






摘要
论文链接:https://arxiv.org/pdf/2307.00395.pdf
传统上,卷积神经网络(CNN)和视觉Transformer(ViT)在计算机视觉领域占据主导地位。然而,最近提出的视觉图神经网络(ViG)提供了一个新的探索途径。不幸的是,对于移动应用程序,由于将图像表示为图形结构的开销,ViG在计算上是昂贵的。在这项工作中,我们提出了一种新的基于图的稀疏注意机制,稀疏视觉图注意(SVGA),该机制专为运行在移动设备上的稀疏视觉图而设计。此外,我们提出了第一个用于移动设备视觉任务的混合CNN-GNN架构,MobileViG,它使用SVGA。大量实验表明,MobileViG在图像分类、目标检测和实例分割任务的准确性和/或速度方面优于现有的ViG模型和现有的移动CNN和ViT架构。我们最快的模型,MobileViG-Ti,在ImageNet-1K上达到75.7%的top-1精度,在iPhone 13 Mini NPU(用CoreML编译)上的推理延迟为0.78 ms,比MobileNetV2x1.4 (1.02 ms, 74.7% top-1)和MobileNetV2x1.0 (0.81 ms, 71.8% top-1)快。我们最大的模型MobileViG-B获得了82.6%的top-1准确率,只有2.30 ms的延迟,比同样大小的EfficientFormer-L3模型(2.77 ms, 82.4%)更快更准确。我们的工作证明,设计良好的混合CNN-GNN架构可以为在移动设备上设计非常快速和准确的模型提供新的探索途径。我们的代码可以在https://github.com/SLDGroup/MobileViG上公开获得。
1、简介
人工智能(AI)和机器学习(ML)在过去十年中有了爆炸式的增长。在计算机视觉中,这种增长背后的关键驱动因素是神经网络的重新出现,特别是卷积神经网络(CNN)和最近的视觉Transformer[4,25]。尽管通过反向传播训练的CNN是在20世纪80年代发明的[16,25],但它们被用于更小规模的任务,如字符识别[17]。CNN重塑人工智能领域的潜力直到在ImageNet[32]竞赛中引入AlexNet[15]才完全实现。对CNN架构的进一步改进提高了其准确性、效率和速度[10,12,13,33,34]。与CNN架构一样,纯多层感知器(MLP)架构和类似MLP的架构也有望成为通用视觉任务的主干[2,37,38]。
