






注: 本教程是在使用mmsegmentation跑该模型的自己数据集过程中积累的经验,全部参考于mmsegmentation的仓库教程,但对于初学者来说一些细节并不太好理解和找到相关的文档支撑,因此在这里写一下自己的经验。
文章目录
0.mmsegmentation简介以及使用的整体思路
0.1mmsegmentation简介
MMSegmentation 是 OpenMMLab 开源的基于 PyTorch 实现的功能强大的语义分割工具箱
-
丰富的语义分割模型
目前支持数十种主干网络和算法,例如常用的FCN, U-Net,PSPNet, Swin Transformer, Mask2former等多种方法,并且目前也还在不断更新好的图像分割算法上去框架。 -
大量开箱即用的权重模型
我们可以直接使用它所提供的训练好的模型进行推理测试。 -
统一的性能评估框架
优化和统一了训练和测试的流程,方便公平比较各个模型在特定任务上的表现。
详情可以查看mmsegmentation的github链接:
https://github.com/open-mmlab/mmsegmentation
0.2整体思路
- 首先我们就是先把mmsegmentation的仓库下载到自己的电脑或者服务器上,配置好相关的环境。
环境搭建和测试验证直接参考官方指导文档就好了:
https://github.com/open-mmlab/mmsegmentation/blob/main/docs/en/get_started.md#installation
- 打开仓库我们可以看到,mmsegmentation把数据集,骨干网络,方法,评估等都已经模块化给我们划分好了。比如我以跑一个自己找的数据集(不用它给出的数据集)跑一个6类别分割任务为例,基于FCN模型。
我们可以看到mmsegmentation已经帮我们写好了基于FCN的多个已有的数据集的配置文件了

那么我们只需要写自己的数据集配置文件,以及将分割类别的数目21改成6就可以了。具体需要修改的是以下的文件,首先在mmseg文件夹下的dataset和utils添加自己的数据信息,然后在config的base下的datasets中写好自己的数据的数据路径,数据增强方式等详细信息。
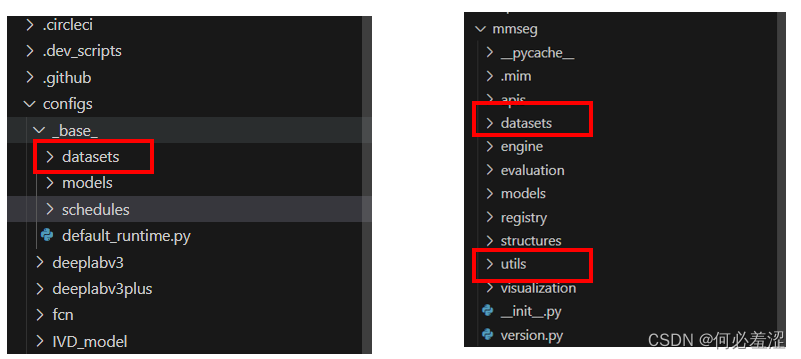
1.构建好自己的数据集
1.数据集预处理
我使用的是工业缺陷分割数据集magnetic_tile,图像和mask都设置成256×256的大小,然后将五种类别的缺陷分别定位1,2,3,4,5,背景设置为0,mask是单通道的PNG格式,图片也是PNG格式。
数据结构布局如下所示,你们也可以按照自己喜欢的方式设置, 其中子文件夹all不是必须的,只是为了方便训练验证测试的分割。
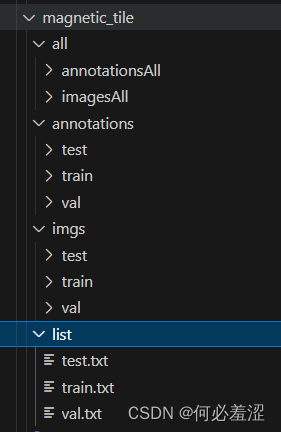
其中list存放的是对应的训练集,验证集和测试集的图片的名称,分割按照7:1:2的比例。
#数据集按比例随机划分函数
def split_images_to_files(source_folder, train_ratio=0.7, val_ratio=0.1):
source_folder_a = os.path.join(source_folder, 'all')
source_folder_a = os.path.join(source_folder_a, 'annotationsAll')
output_folder = os.path.join(source_folder, 'list')
os.makedirs(output_folder, exist_ok=True)
image_files = [f for f in os.listdir(source_folder_a) if f.endswith(('.jpg', '.png', '.jpeg', '.bmp'))]
random.shuffle(image_files)
total_images = len(image_files)
train_count = int(total_images * train_ratio)
val_count = int(total_images * val_ratio)
train_images = image_files[:train_count]
val_images = image_files[train_count:train_count + val_count]
test_images = image_files[train_count + val_count:]
def write_to_file(image_list, file_name):
