






摘要
论文提出的模型主要基于对传统DenseNet架构的改进和复兴,通过一系列创新设计,旨在提升模型性能并优化其计算效率,提出了RDNet模型。该模型的主要特点和改进点:
1. 强调并优化连接操作(Concatenation)
论文首先强调了DenseNet中连接操作(Concatenation)的重要性,并通过广泛的实验验证了连接操作在性能上能够超越传统的加法快捷连接(Additive Shortcut)。这一发现促使研究者们重新审视并优化DenseNet的连接机制。
2. 扩大中间通道维度
为了进一步提升模型性能,论文提出通过调整扩展比(Expansion Ratio, ER)来增大中间张量(Tensor)的尺寸,使其超过输入维度。传统方法中,ER主要用于调整输入和输出维度,但在这篇论文中,ER被重新设计为与输入维度成比例,即ER与增长率(Growth Rate, GR)解耦。这种设计使得在非线性处理之前能够更充分地丰富特征,同时为了管理由此产生的计算需求,将GR减半(例如从120减少到60),从而在不影响准确性的前提下控制计算量。
3. 记忆高效的DenseNet设计
为了优化DenseNet的架构设计,论文采用了更加内存高效的设计策略,通过丢弃无效组件并增强架构和块设计,同时保持DenseNet的核心连接机制不变。这种设计使得模型在保持高性能的同时,也减少了内存占用,提升了处理大规模数据集的能力。

本文使用RDNet的Block改进YoloV8,改进后的网络涨点明显。即插即用,欢迎大家使用!
文章结构:
文章目录
论文:《DenseNets再探索:超越ResNets和ViTs的范式转变》
https://arxiv.org/pdf/2403.19588
本文重新探讨了密集连接的卷积网络(DenseNets),并揭示了其在当前主流的ResNet风格架构之上的被低估的有效性。我们认为,DenseNets的潜力被忽视的原因在于未得到充分研究的训练方法以及传统设计元素未能完全展现其能力。我们的初步研究表明,通过拼接实现的密集连接非常强大,证明了DenseNets可以通过复兴来与现代架构竞争。我们系统地改进了次优组件——包括架构调整、块重新设计以及改进的训练策略,旨在拓宽DenseNets并提升内存效率,同时保持拼接的快捷连接。我们的模型采用简单的架构元素,最终超越了Swin Transformer、ConvNeXt和DeiT-III等残差学习谱系中的关键架构。此外,我们的模型在ImageNet-1K数据集上展示了接近最先进的性能,与最新模型在下游任务(如ADE20k语义分割和COCO目标检测/实例分割)上的表现相媲美。最后,我们提供了实证分析,揭示了拼接相较于加法快捷连接的优点,引导了对DenseNet风格设计的重新青睐。我们的代码可在https://github.com/naver-ai/rdnet获取。
1、引言
“ImageNet时刻”由卷积神经网络(ConvNets)的兴起而引发,这一里程碑始于AlexNet[38]的诞生。随后,VGG[62]和GoogleNet[65]进一步凸显了在ConvNets中堆叠多个卷积层的好处。在同一时期,具有划时代意义的架构ResNet[27]及其家族[28,87]脱颖而出,引入了突破性的概念——加法跳跃连接(也称为加法捷径或恒等映射[28]),这使得能够堆叠多达1,000层的网络。残差学习的引入是一个重大变革,它通过确保来自恒等映射导数的输入梯度始终保持为1,从而缓解了梯度消失问题。这一创新催生了一系列后续的重要ConvNets,包括EfficientNet[67]和ConvNeXt[48];同时,也为Transformer[75]、视觉Transformer(ViTs)[19]和分层ViTs[47]等下一代架构的发展铺平了道路,这进一步凸显了加法捷径的持久影响力。
