






K近邻算法
通过“邻居”判断所述的类别


如何求距离呢:

为了防止某一个特征的数据数量太大,我们需要做标准化处理

K的取值:会影响最后的结果。
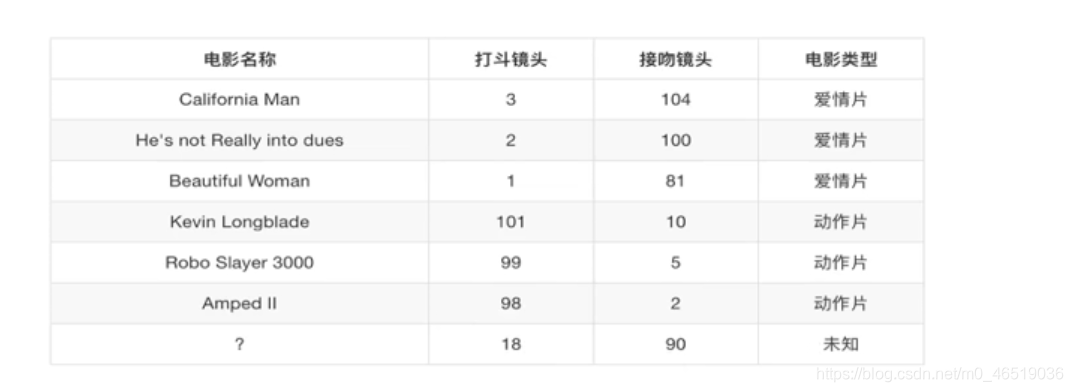
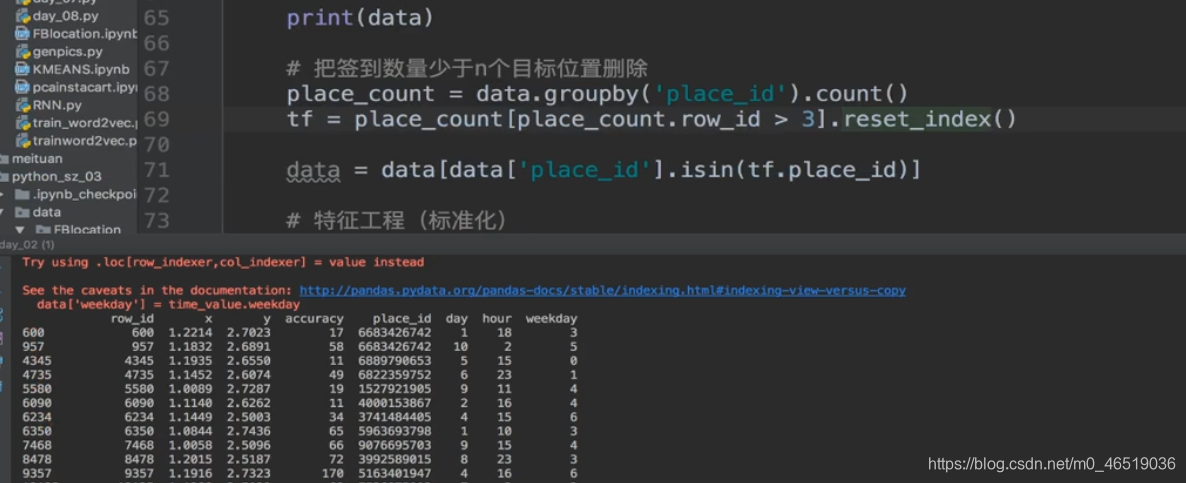
案例:



pandas处理时间戳
增加时间戳


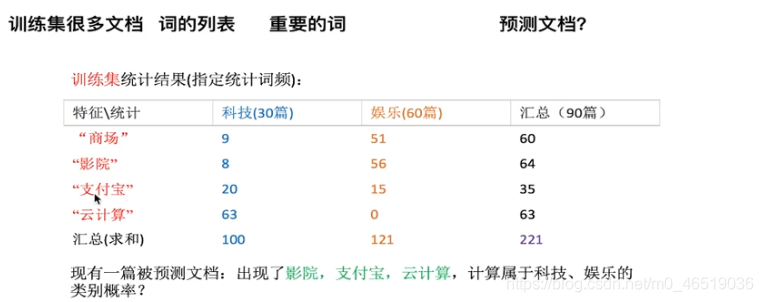

P(科技|影院,支付宝,云计算) = P(影院,支付宝,云计算|科技)*P(科技)
= (8/100)(20/100)(63/100)(30/90) = 0.00456
P(娱乐|影院,支付宝,云计算) = P(影院,支付宝,云计算|娱乐)*P(娱乐)
= (56/121)(15/100)(0/121)(60/90) = 0