虽然CNN和MLP已经在计算机视觉领域得到了广泛的应用,但由于视觉和语言任务的差异,自然语言处理领域使用的是递归神经网络(RNN),特别是长短期记忆(LSTM)网络[11]。虽然LSTM仍在使用,但在NLP任务[40]中,它们在很大程度上已被Transformer架构取代。随着视觉Transformer (ViT)的引入,介绍了一种同时适用于语言和视觉领域的[4]网络架构。通过将图像分割为一系列块嵌入,图像可以转换为Transformer模块[4]可用的输入。与CNN或MLP相比,Transformer架构的主要优势之一是其全局感受野,使其能够从图像中的远处物体交互中学习。
图神经网络(GNN)已经发展到在基于图的结构上运行,如生物网络、社会网络或引文网络[7,14,43,45]。GNN甚至被用于节点分类[14]、药物发现[5]、欺诈检测[23]等任务,以及最近提出的视觉GNN (ViG)[8]的计算机视觉任务。简而言之,ViG将图像分割成多个小块,然后通过k近邻(KNN)算法将这些小块连接起来[8],从而提供了类似于ViTs的处理全局对象交互的能力。
移动应用的计算机视觉研究快速增长,导致使用CNN学习空间局部表示和使用视觉Transformer(ViT)学习全局表示的混合架构[27]。当前的ViG模型不适合移动任务,因为它们在移动设备上运行时效率低下且速度缓慢。可以探索从CNN和ViT模型设计中学习到的概念,以确定CNN- GNN混合模型是否能够提供基于CNN的模型的速度和基于ViT的模型的精度。在这项工作中,我们研究了移动设备上计算机视觉的混合CNN-GNN架构,并开发了一种基于图的注意力机制,可以与现有的高效架构竞争。我们的贡献总结如下:
- 我们提出了一种新的基于图的稀疏注意力方法,用于移动视觉应用。我们将这种注意方法称为稀疏视觉图注意(SVGA)。我们的方法是轻量级的,因为它不需要重塑,并且与以前的方法相比,在图构建中产生的开销很小。
- 我们使用我们提出的SVGA、最大相对图卷积[18]以及来自移动CNN和移动视觉Transformer架构[12,27]的概念(我们称之为MobileViG),为视觉任务提出了一种新的移动CNN- GNN架构。
- 我们所提出的模型MobileViG在三个代表性视觉任务(ImageNet图像分类、COCO目标检测和COCO实例分割)上的精度和/或速度方面,与现有的视觉图神经网络(ViG)、移动卷积神经网络(CNN)和移动视觉Transformer (ViT)架构相匹配或优于。
据我们所知,本文是第一个研究移动视觉应用的混合CNN-GNN架构。所提出的SVGA注意力方法和MobileViG架构为最先进的移动架构和ViG架构开辟了一条新的探索路径。
本文的结构如下。第2节介绍了ViG和移动架构领域的相关工作。第3节描述了SVGA和MobileViG架构背后的设计方法。第4节介绍了ImageNet-1k图像分类、COCO目标检测和COCO实例分割的实验设置和结果。最后,第五部分对本文进行了总结,并对未来在移动架构设计中使用ViGs的工作提出了建议。
