







文末获取完整源码+10000张数据集+配置说明+文件说明+远程操作配置环境跑通程序

功能效果演示
基于深度学习YOLOv8+PyQt5的车牌检测识别系统(源码+数据集+配置说明)

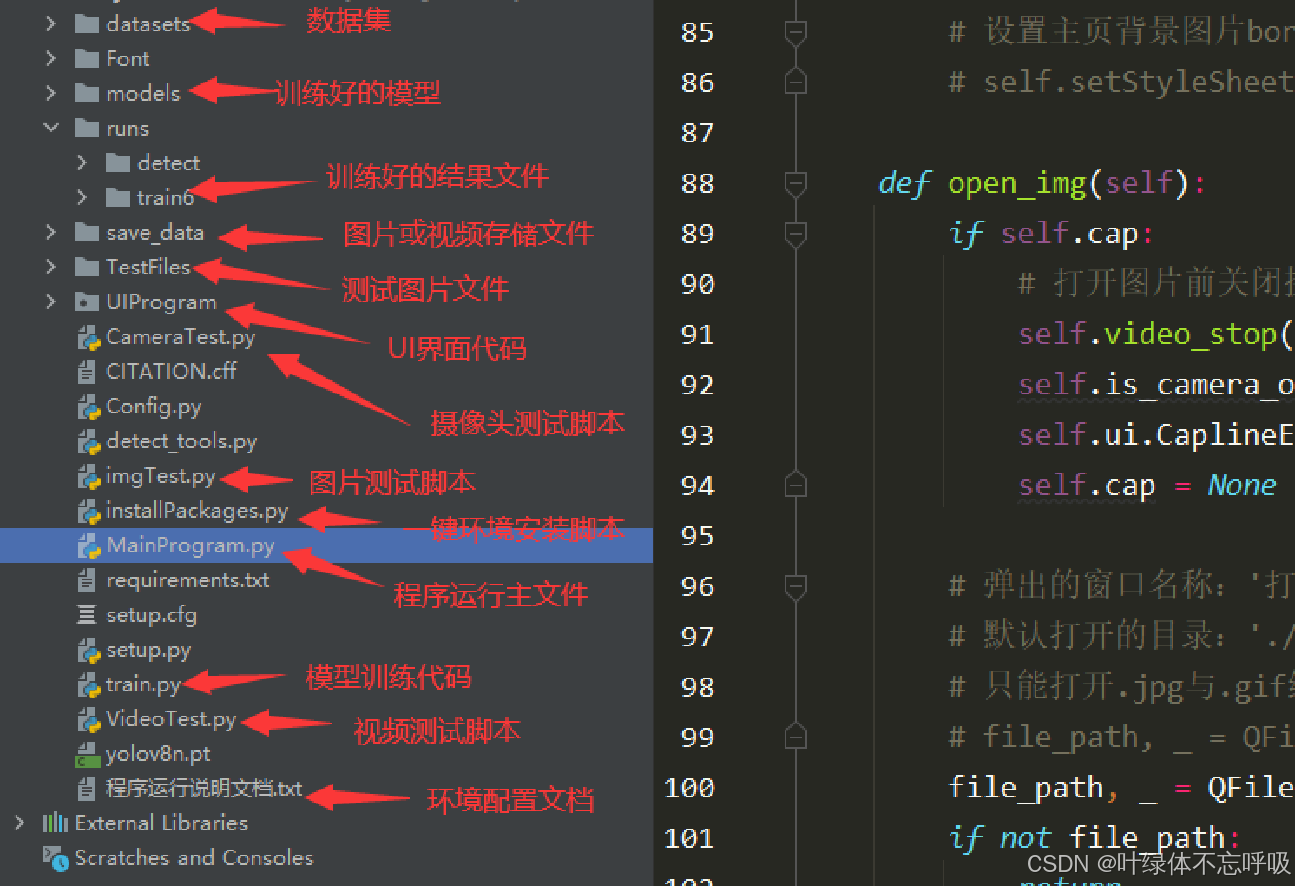
项目各文件说明
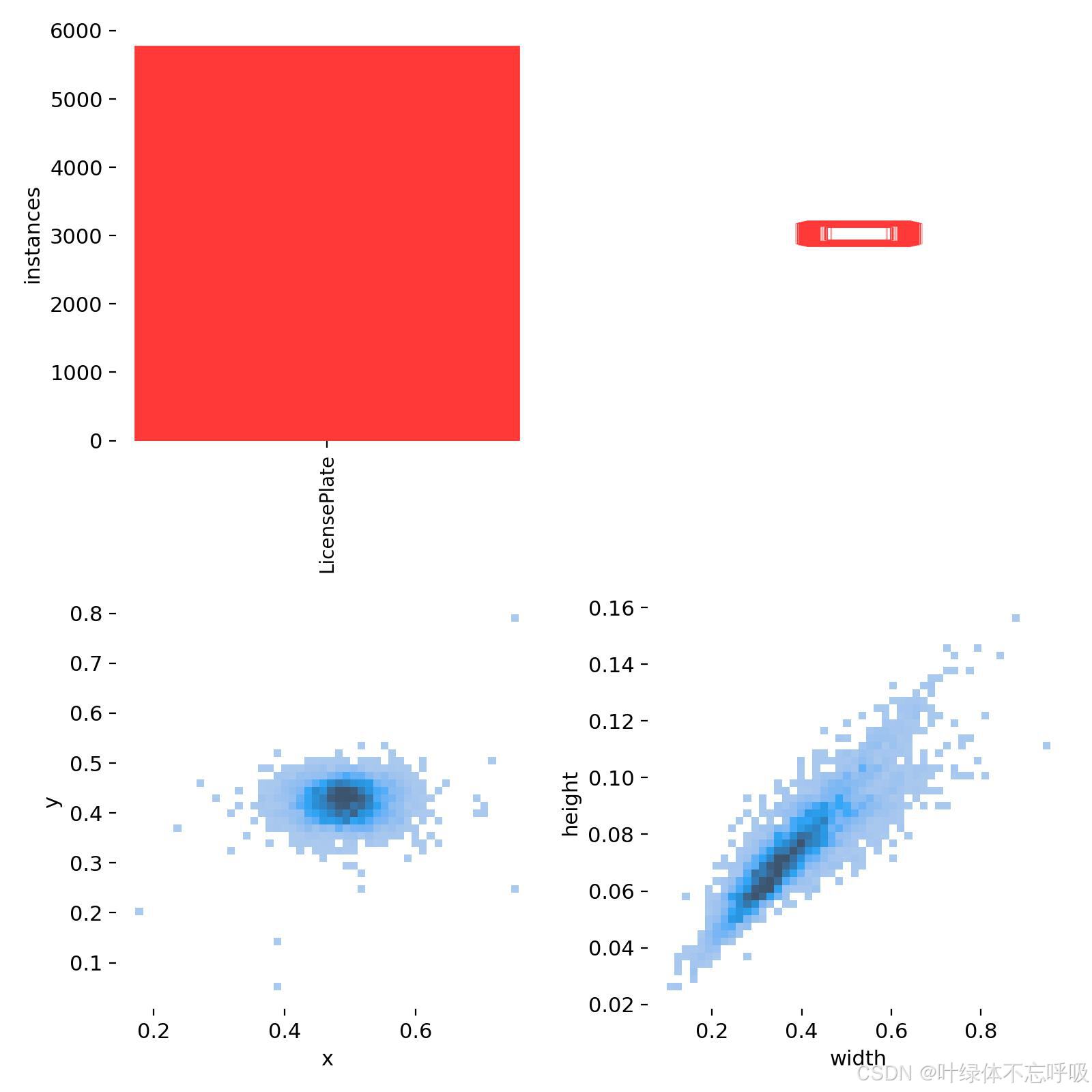
10000+张标注好数据集

程序运行说明

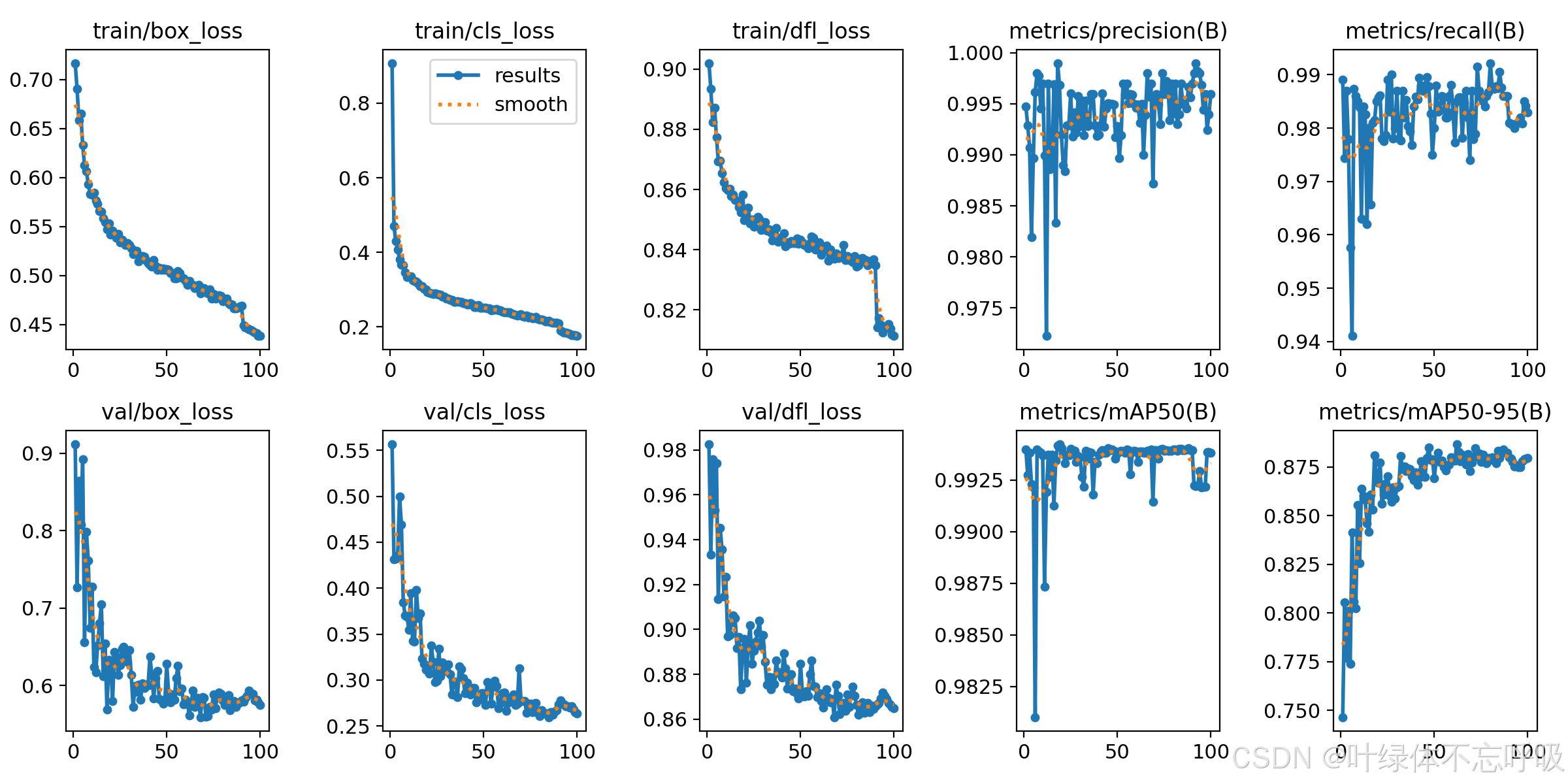
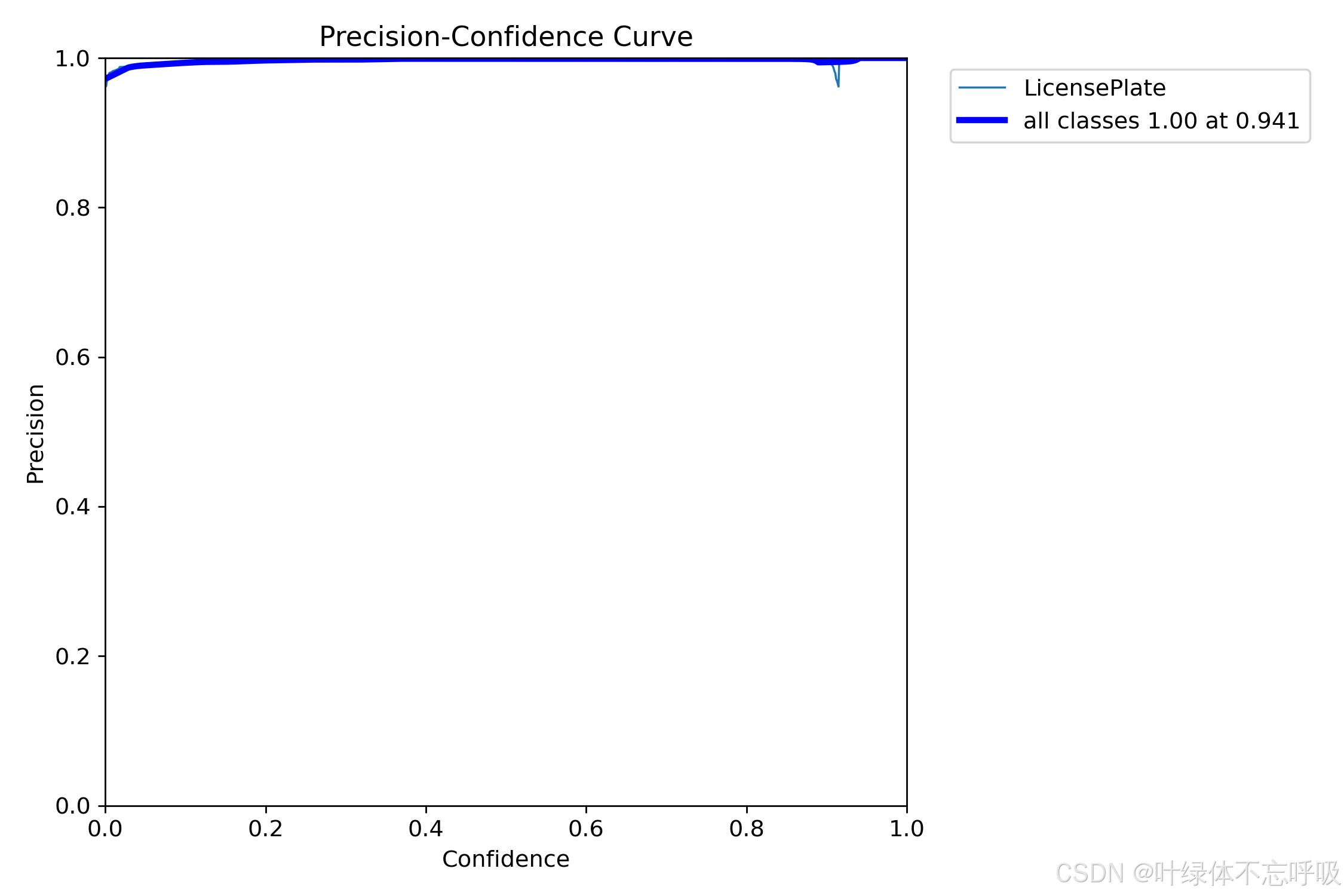
模型评价指标
mAP (mean Average Precision): 平均精度均值是目标检测领域中最常用的评价指标之一。它衡量的是模型在不同IoU(Intersection over Union,交集与并集的比值)阈值下的性能。mAP通常在0到1之间,值越高表示模型性能越好。mAP50-95是一个更严格的评价指标,它计算了在50-95%的IoU阈值范围内的mAP值,然后取平均,这能够更准确地评估模型在不同IoU阈值下的性能。
Precision (精度): 精度是评估模型预测正确的正样本的比例。它表示在所有被模型预测为正类的样本中,实际为正类的比例。
Recall (召回率): 召回率是评估模型对真实目标检测率的指标。它表示模型正确预测出的目标数量与真实目标数量的比例。
F1 Score (F1分数): F1分数综合了精度和召回率两个指标,用于评估模型的综合性能。它是精确率和召回率的调和平均值,适用于在不平衡类别分布的情况下评估模型性能。
IoU (Intersection over Union): 交集大于联合是量化预测边界框与地面实况边界框之间重叠程度的指标。IoU的值介于0和1之间,值越高表示预测边界框与实际边界框的重叠程度越高。