with open(os.path.join(output_folder, file_name), 'w') as f:
for image_name in image_list:
if image_name.endswith('.png'):
# 如果以 .png 结尾,替换掉 .png 后缀
image_name = image_name.replace('.png', '')
f.write(image_name + '\n')
print(f"完成{image_name}的写入")
write_to_file(train_images, 'train.txt')
write_to_file(val_images, 'val.txt')
write_to_file(test_images, 'test.txt')
# 按照写好的.txt将全部对应名称的图片移动到对应的文件夹
## 下面两个函数一起使用,已经含有了all子文件夹的所有内容,并创建了annotations和imgs,根据已有的list进行图片分类
def move_img_annotationV2(target_folder):
ps_folder = target_folder # 请替换成实际的文件夹路径
splits = ["train", "test", "val"]
for split in splits:
split_file_path = os.path.join(ps_folder, 'list', f'{split}.txt')
imgs_dest_folder = os.path.join(ps_folder, 'imgs', split)
annotations_dest_folder = os.path.join(ps_folder, 'annotations', split)
os.makedirs(imgs_dest_folder, exist_ok=True)
os.makedirs(annotations_dest_folder, exist_ok=True)
move_images_and_annotationsV1(ps_folder,imgs_dest_folder, annotations_dest_folder, split_file_path)
def move_images_and_annotationsV1(src_folder,imgs_dest_folder,annotations_dest_folder, split_file):
with open(split_file, 'r') as f:
lines = f.readlines()
for line in lines:
file_name = line.strip()
# 构建源文件和目标文件的完整路径
src_image_path = os.path.join(src_folder, 'all', 'imagesAll', file_name + '.png')
src_annotation_path = os.path.join(src_folder, 'all', 'annotationsAll', file_name + '.png')
dest_image_path = os.path.join(imgs_dest_folder, file_name + '.png')
dest_annotation_path = os.path.join(annotations_dest_folder, file_name + '.png')
# 移动文件
shutil.copy(src_image_path, dest_image_path)
shutil.copy(src_annotation_path, dest_annotation_path)
print(f"图片{file_name}移动完成")
1.2新增自定义数据集
- 创建一个新的文件 mmseg/datasets/magnetic_tile.py, 其实在同级文件夹中找一个类似的改一下就行
from mmseg.registry import DATASETS
from .basesegdataset import BaseSegDataset
@DATASETS.register_module()
class Magnetic_tileDataset(BaseSegDataset):
"""ISPRS dataset.
In segmentation map annotation for ISPRS, 0 is the ignore index.
``reduce_zero_label`` should be set to True. The ``img_suffix`` and
``seg_map_suffix`` are both fixed to '.png'.