2、相关工作
由于能够以更灵活的格式表示图像数据,ViG[8]被提出作为CNN和ViTs的替代方案。ViG通过使用KNN算法来表示图像[8],其中图像中的每个像素都关注相似的像素。ViG的性能与流行的ViT模型DeiT[39]和SwinTransformer[24]相当,值得进一步研究。
尽管基于ViT的模型在视觉任务中取得了成功,但与轻量级的基于CNN的模型相比,它们仍然较慢[21],相比之下,基于CNN的模型缺乏基于ViT的模型的全局感受野。因此,通过提供比基于ViT的模型更快的速度和比基于CNN的模型更高的精度,基于ViT的模型可能是一种可能的解决方案。据我们所知,目前还没有关于移动ViGs的作品;然而,在移动CNN和混合模型领域,已有很多研究成果。我们将移动架构设计分为两大类:卷积神经网络(CNN)模型和混合CNN- ViT模型,其中融合了CNN和ViT的元素。
基于CNN架构的MobileNetv2[33]和EfficientNet[35,36]家族是第一批在常见图像任务中取得成功的移动模型。这些模型轻量级,推理速度快。然而,纯粹基于CNN的模式已经逐渐被混合竞争对手所取代。
目前存在大量的混合移动模型,包括MobileViTv2[28]、EdgeViT[29]、LeViT[6]、EfficientFormerv2[20]等。这些混合模型在图像分类、物体检测和实例分割任务方面始终优于MobileNetv2,但其中一些模型在延迟方面的表现并不总是那么好。延迟差异可能与包含ViT块有关,传统上,ViT块在移动硬件上速度较慢。为了改善这种状况,我们提出了MobileViG,它提供了与MobileNetv2[33]相当的速度和与EfficientFormer[21]相当的精度。
3、方法
在本节中,我们将介绍SVGA算法,并详细介绍MobileViG架构设计。更准确地说,3.1节介绍了SVGA算法。3.2节解释了我们如何从ViG[8]改编Grapher模块来创建SVGA块。3.3节描述了我们如何将SVGA块与反向残差块结合起来进行本地处理,以创建MobileViGTi、MobileViG-S、MobileViG-M和MobileViG-B。
3.1、稀疏视觉图注意力
本文提出稀疏视觉图注意力(SVGA)作为一种适用移动端的替代方案,取代视觉GNN[8]中的KNN图注意力。基于KNN的图注意力引入了两个不适用移动端的组件,KNN计算和输入重塑,我们用SVGA删除了它们。

