







论文笔记-RecSys2023-TALLRec: An Effective and Efficient Tuning Framework to Align Large Language Model with Recommendation(包含源码运行)
论文内容
论文下载链接: TALLRec
1.挑战
基于上下文学习的LLM推荐存在以下挑战:
-
训练LLM的语言处理任务和推荐任务之间存在巨大的差异,而且在训练LLM时面向推荐任务的语料库非常有限。
-
LLM的效果受低层推荐模型的限制,由于其容量有限,候选列表中可能没有目标项目。
2.TALLRec
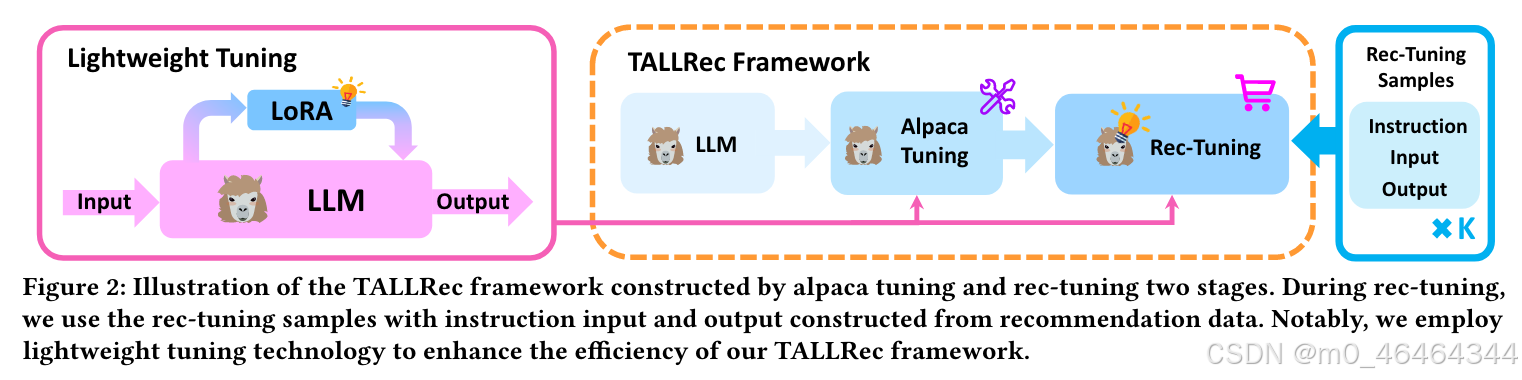
提出两个具有轻量级实现的TALLRec调整阶段:
-
alpaca tuning,LLM的通用训练过程,增强LLM的泛化能力。
-
rec-tuning,模拟指令调优,针对推荐任务调整LLM。
2.1 alpaca tuning
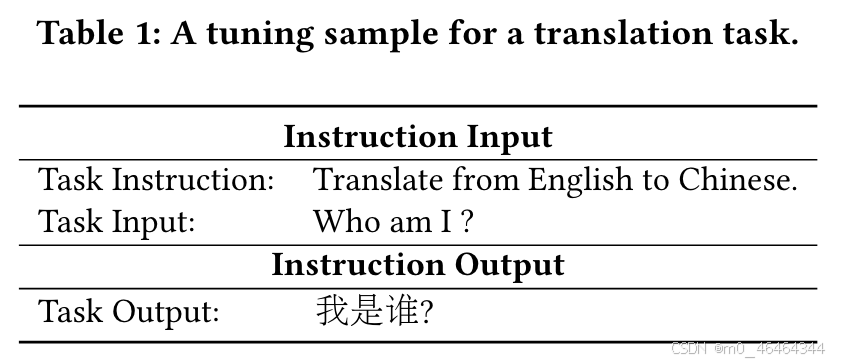
使用Alpaca提供的自指导数据来训练LLM,指导数据如下:
-
使用自然语言定义task instruction;
-
设计并构建输入输出(Task Input/0utput);
-
把Task Instruction和Task Input整合成指令输入,指令输出作为对应输出;
-
把指令输入和指令输出作为格式对,对LLM 指令微调。
在调优过程中使用条件语言建模目标:
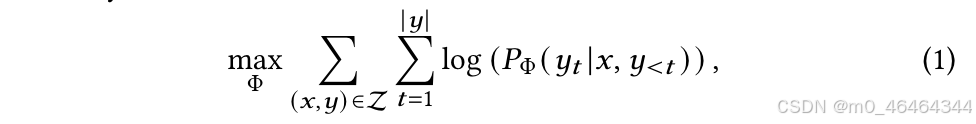
x,y表示“指示输入”和“指示输出”,yt表示y的第t个token,Φ是模型M的初始参数,Z是训练数据。
2.2 rec-tuning
将推荐数据格式化为指令调整模式,类似alpaca tuning微调LLM:

-
将推荐数据格式化为指令微调模式;
-
构建Task Instruction直接让LLM给出答案,并规定Task 0utput输出答案格式(Y/N);
-
将Task Input数据基于ratings划分为两类, liked items和disliked items,同时包含target new item;
-
最后整合Instruction Input和Instruction output。
2.3 轻量级调优
使用LoRA,冻结预训练的模型参数,并将可训练的秩分解矩阵引入Transformer架构的每一层。
通过优化秩分解矩阵,我们可以有效地合并补充信息,同时保持原始参数处于冻结状态。最终的学习目标可以表示为:
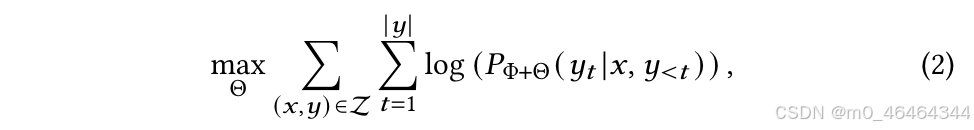
Θ是LoRA参数,仅在训练过程中更新LoRA参数,只需要原来LLM千分之一的参数量就可以完成训练过程。