FPS (Frames Per Second): 每秒帧数是衡量模型实时性能的指标,特别是在视频处理或实时应用中。FPS越高,表示模型处理速度越快。
这些指标共同提供了对YOLO模型性能的全面评估,包括模型的准确性、效率和实用性。在实际应用中,根据具体需求和场景,可能会重点考虑某些指标。例如,在需要高实时性的应用中,FPS可能是一个关键指标;而在对准确性要求极高的场景中,mAP和精度可能是更重要的评价标准。
部分源码
# -*- coding: utf-8 -*-
import time
from PyQt5.QtWidgets import QApplication , QMainWindow, QFileDialog, \
QMessageBox,QWidget,QHeaderView,QTableWidgetItem, QAbstractItemView
import sys
import os
from PIL import ImageFont
from ultralytics import YOLO
sys.path.append('UIProgram')
from UIProgram.UiMain import Ui_MainWindow
import sys
from PyQt5.QtCore import QTimer, Qt, QThread, pyqtSignal,QCoreApplication
import detect_tools as tools
import cv2
import Config
from UIProgram.QssLoader import QSSLoader
from UIProgram.precess_bar import ProgressBar
import numpy as np
# import torch
class MainWindow(QMainWindow):
def __init__(self, parent=None):
super(QMainWindow, self).__init__(parent)
