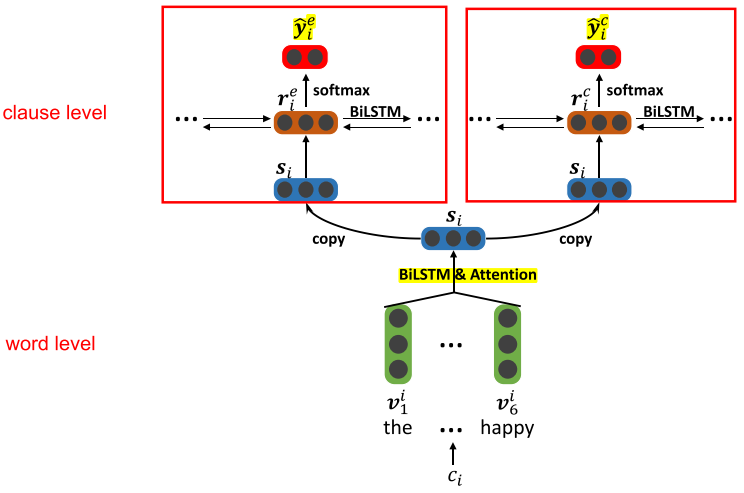
The Lower Layer
The lower layer consists of a set of word-level Bi-LSTM modules, each of which corresponds to one clause, and accumulate the context information for each word of the clause.
The hidden state of the j t h j^{th} jth word in the i t h i^{th} ith clause h i , j h_{i,j} hi,j is obtained based on a bi-directional LSTM.
Attention mechanism - get a clause representation s i s_i si.
The Upper Layer
The upper layer consists of two components:
- emotion extraction
- cause extraction
Each component is a clause-level BiLSTM which receives the independent clause representations [ s 1 , s 2 , . . . , s ∣ d ∣ ] [s_1, s_2, ..., s_{|d|}] [s1,s2,...,s∣d∣] obtained at the lower layer as inputs.
The hidden states of two component Bi-LSTM,
r
i
e
r^e_i
rie and
r
i
c
r^c_i
ric, can be viewed as the context-aware representation of clause
c
i
c_i
ci, and finally feed to the softmax layer for emotion prediction and cause predication:
y
^
i
e
=
s
o
f
t
m
a
x
(
W
e
r
i
e
+
b
e
)
\hat y^e_i = softmax(W^er^e_i+b^e)
y^ie=softmax(Werie+be)
y ^ i c = s o f t m a x ( W c r i c + b c ) \hat y^c_i = softmax(W^c r^c_i+b^c) y^ic=softmax(Wcric+bc)
where the superscript e e e and c c c denotes emotion and cause, respectively.
激活函数 - softmax
The loss of the model is a weighted sum of two components:
L
p
=
λ
L
e
+
(
1
−
λ
)
L
c
L^p = \lambda L^e + (1-\lambda)L^c
Lp=λLe+(1−λ)Lc
where
L
e
L^e
Le and
L
c
L^c
Lc are the cross-entropy error of emotion predication and cause predication respectively, and
λ
\lambda
λ is a tradeoff parameter.
损失函数 - 情绪预测与原因预测各自的交叉熵损失的加权之和
Interactive Multi-task Learning
The two sub-tasks (emotion extraction and cause extraction) are not mutually independent:
- providing emotions can help better discover the causes
- knowing causes may also help more accurately extract emotions
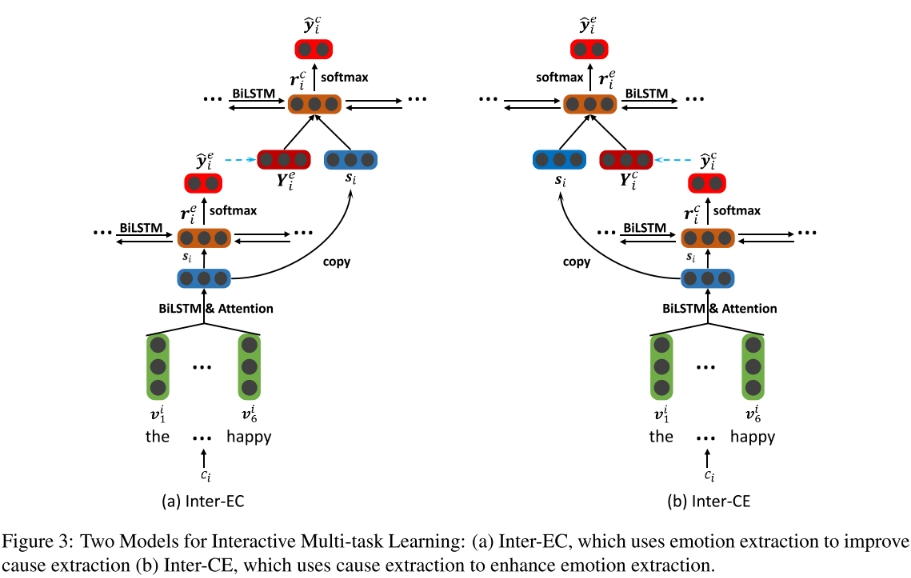
This one is an enhenced version of the former one.
