






 本文介绍了强化学习的基本概念,将其与监督学习和自监督学习进行对比,重点讲解了RL的三个步骤——寻找PolicyNetwork,定义基于奖励的loss,以及优化参数以最大化总奖励。同时讨论了PolicyGradient方法在RL中的应用,包括收集训练数据、评价行为和调整策略的过程。
本文介绍了强化学习的基本概念,将其与监督学习和自监督学习进行对比,重点讲解了RL的三个步骤——寻找PolicyNetwork,定义基于奖励的loss,以及优化参数以最大化总奖励。同时讨论了PolicyGradient方法在RL中的应用,包括收集训练数据、评价行为和调整策略的过程。
什么是Reinforcement Learning(RL)?目前讲的都是supervised Learning(带有标签资料的数据),比如在分类任务的时候我们有输入,然后通过模型得到输出,这个输出要和人类设定的标签一致才能说这个模型做对了,就算之前讲的self supervised Learning也是类似supervised Learning,只不过自监督学习不需要人力去设定标签,而是让模型自己学习产生标签。在RL中我们面临的另外一种问题--当我们给模型一个输入的时候,人类自己也不知道最佳的输出应该是什么,比如说下棋,这就是使用RL的时候。
一、什么是RL
RL其实和machine Learning很像,也是三个步骤。机器学习就是找一个函数,RL也是找一个函数,这个函数里面有两个变量-行为(Actor)和环境(Environment),两者进行互动。
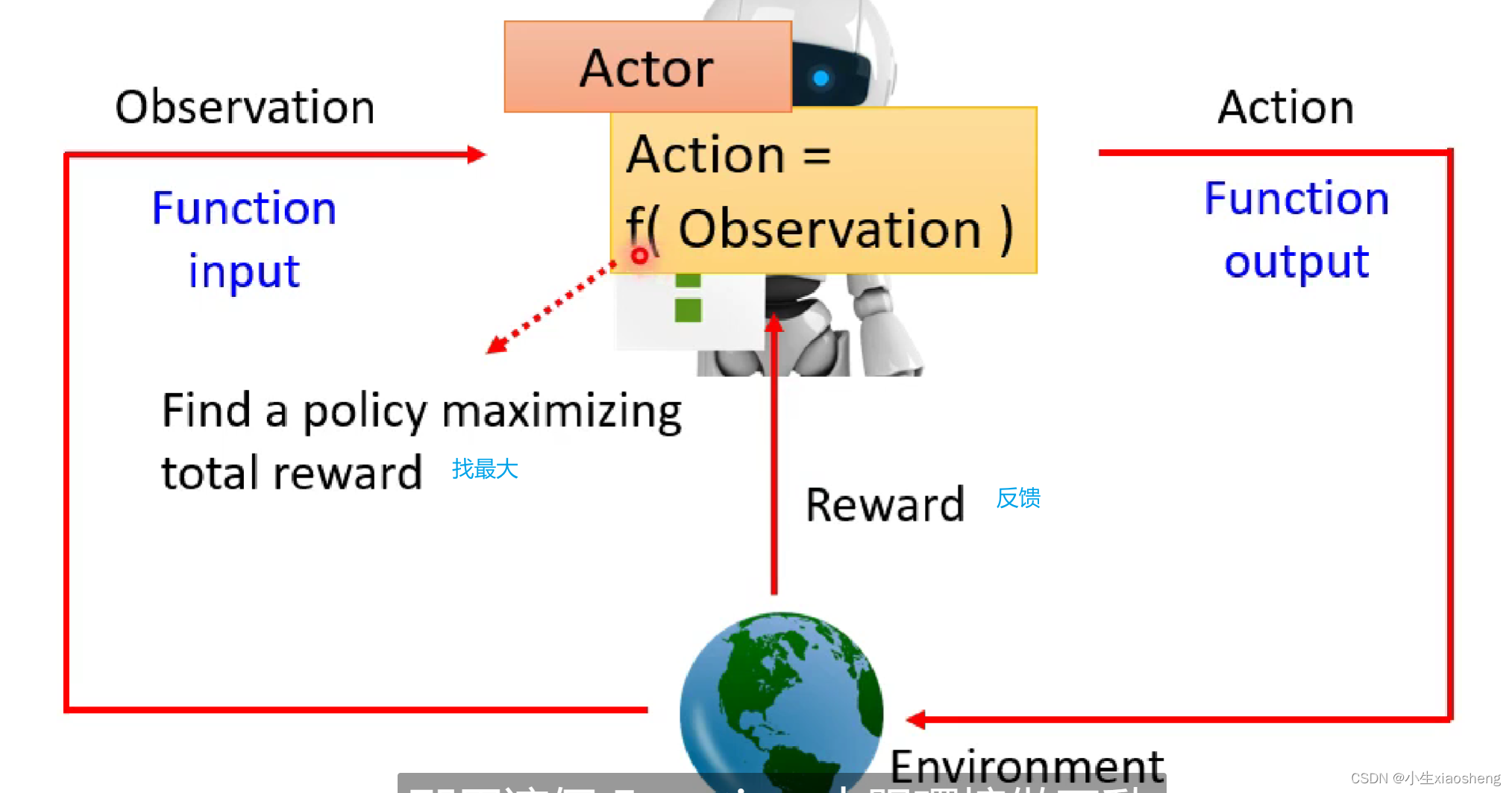