self.ui = Ui_MainWindow()
self.ui.setupUi(self)
self.initMain()
self.signalconnect()
# 加载css渲染效果
style_file = 'UIProgram/style.css'
qssStyleSheet = QSSLoader.read_qss_file(style_file)
self.setStyleSheet(qssStyleSheet)
def signalconnect(self):
self.ui.PicBtn.clicked.connect(self.open_img)
self.ui.comboBox.activated.connect(self.combox_change)
self.ui.VideoBtn.clicked.connect(self.vedio_show)
self.ui.CapBtn.clicked.connect(self.camera_show)
self.ui.SaveBtn.clicked.connect(self.save_detect_video)
self.ui.ExitBtn.clicked.connect(QCoreApplication.quit)
self.ui.FilesBtn.clicked.connect(self.detact_batch_imgs)
def initMain(self):
self.show_width = 770
self.show_height = 480
self.org_path = None
self.is_camera_open = False
self.cap = None
# self.device = 0 if torch.cuda.is_available() else 'cpu'
# 加载检测模型
self.model = YOLO(Config.model_path, task='detect')
self.model(np.zeros((48, 48, 3))) #预先加载推理模型
self.fontC = ImageFont.truetype("Font/platech.ttf", 25, 0)
# 用于绘制不同颜色矩形框
self.colors = tools.Colors()
# 更新视频图像
self.timer_camera = QTimer()
# 更新检测信息表格
# self.timer_info = QTimer()
# 保存视频
self.timer_save_video = QTimer()
# 表格
self.ui.tableWidget.verticalHeader().setSectionResizeMode(QHeaderView.Fixed)
self.ui.tableWidget.verticalHeader().setDefaultSectionSize(40)
self.ui.tableWidget.setColumnWidth(0, 80) # 设置列宽
self.ui.tableWidget.setColumnWidth(1, 200)
self.ui.tableWidget.setColumnWidth(2, 150)
self.ui.tableWidget.setColumnWidth(3, 90)
self.ui.tableWidget.setColumnWidth(4, 230)
# self.ui.tableWidget.horizontalHeader().setSectionResizeMode(QHeaderView.Stretch) # 表格铺满
# self.ui.tableWidget.horizontalHeader().setSectionResizeMode(0, QHeaderView.Interactive)