分类模型评估
混淆矩阵


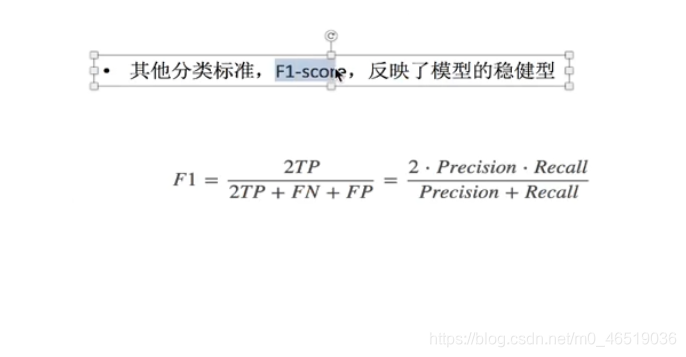
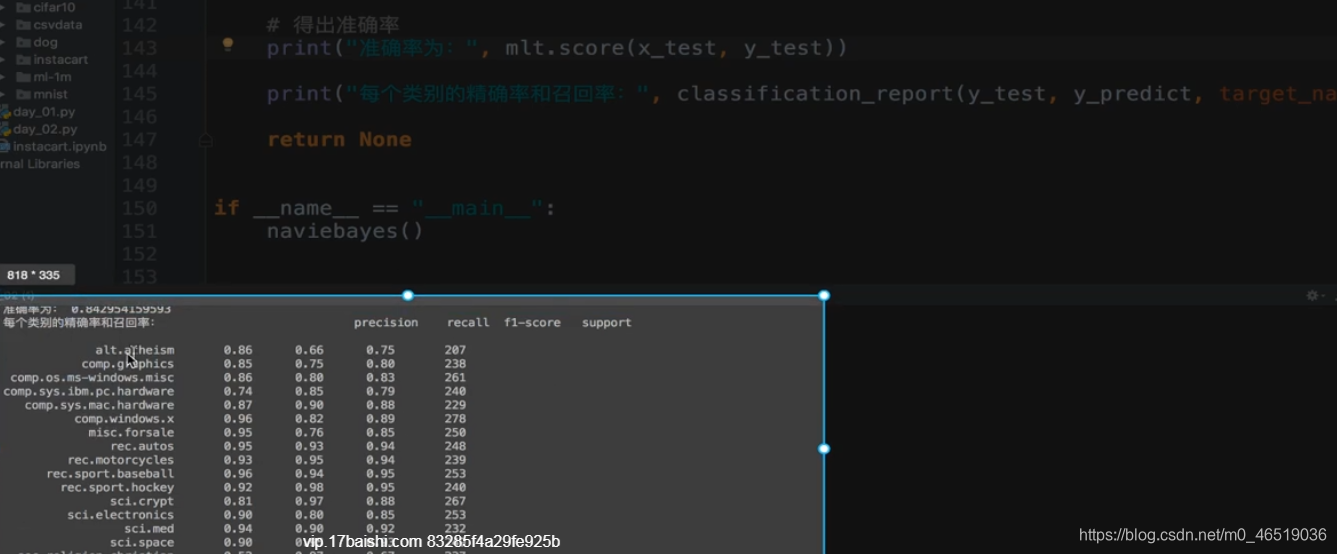
分类模型评估API
sklearn.metrics.classification_report

