







文章目录
- 1.torch.atleast_1d()
- 2.torch.atleast_2d()
- 3.torch.bincount()
- 4.torch.block_diag()
- 5.torch.broadcast_tensors()
- 6.torch.broadcast_shapes()
- 7.torch.bucketize()
- 8.torch.cartesian_prod()
- 9.torch.cdist()
- 10.torch.clone()
- 11.torch.cummax()
- 12.torch.cummin()
- 13.torch.cumprod()
- 14.torch.cumsum()
- 15.torch.diag()
- 16.torch.diag_embed()
- 17.torch.diagflat()
- 18.torch.diagonal()
- 19.torch.flatten()
- 20.torch.flip()
- 21.torch.ravel()
- 22.torch.trace()
- 23.torch.tril()
- 24.torch.triu()
- 24.torch.triu_indices()
1.torch.atleast_1d()
torch.atleast_1d() 是 PyTorch 框架中的一个函数,用于确保输入张量至少具有一维的维度。
import torch
x = torch.tensor(5) # 标量张量,零维
y = torch.tensor([1, 2, 3]) # 一维张量
z = torch.tensor([[4, 5, 6], [7, 8, 9]]) # 二维张量
x = torch.atleast_1d(x)
y = torch.atleast_1d(y)
z = torch.atleast_1d(z)
print(x) # 输出: tensor([5])
print(y) # 输出: tensor([1, 2, 3])
print(z) # 输出: tensor([[4, 5, 6],
# [7, 8, 9]])
2.torch.atleast_2d()
torch.atleast_2d()是PyTorch框架中的一个函数,用于确保输入张量至少具有两个维度。
该函数的作用是将输入张量转换为至少具有两个维度的形状。如果输入张量已经是两个或更多维度,则不做任何修改;如果输入张量是一维的,则会将其转换为二维张量,其中一个维度的大小为1。
import torch
x = torch.tensor([1, 2, 3]) # 一维张量
y = torch.tensor([[4, 5, 6], [7, 8, 9]]) # 二维张量
x = torch.atleast_2d(x)
y = torch.atleast_2d(y)
print(x) # 输出: tensor([[1, 2, 3]])
print(y) # 输出: tensor([[4, 5, 6],
# [7, 8, 9]])
3.torch.bincount()
当我们使用 torch.bincount() 函数时,它可以帮助我们计算给定整数张量中每个值出现的频率。
torch.bincount(input, weights=None, minlength=0)
"""
参数说明:
input:输入的一维整数张量。
weights:可选参数,具有相同长度的张量,用于指定每个值的权重。
minlength:可选参数,返回张量的最小长度。如果指定,则返回的张量长度为 max(input) + 1 和 minlength 中的较大者。
"""
import torch
x = torch.tensor([0, 1, 1, 3, 2, 1, 4, 3, 2, 2, 0])
counts = torch.bincount(x)
print(counts) # 输出: tensor([2, 3, 3, 2, 1])
import torch
x = torch.tensor([0, 1, 1, 3, 2, 1, 4, 3, 2, 2, 0])
weights = torch.tensor([0.1, 0.5, 0.2, 0.3, 0.4, 1.0, 0.2, 0.5, 0.1, 0.3, 0.2])
counts = torch.bincount(x, weights=weights)
print(counts) # 输出: tensor([0.3, 0.8, 1.1, 1.1, 0.2])
4.torch.block_diag()
block_diag 是一个数学工具函数,用于构建块对角矩阵(block diagonal matrix)。块对角矩阵是一个由多个方阵组成的大矩阵,其中每个方阵作为对角线的一个块。
import torch
A = torch.tensor([[1, 2], [3, 4]])
B = torch.tensor([[5, 6], [7, 8]])
C = torch.tensor([[9, 10], [11, 12]])
# 构建块对角矩阵
result = torch.cat((torch.cat((A, torch.zeros_like(B)), dim=1),
torch.cat((torch.zeros_like(A), B), dim=1)), dim=0)