# self.ui.tableWidget.setEditTriggers(QAbstractItemView.NoEditTriggers) # 设置表格不可编辑
self.ui.tableWidget.setSelectionBehavior(QAbstractItemView.SelectRows) # 设置表格整行选中
self.ui.tableWidget.verticalHeader().setVisible(False) # 隐藏列标题
self.ui.tableWidget.setAlternatingRowColors(True) # 表格背景交替
# 设置主页背景图片border-image: url(:/icons/ui_imgs/icons/camera.png)
# self.setStyleSheet("#MainWindow{background-image:url(:/bgs/ui_imgs/bg3.jpg)}")
def open_img(self):
if self.cap:
# 打开图片前关闭摄像头
self.video_stop()
self.is_camera_open = False
self.ui.CaplineEdit.setText('摄像头未开启')
self.cap = None
# 弹出的窗口名称:'打开图片'
# 默认打开的目录:'./'
# 只能打开.jpg与.gif结尾的图片文件
# file_path, _ = QFileDialog.getOpenFileName(self.ui.centralwidget, '打开图片', './', "Image files (*.jpg *.gif)")
file_path, _ = QFileDialog.getOpenFileName(None, '打开图片', './', "Image files (*.jpg *.jepg *.png)")
if not file_path:
return
if __name__ == "__main__":