交叉验证和网格搜索对K近邻算法调优
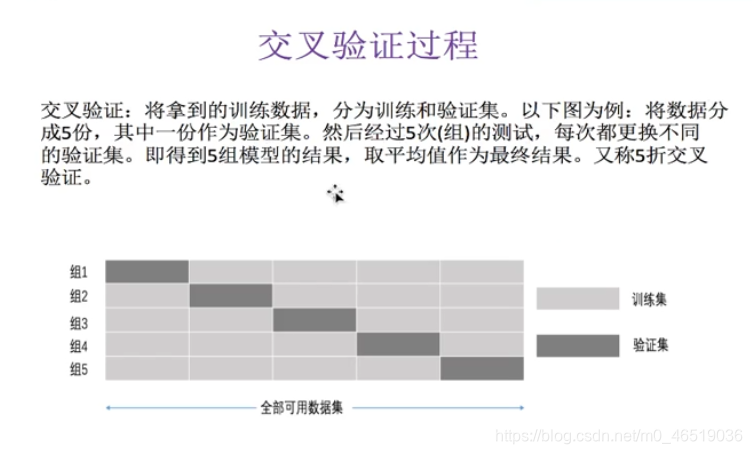
交叉验证:为了让被评估的模型更加准信可信
把所有数据分成N等分。让其中一个当成验证集,其他的都是数据集
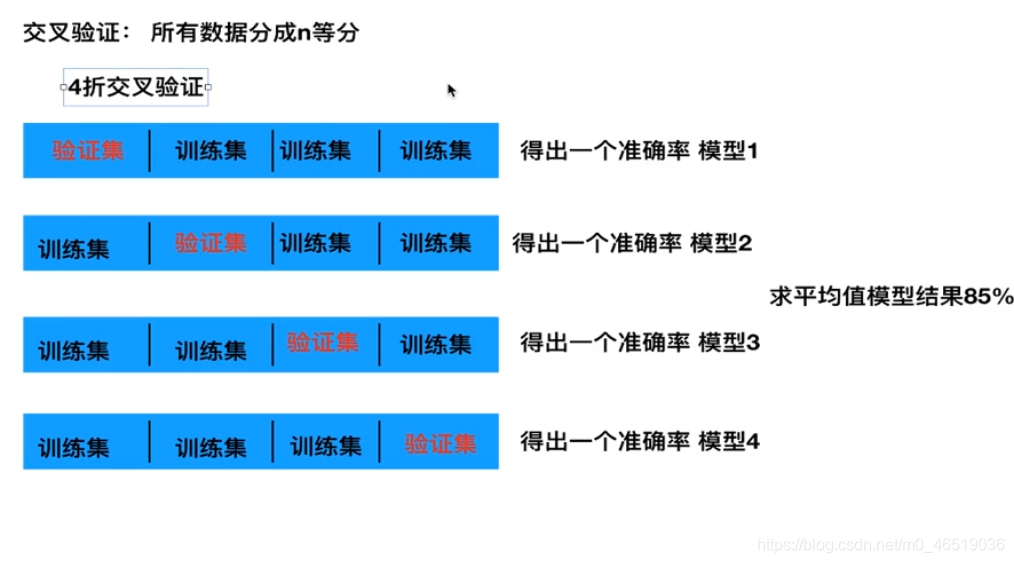
所有的数据都做过训练集,也做过测试集,求均值。这样得到的结果更加准确。
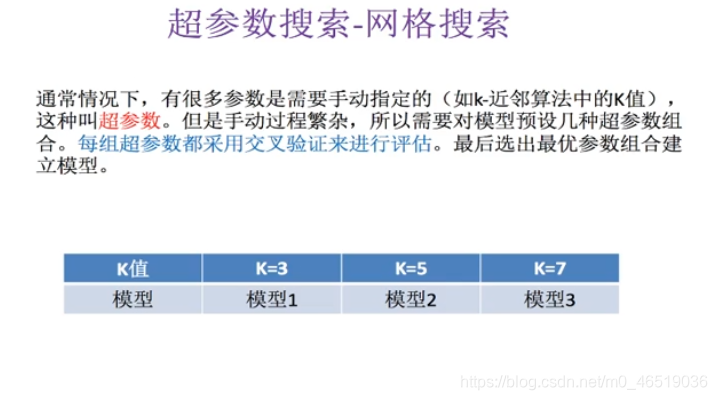
当K=1.5.7.10不同的值,每次取值都进行一次交叉验证。
网格搜索:调参数 K-近邻:超参数K

和调节音响一样,总有一个点,使得结果最好
最长用的是十折交叉验证
如果一个算法中有2个超参数,就进行两两组合。
比如a[2,3,5,8,10],b[20,70,80],两两组合,就有15种组合方式
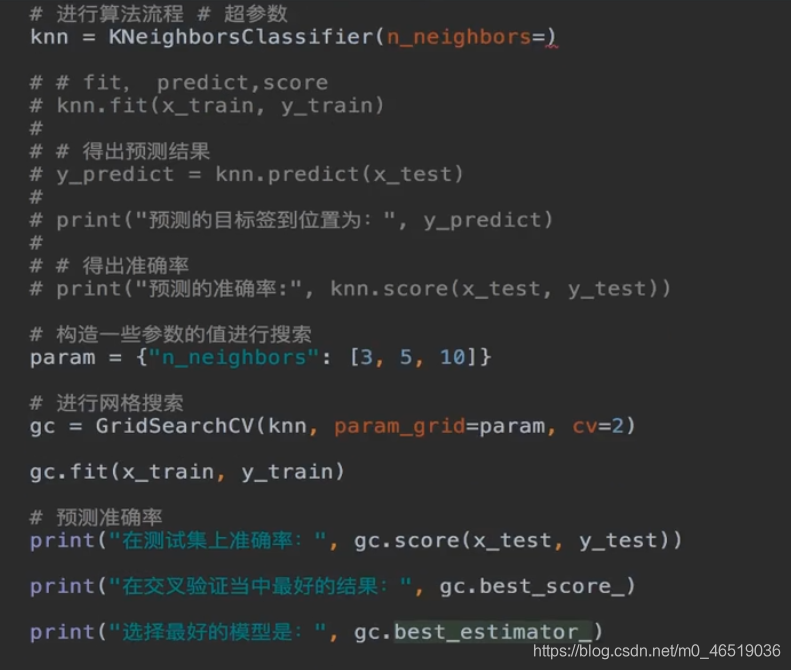
超参数搜索-网格搜索api:

这个api代表了网格搜索和交叉验证一起使用

只要把它放到GridSearchCV,就不用fit,score了
















 959
959











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