2.4 主干网络选择
选择使用LLMs-LLaMA进行实验,它是目前性能最好的开源LLM,并且训练数据也是公开的。
3.实验
3.1 设置
数据集
对最近10000个交互进行采样,并将其按照 8:1:1的比例分为训练集、验证集和测试集。为了构建调整样本,目标项之前的10次交互将被保留为历史交互。对于电影数据集,将评分>3的交互视为“喜欢”,否则视为“不喜欢”。对于图书数据集,将评分>5视为“喜欢”,否则为“不喜欢”。
K-shot训练设置
K代表使用的训练样本的数量。通过设置一个极小的K值可以测试一种方法是否可以在训练数据非常有限的情况下快速从LLM中获得推荐能力。
基线
-
基于LLM的方法:Alpaca-LoRA、TextDavinvi-002、Text-Daviniv-003和ChatGPT
-
传统方法:GRU4Rec、Caser、SASRec、DROS、GRU-BERT、DROS-BERT
评估指标
AUC
3.2 实验结果
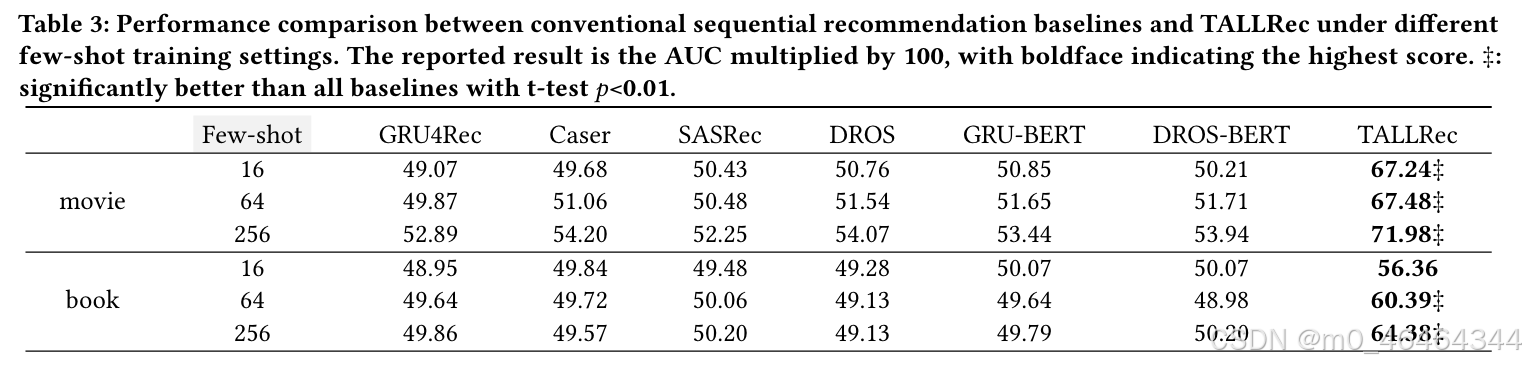
和传统模型的比较:
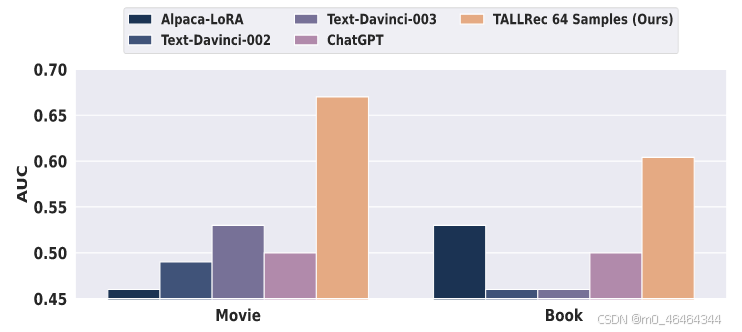
和基于LLM方法的比较:
结论:
-
TALLRec性能优于传统模型和基于LLM的模型;
-
基于LLM的模型性能接近于随机猜测(AUC≈0.5),TALLRec的性能体现了推荐数据对微调LLM的重要性;
-
传统模型在少样本学习时表现不佳;
-
GRU-BERT和DROS-BERT相对于GRU4Rec和DROS并没有表现出显著的改进,表明添加文本描述无法增强少样本训练的性能。
3.3 消融实验
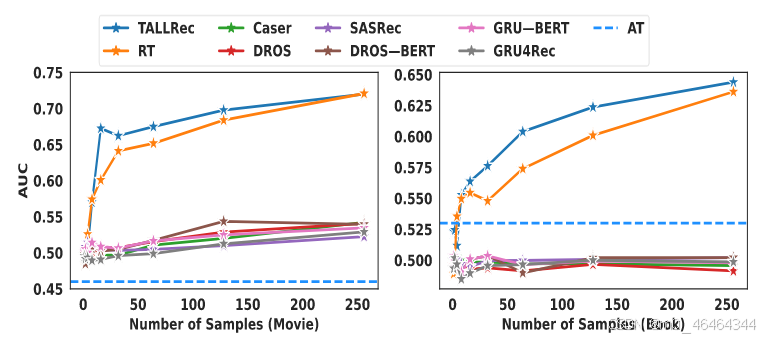
结论:
-
AT性能较差,说明re-tuning有效激发了LLM的推荐能力;
-
训练数据不足时,TALLRec优于RT,说明alpaca tuning可以增强LLM的泛化能力;训练数据增加,RT接近TALLRec,因为训练数据增加,从其他任务中获得的泛化能力的重要性就会减弱;
-
样本数量增加,TALLRec一直优于基线。
3.4 跨领域泛化分析
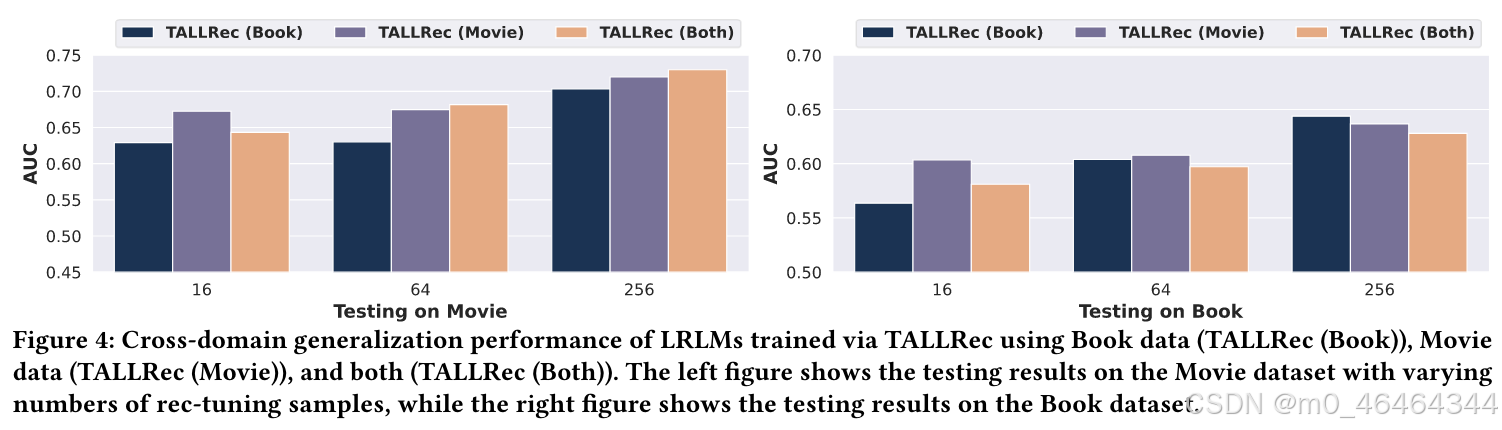
结论:
-
TALLRec表现了良好的泛化能力,TALLRec(Movie)在book数据集上性能优于TALLRec(Book);
-
在某些情况下,TALLRec(Both)优于单独的域,表明 TALLRec可以无缝集成来自不同领域的数据,以增强其泛化性能。
4.相关工作
-
基于LLM方法:利用了GPT3.5系列模型的交互能力并应用了In-context Learning,如Chat-Rec和NIR等。
-
顺序推荐:旨在根据用户的历史交互序列推断用户的下一次交互。现有方法忽视了LLM的泛化能力,导致LLM4Rec的探索不足。