app = QApplication(sys.argv)
win = MainWindow()
win.show()
sys.exit(app.exec_())
在智能交通领域,尤其是新能源汽车的管理中,及时准确地检测和识别车牌信息是提高交通效率和车辆管理的关键任务。然而,由于车牌在不同光照、角度和遮挡条件下的复杂性,传统的人工检测方法既耗时又容易出错。为了提高车牌检测的效率和准确性,本文提出了一种基于YOLOv8和PyQt5的新能源汽车车牌检测系统。
系统设计
数据集准备:首先,需要收集和标注一个包含各种新能源汽车车牌的图像数据集。数据集应涵盖不同光照条件、角度变化和遮挡情况下的外观。图像标注需要精确识别出车牌的位置,以便训练模型进行有效识别。
模型训练:利用准备好的数据集,对YOLOv8模型进行训练。在训练过程中,需要调整超参数,如学习率、批大小和训练周期,以优化模型的检测性能。同时,采用数据增强技术,如随机调整亮度、对比度和模拟不同光照条件,以提高模型对复杂环境的适应性。
系统实现:系统核心是YOLOv8模型,负责从摄像头捕获的实时图像中检测车牌。系统还包括一个基于PyQt5的用户界面,用于展示检测结果。
结果与讨论
在测试集上,YOLOv8模型显示出了较高的车牌检测准确率。模型能够在多种光照和角度条件下稳定识别车牌。通过与OCR技术结合,系统不仅能够检测车牌位置,还能识别车牌上的字符,进一步提高了系统的实用性。
结论
本文提出的基于YOLOv8和PyQt5的新能源汽车车牌检测系统,能够有效地提升车牌检测的自动化水平。通过实时监测和即时反馈,该系统有助于提高交通管理的效率和准确性。未来的工作将致力于进一步提升模型的鲁棒性,并探索更加高效的模型部署方案,以适应更多样化的交通环境。


















 1894
1894

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