更详细地说,每个输入图像都需要KNN计算,因为每个像素的最近邻居不能提前知道。这将产生一个图,如图1a所示,其中包含看似随机的连接。由于KNN的非结构化性质,[8]的作者将输入图像从4D张量重塑为3D张量,使他们能够正确对齐连接像素的特征进行图卷积。在图卷积之后,输入必须从3D重塑回4D,以进行后续的卷积层。因此,基于KNN的注意力需要KNN计算和两次重塑操作,这两种操作在移动设备上都是代价高昂的。
为了消除KNN计算和重构操作的开销,SVGA假设图是固定的,其中每个像素都连接到其行和列的第k个像素。例如,给定一个8×8图像和K = 2,左上角的像素将连接到其行上的每一个像素和其列下的每一个像素,如图1b所示。对输入图像中的每个像素重复相同的模式。由于图具有固定的结构(即,每个像素对于所有8×8输入图像将具有相同的连接),因此输入图像不必进行重塑以执行图卷积。

相反,它可以通过跨两个图像维度的滚动操作来实现,在算法1中表示为 r o l l r i g h t roll_{right} rollright和 r o l l d o w n roll_{down} rolldown。roll操作的第一个参数是roll的输入,第二个参数是向右或向下滚动的距离。使用图1b中的示例,其中K = 2,通过将图像向右滚动两次、向右滚动4次、向右滚动6次,可以将左上角的像素与该行中的每秒像素对齐。对于所在列中的每一个像素,除了向下滚动之外,也可以执行相同的操作。注意,由于每个像素都以相同的方式连接,因此用于将左上角像素与其连接对齐的滚动操作会同时将图像中其他每个像素与其连接对齐。在MobileViG中,使用最大相对图卷积(MRConv)执行图卷积。因此,每次 r o l l r i g h t roll_{right} rollright和 r o l l d o w n roll_{down} rolldown操作后,都会计算原始输入图像与滚动版本之间的差值,在算法1中记为 X r X_r Xr和 X c X_c Xc,最大的操作取元素并存储在 X j X_j Xj中,也在算法1中记为 X j X_j Xj。在完成滚动和max-relative操作后,执行最终的Conv2d。通过这种方法,SVGA将KNN计算换成了成本更低的滚动操作,因此不需要重构来执行图卷积。
SVGA避开了KNN的表示灵活性,而更倾向于适应移动端。
3.2、SVGA块
将SVGA和更新后的MRConv层插入视觉GNN[8]中提出的Grapher块。给定输入特征
X
∈
R
N
×
N
X \in \mathbb{R}^{N \times N}
X∈RN×N,更新后的Grapher表示为
Y
=
σ
(
M
R
Ronv
(
X
W
in
)
)
W
out
+
X
Y=\sigma\left(M R \operatorname{Ronv}\left(X W_{\text {in }}\right)\right) W_{\text {out }}+X