result = torch.cat((result, torch.cat((torch.zeros_like(result), C), dim=1)), dim=0)
print(result)
tensor([[ 1, 2, 0, 0, 0, 0],
[ 3, 4, 0, 0, 0, 0],
[ 0, 0, 5, 6, 0, 0],
[ 0, 0, 7, 8, 0, 0],
[ 0, 0, 0, 0, 9, 10],
[ 0, 0, 0, 0, 11, 12]])
Process finished with exit code 0
5.torch.broadcast_tensors()
torch.broadcast_tensors(*tensors)
"""
参数:
*tensors:要广播的输入张量,可以传入多个张量。
这些张量可以具有不同的形状,但需要满足广播规则。
返回值:
broadcasted_tensors:广播后的张量组成的新列表,其中每个张量都具有相同的形状。
"""
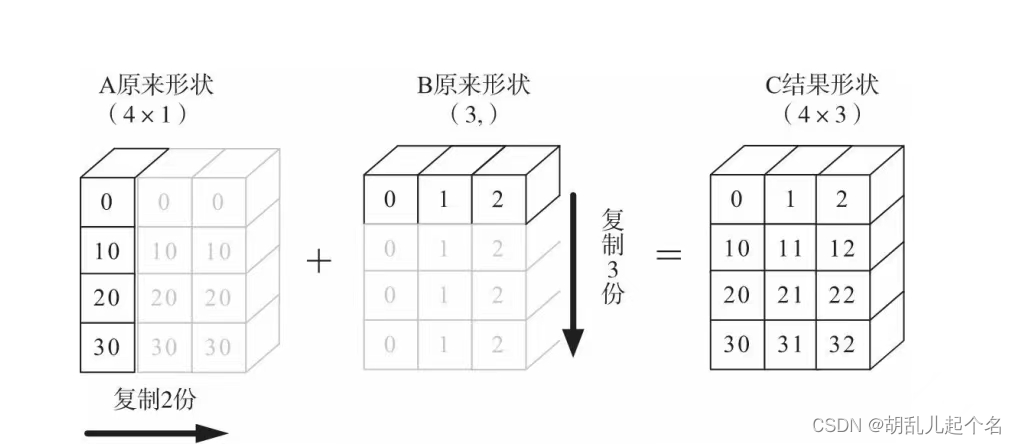
import torch
# 示例1
x = torch.tensor([1, 2, 3]) # 形状为 (3,)
y = torch.tensor([[4], [5], [6]]) # 形状为 (3, 1)
broadcasted_x, broadcasted_y = torch.broadcast_tensors(x, y)
print(broadcasted_x)
print(broadcasted_y)
tensor([[1, 2, 3],
[1, 2, 3],
[1, 2, 3]])
tensor([[4, 4, 4],
[5, 5, 5],
[6, 6, 6]])
6.torch.broadcast_shapes()
torch.broadcast_shapes() 是 PyTorch 中的一个函数,用于计算广播操作中的形状。广播是一种在不同形状的张量之间进行元素级操作的机制。在进行广播操作时,PyTorch会自动调整张量的形状,使其具有相容的尺寸以进行元素级操作。
import torch
shape1 = (2, 1, 4)
shape2 = (2, 3, 1)
shape3_adjusted = (1, 3, 1)
result_shape = torch.broadcast_shapes(shape1, shape2, shape3_adjusted)
print(result_shape)
torch.Size([2, 3, 4])
7.torch.bucketize()
在 PyTorch 中,torch.bucketize() 函数用于将输入张量中的元素根据给定的边界值(boundaries)划分到不同的桶(buckets)中。
import torch
input_tensor = torch.tensor([1.2, 2.5, 3.7, 4.1, 5.8])
boundaries = torch.tensor([2.0, 4.0])
output_tensor = torch.bucketize(input_tensor, boundaries)
print(output_tensor)
tensor([0, 1, 1, 2, 2])
"""
输出张量 output_tensor 包含了与输入张量相同数量的元素,
每个元素表示对应输入元素所属的桶的索引。
在这个例子中,边界值为 [2.0, 4.0],因此小于 2.0 的元素被划分到桶 0,
大于等于 2.0 且小于 4.0 的元素被划分到桶 1,大于等于 4.0 的元素被划分到桶 2。
"""
8.torch.cartesian_prod()
在 PyTorch 中,torch.cartesian_prod() 函数用于计算给定张量序列的笛卡尔积。
import torch
tensors = [torch.tensor([1, 2]), torch.tensor([3, 4, 5]), torch.tensor([6])]
result = torch.cartesian_prod(*tensors)
print(result)
tensor([[1, 3, 6],
[1, 4, 6],
[1, 5, 6],
[2, 3, 6],
[2, 4, 6],
[2, 5, 6]])
9.torch.cdist()
torch.cdist() 是 PyTorch 中的一个函数,用于计算两个张量之间的距离。
torch.cdist(x1, x2, p=2, compute_mode='use_mm_for_euclid_dist')
"""
x1:第一个输入张量,形状为 (n1, d)。
x2:第二个输入张量,形状为 (n2, d)。
p:距离度量的参数,默认为 2,表示欧氏距离。可以选择其他值,如 1 表示曼哈顿距离。
compute_mode:计算模式,默认为 'use_mm_for_euclid_dist',表示对欧氏距离使用矩阵乘法进行计算。可以选择 'donot_use_mm_for_euclid_dist',表示不使用矩阵乘法进行欧氏距离的计算。
"""
import torch
x1 = torch.tensor([[1., 2.], [3., 4.], [5., 6.]])
