







摘要。我们介绍了最新一代 MobileNets,即 MobileNetV4 (MNv4),它具有适用于移动设备的通用高效架构设计。在其核心,我们引入了通用倒置瓶颈 (UIB) 搜索块,这是一种统一而灵活的结构,融合了倒置瓶颈 (IB)、ConvNext、前馈网络 (FFN) 和新颖的额外深度 (ExtraDW) 变体。除了 UIB,我们还介绍了 Mobile MQA,这是一种专为移动加速器量身定制的注意力块,可显着提高 39% 的加速。还引入了一种优化的神经架构搜索 (NAS) 配方,可提高 MNv4 搜索效率。UIB、Mobile MQA 和改进的 NAS 配方的集成产生了一套新的 MNv4 模型,这些模型在移动 CPU、DSP、GPU 以及 Apple Neural Engine 和 Google Pixel EdgeTPU 等专用加速器上大多是帕累托最优的 - 这是在任何其他测试模型中都找不到的特性。最后,为了进一步提高准确性,我们引入了一种新颖的蒸馏技术。通过这种技术增强,我们的 MNv4-Hybrid-Large 模型可提供 87% 的 ImageNet-1K 准确率,Pixel 8 EdgeTPU 运行时间仅为 3.8 毫秒。
1 简介
高效的设备内置神经网络不仅可以实现快速、实时和交互式体验,还可以避免通过公共互联网传输私人数据。 然而,移动设备的计算限制带来了平衡准确性和效率的重大挑战。为此,我们引入了 UIB 和 Mobile MQA,这两个创新的构建块通过精炼的 NAS 配方集成在一起,以创建一系列普遍的帕累托最优移动模型。 此外,我们还提出了一种进一步提高准确性的蒸馏技术。
我们的通用倒置瓶颈 (UIB) 块通过合并两个可选的深度卷积 [19] 改进了倒置瓶颈块 [36]。 尽管 UIB 很简单,但它统一了著名的微架构 - 倒置瓶颈 (IB)、ConvNext [32] 和 FFN [12] - 并引入了额外深度 (ExtraDW) IB 块。UIB 在空间和通道混合方面提供了灵活性、扩展感受野的选项以及增强的计算效率。
我们优化的移动 MQA 模块相对于多头注意力机制 (Multi-Head Attention) 在移动加速器上实现了超过 39% 的推理加速 [44]。
我们的两阶段 NAS 方法将粗粒度搜索和细粒度搜索分开,大大提高了搜索效率,并有助于创建比以前最先进的模型大得多的模型 [41]。此外,结合离线蒸馏数据集可减少 NAS 奖励测量中的噪音,从而提高模型质量。
通过集成 UIB、MQA 和改进的 NAS 配方,我们推出了 MNv4 模型套件,在包括 CPU、DSP、GPU 和专用加速器在内的各种硬件平台上实现了大部分帕累托最优性能。我们的模型系列涵盖了从极其紧凑的 MNv4-Conv-S 设计(具有 3.8M 个参数和 0.2G MAC,在 Pixel 6 CPU 上 2.4 毫秒内实现 73.8% 的 Top-1 ImageNet-1K 准确率)到 MNv4-Hybrid-L 高端变体(为移动模型准确率建立了新的参考),在 Pixel 8 EdgeTPU 上的运行时间为 3.8 毫秒)。我们新颖的蒸馏配方将数据集与不同的增强相结合,并添加平衡的类内数据,从而增强了泛化能力并进一步提高了准确率。 通过这种技术,MNv4-Hybrid-L 在 ImageNet-1K 上实现了令人印象深刻的 87% top-1 准确率:尽管 MAC 少了 39 倍,但与其老师相比仅下降了 0.5%。