"""
METAINFO = dict(
classes=('background', 'blowhole', 'break', 'crack',
'fray', 'uneven'),
palette=[[0, 0, 0], [0, 0, 255], [0, 255, 255], [0, 255, 0],
[255, 255, 0], [255, 0, 0]])
def __init__(self,
img_suffix='.png',
seg_map_suffix='.png',
reduce_zero_label=False,
**kwargs) -> None:
super().__init__(
img_suffix=img_suffix,
seg_map_suffix=seg_map_suffix,
reduce_zero_label=reduce_zero_label,
**kwargs)
- 在mmseg/datasets/init.py 中导入模块
from .magnetic_tile import Magnetic_tileDataset
# 另外还要在下面的all = []中补充对应的名称信息
- 在mmseg/utils/class_names.py 中补充数据集元信息, 也是照着其他已有的数据集改就行
def magnetic_tile_classes():
"""IVD class names for external use"""
return [
'background', 'blowhole', 'break', 'crack',
'fray', 'uneven'
]
def magnetic_tile_palette():
return[[0, 0, 0], [0, 0, 255], [0, 255, 255], [0, 255, 0],
[255, 255, 0], [255, 0, 0]]
- 在mmseg/utils/init.py 中补充数据集元信息, 也是照着其他已有的数据集改就行
2.写好相关的config文件
- 通过创建一个新的数据集配置文件 configs/base/datasets/magnetic_tile.py 来使用它, 注意更改一些对应的参数就好,主要是img_szie, img_path, seg_map_path, 这里训练权重保持依据使用mIoU,
## 仿照数据集 synapse.py
dataset_type = 'Magnetic_tileDataset' # 数据集类型,自定义
data_root = 'IVD_data/magnetic_tile' # 数据根路径
img_szie = (256,256) # 训练时裁剪的大小
train_pipeline = [
dict(type='LoadImageFromFile'), # 第一个流程,从文件路径加载图像
dict(type='LoadAnnotations'), # 第2个流程,对于当前图像,加载它的标注图像
dict(
type='RandomChoiceResize',
scales=[int(x * 0.1 * 256) for x in range(5, 21)],
resize_type='ResizeShortestEdge',
max_size=768),
dict(type='RandomCrop', crop_size=img_szie, cat_max_ratio=0.75),
dict(type='RandomFlip', prob=0.5), # 翻转图像和其标注图像的数据增广流程, 翻转图像的概率为0.5
dict(type='PhotoMetricDistortion'), # 光学上使用一些方法扭曲当前图像和其标注图像的数据增广流程
dict(type='PackSegInputs') # 打包用于语义分割的输入数据
]
test_pipeline = [
dict(type='LoadImageFromFile'), # 第1个流程,从文件路径里加载图像
dict(type='Resize', scale=img_szie, keep_ratio=True),
dict(type='LoadAnnotations'), # 加载数据集提供的语义分割标注
dict(type='PackSegInputs') # 打包用于语义分割的输入数据
]
train_dataloader = dict(
batch_size=2, # 每一个GPU的batch size大小
num_workers=1, # 为每一个GPU预读取数据的进程个数
persistent_workers=True, # 在一个epoch结束后关闭worker进程,可以加快训练速度
sampler=dict(type='InfiniteSampler', shuffle=True), # 训练时进行随机洗牌(shuffle)
dataset=dict( # 训练数据集配置
type=dataset_type,
data_root=data_root,
data_prefix=dict(
img_path='imgs/train', seg_map_path='annotations/train'),
pipeline=train_pipeline))
val_dataloader = dict(
batch_size=2,
num_workers=1,
persistent_workers=True,
sampler=dict(type='DefaultSampler', shuffle=False), # 训练时不进行随机洗牌(shuffle)
dataset=dict(
type=dataset_type,
data_root=data_root,
data_prefix=dict(
img_path='imgs/val',
seg_map_path='annotations/val'),
pipeline=test_pipeline))
test_dataloader = dict(
batch_size=2,
num_workers=1,