Y=σ(MRRonv(XWin ))Wout +X
其中$ Y \in \mathbb{R}^{N \times N}, W_{\text {in }} 和 和 和W_{out}$为全连接层权重,σ为GeLU激活。在MRConv步骤中,我们还将滤波器组的数量从4(视觉GNN[8]中使用的值)更改为1,以增加MRConv层的表达潜力,而不会明显增加延迟。更新后的Grapher模块如图2d所示。
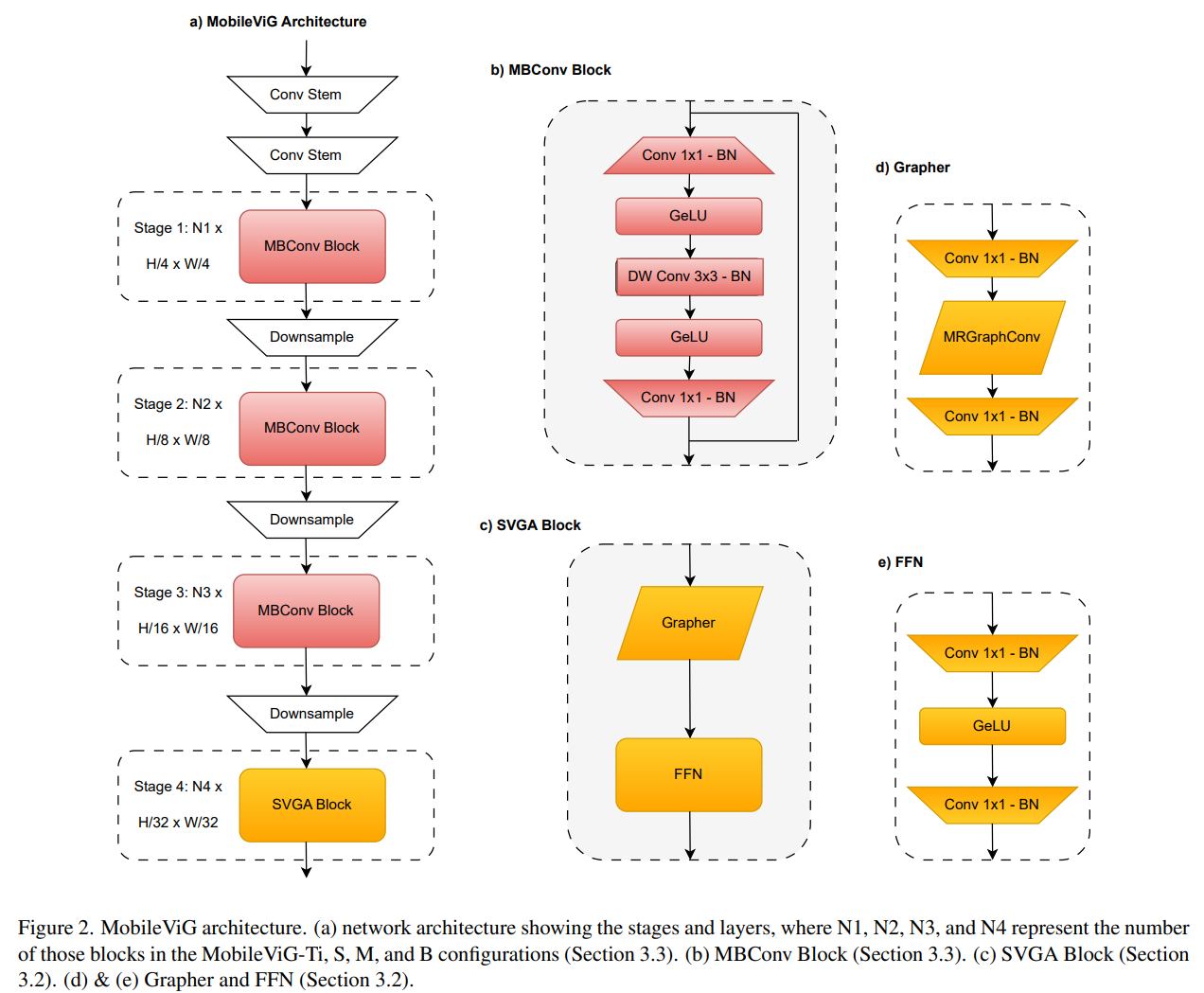
在更新后的Grapher之后,我们使用Vision GNN[8]中提出的前馈网络(FFN)模块,如图2e所示。FFN模块是一个两层MLP,表示为
Z
=
σ
(
X
W
1
)
W
2
+
Y
Z=\sigma\left(X W_{1}\right) W_{2}+Y
Z=σ(XW1)W2+Y
其中
Z
∈
R
N
×
N
,
W
1
Z \in \mathbb{R}^{N \times N}, W_{1}
Z∈RN×N,W1和
W
2
W_2
W2为全连接层权值,σ再次为GeLU。我们称这种更新后的Grapher和FFN的组合为SVGA块,如图2c所示。
3.3、MobileViG架构
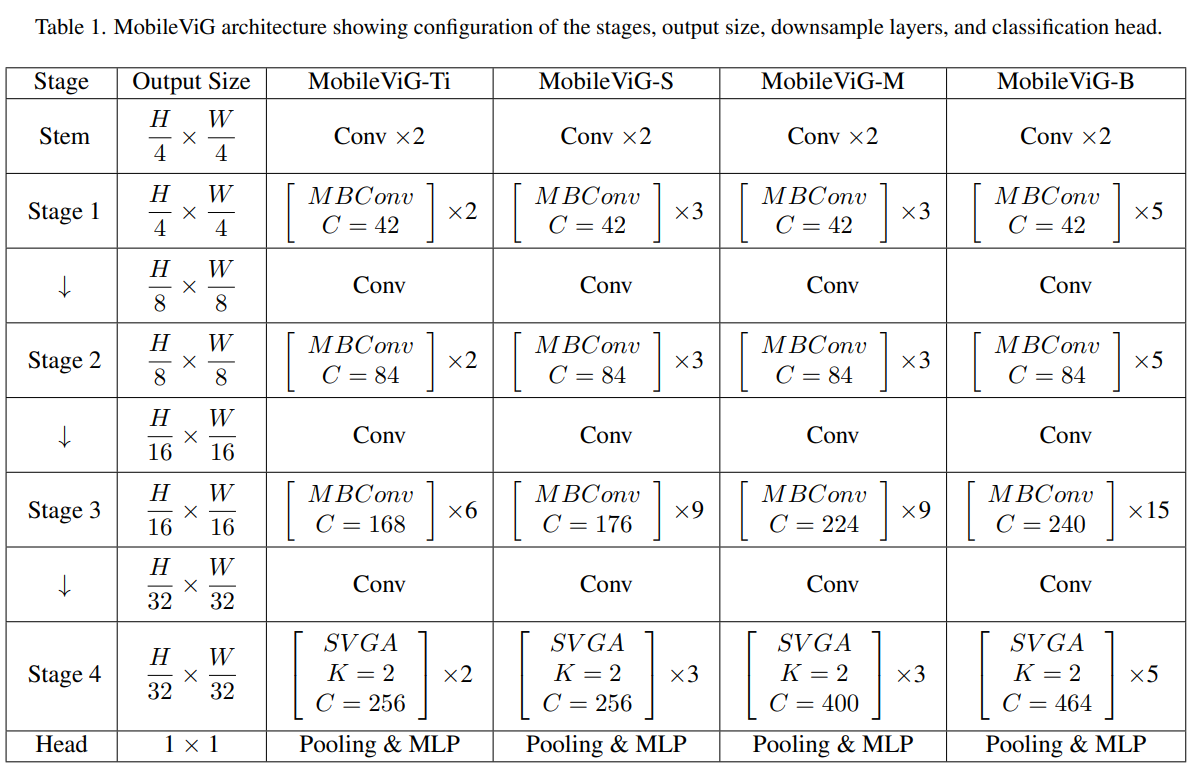
图2a所示的MobileViG架构由一个卷积Stem和三个阶段的反向残差块(MBConv)组成,其扩展比为4,用于本地处理,如MobileNetv2[33]所示。在MBConv块中,我们将ReLU6替换为GeLU,因为它已被证明可以提高计算机视觉任务的性能[4,20]。MBConv块包括1×1卷积加批量归一化(BN)和GeLU,深度3×3卷积加BN和GeLU,最后是1×1卷积加BN和残差连接,如图2b所示。在MBConv块之后,我们有一个SVGA块阶段来捕获全局信息,如图2a所示。在SVGA块之后,我们还有一个卷积头用于分类。在每个MBConv阶段之后,下采样步骤将输入分辨率减半并扩展通道维度。每个阶段由多个MBConv或SVGA块组成,其中重复的数量根据模型大小而改变。MobileViG-Ti、MobileViG-S、MobileViG-M和MobileViG-B的信道维度和每个阶段重复的块数如表1所示。
4、实验结果
我们将MobileViG与ViG[8]进行比较,并在表2中展示了MobileViG在ImageNet-1k[3]上的延迟、模型大小和图像分类精度方面的优越性能。我们还将MobileViG与几个移动模型进行了比较,并在表3中显示,对于每个模型,它在准确性和延迟方面都具有优越或相当的性能。

4.1、图像分类