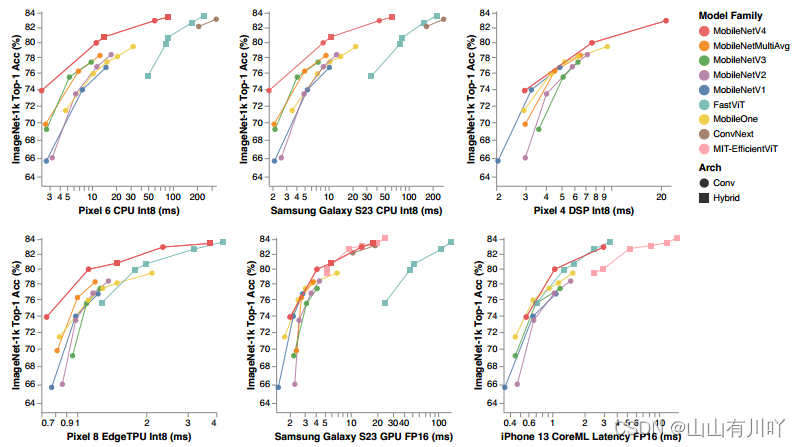
图 1:MNv4 模型普遍符合帕累托最优:MNv4 与领先的高效模型相比,在不同硬件上的表现都十分出色。所有模型均在 ImageNet-1k 上进行训练。大多数模型都针对一种设备进行了优化,但 MNv4 在大多数设备上都符合帕累托最优。混合模型和 ConvNext 与 DSP 兼容。由于 PyTorch-to-TFLite 导出工具的限制,EfficientViTs [13] [14] 未在 CPU 和 EdgeTPU 上进行基准测试。由于缺乏 PyTorch 实现的 Mobile MQA,MNv4-Hybrid 模型被排除在 CoreML 评估之外。
2 相关工作
优化模型以提高准确性和效率是一个研究得很好的问题。
移动卷积网络:关键工作包括 MobileNetV1 [20],它具有深度可分离卷积以提高效率,MobileNetV2 [36] 引入了线性瓶颈和倒置残差,MnasNet [40] 在瓶颈中集成了轻量级注意力,MobileOne [43] 在推理时在倒置瓶颈中添加和重新参数化线性分支。
高效混合网络:该研究方向集成了卷积和注意力机制。MobileViT [33] 通过全局注意力模块将 CNN 的优势与 ViT [12] 相结合。MobileFormer [6] 将 MobileNet 和 Transformer 并行化,并在两者之间建立双向桥接以进行特征融合。FastViT [42] 在最后阶段增加了注意力,并在早期阶段使用大型卷积核代替自注意力。
高效注意力:研究重点是提高 MHSA [44] 的效率。EfficientViT [13] 和 MobileViTv2 [34] 引入了自注意力近似,以降低线性复杂度,同时对准确性的影响很小。EfficientFormerV2 [27] 对 Q、K、V 进行下采样以提高效率,而 CMT [15] 和 NextViT [26] 仅对 K 和 V 进行下采样。
硬件感知神经架构搜索 (NAS):另一种常见技术是使用硬件感知神经架构搜索 (NAS) 自动化模型设计过程。NetAdapt [49] 使用经验延迟表在目标延迟约束下优化模型的准确性。 MnasNet [40] 也使用延迟表,但应用强化学习来实现硬件感知 NAS。FBNet [47] 通过可微分 NAS 加速多任务硬件感知搜索。MobileNetV3 [18] 通过结合硬件感知 NAS、NetAdapt 算法和架构改进,针对手机 CPU 进行了调整。MobileNet MultiHardware [8] 针对多个硬件目标优化单个模型。Once-for-all [5] 将训练和搜索分开以提高效率。
3 硬件独立的帕累托效率
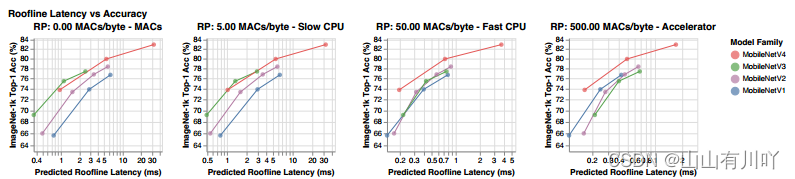
图 2:脊点和延迟/准确度权衡:脊点测量屋顶线性能模型中内存带宽 MAC 之间的关系。如果内存带宽不变,则高计算硬件(加速器)的脊点高于低计算硬件(CPU)。MobileNetV4 从 0 到 500 MAC/字
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2220
2220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