persistent_workers=True,
sampler=dict(type='DefaultSampler', shuffle=False),
dataset=dict(
type=dataset_type,
data_root=data_root,
data_prefix=dict(
img_path='imgs/test',
seg_map_path='annotations/test'),
pipeline=test_pipeline))
val_evaluator = dict(type='IoUMetric', iou_metrics=['mIoU'])
test_evaluator = val_evaluator
- 在
config/fcn/文件夹下找一个文件进行复制修改,名称为fcn_magnetic_tile-256×256.py
_base_ = [
'/home/s414e2/wjc/mm_ivd/configs/_base_/models/fcn_r50-d8_IVD.py', '/home/s414e2/wjc/mm_ivd/configs/_base_/datasets/magnetic_tile.py',
'/home/s414e2/wjc/mm_ivd/configs/_base_/default_runtime.py', '/home/s414e2/wjc/mm_ivd/configs/_base_/schedules/schedule_100k_IVD.py'
]
crop_size = (256, 256)
data_preprocessor = dict(size=crop_size)
model = dict(
data_preprocessor=data_preprocessor,
decode_head=dict(num_classes=6),
auxiliary_head=dict(num_classes=6))
其中,_base_ = [ ]中包含了训练策略文件,数据集文件,基础模型文件等,相关的更多要求如用不同的指标进行监控,使用更多的指标进行展示,如何规律地保持自己需要的权重文件等,部分内容在下面的相关细节中有更多的介绍。
3.训练代码运行
单GPU训练
python tools/train.py ${配置文件} [可选参数]
例如
python tools/train.py config/fcn_r50/fcn_magnetic_tile-256x256.py --work_dir = experimenta/magnetic_tile/
多GPU训练
# 训练代码运行
CUDA_VISIBLE_DEVICES=5,6 PORT=29560 bash ./tools/dist_train.sh configs/IVD_model/fcn_r50-d8_4xb4-20k_voc12aug-512x512.py 2 --work-dir=experiment/FCN/phonescreen
部分训练结果展示:
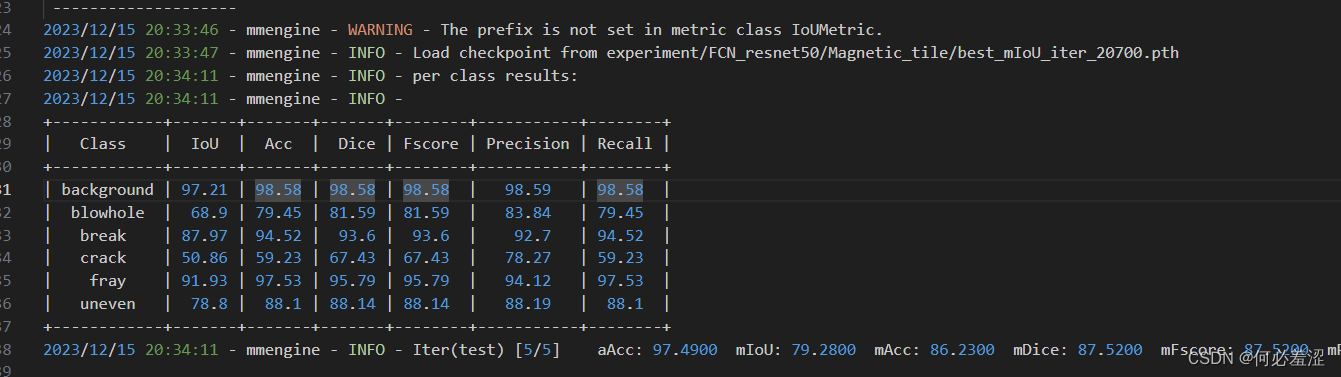
单GPU测试
python tools/test.py ${配置文件} ${模型权重文件} [可选参数]
其他更多的设置可以看mmsegmentation的训练测试手册:
https://github.com/open-mmlab/mmsegmentation/blob/main/docs/zh_cn/user_guides/4_train_test.md
4.其他相关细节
4.1训练过程的可视化监控
MMSegmentation 1.x 使用 TensorBoard 来监控训练时候的状态。
- tensorboard安装
pip install tensorboardX
pip install future tensorboard
- 更改配置文件
default_runtime.py
vis_backends = [dict(type='LocalVisBackend'),
dict(type='TensorboardVisBackend')]
visualizer = dict(
type='SegLocalVisualizer', vis_backends=vis_backends, name='visualizer')
- 启动训练代码
python tools/train.py configs/pspnet/pspnet_r50-d8_4xb4-80k_ade20k-512x512.py --work-dir work_dir/test_visual
4.可视化运行
tensorboard --logdir work_dirs/test_visual/20220810_115248/vis_data
4.2数据和结果的可视化
模型测试或验证期间的可视化数据样本
MMSegmentation 提供了 SegVisualizationHook ,它是一个可以用于可视化 ground truth 和在模型测试和验证期间的预测分割结果的钩子 。 它的配置在 default_hooks 中。
例如,在 _base_/schedules/schedule_20k.py 中,修改 SegVisualizationHook 配置,将 draw 设置为 True 以启用网络推理结果的存储,interval 表示预测结果的采样间隔, 设置为 1 时,将保存网络的每个推理结果。 interval 默认设置为 50:
default_hooks = dict(
timer=dict(type='IterTimerHook'),
logger=dict(type='LoggerHook', interval=50, log_metric_by_epoch=False),
param_scheduler=dict(type='ParamSchedulerHook'),
checkpoint=dict(type='CheckpointHook', by_epoch=False, interval=2000),
sampler_seed=dict(type='DistSamplerSeedHook'),