我们使用PyTorch 1.12[30]和Timm库[42]实现该模型。我们使用8个NVIDIA A100 GPU来训练每个模型,有效批大小为1024个。模型在ImageNet1K[3]上使用AdamW优化器[26]从头开始训练300个epoch。学习率设置为2e-3,余弦退火策略。我们使用标准的图像分辨率,224 × 224,用于训练和测试。与DeiT[39]类似,我们使用RegNetY-16GF[31]进行知识蒸馏,准确率为82.9%。对于数据增强,我们使用RandAugment, Mixup, Cutmix,随机擦除和重复增强。
我们使用iPhone 13 Mini (iOS 16)对NPU和GPU的延迟进行基准测试。这些模型是用CoreML编译的,延迟是超过1000次预测的平均值[1]。
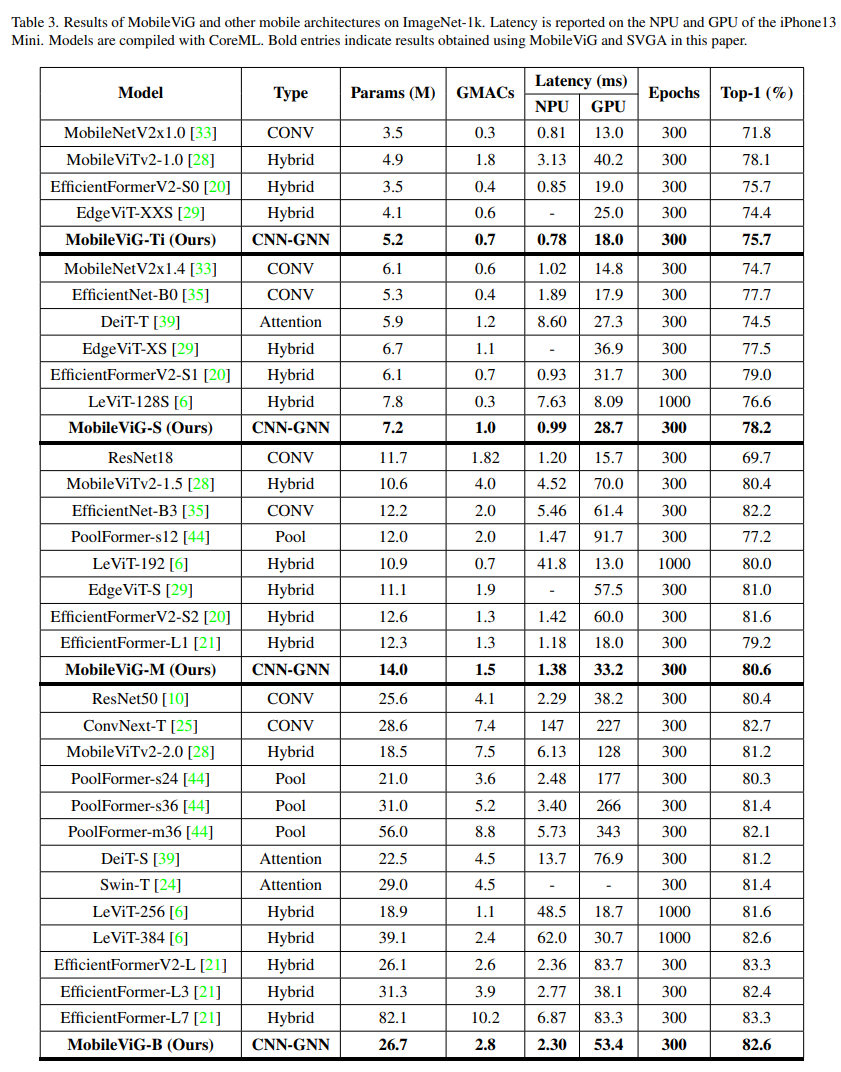
如表2所示,对于相似数量的参数,MobileViG在准确率和GPU延迟方面都优于Pyramid ViG[8]。例如,在参数少3.5 M的情况下,MobileViG-S与Pyramid ViG-Ti达到了相同的Top-1精度,同时速度提高了2.83倍。此外,在参数减少0.6 M的情况下,MobileViG-B在Top-1精度上比Pyramid ViG-S高出0.5%,同时速度提高2.08倍。
与表3中的移动模型相比,MobileViG在NPU延迟、GPU延迟或准确性方面始终优于所有模型。MobileViG-Ti比MobileNetv2更快,Top-1准确率高出3.9%。它还与EfficientFormerv2[20]在Top-1中匹配,同时在NPU和GPU延迟方面略有优势。MobileViG-S的NPU延迟比EfficientNet-B0[35]快近2倍,Top-1准确率比EfficientNet-B0高0.5%。与MobileViTv2-1.5[28]相比,MobileViG-M在NPU延迟上快了3倍,在GPU延迟上快了2倍,最高准确率提高了0.2%。此外,MobileViG-B比DeiT-S快6倍,并且能够在Top-1精度上击败DeiT-S和Swin-Tiny。
4.2、目标检测和实例分割
评估了MobileViG在目标检测和实例分割任务上的表现,进一步证明了SVGA的潜力。将MobileViG作为骨网络集成到Mask-RCNN框架[9]中,并使用MS COCO 2017数据集[22]进行实验。我们使用PyTorch 1.12[30]和Timm库[42]实现了backbone,并使用4块NVIDIA RTX A6000 GPU来训练我们的模型。我们从300轮的训练中使用预训练的ImageNet-1k权重初始化模型,使用初始学习率为2e-4的AdamW[26]优化器,并按照NextViT、EfficientFormer和EfficientFormerV2的过程,以标准分辨率(1333 X 800)训练模型12轮[19-21]。