x2 = torch.tensor([[7., 8.], [9., 10.]])
distances = torch.cdist(x1, x2)
print(distances)
10.torch.clone()
torch.clone() 是 PyTorch 中的一个函数,用于创建一个张量的副本(深拷贝)。
torch.clone(input, memory_format=None)
"""
input:要克隆的输入张量。
memory_format:(可选)指定内存布局格式的选项。默认为 None,
表示保持与输入张量相同的内存布局。
可以选择 'contiguous',表示返回一个连续内存布局的张量。
"""
深拷贝(Deep Copy)和浅拷贝(Shallow Copy)是在计算机科学中用来描述对象复制的两个概念,它们有着不同的特点和应用场景。
深拷贝是指创建一个新对象,将被复制对象的所有内容逐个复制到新对象中,包括对象的所有属性和嵌套对象。新对象与原对象是完全独立的,对新对象的修改不会影响到原对象。深拷贝是一种完全的复制,它创建了一个原始对象的完全独立副本。
浅拷贝是指创建一个新对象,新对象与原对象共享一部分数据,包括对象的引用和一些属性。浅拷贝并不复制嵌套对象本身,而是复制嵌套对象的引用。因此,对浅拷贝对象的修改可能会影响到原对象或其他共享该数据的对象。浅拷贝创建了一个新对象,但它与原对象之间存在一定的关联。
import copy
# 原始对象
original_list = [1, 2, [3, 4]]
# 深拷贝
deep_copy_list = copy.deepcopy(original_list)
# 浅拷贝
shallow_copy_list = copy.copy(original_list)
# 修改嵌套对象
original_list[2][0] = 5
print(original_list) # 输出: [1, 2, [5, 4]]
print(deep_copy_list) # 输出: [1, 2, [3, 4]]
print(shallow_copy_list) # 输出: [1, 2, [5, 4]]
11.torch.cummax()
torch.cummax() 是 PyTorch 中的一个函数,用于计算沿指定维度的累积最大值。
torch.cummax(input, dim, out=None)
"""
torch.cummax(input, dim, out=None)
input:输入张量。
dim:指定进行累积最大值计算的维度。
out:(可选)输出张量,用于存储结果。
"""
import torch
x = torch.tensor([[1, 3, 2],
[4, 2, 5]])
cumulative_max, _ = torch.cummax(x, dim=1)
cumulative_ma ,__= torch.cummax(x, dim=0)
print(cumulative_max)
print(cumulative_ma)
tensor([[1, 3, 3],
[4, 4, 5]])
tensor([[1, 3, 2],
[4, 3, 5]])
12.torch.cummin()
torch.cummin() 是 PyTorch 中的一个函数,用于计算沿指定维度的累积最小值。
torch.cummin(input, dim, out=None)
"""
input:输入张量。
dim:指定进行累积最小值计算的维度。
out:(可选)输出张量,用于存储结果。
"""
import torch
x = torch.tensor([[3, 2, 4], [1, 5, 2]])
cumulative_min = torch.cummin(x, dim=0)
print(cumulative_min)
torch.return_types.cummin(
values=tensor([[3, 2, 4],
[1, 2, 2]]),
indices=tensor([[0, 0, 0],
[1, 0, 1]]))
13.torch.cumprod()
torch.cumprod() 是 PyTorch 中的一个函数,用于计算沿指定维度的累积乘积。
torch.cumprod(input, dim, dtype=None)
"""
input:输入张量。
dim:指定进行累积乘积计算的维度。
dtype:(可选)输出张量的数据类型。
"""
import torch
x = torch.tensor([[2, 3, 4], [5, 6, 7]])
cumulative_prod = torch.cumprod(x, dim=1)
print(cumulative_prod)
tensor([[ 2, 6, 24],
[ 5, 30, 210]])
14.torch.cumsum()
torch.cumsum() 是 PyTorch 中的一个函数,用于计算沿指定维度的累积求和。
torch.cumsum(input, dim, dtype=None)
"""
input:输入张量。
dim:指定进行累积求和计算的维度。
dtype:(可选)输出张量的数据类型。
"""
import torch
x = torch.tensor([[1, 2, 3], [4, 5, 6]])
cumulative_sum = torch.cumsum(x, dim=1)