在残差学习主导的这一时期早期,密集连接的卷积网络(DenseNets[32])引入了一种新颖的方法:通过特征拼接而不是加法捷径来维持捷径连接。这导致了特征重用[32]的概念,使得模型更加紧凑,并通过将显式监督传播到早期层来减少过拟合。DenseNets在诸如语义分割[36]等任务中展示了高效性和优越的性能。然而,DenseNet之后的架构设计演变似乎挑战了ResNets的主导地位,但其受欢迎程度却有所下降,被加法捷径的优势所掩盖。
DenseNets的后续研究[40,76,79]重新探索了DenseNets,以推进其设计理念,但再次难以与更主流的架构趋势抗衡。我们认为,DenseNets的潜力仍然没有得到充分发掘,原因是其可访问性较低,逐渐被过时的训练方法和低容量组件的限制所阻碍;它们难以跟上现代架构的发展步伐,这些现代架构受益于多年的进化式改进。此外,我们推测DenseNets需要进行全面改革,因为其适用性有限,并且随着特征维度的增加,内存挑战也变得愈发严峻。尽管作者们已经解决了内存方面的问题[32,53],但这些问题仍然限制着架构的扩展,特别是宽度扩展。尽管存在这些缺点,但我们推测DenseNets的核心设计理念仍然非常强大。
有鉴于此,本文通过强调拼接操作被低估的有效性来重振DenseNets。通过在不同设置下对超过 10 , 000 10,000 10,000个随机网络进行全面试点研究训练,我们验证了拼接操作可以超越加法捷径的断言。随后,我们对DenseNet进行了现代化改造,采用了一种更节省内存的设计来拓宽网络,同时摒弃了无效组件并增强了架构和块设计,同时保留了通过拼接实现的密集连接的本质。我们还采用了与DenseNets协同工作的当代策略。我们的方法最终在ImageNet-1K[59]上的性能权衡中超越了强大的现代架构[21, 25, 42, 45, 57, 97]以及一些里程碑式的模型,如Swin Transformer[47]、ConvNeXt[48]和DeiT-III[71]。我们的模型在ADE20K语义分割和COCO对象检测/实例分割等下游任务中表现出了具有竞争力的性能。值得注意的是,随着输入尺寸的增加,我们的模型并未出现速度变慢或性能下降的情况。最终,我们的实证分析揭示了拼接操作的独特优势。
2、相关工作
密集连接神经网络(DenseNets)[32]在卷积神经网络(ConvNets)中开创了超越加法捷径的密集连接,以参数效率和增强的精度为特点。基于这一框架,提出了一些变体。PeleeNet[79]成功地对DenseNet进行了修改,以实现实时推理能力。VovNet[40]摒弃了DenseNets的密集特征重用,转而采用更稀疏的一次性聚合,旨在实现实时目标检测。CSPNet[76]通过省略特征并在跨阶段层中重新拼接它们,减少了计算需求,同时几乎不影响精度。DenseNets在密集预测任务中的有效性也得到了进一步强调,例如,Jegou等人[36]展示了DenseNets在语义分割中的有效性。MDUNet[94]利用密集连接来增强生物医学图像分割。DCCT[52]将密集连接集成到Transformer架构[75]中,以促进图像去雾。对于视频快照压缩成像,EfficientSCI[78]也利用了密集连接的优势。Wang等人[82]利用密集连接来改善小目标的检测。
我们认为,这些参考文献证明了基于DenseNet的设计的潜力,但据我们所知,最近没有使用密集连接原则来挑战ImageNet基准的研究。
现代架构。DeiT[69]和AugReg[64]展示了现代化的训练策略[5,67,84]可以替代大量训练数据用于ViT[19]的训练。更接近ConvNets的后代分层ViT[18,47,80,81,88,89]表明,局部性在提供有效性的同时也提高了计算效率。随后,混合架构[14,25,43,74,97]明确地为局部性配备了卷积。具有讽刺意味的是,新来者越来越接近ConvNets,旨在不放弃简单卷积已被证实的有效性,尽管它们使用了Transformer。
