






在LangChain中的Agents篇,有一个Agents Type,叫做“zero-shot-react-description”,其描述为:使用ReAct框架,来抉择使用什么工具,这个抉择的标准是基于对于每一个tool的描述决定的。它不限制tool的数量,但要求所有提供的tool都必须配有一个描述。
我们来看一下他的实现结果: 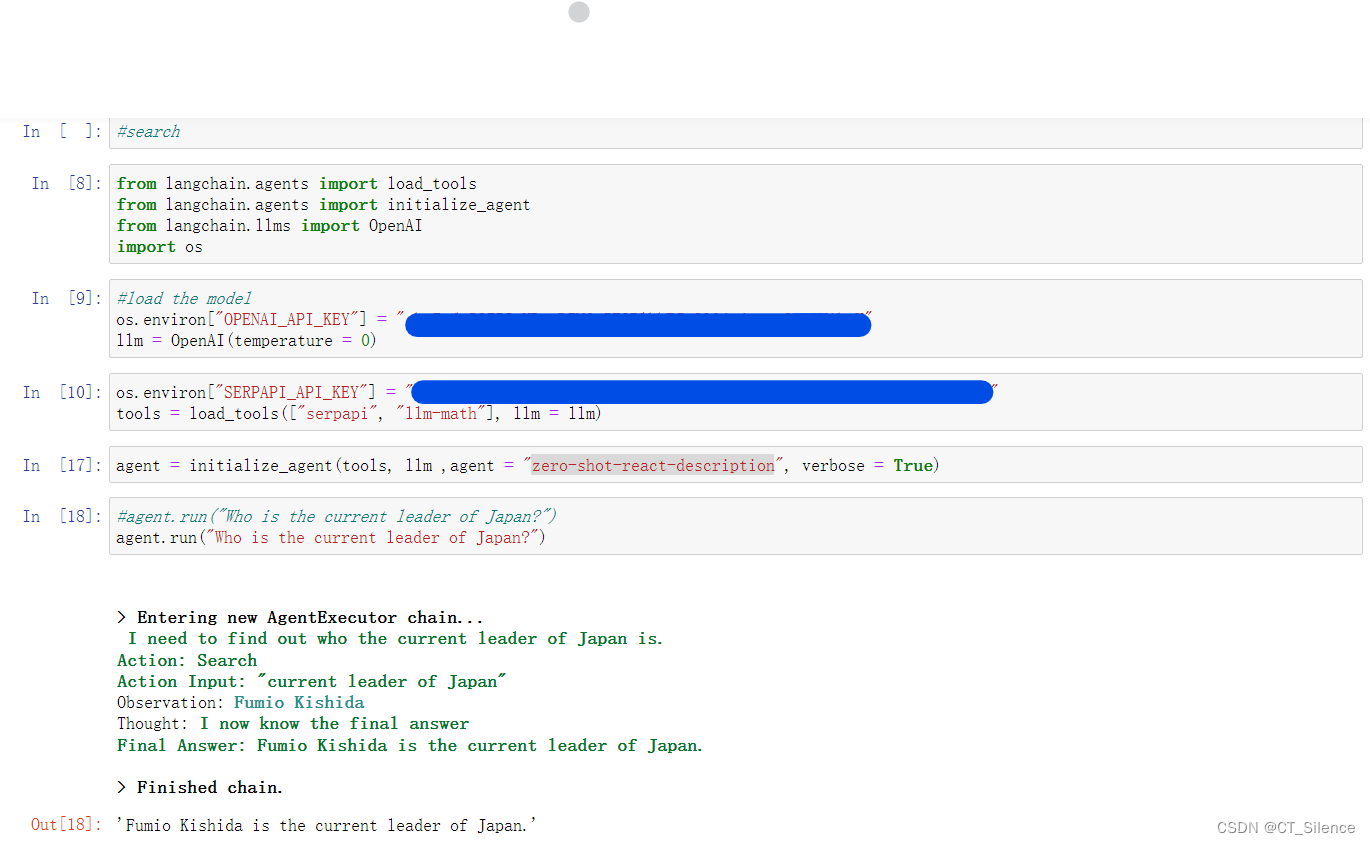
显然,效果不错,很好地实现了ReAct框架。除了“zero-shot-react-description”以外,官方提供的技术文档里,还包括了以下几种:
react-docstore
This agent uses the ReAct framework to interact with a docstore. Two tools must be provided: a Search tool and a Lookup tool (they must be named exactly as so). The Search tool should search for a document, while the Lookup tool should lookup a term in the most recently found document. This agent is equivalent to the original ReAct paper, specifically the Wikipedia example.
self-ask-with-search
This agent utilizes a single tool that should be named Intermediate Answer. This tool should be able to lookup factual answers to questions. This agent is equivalent to the original self ask with search paper, where a Google search API was provided as the tool.
conversational-react-description
This agent is designed to be used in conversational settings. The prompt is designed to make the agent helpful and conversational. It uses the ReAct framework to decide which tool to use, and uses memory to remember the previous conversation interactions.
但其实如果我们去翻LangChain库的源代码,其实还有以下几种:
CHAT_ZERO_SHOT_REACT_DESCRIPTION = "chat-zero-shot-react-description"
CHAT_CONVERSATIONAL_REACT_DESCRIPTION = "chat-conversational-react-description"
STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION = (
"structured-chat-zero-shot-react-description"这里没有在技术文档体现的原因,我想可能是因为作者觉得这些只是上面种类的分支,没有再去做详细介绍的必要。
那我们一步一步来,一个个深入探索。
Question 1:
它是怎么实现Agent的自主判断选择能力的?即我们的第一个图中的“I need to find out ……”,因为要知道,ChatGPT的数据库是只到2021年9月,但他是知道2021年9月前的日本首相是谁,那怎么让他知道他现在知道的是不一定对的,然后让他主动去用SerpAPI去查找现在的结果呢?
答案是Description和FewShot。
Description就是去描述这个tool该如何使用,没错!就是自然语言的描述,第一时间其实蛮难接受的,但细想下来其实又很合理,因为LLM模型的参数都是几十亿到上千亿的,不可能去从中选择出哪些参数是和我想要的结果紧密相关的,那解决方案不如让模型去自己判断。而具体到Description的具体效果如何,这个取决于你的模型的应变能力,对于ChatGPT来说,其实相对来说就比较完善,给出相应的Description,只要描述的恰当,就能去调用工具,然后返回结果。
但很多模型,尤其是本地端模型,由于参数较少(参数大的模型,大多数显卡跑不起来),其对工具的描述是不接受的,而且我们调用工具往往不是一次调用,是多次的,如何让模型知道要多次调用呢?也是给他一个模板,比如让它判断结果还需要查询,那么就让他以Action:……开头,如果结果是最终结果,那么以Final Answer:……开头,但显然,这也需要模型足够灵活,足够理解人类的意图,这是小参数模型的普遍缺点。
那么,FewShot就很需要了,也就是给模型一些样例,让模型按照这个样例去做,让它觉得,它曾经这么回答过。一般来说,给三四个模板就可以了,这也是FewShot的好处。
如果以上两个方法都不行,那很遗憾,只能从模型下手了,也就是微调。其实,微调和FewShot本质上没什么区别,只不过一个是跑代码前给了FewShot,一个是跑代码途中给了FewShot,以及整体的样本量也是一个区别,但本质的方法是一样的,都是给他样本去学习。这一般是最终方案,针对于那些模型较小,想要让模型做一些特化回答的情况。















 2153
2153











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









