




文章目录
摘要
论文链接:https://arxiv.org/pdf/2404.10518
我们推出了最新一代的MobileNets,称为MobileNetV4(MNv4),其特点是为移动设备提供普遍高效的架构设计。在核心部分,我们引入了通用倒置瓶颈(UIB)搜索块,这是一种统一且灵活的结构,融合了倒置瓶颈(IB)、ConvNext、前馈网络(FFN)以及新型Extra Depthwise(ExtraDW)变体。除了UIB之外,我们还推出了Mobile MQA,这是一种专为移动加速器设计的注意力块,可带来高达39%的速度提升。我们还引入了一种优化的神经架构搜索(NAS)配方,提高了MNv4搜索的有效性。UIB、Mobile MQA和精炼的NAS配方的集成,产生了一系列新的MNv4模型,这些模型在移动CPU、DSP、GPU以及像Apple Neural Engine和Google Pixel EdgeTPU这样的专用加速器上大多是帕累托最优的——这是在其他测试模型中找不到的特性。最后,为了进一步提高准确性,我们引入了一种新型的知识蒸馏技术。通过这种技术的增强,我们的MNv4-Hybrid-Large模型在ImageNet-1K上达到了87%的准确率,同时在Pixel 8 EdgeTPU上的运行时间仅为3.8毫秒。
代码链接:https://github.com/tensorflow/models/blob/master/official/vision/modeling/backbones/mobilenet.py
1、引言
高效的设备端神经网络不仅能实现快速、实时和交互式的体验,还能避免将私人数据通过公共互联网进行传输。然而,移动设备的计算约束给在准确性和效率之间取得平衡带来了重大挑战。为此,我们引入了UIB和Mobile MQA这两个创新性的构建块,并通过精炼的NAS配置将它们集成在一起,创建了一系列在移动设备上普遍最优的模型。此外,我们还提出了一种蒸馏技术,以进一步提高准确性。
我们的通用倒置瓶颈(UIB)块通过融入两个可选的深度卷积操作,改进了倒置瓶颈块[36]。尽管其设计简单,但UIB统一了突出的微架构——逆置瓶颈(IB)、ConvNext[32]和前馈网络(FFN)[12],并引入了Extra Depthwise(ExtraDW)IB块。UIB在空间和通道混合方面提供了灵活性,可以选择扩展感受野,并提高计算效率。
我们的优化Mobile MQA块相对于多头注意力[44]在移动加速器上实现了超过39%的推理加速。
我们的两阶段NAS方法通过分离粗粒度搜索和细粒度搜索,显著提高了搜索效率,并有助于创建比先前最先进的模型[41]大得多的模型。此外,通过纳入一个离线的蒸馏数据集,我们减少了NAS奖励测量中的噪声,从而提高了模型质量。
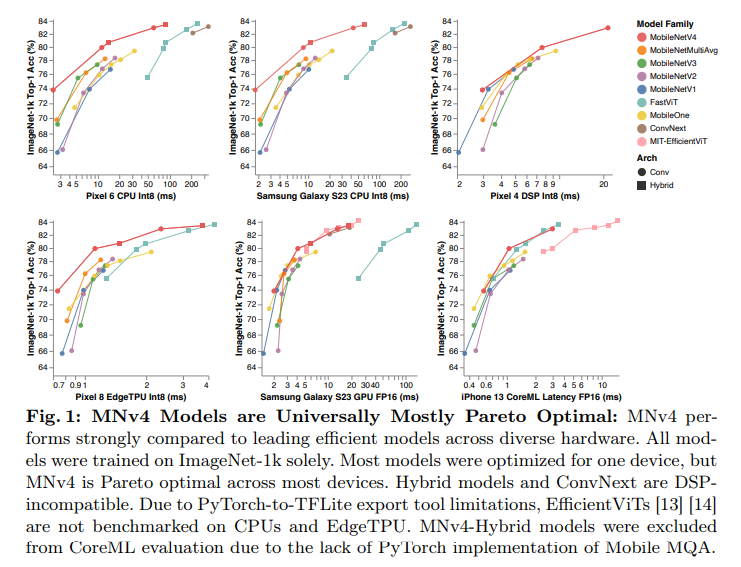
通过集成UIB、MQA和改进的NAS配置,我们推出了MNv4模型套件,它在包括CPU、DSP、GPU和专用加速器在内的多种硬件平台上实现了大多数帕累托最优性能。我们的模型系列涵盖了一个广泛的计算谱系,从极其紧凑的MNv4-Conv-S设计开始,该设计具有3.8M参数和0.2G MACs,在Pixel 6 CPU上以2.4毫秒的速度实现了73.8%的ImageNet-1K top-1准确率,一直到MNv4-Hybrid-L高端变体,它建立了移动模型准确性的新基准,在Pixel 8 EdgeTPU上以3.8毫秒的速度运行。我们新颖的蒸馏配方混合了具有不同增强的数据集,并添加了平衡的同类数据,增强了泛化能力,并进一步提高了准确性。通过这种技术,MNv4-Hybrid-L在ImageNet-1K上实现了令人印象深刻的87% top-1准确率:与其教师模型相比,仅下降了0.5%,尽管其MACs减少了39倍。
2、相关工作
在准确性和效率方面优化模型是一个经过深入研究的问题。
移动卷积网络:关键工作包括MobileNetV1[20],它使用深度可分离卷积来提高效率;MobileNetV2[36]引入了线性瓶颈和倒置残差;MnasNet[40]在瓶颈中集成了轻量级注意力;MobileOne[43]在推理时添加并重新参数化倒置瓶颈中的线性分支。