ConvNets[6,27,56,67]最初因其强大的能力和效率而占据主导地位。有趣的是,ViT方面的进步也促进了ConvNets的现代化;许多最近的架构[23,70,73,90]受到ViT设计的启发,但配备了局部性,展示了卷积的持续高竞争力。像RepLKNet[17]和SLaK[46]这样的后继者采用了基于前辈遗产的大规模核卷积来模拟注意力的全局性[19],提供了学习增强的全局表示的能力。RevCol[7]引入了一个新概念,即通过多个列反复混合多级特征。InceptionNeXt[91]在ConvNeXt内部采用了Inception模块[65],以展示改进的性能。HorNet[57]和MogaNet[42]分别通过采用多个门控卷积和多级特征,展示了显著的性能,同时也利用了多尺度特征来实现全局性。
那些架构在ImageNet和密集预测任务上也超越了ViT,但使用加法捷径和架构复杂性等相似性继续限制着架构的多样性和创新。此外,网络现代化方法[5,48,79,84]成功地重新审视了现有架构,但并未在基线之上使用加法捷径来处理问题。本工作遵循一般方向,但确保我们从不同的基线开始,认识到现有路线图有效性的不确定性。
3、方法论:复兴DenseNets
本节首先提出我们的猜想,即DenseNet可能并不落后于现代架构,并通过实证修改后的DenseNet架构来证明这一点。基于我们的猜想和初步实验,我们提出了我们的方法论,该方法包含了一些现代化元素来复兴DenseNet。
3.1、初步研究
**动机。**ResNets [27] 因其在第 l l l 层的简洁公式而广为人知: X l + 1 = X l + f ( X l W ) \mathbf{X}_{l+1}=\mathbf{X}_{l}+f(\mathbf{X}_{l} \mathbf{W}) Xl+1=Xl+f(XlW),其中 X l \mathbf{X}_{l} Xl 是输入, W \mathbf{W} W 是权重。一个关键元素是残差连接(即加法捷径,+),它促进了模块化架构设计,这在Swin [47]、ConvNeXt [48] 和ViT [19] 中得到了验证。而DenseNets [32] 遵循的公式是: X l + 1 = [ X l , f ( X l W ) ] \mathbf{X}_{l+1}=[\mathbf{X}_{l}, f(\mathbf{X}_{l} \mathbf{W})] Xl+1=[Xl,f(XlW)],基于通过拼接实现的密集连接,具有显式的参数效率。然而,由于内存问题,这种公式应该限制特征维度,使得在宽度上进行扩展变得具有挑战性。
DenseNets [32] 最初在性能上超越了ResNets [27],但未能实现完全的范式转变,由于适用性问题而失去了初期的势头。特别是,尽管在内存方面进行了努力 [40,53],但DenseNets的宽度扩展仍然存在问题,像DenseNet-161/-233这样的更宽模型会消耗更多内存 [32]。不过,受先前工作 [5,48,84] 的启发,并受到在语义分割 [94] 等密集预测任务中取得成功的鼓舞,我们相信DenseNets 将超越流行的架构,并值得进一步探索其潜力:1) 特征拼接具有强大的能力;2) 通过战略设计可以缓解DenseNets中的上述问题。