print(cumulative_sum)
tensor([[ 1, 3, 6],
[ 4, 9, 15]])
15.torch.diag()
torch.diag() 是 PyTorch 中的一个函数,用于创建一个以给定对角线元素填充的张量,或者从一个二维张量中提取对角线元素。
torch.diag(input, diagonal=0, out=None)
"""
input:输入张量。
diagonal:(可选)指定对角线的偏移量,默认为 0,表示主对角线。正值表示上方的对角线,负值表示下方的对角线。
out:(可选)输出张量,用于存储结果。
"""
import torch
# 创建一个以给定对角线元素填充的张量
x = torch.diag(torch.tensor([1, 2, 3]))
print(x)
# 从一个二维张量中提取对角线元素
y = torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
diagonal = torch.diag(y)
print(diagonal)
tensor([[1, 0, 0],
[0, 2, 0],
[0, 0, 3]])
tensor([1, 5, 9])
16.torch.diag_embed()
torch.diag_embed() 是 PyTorch 中的一个函数,用于创建一个以给定对角线元素填充的张量,或者将一维张量转换为对角矩阵。
torch.diag_embed(input, offset=0, dim1=-2, dim2=-1)
"""
input:输入张量,可以是一维或多维张量。
offset:(可选)指定对角线的偏移量,默认为 0,表示主对角线。正值表示上方的对角线,负值表示下方的对角线。
dim1:(可选)指定输入张量的第一个维度。
dim2:(可选)指定输入张量的第二个维度。
"""
import torch
# 创建一个以给定对角线元素填充的张量
x = torch.diag_embed(torch.tensor([1, 2, 3]))
print(x)
# 将一维张量转换为对角矩阵
y = torch.tensor([4, 5, 6])
diagonal_matrix = torch.diag_embed(y)
print(diagonal_matrix)
tensor([[1, 0, 0],
[0, 2, 0],
[0, 0, 3]])
tensor([[4, 0, 0],
[0, 5, 0],
[0, 0, 6]])
17.torch.diagflat()
torch.diagflat() 是 PyTorch 中的一个函数,用于创建一个以给定一维张量进行扁平化后的元素填充的张量。
torch.diagflat(input, offset=0)
"""
input:输入一维张量。
offset:(可选)指定对角线的偏移量,默认为 0,表示主对角线。正值表示上方的对角线,负值表示下方的对角线。
"""
import torch
x = torch.tensor([1, 2, 3])
diagonal_tensor = torch.diagflat(x)
print(diagonal_tensor)
tensor([[1, 0, 0],
[0, 2, 0],
[0, 0, 3]])
18.torch.diagonal()
torch.diagonal() 是 PyTorch 中的一个函数,用于提取输入张量的对角线元素或返回指定偏移量的对角线。
torch.diagonal(input, offset=0, dim1=0, dim2=1)
"""
input:输入张量。
offset:(可选)指定对角线的偏移量,默认为 0,表示主对角线。正值表示上方的对角线,负值表示下方的对角线。
dim1:(可选)指定输入张量的第一个维度。
dim2:(可选)指定输入张量的第二个维度。
"""
import torch
# 提取输入张量的主对角线
x = torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
diagonal = torch.diagonal(x)
print(diagonal)
# 提取输入张量的上方对角线
upper_diagonal = torch.diagonal(x, offset=1)
print(upper_diagonal)
# 提取输入张量的下方对角线
lower_diagonal = torch.diagonal(x, offset=-1)
print(lower_diagonal)
tensor([1, 5, 9])
tensor([2, 6])
tensor([4, 8])
19.torch.flatten()
torch.flatten() 是 PyTorch 中的一个函数,用于将输入张量扁平化为一维张量。
torch.flatten(input, start_dim=0, end_dim=-1)
"""
input:输入张量。
start_dim:(可选)指定开始扁平化的维度,默认为 0。
end_dim:(可选)指定结束扁平化的维度,默认为 -1。
"""
import torch
x = torch.tensor([[1, 2, 3], [4, 5, 6]])
flatten_tensor = torch.flatten(x)