5.总结
提出TALLRec 框架,该框架可以通过两个调优阶段(alpaca tuning和re-tuning)将大语言模型与推荐任务有效结合。
源码运行
源码github地址: https://github.com/SAI990323/TALLRec
- 新建虚拟环境py310
conda create -n py310 python=3.10
conda install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=11.7 -c pytorch -c nvidia
pip install -r requirements.txt
- 更新peft包版本
pip uninstall peft -y
pip install git+https://github.com/huggingface/peft.git@e536616888d51b453ed354a6f1e243fecb02ea08
-
修改/home/user/TALLRec/shell/instruct_7B.sh
output_dir=/home/user/TALLRec/
base_model=/home/user/LLM/llama-7b-hf/
train_data=/home/user/TALLRec/data/movie/train.json
val_data=/home/user/TALLRec/data/movie/valid.json
instruction_model=/home/user/TALLRec/alpaca-lora-7B/
(也可以将/home/user/TALLRec换为.) -
修改LD_LIBRARY_PATH(在3个finetune的py文件中)
将/data/baokq/miniconda3/envs/alpaca_lora/lib/替换为/home/user/anaconda3/envs/pytorch/lib/ -
更换文件夹alpaca-lora-7B
下载地址:https://drive.google.com/file/d/1teUwLm4BOqhngfCKKXE1tiMhJPf_FvRJ/view -
激活py310环境并进入代码所在的文件夹
conda activate py310
cd TALLRec
- 训练TALLRec
bash ./shell/instruct_7B.sh 0 2023
nohup bash ./shell/instruct_7B.sh 0 2023 > output.log 2>&1 &
如果报错AttributeError: ‘_IncompatibleKeys’ object has no attribute ‘print_trainable_parameters’