我们的猜想。拼接捷径是增加秩的有效方式。考虑层输出 f ( X W ) f(\mathbf{X W}) f(XW),其中权重 W ∈ R d in × d out \mathbf{W} \in \mathbb{R}^{d_{\text{in}} \times d_{\text{out}}} W∈Rdin×dout,输入 X ∈ R N × d in \mathbf{X} \in \mathbb{R}^{N \times d_{\text{in}}} X∈RN×din,以及一个非线性函数 f f f,我们假设实例数量 N ≫ d in N \gg d_{\text{in}} N≫din。当关注 f f f 的矩阵秩 rank ( f ( X W ) ) \operatorname{rank}(f(\mathbf{X W})) rank(f(XW)) 时,由于非线性,当 d in d_{\text{in}} din 不是那么小时,它通常会接近 d out d_{\text{out}} dout [24]。文献 [10,22,24] 表明,当 d out > d in d_{\text{out}} > d_{\text{in}} dout>din 时,层 W \mathbf{W} W 提供了更大的表示能力。有趣的是,DenseNets 享有类似的特性,因为我们可以将 W \mathbf{W} W 分解为 [ W P , I ] \left[\mathbf{W}_{\mathbf{P}}, \mathbf{I}\right] [WP,I],其中 W P \mathbf{W}_{\mathbf{P}} WP 和 I \mathbf{I} I 分别表示构建块和拼接中的权重。我们进一步认为,像这样频繁地增加秩会更有益。 W P \mathbf{W}_{\mathbf{P}} WP 的输出维度被称为增长率。
战略设计缓解了内存问题。考虑堆叠层的输出 X W 1 f ( W 2 ) \mathbf{X} \mathbf{W}_{\mathbf{1}} f\left(\mathbf{W}_{\mathbf{2}}\right) XW1f(W2),其中权重 W 1 ∈ R d in × d r , W 2 ∈ R d r × d out \mathbf{W}_{\mathbf{1}} \in \mathbb{R}^{d_{\text{in}} \times d_{r}}, \mathbf{W}_{\mathbf{2}} \in \mathbb{R}^{d_{r} \times d_{\text{out}}} W1∈Rdin×dr,W2∈Rdr×dout,且 d r < d in , d out d_{r} < d_{\text{in}}, d_{\text{out}} dr<din,dout,以及 W 2 \mathbf{W}_{\mathbf{2}} W2 之后的非线性函数 f f f。同样,当 d r d_{r} dr 不是那么小时,秩可能得以保持。这表明,使用像 W 1 \mathbf{W}_{1} W1 这样的中间维度减少器(即转换层)可能不会对秩产生显著影响。我们认为频繁地应用这种方法可以有效地解决内存问题。
试点研究。我们通过在Tiny-ImageNet数据集[39]上采样超过15,000个网络来进行试点研究,以验证我们的猜想。这些网络的捷径要么是像ResNets[27]那样的加法捷径,要么是DenseNets[32]中的拼接捷径。我们仔细控制了实验的计算成本,并涉及了多种训练设置,以确保比较的平衡性和全面性。有趣的是,拼接捷径在所有情况下都优于加法捷径,Tiny-ImageNet的平均准确率为54.3±3.7(拼接)vs. 52.7±4.2(加法),从而从经验上支持了我们的主张。详细的结果和设置见第5.1节。
3.2、复兴DenseNets
我们在保持DenseNets核心原则(通过拼接)的同时,重新审视了DenseNets。我们的策略探索了拓宽DenseNets的方法,并确定了有效的元素。表1详细列出了对性能提升有贡献的元素。
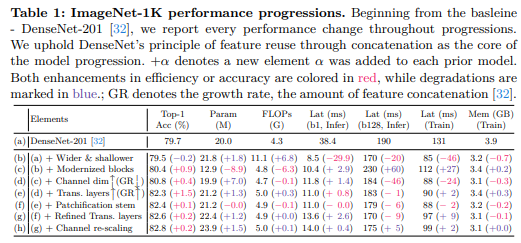