机器学习的三个步骤是:1.找出定义函数中的所有未知数;2.定义loss函数来训练数据;3.找到未知数参数从而得到最小的loss。而RL和这三个步骤是一样的。
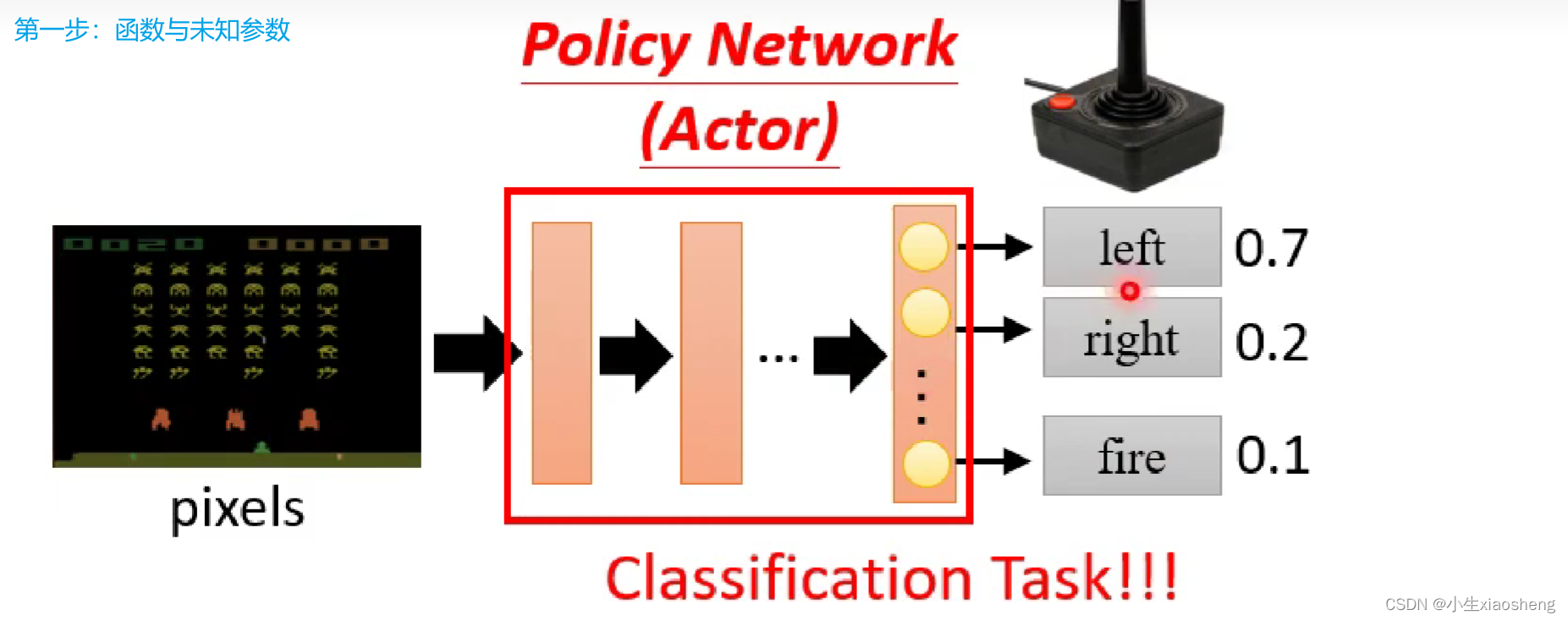
第①步:在RL中第一步里面的函数就是Actor,我们一般把这个函数叫做Policy Network,这个网络可能和分类网络很像,当然中间的网络可以是各种网络,最后的结果可以是概率最大的执行,也可以是概率大的执行的概率大一些,但是不一定执行。
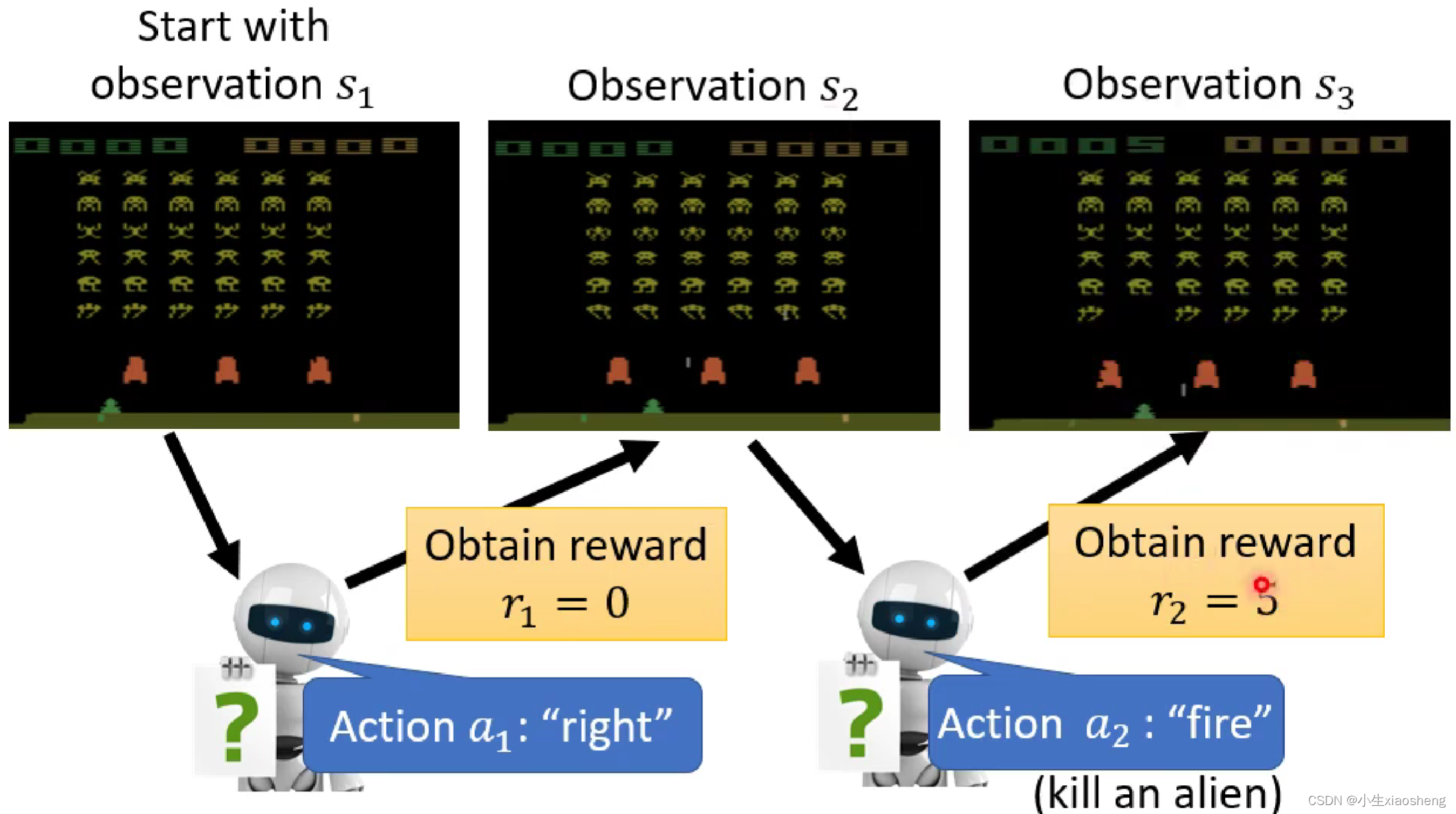
 第②步:定义我们的loss,首先有一个输入输到模型中,然后从模型中得到一个输出,执行这个输出的动作之后,画面出现变动,然后把变得的画面再输入到