则修改finetune_rec.py中206行:
# model = set_peft_model_state_dict(model, adapters_weights)
set_peft_model_state_dict(model, adapters_weights)
得到以下结果并生成文件夹/home/user/TALLRec/_2023_64:
{‘train_runtime’: 3885.7795, ‘train_samples_per_second’: 3.294, ‘train_steps_per_second’: 0.051, ‘train_loss’: 0.30903920650482175, ‘epoch’: 200.0}
100%|█████████████████████████████████████████████████████████████████████████████| 200/200 [1:04:45<00:00, 19.43s/it]
If there’s a warning about missing keys above, please disregard 😃
-
修改/home/user/TALLRec/shell/evaluate.sh
base_model=/home/user/LLM/llama-7b-hf/
test_data=./data/movie/test.json -
修改/home/user/TALLRec/evaluate.py
base_model: str = “/home/user/LLM/llama-7b-hf”,
lora_weights: str = “/home/user/TALLRec/_2023_64”,
test_data_path: str = “/home/user/TALLRec/data/movie/test.json”, -
在验证集上评估模型的测试结果
bash ./shell/evaluate.sh 0 /home/user/TALLRec/_2023_64
如果报错torch.cuda.OutOfMemoryError: CUDA out of memory.
则修改batch_size=4
得到以下结果并生成文件/home/user/TALLRec/_2023_64.json
logits = torch.tensor(scores[:,[8241, 3782]], dtype=torch.float32).softmax(dim=-1)
250it [28:04, 6.74s/it]
1000it [00:00, 1331102.51it/s]

















 3981
3981

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