基线。正如重新审视ResNets[5,84]的系列研究所示,精细的训练方案带来了显著的改进。同样地,我们使用现代训练方案训练DenseNet-201,将其作为我们的基线。遵循广泛研究的设置[47, 48, 68, 69, 84],我们包括了标签平滑[66]、RandAugment[13]、随机擦除[16, 95]、Mixup[93]、Cutmix[92]和随机深度[33];我们使用AdamW优化器[50],带有余弦学习率调度[49]和线性预热[20],并采用流行的长周期训练设置(300个周期)。
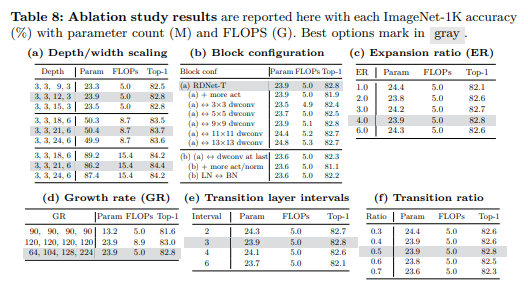
更宽更浅的设计。DenseNets最初提出了极深的架构(例如DenseNet-265[32]),这有效地展示了其可扩展性。我们认为,在资源受限的情况下,很难同时通过提高增长率(GR)来增强特征维度并增加深度。先前的工作[24,40,48,56,79]设计了更浅的网络以实现效率,特别是延迟方面。受此启发,我们相应地对DenseNet进行了修改,使其成为一个更优的基线;通过增加GR来拓宽网络,同时减少其深度。具体来说,我们通过将GR从32大幅增加到120来实现这一点;我们调整了每个阶段的块数,从(6,12,48,32)减少到更小的(3,3,12,3),以进行深度调整。我们没有过度减少深度,以保持最低限度的非线性。表1(b)显示,这种策略性的修改带来了显著的延迟和内存效率——训练速度和内存分别减少了约35%和18%。GFLOPs的大幅增加到11.1将通过后续的元素进行调整。进一步的研究支持了我们的决定——在平衡深度的同时优先考虑宽度(见表8a)。
改进的特征混合器。我们采用了基础块[48]作为我们的特征混合器块,该块已被广泛研究以证明其有效性。在使用它之前,我们应该针对我们的情况重新评估这些研究,因为1) DenseNets没有使用加法捷径,2) 构建块最初被设计为连续降维。我们发现使用以下设置仍然有效:1) 使用层归一化(LN)[2]代替批归一化(BN)[35];2) 后激活;3) 深度可分离卷积[31];4) 减少归一化和激活操作;5) 卷积核大小为7。我们块的一个独特之处在于输出通道(GR)小于输入通道(C);混合特征最终是更压缩的特征。如表1©所示,我们的设计在大幅提高准确率( + 0.9 % p +0.9 \%\mathrm{p} +0.9%p)的同时,仅略微增加了计算成本。我们在此处为我们的研究补充了因子分析(见表8b)。
更大的中间通道维度。对于深度可分离卷积来说,一个大的输入维度至关重要[60]。通过巧妙调整先前工作中倒置瓶颈的扩展比(ER)[24,48,60,67,68],成功地实现了显著的性能提升,这是通过在块内将中间张量的大小扩大到超出输入维度来实现的(例如,ER被调整为6)。
DenseNets同样采用了ER(扩展比)的概念;然而,它们独特地将ER应用于增长率(GR)(例如, E R = 4 × G R \mathrm{ER}=4 \times \mathrm{GR} ER=4×GR)而不是输入维度,以减少输入和输出维度。我们认为,这损害了通过非线性编码特征的能力[24]。因此,我们通过将ER与输入维度成比例(即,将ER与GR解耦)来重新设计这种方法。这一变化导致了由于中间维度增大而增加的计算需求;因此,将GR减半(例如,从120减少到60)可以在不损害准确性的情况下管理这些需求。即,我们在应用非线性之前丰富特征,并进一步压缩通道以控制计算成本。之后,我们实现了更快的训练速度(提升 21 % 21\% 21%)和表1中所示的 0.4 % p 0.4 \%\mathrm{p} 0.4%p的准确率提升。此外,我们还进行了因子分析,以确定减少ER并增加GR是否更可取,或者相反,增加ER并减少GR是否更优;表8c显示,使用GR为4最终产生了最优结果。
