






前言
概述增强式学习(一)
一、增强式学习reinforcement learning
RL里面遇到的问题是,给机器一个输入时,人类也不知道最佳输出是什么。比如下围棋,下一步落子应该在哪里的问题(最佳位置)。
RL是机器学习的一种,也在找一个function。RL里面有一个actor和一个environment会进行互动。Environment给actor一个observation(一个输入),actor看到observation后会有一个输出(action),action影响environment,environment给与actor新的observation,actor给与新的action…这个Actor就是要找的function,在actor和environment互动的过程中,environment会不断给actor reward,reward表示actor采取的这个action是好的还是不好的。Actor那observation当做input,action当做output,function的目标是要去maximize 从environment获得的reward的总和。
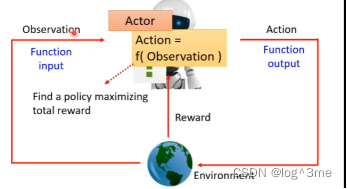
在下围棋上,observation就是棋盘中的黑/白子情况,action就是落子后的。在下围棋的过程中没有办法获得reward,只有在结束是,输或者赢会获得分数。
二、RL三步骤
一:function with unknown
Actor是一个network,actor的输出就像分类任务一样,经过softmax获得一个分数,机器把分数当做概率,根据概率随机选取一个当做action。不选择分数最高的有一个好处是,就算面对同样的输入,机器采取的行为也会略有不同,随机性有时候是很重要的。Actor中的未知变量是要被学出来的东西。
二:RL中训练资料的Loss
从开始到结束,叫做一个episode。在整个过程中actor会获得很多reward,把整个过程中的reward加起来叫做return。这个return就是要去最大化的东西(训练的目标),从而负的return就是RL需要的loss。
三:优化

Environment和actor产生的互动中的s1,a1,s2,a2等等叫做Trajectory。Reward有时候光看action是不够的,也要看observation。Optimization的过程就是learn出一组参数,这组参数放到actor里面可以让R的数值越大越好。有一些问题,导致RL和普通的训练不太一样。第一个问题是actor的输出是有随机性的,a是有sample产生的,同样的s,每次的a可能是不同的。另外environment也是有随机性的,比如围棋中,落子在同一个位置,对手的回应可以是不一样的。
整个问题其实跟GAN有异曲同工之妙,在训练GAN的时候,会把generator和discriminator接在一起,调generator的参数让discriminator的输出越大越好。在RL中actor就像generator,environment和reward就像discriminator。但是在RL中environment和reward不是network,是一个黑盒子,不能通过gradient descent调整参数。
Policy gradient
如何控制actor在输入是s时,输出a。假设a是label,计算actor的输出和a的cross entropy。定义loss,假设希望actor采取a~行为时,loss=cross entropy,learn 让loss最小。如果希望actor不采取某个行动时,只要把loss改为负的。
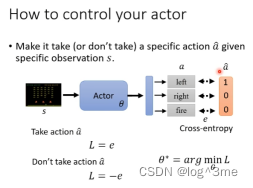
如果要训练一个actor就要收集一些训练资料,如看到s1采取a1,s2不要采取a2等等。s和a~组合是有期待值的,有正有负有大有小。可以定义一个loss只是在原来的cross-entropy上乘上这个组合的期待值。
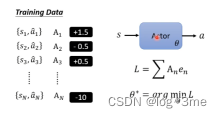
总结
学习视频地址:https://www.bilibili.com/video/BV13Z4y1P7D7/?p=28&spm_id_from=333.1007.top_right_bar_window_history.content.click&vd_source=3a369b537e1d34ff9ba8f8ab23afedec














 1028
1028











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