- Inter-EC - using emotion extraction to improve cause extraction
- Inter-CE - using cause extraction to enhance emotion extraction
The first component takes the independent clause representations [ s 1 , s 2 , . . . , s ∣ d ∣ ] [s_1, s_2, ..., s_{|d|}] [s1,s2,...,s∣d∣] obtained at the lower layer as inputs for emotion extraction. The hidden state of clause-level Bi-LSTM r i e r^e_i rie is used as feature to predict the distribution of the i-th clause y ^ i e \hat y^e_i y^ie. Then we embed the predicted label of the i-th clause as a vector Y i e Y^e_i Yie , which is used for the next component.
Another component takes ( s 1 ⨁ Y 1 e , s 2 ⨁ Y 2 e , . . . , s ∣ d ∣ ⨁ Y ∣ d ∣ e ) (s_1 \bigoplus Y^e_1, s_2 \bigoplus Y^e_2, ..., s_{|d|} \bigoplus Y^e_{|d|}) (s1⨁Y1e,s2⨁Y2e,...,s∣d∣⨁Y∣d∣e) as inputs for cause extraction, where ⨁ \bigoplus ⨁ represents the concatenation operation.
The hidden state of clause-level Bi-LSTM r i c r^c_i ric is used as feature to predict the distribution of the i-th clause y ^ i c \hat y^c_i y^ic.
The loss of the model is a weighted sum of two components:
L
p
=
λ
L
e
+
(
1
−
λ
)
L
c
L^p = \lambda L^e + (1-\lambda)L^c
Lp=λLe+(1−λ)Lc
Step 2: Emotion-Cause Pairing and Filtering
In Step 1, we finally obtain a set of emotions E = c 1 e , ⋅ ⋅ ⋅ , c m e E = {c^e_1, · · · , c^e_m} E=c1e,⋅⋅⋅,cme and a set of cause clauses C = c 1 c , ⋅ ⋅ ⋅ , c n c C = {c^c_1, · · · , c^c_n} C=c1c,⋅⋅⋅,cnc.
The goal of Step 2 is then to pair the two sets and construct a set of emotion-cause pairs with causal relationship.
Firstly, we apply a Cartesian product to
E
E
E and
C
C
C, and obtain the set of all possible pairs:
P
a
l
l
=
{
⋯
,
(
c
i
e
,
c
i
c
)
,
⋯
}
P_{all} = \{ \cdots, (c^e_i,c^c_i), \cdots \}
Pall={⋯,(cie,cic),⋯}
Secondly, we represent each pair in
P
a
l
l
P_{all}
Pall by a feature vector composed of three kinds of features:
x
(
c
i
e
,
c
j
c
)
=
[
s
i
e
,
s
j
c
,
v
d
]
x_{(c^e_i,c^c_j)}=[s^e_i,s^c_j,v^d]
x(cie,cjc)=[sie,sjc,vd]
where
s
e
s^e
se and
s
c
s^c
sc are the representations of the emotion clause and cause clause respectively, and
v
d
v^d
vd represents the distances between the two clauses.
A Logistic regression model is then trained to detect for each candidate pair (
c
i
e
c^e_i
cie,
c
j
c
c^c_j
cjc), whether
c
i
e
c^e_i
cie and
c
j
c
c^c_j
cjc have a causal relationship:
y
^
(
c
i
e
,
c
j
c
)
←
δ
(
θ
T
x
(
c
i
e
,
c
j
c
)
)
\hat y_{(c^e_i,c^c_j)} \leftarrow \delta (\theta^Tx(c^e_i,c^c_j))
y^(cie,cjc)←δ(θTx(cie,cjc))
- y ^ ( c i e , c j c ) = 1 \hat y_{(c^e_i,c^c_j)}=1 y^(cie,cjc)=1 → \rightarrow → ( c i e , c j c ) (c^e_i,c^c_j) (cie,cjc) is a pair with causal relationship
- y ^ ( c i e , c j c ) = 0 \hat y_{(c^e_i,c^c_j)}=0 y^(cie,cjc)=0 → \rightarrow → ( c i e , c j c ) (c^e_i,c^c_j) (cie,cjc) is a pair without causal relationship
- δ \delta δ → \rightarrow → the Sigmoid function















 550
550











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









