







在pytorch中,函数torch.bucketize(input, boundaries)可以根据boundaries序列返回input中每个元素的区间索引。详细介绍如下:
函数详解:
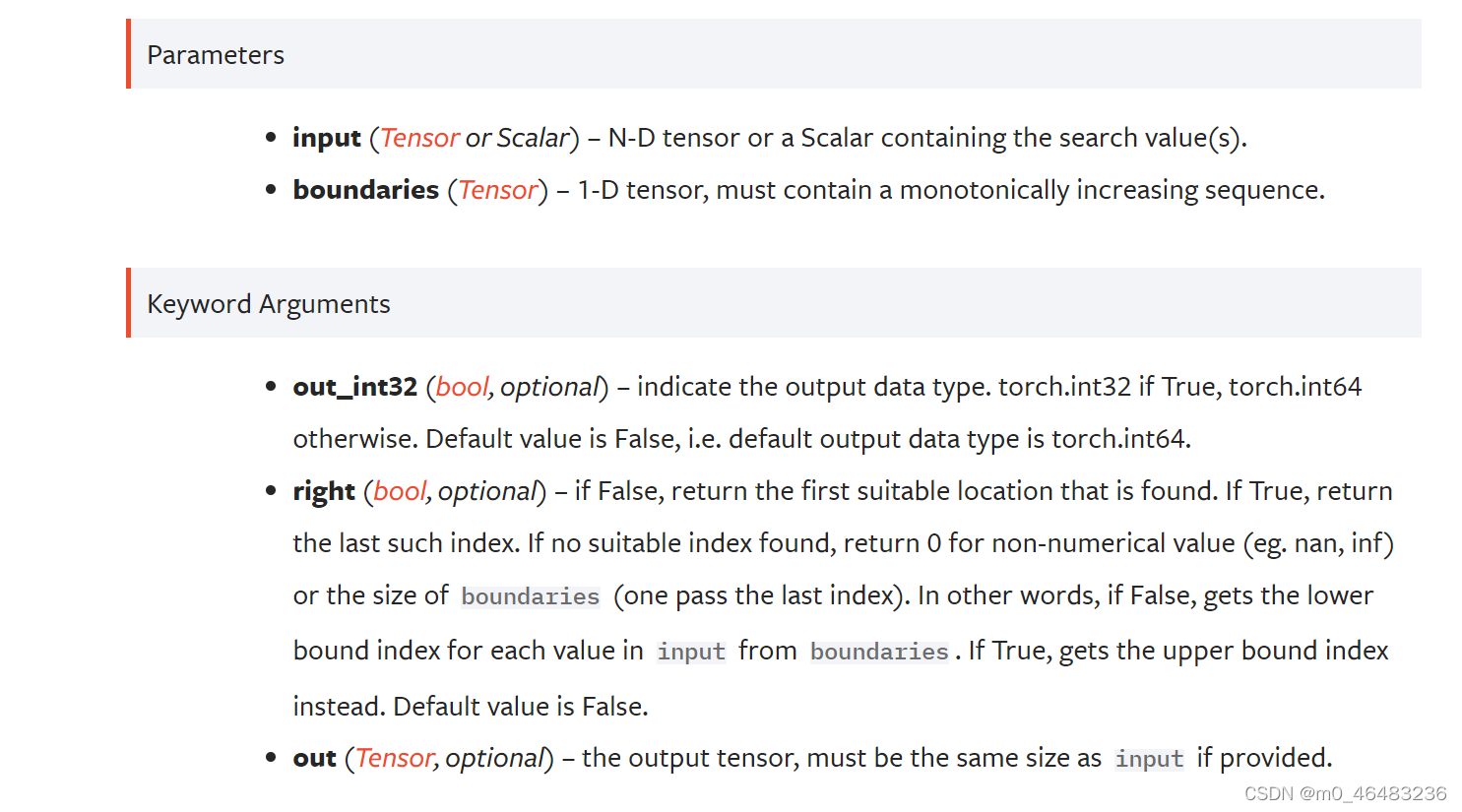
torch.bucketize(input, boundaries, out_int32=False, right=False, out=None) --> Tensor- 功能:返回input中每个元素的所属的桶的索引,桶的边界由boundaries设置。返回的是和input相同大小的新的Tensor。
- 参数:
- input(Tensor or Scalar):N-D Tensor,
- boundaries(Tensor):,1-D Tensor,必须包含一个单调递增的序列。
- out_int32(bool,optional):指明输出数据类型。如果是True,则输出torch.int32;如果是False,则输出torch.int64。默认是False。
- right(bool,optional):如果为False,返回找到的第一个合适的位置; 如果为True,返回最后一个这样的索引; 如果没有找到合适的索引,则返回0作为非数值值(例如。 Nan, inf)或边界的大小(通过最后一个索引)。 换句话说,如果为False,则从边界获取输入中每个值的下界索引; 如果为True,则获取上界索引。 默认值为False。
- out(Tensor,optional):输出的Tensor必须和输出的Tensor大小相同。
官方文档:


实例分析:
比如 boundaries = torch.tensor([1, 5, 9, 13]),其实就是在(-∞,+∞)上通过boundaries中的这4个值划分了5个区间:
- right=False时,左开右闭:(-∞, 1],(1, 5],(5, 9],(9, 13],(13, +∞)分别对应索引值0,1,2,3,4。
- right=True时,左闭右开:(-∞, 1),[1, 5),[5, 9),[9, 13),[13, +∞)分别对应索引值0,1,2,3,4。
import torch
boundaries = torch.tensor([1, 5, 9, 13])
a = torch.tensor([1, 6, 14])
## right = False
output = torch.bucketize(a, boundaries)
print(output) ## tensor([0, 2, 4])
## right = True
output = torch.bucketize(a, boundaries, right=True)
print(output) ## tensor([1, 2, 4])实际应用:
应用场景有很多,例如,有时候需要将某个1维的数据 加和(add)到网络中的多维数据中(如256维)去 ,这时候就需要先将1维的数据扩展为256维,其中一个很好的办法就是采用nn.Embedding()的形式。但是,torch.nn.Embedding(num_embeddings,embedding_dim)的意思是创建一个词嵌入模型,num_embeddings代表一共有多少个词, embedding_dim代表你想要为每个词创建一个多少维的向量来表示它。也就是需要设定num_embeddings的数目,但是该1维的数据是一个连续的数据,并不是固定数目的几个类。这时,一个很好的做法就是,先统计该1维数据的最大最小值,然后利用torch.linspace()在最大最小值之间生成多个平均的间隔点,这样就可以将该1维的数据平均离散化成多个固定的索引值,这样,就能够保证对于所有的某一个索引值,它对应的256维的embedding是相同的了。详见FastSpeech2的代码设置加和pitch,energy的embedding部分。


















 6271
6271

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