模型中,模型再次得到输出,如果模型在一些列输出的过程中做的不错,那么就会得到正的reward,直到最后的结束。所有的这个过程叫做episode,所有的reward集合起来叫做total reward。我们训练的目标就是希望total reward最大。
第②步:定义我们的loss,首先有一个输入输到模型中,然后从模型中得到一个输出,执行这个输出的动作之后,画面出现变动,然后把变得的画面再输入到模型中,模型再次得到输出,如果模型在一些列输出的过程中做的不错,那么就会得到正的reward,直到最后的结束。所有的这个过程叫做episode,所有的reward集合起来叫做total reward。我们训练的目标就是希望total reward最大。
第③步:优化的目标是在网络中学习到一系列的参数,使得最后的total reward越大越好,这也是整个网络最麻烦的地方,很难训练。
二、Policy Gradient
我们要怎么让网络在看到某一个特定的环境的时候,采取某一个特定的行为呢?在这个地方其实和supervised Learning一样,有真实的标签,也就是正确答案,在要使得L变得越来越大的情况下会更新参数,但是还是有区别。
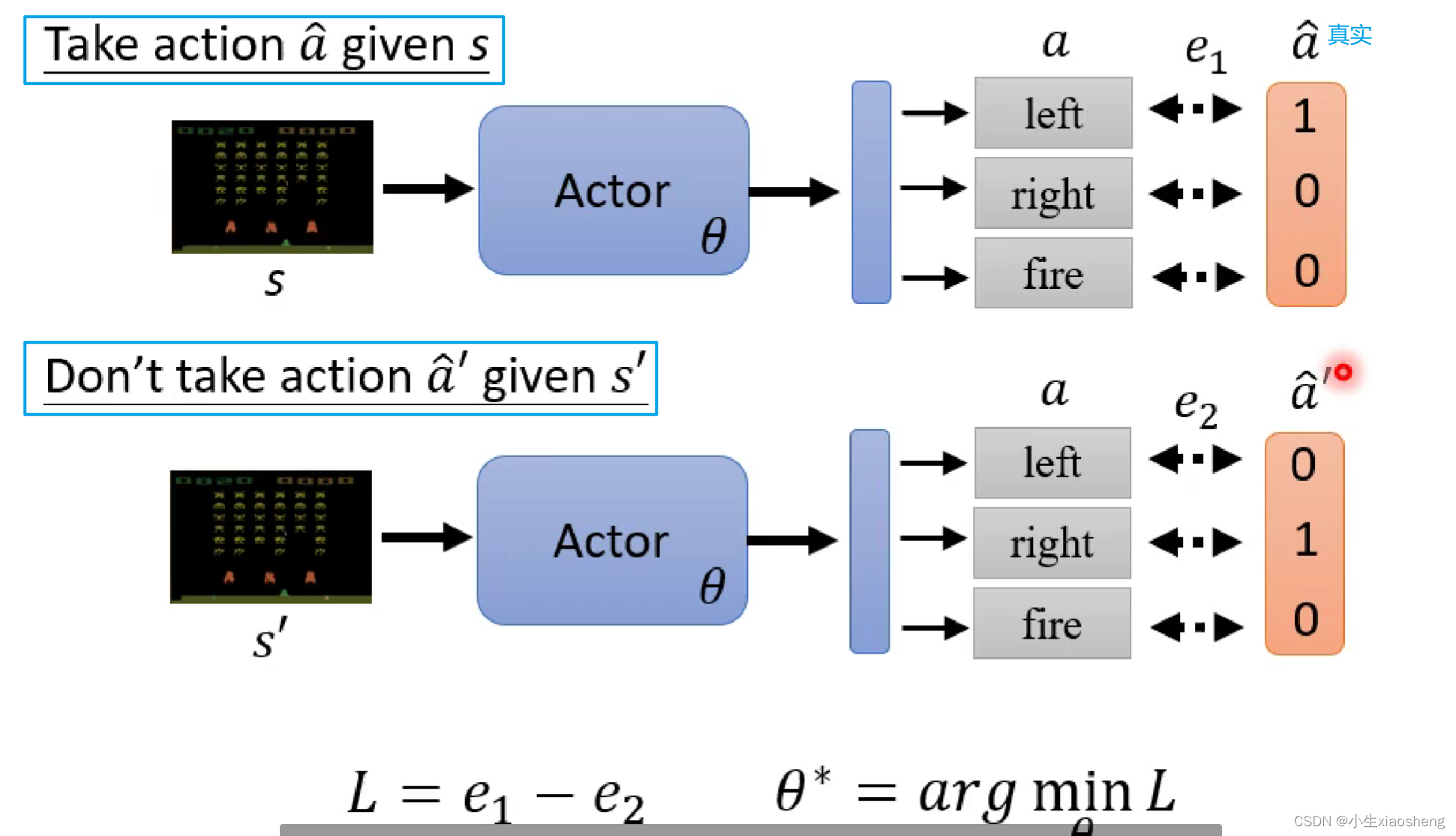
所以我们会在训练网络的时候准备一些训练资料,这些资料有正负样本,然后定义loss函数就能训练整个网络了,从而更新参数,那么我们要怎么准备这个训练资料并且得到相应的Ai,得到Ai的过程就是和传统的supervised Learning区别的地方。
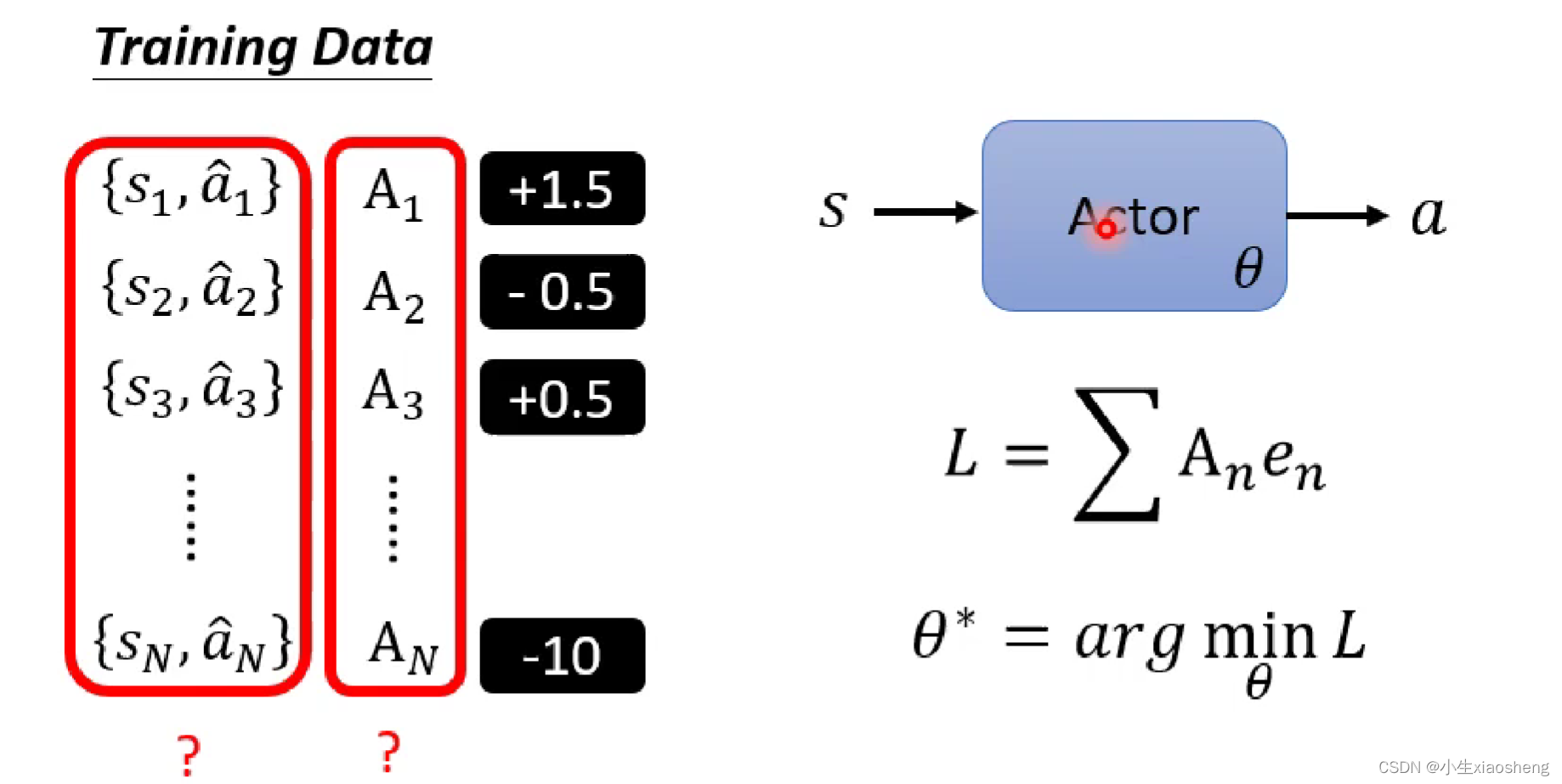