此外,我们注意到与它们的浮点运算次数(FLOPs)相比,这些模型的参数数量较少。我们通过在不同阶段引入可变增长率(GR)(例如, 64 , 104 , 128 , 192 64, 104, 128, 192 64,104,128,192)而不是统一的GR来解决这个问题。我们在表8d中的进一步研究表明,统一的增长率(GR)会损害准确性和效率。最后,表1(e)显示我们的设计在显著提高准确性的同时,并没有大幅增加计算成本。
块化主干:最近的研究揭示了将图像块作为主干中的输入的有效性[48,57,70]。我们使用相同的设置,即块大小为4,步长为4作为块化(后跟层归一化LN[2])。我们的实验结果表明,采用块化可以在不损失精度的情况下显著提高计算速度(见表1(f))。
优化过渡层:过渡层的另一个作用是降采样,并且采用了额外的平均池化来进行降采样。我们优化了过渡层,移除了平均池化,并通过调整卷积核大小和步长来替换卷积(同时也用LN替换了BN)。因此,我们的过渡层扮演了两个额外的角色:1)如上所述的降维;2)降采样。在每个阶段之后放置过渡层可以实现 + 0.2 % p +0.2 \%\mathrm{p} +0.2%p的增益,几乎不影响效率(见表1(g))。对于降维比,我们重新评估了之前在[32]中探索的影响;表8f再次证实了0.5是最优的;更高的过渡比会降低精度。
通道重缩放:我们研究了由于连接特征的多样方差是否需要进行通道重缩放。我们检查了我们提出的重缩放方法,该方法通过合并通道层缩放[69]和有效的压缩激励网络[41]具有类似的公式。表1(h)表明,尽管效率略有下降,但它实现了 + 0.2 % p +0.2 \%\mathrm{p} +0.2%p的轻微提升。
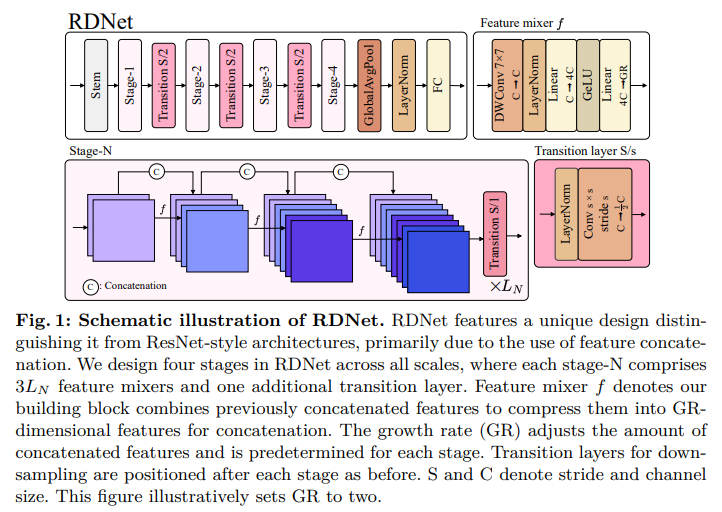
3.3 复兴DenseNet(RDNet)
我们最终介绍了复兴DenseNet(简称RDNet),如图1所示。我们的最终模型在精度和效率上都得到了提升,特别是速度显著提高(见表1(h)与表1(a)的比较)。我们构建了RDNet模型家族,与广泛采用的规模[27,47,48]保持一致。我们的模型独特地包括了增长率—— G R = ( G R 1 , G R 2 , G R 3 , G R 4 ) \mathrm{GR}=\left(GR_{1}, GR_{2}, GR_{3}, GR_{4}\right) GR=(GR1,GR2,GR3,GR4),以及每个阶段中混合块的数量—— B = ( B 1 , B 2 , B 3 , B 4 ) \mathrm{B}=\left(B_{1}, B_{2}, B_{3}, B_{4}\right) B=(B1,B2,B3,B4),其中我们在每个阶段分配了三个块,即 B n = 3 L n B_{n}=3L_{n} Bn=3Ln。我们总结了以下配置:
- RDNet-T: G R = ( 64 , 104 , 128 , 224 ) \mathrm{GR}=(64,104,128,224) GR=(64,104,128,224), B = ( 3 , 3 , 12 , 3 ) \mathrm{B}=(3,3,12,3) B=(3,3,12,3)
- RDNet-S: G R = ( 64 , 128 , 128 , 240 ) \mathrm{GR}=(64,128,128,240) GR=(64,128,128,240), B = ( 3 , 3 , 21 , 6 ) \mathrm{B}=(3,3,21,6) B=(3,3,21,6)
- RDNet-B: G R = ( 96 , 128 , 168 , 336 ) \mathrm{GR}=(96,128,168,336) GR=(96,128,168,336), B = ( 3 , 3 , 21 , 6 ) \mathrm{B}=(3,3,21,6) B=(3,3,21,6)