visualization=dict(type='SegVisualizationHook', draw=True, interval=1))
启动训练实验后,可视化结果将在 validation loop 存储到本地文件夹中,或者在一个数据集上启动评估模型时,预测结果将存储在本地。本地的可视化的存储结果保存在 $WORK_DIRS/vis_data 下的 vis_image 中,例如:
work_dirs/test_visual/20220810_115248/vis_data/vis_image
另外,如果在 vis_backends 中添加 TensorboardVisBackend ,如 TensorBoard 的配置,我们还可以运行下面的命令在 TensorBoard 中查看它们:
tensorboard --logdir work_dirs/test_visual/20220810_115248/vis_data
可视化单个数据样本
如果你想可视化单个样本数据,我们建议使用 SegLocalVisualizer 。
import mmcv
import os.path as osp
import torch
# `PixelData` 是 MMEngine 中用于定义像素级标注或预测的数据结构。
# 请参考下面的MMEngine数据结构教程文件:
# https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/data_element.html#pixeldata
from mmengine.structures import PixelData
# `SegDataSample` 是在 MMSegmentation 中定义的不同组件之间的数据结构接口,
# 它包括 ground truth、语义分割的预测结果和预测逻辑。
# 详情请参考下面的 `SegDataSample` 教程文件:
# https://github.com/open-mmlab/mmsegmentation/blob/1.x/docs/en/advanced_guides/structures.md
from mmseg.structures import SegDataSample
from mmseg.visualization import SegLocalVisualizer
out_file = 'out_file_cityscapes'
save_dir = './work_dirs'
image = mmcv.imread(
osp.join(
osp.dirname(__file__),
'./aachen_000000_000019_leftImg8bit.png'
),
'color')
sem_seg = mmcv.imread(
osp.join(
osp.dirname(__file__),
'./aachen_000000_000019_gtFine_labelTrainIds.png' # noqa
),
'unchanged')
sem_seg = torch.from_numpy(sem_seg)
gt_sem_seg_data = dict(data=sem_seg)
gt_sem_seg = PixelData(**gt_sem_seg_data)
data_sample = SegDataSample()
data_sample.gt_sem_seg = gt_sem_seg
seg_local_visualizer = SegLocalVisualizer(
vis_backends=[dict(type='LocalVisBackend')],
save_dir=save_dir)
# 数据集的元信息通常包括类名的 `classes` 和
# 用于可视化每个前景颜色的 `palette` 。
# 所有类名和调色板都在此文件中定义:
# https://github.com/open-mmlab/mmsegmentation/blob/1.x/mmseg/utils/class_names.py
seg_local_visualizer.dataset_meta = dict(
classes=('road', 'sidewalk', 'building', 'wall', 'fence',
'pole', 'traffic light', 'traffic sign',
'vegetation', 'terrain', 'sky', 'person', 'rider',
'car', 'truck', 'bus', 'train', 'motorcycle',
'bicycle'),
palette=[[128, 64, 128], [244, 35, 232], [70, 70, 70],
[102, 102, 156], [190, 153, 153], [153, 153, 153],
[250, 170, 30], [220, 220, 0], [107, 142, 35],
[152, 251, 152], [70, 130, 180], [220, 20, 60],
[255, 0, 0], [0, 0, 142], [0, 0, 70],
[0, 60, 100], [0, 80, 100], [0, 0, 230],
[119, 11, 32]])
# 当`show=True`时,直接显示结果,
# 当 `show=False`时,结果将保存在本地文件夹中。
seg_local_visualizer.add_datasample(out_file, image,
data_sample, show=False)
可视化后的图像结果和它的对应的 ground truth 图像可以在 ./work_dirs/vis_data/vis_image/ 路径找到,文件名字是:out_file_cityscapes_0.png :
4.3权重保存设置
查看checkpointhook的API
