







提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
目录
前言
在前面的实验中我们利用Logistic回归方法对审计风险数据进行了分类,此次我们仍然使用这个数据集用支持向量机的方法对其进行分类。
提示:以下是本篇文章正文内容,下面案例可供参考
一、支持向量机
1.1 简介
支持向量机,因其英文名为support vector machine,故一般简称SVM,是一类按监督学习方式对数据进行二元分类的广义线性分类器。通俗来讲,它是一种二类分类模型,其基本模型定义为特征空间上的间隔最大的线性分类器,其学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。最基础的便是二分类问题,给定一个数据集,含有多个属性,通过这些属性,建立超平面,使得这些点分为2类,定义标签1与-1,然后对其他的点进行预测。
假如数据是完全线性可分的,那么学习到的模型可以称为硬间隔支持向量机。换个说法,硬间隔指的就是完全分类准确,不能存在分类错误的情况。软间隔就是允许一定量的样本分类错误。

1.2 算法思想
找到集合边缘上的若干数据(称为支持向量),用这些点找出一个平面(称为决策面),使得支持向量到该平面的距离最大。在下图中红色线就是两个类别的决策面,距离超平面最近的且满足一定条件的几个训练样本点被称为支持向量。

1.3 背景知识
任意超平面可以用一个线性方程描述:
![]()
二维空间点(x,y)到直线Ax+By+C=0的距离公式为:
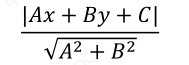
扩展到n维空间后,点(x1,x2,...,xn)到超平面的距离为:
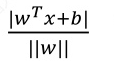 ,其中
,其中

如图所示,根据支持向量的定义知,支持向量到超平面的距离为d,其他点到超平面的距离大于d。每个支持向量到超平面距离可以写为:
于是可以得到如下公式:
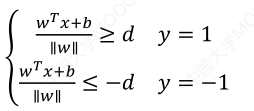
我们暂且令d 为1(之所以令它等于1,是为了方便推导和优化,且这样做对目标函数优化没有影响),将两个方程合并,我们可以简写为:![]()
支持向量机的最终目的是最大化 d
函数间隔:![]()
几何间隔: ![]() ,一般是实例点到超平面的带符号的距离,当样本点被超平面正确分类时就是实例点到超平面的距离。
,一般是实例点到超平面的带符号的距离,当样本点被超平面正确分类时就是实例点到超平面的距离。
几何间隔与函数间隔的关系:d = d*/||w||
1.4 最大间隔与分类
(1)转化为凸函数
为了求解几何间隔最大,SVM基本问题可以转化为求解:

函数间隔的取值对不等式约束条件不影响,因此令d*=1,则:

将求解最大值转换为求解最小值:(1/2是为了求导之后方便计算)

间隔最大化的toy example:

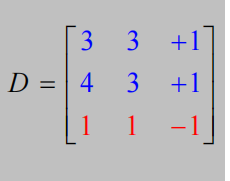

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1250
1250











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