- RDNet-L:
G
R
=
(
128
,
192
,
256
,
360
)
\mathrm{GR}=(128,192,256,360)
GR=(128,192,256,360),
B
=
(
3
,
3
,
24
,
6
)
\mathrm{B}=(3,3,24,6)
B=(3,3,24,6)
4、实验
4.1、图像分类
我们在ImageNet-1K数据集[59]上评估了我们的模型家族。我们的模型训练遵循Swin Transformer[47]和ConvNeXt[48]的训练设置,以确保公平比较,并非旨在微调这些设置。模型使用AdamW优化器[50]进行训练,批量大小为512,初始学习率为
1
e
−
4
1\mathrm{e}-4
1e−4,训练周期为300个周期。如前所述,在我们的基线(\S 3.2)中,我们采用了与ConvNeXt相同的数据增强/正则化技术;在训练过程中未使用指数移动平均(EMA)。训练配方的详细信息见附录。我们遵循标准的评估协议[27, 47, 48]。
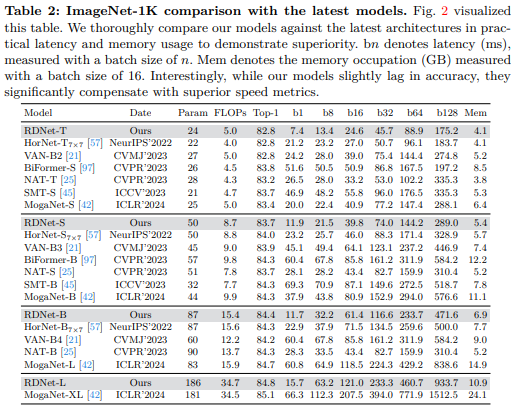
我们的优越性首先与当前表现最佳的架构[21,25,45,57,97]进行了比较。我们在图2中可视化了权衡图,并在表2中详细列出了具有不同计算成本的准确率。与最先进的模型相比,我们的结果非常具有竞争力。表2显示,虽然我们的模型在准确率上略有落后,但它们在速度指标上显著优于其他模型。例如,RDNet-S可以与SMT-S或MogaNet-S等其他更轻量级的模型相媲美。值得注意的是,我们的模型不仅达到了预期的低内存使用量,还进一步提高了效率。
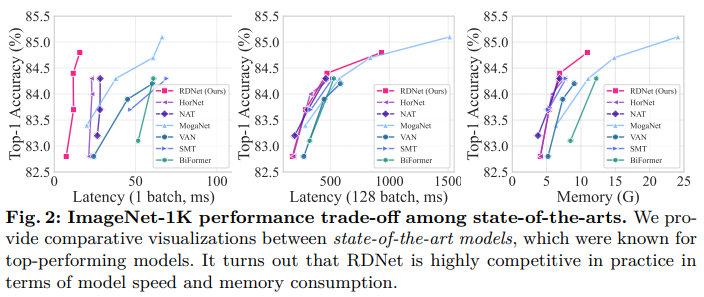
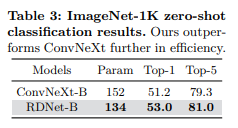
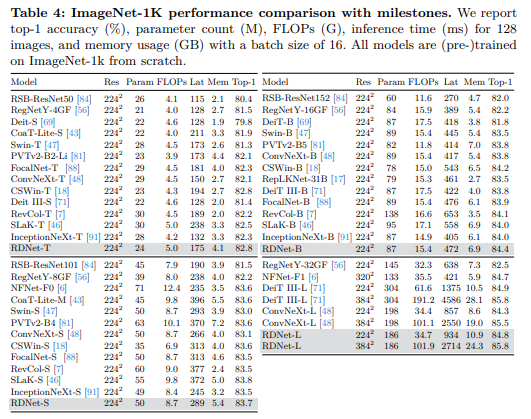
我们还在表4中进一步展示了与流行模型的比较。我们的模型以高精度、适中的内存使用量和更快的速度超越了竞争对手。我们还在图3中可视化了权衡关系,其中RDNet即使在与里程碑式架构并列比较时也表现出竞争性的性能。
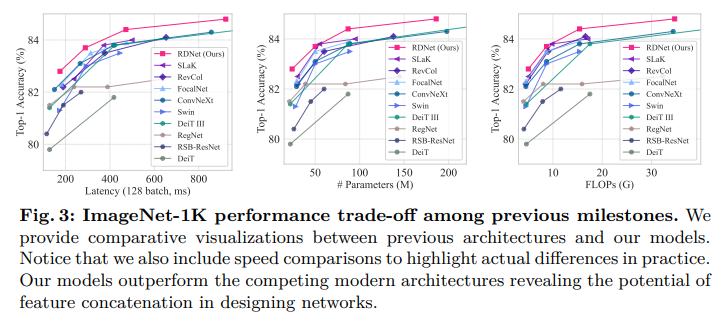
4.2、零样本图像分类
我们通过训练CLIP[55]在ImageNet-1k上进行零样本性能评估,以验证在不同训练方案下的适用性。我们遵循ConvNeXt-OpenCLIP[11]的训练协议,使用来自CC3M[61]、CC12M[9]和RedCaps[15]聚合集的12.8亿张已见图像。我们使用了OpenCLIP的代码库^2。
4.3、语义分割
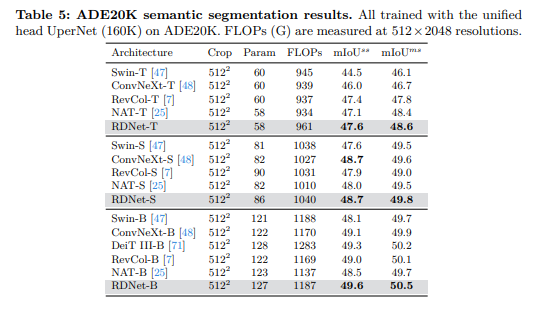
我们使用在ImageNet-1K上预训练的权重,在ADE20K[96]数据集上使用UperNet[86]进行语义分割。对于RDNet-T、-S和-B,我们分别使用8e-5的学习率、0.03的权重衰减,以及0.1、0.2和0.3的随机深度率。其余训练设置遵循ConvNeXt[48]。如表5所示,RDNet表现出强大的性能,这证明了其在密集预测任务上的有效性。
4.4、目标检测
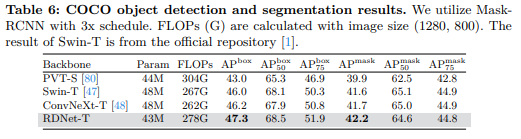
我们使用Mask-RCNN[26]在COCO[44]上评估目标检测性能。我们使用3e-5的学习率和0.2的随机深度率。其余训练设置再次遵循ConvNeXt[48]。如表6所示,RDNet表现出竞争性的性能。
5、讨论
5.1、初步研究 - 随机网络实验
本研究旨在揭示密集连接相比残差连接的有效性。我们在各种场景下训练了大量随机网络,这些场景包括:1) 多种网络规模;2) 多种类型的构建块;3) 一系列网络架构元素;4) 不同的训练设置。