得到Ai的有以下几种情况:1.首先我们还是要去收集资料,不过得有一个Actor网络,让这个网络和环境进行互动,这样我们就能收集到训练资料中的s和a。而Actor可以理解为一个随机出来的函数,当然此时得到的结果可能就是很乱的训练资料,我们对这些训练得到的结果进行评价也就是Ai,这个评价结果就是训练时得到的reward,但是这个方法并不是一个很好的方法,因为一个行为肯定会影响接下来的行为,但是这样只考虑了目前的情况,所以不是很好,而且可能存在这样的情况我们需要牺牲部分好的reward,而得到最终整个好的reward。2.所以有这种方法,前面执行动作会造成后面所有的结果,所有就把这个动作之后的所有reward加起来,但是这个方法也存在一个问题,比如整个资料特别长,所以前面的动作有影响,但是不一定是最重要的影响。所以我此基础上对于相应得到reward乘上距离的概念。
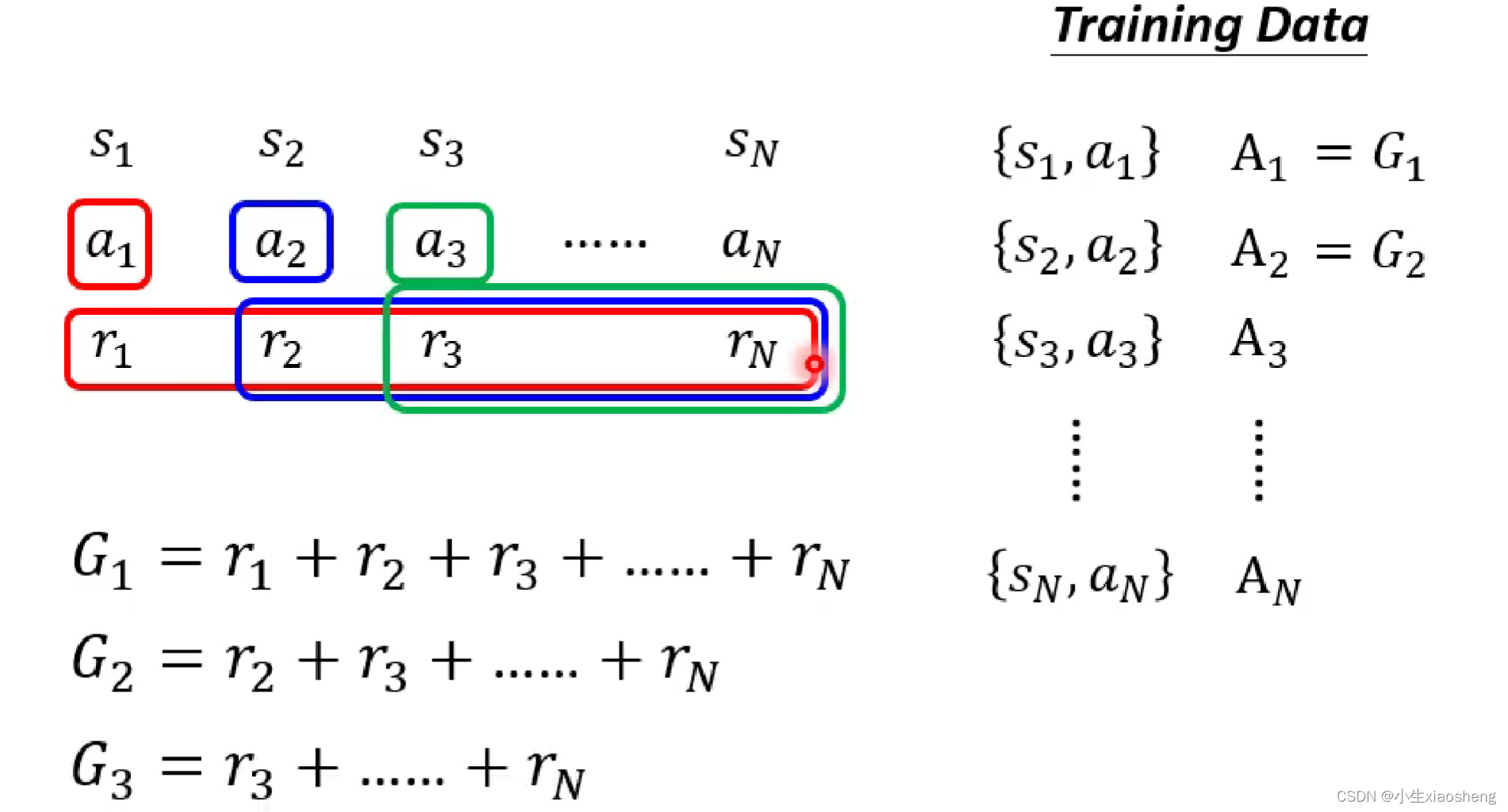
3.在上面的基础上做归一化,reward是相对的,有正反馈,但是有更大的正反馈,所以我们在得到的所有Gi上再减去b基线参数。
Policy Gradient的具体流程:首先随机初始化Actor参数,然后进行训练也就是Actor和环境进行互动,这样就得到一系列的s和a,然后使用A来判断这些s和a到底好还是不好,然后定义loss并且更新参数。
















 4574
4574











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









