






情感分析的子领域
- 粗细粒度
粗粒度情感分析只是简单的积极或消极情感的划分,并计算出情感的强度。但是情绪更细的维度层次,应该还可以对正负情绪进行划分。比如,积极情绪的期待、喜悦,负面情绪的愤怒、悲伤、害怕等,分析单位更小更精准。 - aspect情感分析
“aspect”(方面)指的是被分析对象的不同方面或特定部分。Aspect-based sentiment analysis(方面级别情感分析)是一种情感分析方法,专注于对文本中不同方面或目标的情感进行分析,而不仅仅是对整体文本的情感进行分类。

文档级别情感分析
- 存在问题:一篇文档可能包含多个目标对象;粗粒度的文档情感会模糊掉这些细粒度。所以应用文档级别需要有一个很强的假设,即文档中只包含一个观点、一个情感对象、一个观点持有者。
- 适用场景:由于该假设非常强,文档级别的应用场景其实很有限**,一般在评价对象已定的场景下才能适用**,例如淘宝商品评价或豆瓣电影评价,即评价商品或电影已经在上下文中确定
- 优势:由于文档的文本长度比较长,包含足够多的上下文信息,在满足上述假设的情况下情感分析的效果会比较好。
- 方法:一般建模为文档分类任务

句子级别情感分析
- 存在问题
- 句子级别也需要遵从单一情感对象假设,在有的场景下并不符合例如对产品多个属性进行评价。另外,句子级别粒度仍然比较粗,没有最终定位到具体对象,应用场景有限制。
- 对于缺少上下文的短句子,可能没有足够多的特征来判断,需要依赖文档中的其他句子或短文本之外的上下文信息。
- 适用场景:同文档一样,如果情感对象已定,句子情感分析适合于大部分场景,并且其结果是很多其他任务的重要特征。
- 优势:任务简单,粒度比较细,应用性广
- 方法:一般建模为句子分类任务。

aspect情感分析
例如,考虑以下句子:“这台手机的电池续航很长,但相机质量一般。” 在这里,“电池续航” 和 “相机质量” 就是两个方面。Aspect-based sentiment analysis 将尝试为每个方面分别确定情感,而不是简单地对整个句子进行情感分类。在这个例子中,“电池续航” 可能被分类为正面,而 “相机质量” 可能被分类为一般或负面。
Aspect-based sentiment analysis 通常包含以下关键点:
- 目标(Aspect)
指文本中用户关注的特定方面、特征或实体,例如一篇产品评论中可能包含多个方面,如性能、外观、价格等。 - 情感分类: 针对每个方面,对其情感进行分类,通常划分为正面、负面或中性。这使得系统能够更细致地理解用户对每个方面的态度。
- 实例: 指的是与特定方面或目标相关联的具体描述、例子或提及以一条产品评论为例,考虑以下句子:“这台手机的电池续航很长,但相机质量一般。” 在这里:
“电池续航” 和 “相机质量” 是两个方面。
“电池续航很长” 是关于 “电池续航” 方面的一个实例。
“相机质量一般” 是关于 “相机质量” 方面的一个实例。



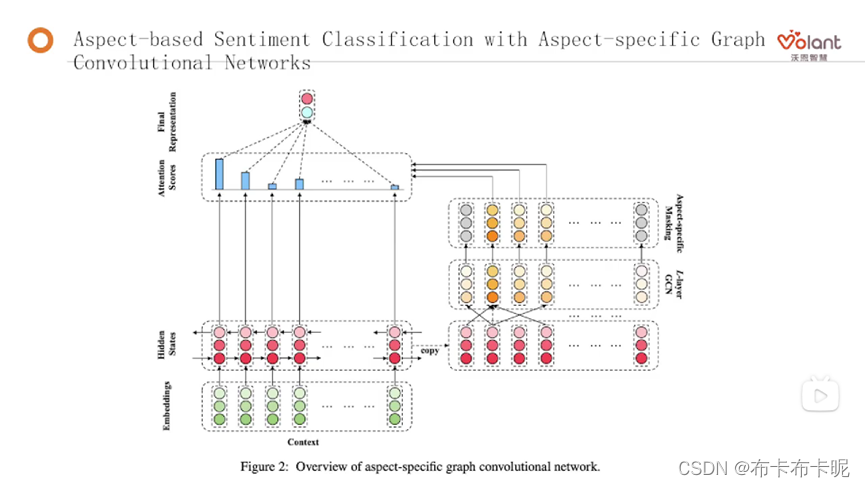
Aspect-Based Sentiment Classification with Aspect-specific Graph Convolutional Networks
将Bert当作上游,使用Bert作为embedding,再拿这个embedding做网络上的处理
-
BERT 作为上游模型: BERT是一个预训练的深度学习模型,专门用于处理自然语言处理任务。在这里,BERT 被视为上游模型,意味着它是在大量文本数据上进行预训练的模型,学习了丰富的语言表示。
- 上游模型指的是在某一任务上进行预训练的模型,其学到的知识和表示可以在下游任务中使用。上游模型通常被设计为通用的,能够学习丰富的语言表示。这些预训练的表示可以在下游任务中进行微调或者用作特征。
- 情感分析是一个下游任务
-
使用 BERT 进行文本嵌入(Embedding):“使用 BERT 进行文本嵌入” 意味着将文本输入到 BERT 模型中,并获得该文本在模型中学到的语义嵌入表示。嵌入表示是模型对输入文本进行编码后的向量化表示,其中包含了文本的语义信息。下面是一些详细的解释:
- 输入文本: 首先,需要有一段文本,例如一个句子或一个文档。这段文本是待处理的输入。
- Bert 模型: BERT(是一个预训练的深度学习模型,专门用于处理自然语言处理任务。在这个上下文中,BERT 被当作一个黑盒,它已经在大量文本数据上进行了预训练,学到了丰富的语言表示。
- Tokenization: 将输入文本进行分词,将其分解成一个个小的单元,称为 tokens。每个 token 通常对应一个词或者子词。
- 嵌入表示: 将分词后的 tokens 输入到 BERT 模型中。BERT 是一个 Transformer 模型,它的主要结构包含多层编码器。每个编码器都会对输入的 tokens 进行编码,并生成与每个 token 相关的语义嵌入表示。
- 输出: 模型的输出是每个输入 token 对应的语义嵌入表示。这些表示是向量,通常是高维度的,其中包含了输入文本的语义信息。
通过这个过程,原始的文本被转化为 BERT 模型学到的语义嵌入。这些嵌入可以在后续的任务中使用,例如情感分析、文本分类等。在一些任务中,这些嵌入可以直接作为输入,也可以进一步进行微调,以适应具体的任务需求。这种方式利用了 BERT 在大规模文本数据上学到的通用语言表示,为各种 NLP 任务提供了强大的基础。
-
将 BERT 输出用作神经网络的输入: 取得从 BERT 中得到的嵌入,然后将这些嵌入作为神经网络的输入。这可以是一个简单的前馈神经网络(Feedforward Neural Network)或者其他深度学习架构,具体取决于任务的性质。
-
网络上的进一步处理: 在神经网络的后续层中,可以执行各种操作,如降维、特征选择、添加额外的上下文层等。这一步是为了更好地适应具体的任务,例如文本分类、命名实体识别、情感分析等。
总体而言,这种方法的优势在于 BERT 预训练模型能够学到非常丰富的语言表示,使得它的输出嵌入包含了输入文本的高级语义信息。将这些嵌入用作神经网络的输入,可以帮助提高网络对文本任务的性能,而不需要从头开始训练一个大型深度学习模型。

















 615
615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