print(flatten_tensor)
tensor([1, 2, 3, 4, 5, 6])
import torch
x = torch.tensor([[[1, 2], [3, 4]], [[5, 6], [7, 8]]])
flatten_tensor = torch.flatten(x, start_dim=1, end_dim=-1)
print(flatten_tensor)
tensor([[1, 2, 3, 4],
[5, 6, 7, 8]])
import torch
x = torch.tensor([[[1, 2], [3, 4]], [[5, 6], [7, 8]]])
flatten_tensor = torch.flatten(x, start_dim=0, end_dim=1)
print(flatten_tensor)
tensor([[1, 2],
[3, 4],
[5, 6],
[7, 8]])
20.torch.flip()
torch.flip() 是 PyTorch 中的一个函数,用于反转张量的维度顺序。
torch.flip(input, dims)
"""
input:输入张量。
dims:指定需要反转的维度。可以是一个整数或一个元组,表示需要反转的维度的索引。
"""
import torch
x = torch.tensor([[1, 2, 3], [4, 5, 6]])
flipped_tensor = torch.flip(x, dims=(0, 1))
print(flipped_tensor)
tensor([[6, 5, 4],
[3, 2, 1]])
21.torch.ravel()
Return a contiguous flattened tensor. A copy is made only if needed.
torch.ravel(input) → Tensor
>>> t = torch.tensor([[[1, 2],
... [3, 4]],
... [[5, 6],
... [7, 8]]])
>>> torch.ravel(t)
tensor([1, 2, 3, 4, 5, 6, 7, 8])
22.torch.trace()
torch.trace() 是 PyTorch 中的一个函数,用于计算矩阵的迹(trace)。
torch.trace(input)
"""
input:输入矩阵。
"""
import torch
x = torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
trace_value = torch.trace(x)
print(trace_value)
tensor(15)
23.torch.tril()
torch.tril() 是 PyTorch 中的一个函数,用于获取一个矩阵的下三角部分(lower triangular part)。
torch.tril(input, diagonal=0)
"""
input:输入矩阵。
diagonal:指定对角线的位置。默认值为 0,表示主对角线。正值表示主对角线之上的对角线,负值表示主对角线之下的对角线。
"""
import torch
x = torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
lower_triangular = torch.tril(x)
print(lower_triangular)
tensor([[1, 0, 0],
[4, 5, 0],
[7, 8, 9]])
24.torch.triu()
torch.triu() 是 PyTorch 中的一个函数,用于获取一个矩阵的上三角部分(upper triangular part)。
torch.triu(input, diagonal=0)
"""
input:输入矩阵。
diagonal:指定对角线的位置。默认值为 0,表示主对角线。正值表示主对角线之上的对角线,负值表示主对角线之下的对角线。
"""
import torch
x = torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
upper_triangular = torch.triu(x)
print(upper_triangular)
tensor([[1, 2, 3],
[0, 5, 6],
[0, 0, 9]])
24.torch.triu_indices()
torch.triu_indices() 是 PyTorch 中的一个函数,用于生成上三角矩阵的索引。
torch.triu_indices(n, m, offset=0, dtype=torch.int64, device='cpu')
"""
n:生成的索引的行数。
m:生成的索引的列数。
offset:生成的索引中非零元素的位置偏移量。默认值为 0,表示主对角线及其以上的元素。
dtype:生成的索引的数据类型。默认为 torch.int64。
device:生成的索引所在的设备。默认为 'cpu'。
"""















 2178
2178











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