如表4所示,在模型大小相似的情况下,MobileViG在对象检测和/或实例分割的参数或提高的平均精度(AP)方面优于ResNet、PoolFormer、EfficientFormer和PVT。中等尺寸的MobileViG-M模型在目标检测任务上的APbox为41.3,当IoU为50时APbox为62.8,当IoU为75时APbox为45.1。对于实例分割任务,MobileViG-M获得38.1 APmask, 50 IoU时获得60.1 APmask, 75 IoU时获得40.8 APmask。大尺寸MobileViG-B模型在目标检测任务上的APbox为42.0,IoU为50时为64.3,IoU为75时为46.0。MobileViG-B在实例分割任务上获得38.9 APmask, 50 IoU时获得61.4 APmask, 75 IoU时获得41.6 APmask。MobileViG在目标检测和实例分割方面的强大性能表明,MobileViG作为计算机视觉中不同任务的主干具有良好的泛化能力。
MobileViG的设计部分灵感来自Pyramid ViG[8]、EfficientFormer[21]和MetaFormer概念[44]的设计。在MobileViG中获得的结果表明,混合CNN- GNN架构是CNN、ViT和混合CNN-ViT设计的可行替代方案。混合CNN-GNN架构可以提供基于CNN的模型的速度以及ViT模型的精度,使其成为高精度移动架构设计的理想候选者。进一步探索用于移动计算机视觉任务的混合CNN-GNN架构可以改进MobileViG概念并引入新的最先进的架构。
5、结论
在这项工作中,我们提出了一种基于图的注意机制,稀疏视觉图注意(SVGA)和MobileViG,一种使用SVGA的有竞争力的移动视觉架构。与以前的方法不同,SVGA不需要重塑,并且允许在推理之前知道图结构。我们使用倒立残差块、最大相对图卷积和前馈网络层来创建MobileViG,这是一种混合CNN-GNN架构,在图像分类、目标检测和实例分割任务上取得了有竞争力的结果。MobileViG在准确性和延迟方面优于现有的ViG模型和许多现有的移动模型,包括MobileNetv2。未来对移动架构的研究可以进一步探索基于GNN的模型在资源受限设备上用于物联网应用的潜力


















 8061
8061

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