# 间隔两个epoch保存一次,如果acc和mIoU的性能有所提升,则保存权重文件
param_scheduler = [
dict(
type='PolyLR', # 调度流程的策略
eta_min=1e-5, # 训练结束时的最小学习率
power=0.9, # 多项式衰减 (polynomial decay) 的幂
begin=0, # 开始更新参数的时间步(step)
end=400, # 停止更新参数的时间步(step)
by_epoch=True) # 是否按照 epoch 计算训练时间
]
train_cfg = dict(type='EpochBasedTrainLoop', max_epochs=400, val_interval=1) #
logger=dict(type='LoggerHook', interval=1, log_metric_by_epoch=True), # 从'Runner'的不同组件收集和写入日志
CheckpointHook(interval=2, by_epoch=True,
save_best=['acc', 'mIoU'], rule='greater')
4.4添加相关的评估指标
MMSegmentation 基于 MMEngine 提供的 BaseMetric 实现 IoUMetric
其中 IoUMetric的IoUMetric.compute_metrics函数中,就有返回值:
- Dict[str,float] - 计算的指标。指标的名称为 key,值是相应的结果。key 主要包括 aAcc、mIoU、mAcc、mDice、mFscore、mPrecision、mPrecall。
返回多个评估指标的代码,对文件mmseg/iou_metric.py进行稍做修改
if metric == 'mIoU':
iou = total_area_intersect / total_area_union
acc = total_area_intersect / total_area_label
ret_metrics['IoU'] = iou
ret_metrics['Acc'] = acc
# 自己把所有的评估参数都加上去, 也就是把后面两部分的复制上来
dice = 2 * total_area_intersect / (
total_area_pred_label + total_area_label)
ret_metrics['Dice'] = dice
precision = total_area_intersect / total_area_pred_label
recall = total_area_intersect / total_area_label
f_value = torch.tensor([
f_score(x[0], x[1], beta) for x in zip(precision, recall)
])
ret_metrics['Fscore'] = f_value
ret_metrics['Precision'] = precision
ret_metrics['Recall'] = recall
elif metric == 'mDice':
dice = 2 * total_area_intersect / (
total_area_pred_label + total_area_label)
acc = total_area_intersect / total_area_label
ret_metrics['Dice'] = dice
ret_metrics['Acc'] = acc
elif metric == 'mFscore':
precision = total_area_intersect / total_area_pred_label
recall = total_area_intersect / total_area_label
f_value = torch.tensor([
f_score(x[0], x[1], beta) for x in zip(precision, recall)
])
ret_metrics['Fscore'] = f_value
ret_metrics['Precision'] = precision
ret_metrics['Recall'] = recall
5.其他相关的问题
5.1 数据集GT处理问题
出现的问题:
- 出现loss的损失计算的时候tensor形状无法对齐的问题
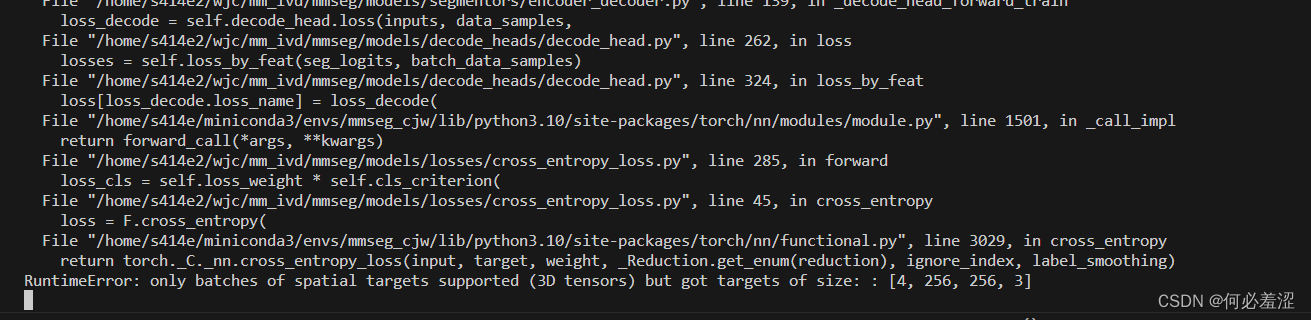
出现该问题是因为GT要设置为单通道的灰度图,部分的mask实质是三通道的,需要通过脚本进行统一处理。
5.2指标修改问题
mmsegmentaion中的权重没有办法选中指标最好的进行保存,需要自己设置好。在配置文件schedule中修改save_best对应的字典就好。
CheckpointHook(interval=2, by_epoch=True,
save_best=['acc', 'mIoU'], rule='greater')
5.3测试推理的时候出现“xxxDataset is not in the dataset registry”
检查自己自定义数据集的方法有没有问题,一步步参考mmsegmentation提供的文档:
主要的步骤如下:
- 在mmseg的dataset中创建自己的examdataset.py
- 在 mmseg/datasets/init.py 中导入模块
- 通过创建一个新的数据集配置文件 configs/base/datasets/example_dataset.py 来使用它
- 在 mmseg/utils/class_names.py 中补充数据集元信息
以上问题都排除在外依然无法解决,尝试重新建立仓库的包的元数据和依赖关系,我是通过这一步才解决的
pip install -v -e . # 在仓库的首级地址执行

















 2730
2730

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