高效混合网络:这一研究方向结合了卷积和注意力机制。MobileViT[33]通过全局注意力块将CNN的优势与ViT[12]相结合。MobileFormer[6]并行化了一个MobileNet和一个Transformer,并在它们之间建立了一个双向桥以进行特征融合。FastViT[42]在最后阶段添加了注意力,并在早期阶段使用大卷积核作为自注意力的替代。
高效注意力:研究集中在提高MHSA[44]的效率上。EfficientViT[13]和MobileViTv2[34]引入了具有线性复杂度的自注意力近似,对准确性影响较小。EfficientFormerV2[27]通过下采样Q、K、V来提高效率,而CMT[15]和NextViT[26]仅下采样K和V。
硬件感知的神经架构搜索(NAS):另一种常见的技术是使用硬件感知的神经架构搜索(NAS)来自动化模型设计过程。NetAdapt[49]使用经验延迟表来优化模型在目标延迟约束下的准确性。MnasNet[40]也使用延迟表,但应用强化学习来进行硬件感知的NAS。FBNet[47]通过可微分的NAS加速多任务硬件感知搜索。MobileNetV3[18]通过结合硬件感知的NAS、NetAdapt算法和架构进步,针对手机CPU进行调整。MobileNet MultiHardware[8]优化单个模型以适应多个硬件目标。Once-for-all[5]为了效率而分离训练和搜索。
3、硬件无关的帕累托效率
Roofline模型:要使模型具有普遍的效率,它必须在具有截然不同瓶颈的硬件目标上表现良好,这些瓶颈在很大程度上限制了模型的性能。这些瓶颈主要由硬件的峰值计算吞吐量和峰值内存带宽决定。
为此,我们使用Roofline模型[46],该模型可以估算给定工作负载的性能,并预测它是否受到内存瓶颈或计算瓶颈的限制。简而言之,它抽象掉了特定的硬件细节,只考虑工作负载的操作强度( L a y e r M A C s i / ( W e i g h t B y t e s i + A c t i v a t i o n B y t e s i ) LayerMACs_{i} / (WeightBytes_{i} + ActivationBytes_{i}) LayerMACsi/(WeightBytesi+ActivationBytesi))与硬件处理器和内存系统的理论限制之间的关系。内存和计算操作大致是并行发生的,因此两者中较慢的一个大致决定了延迟瓶颈。为了将Roofline模型应用于具有层索引 i 的神经网络,我们可以按如下方式计算模型推理延迟 ModelTime:
ModelTime = ∑ i max ( MACTime i , MemTime i ) MACTime i = LayerMACs i PeakMACs , MemTime i = WeightBytes i + ActivationBytes i PeakMemBW \begin{array}{l} \text { ModelTime }=\sum_{i} \max \left(\text { MACTime }_{i}, \text { MemTime }_{i}\right) \\ \text { MACTime }_{i}=\frac{\text { LayerMACs }_{i}}{\text { PeakMACs }}, \quad \text { MemTime }_{i}=\frac{\text { WeightBytes }_{i}+\text { ActivationBytes }_{i}}{\text { PeakMemBW }} \\ \end{array} ModelTime =∑imax( MACTime i, MemTime i) MACTime i= PeakMACs LayerMACs i,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 192
192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