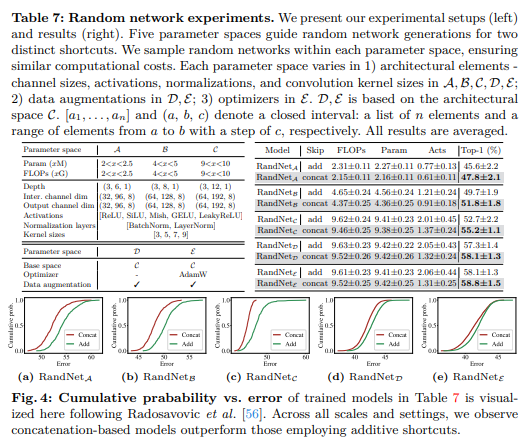
参数空间和成本约束。表7(左)展示了我们在三个不同规模下训练的RandNet A , B , C {}_{\mathcal{A}, \mathcal{B}, \mathcal{C}} A,B,C的参数空间。我们根据预算(如参数数量、浮点运算次数和激活(反映内存消耗))来多样化搜索空间。我们通过纳入数据增强将空间从 C \mathcal{C} C扩展到 D \mathcal{D} D,并进一步通过同时应用数据增强和不同的优化器[50]扩展到 E \mathcal{E} E。只有满足预定预算的随机生成网络才会被训练。我们使用在Tiny-ImageNet[85]上训练的90个周期的训练设置[27]。对于使用数据增强[13,33,66,92,93,95]的 C \mathcal{C} C和 E \mathcal{E} E空间,训练周期为180个周期。总体而言,累计训练的网络数量超过15,000个。
RandNet 架构。基于[27],我们在第一阶段内堆叠随机构建块。我们在包含不同深度、宽度、激活函数、归一化和卷积核大小的参数空间中生成随机网络,以便在受限成本下提供灵活性(参见表7)。此外,我们在所有搜索空间中多样化构建块,以进行更广泛的实验。我们区分了三种不同的架构块——称为PreNorm、PostNorm和PostNorm(无激活)——它们通过预激活和快捷连接位置的使用来区分。PreNorm块采用预归一化[28,32]在跳跃连接之前。相比之下,两个PostNorm块享有后归一化[27,48]。PostNorm与PostNorm(无激活)的区别在于后跳跃连接的激活函数。
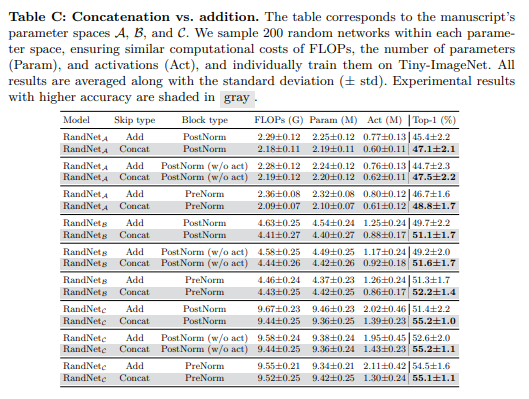
结果解释。表7(右)显示,在所有配置中,级联始终优于加性快捷连接。此外,图4展示了基于级联架构的卓越能力。
5.2、输入尺寸对性能的影响
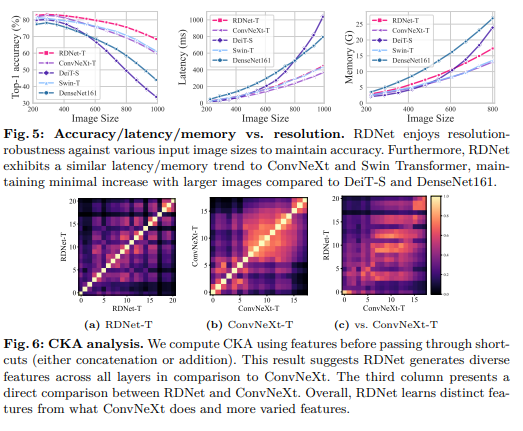
我们提供了关于输入尺寸对比的令人信服的发现。首先,图5(左)显示RDNet对输入尺寸变化具有很强的适应性。有趣的是,DenseNet161即使在没有强大数据增强的情况下进行训练,仍然具有很强的适应性,超越了使用强大数据增强训练的DeiT-S。我们将此归因于密集连接的有效性。
我们的发现进一步表明,与面向宽度的网络(由于中间张量较大而随着输入尺寸增大而变慢)不同,我们模型的优化宽度避免了延迟/内存损失。图5(中间、右)说明,随着图像尺寸的增长,RDNet与ConvNeXt和Swin Transformer竞争,而与DenseNet161[32](随着图像尺寸的增长而变慢且消耗更多内存)不同。我们注意到,更大的规模(如-S、-B和-L)都遵循相同的趋势。
5.3、CKA 分析
我们使用中心核对齐(CKA)[37]来分析RDNet与ConvNeXt的层特定特征。图6显示,RDNet在每一层都学习到了独特的特征,与ConvNeXt相比展示了不同的模式。在第三列中,ConvNeXt和RDNet在比较时惊人地学习了不同的特征,突出了每个模型独特的学习动态。
5.4、重新审视随机深度
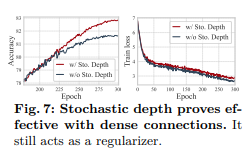
值得注意的是,由于DenseNets在网络的连接模式上具有相似性,它们最初并没有在模型训练中使用随机深度[33]。我们认为,随机深度不应被忽视;我们的结果表明,当将其融入我们的模型时,可以观察到显著的改进,如图7所示。我们还观察到,即使是很小的随机深度比例也会产生深远的影响(参见表9)。

5.5、消融研究
我们将所有消融研究结果汇总在表8中。每个表格都包含几个模型,这些模型经过精心调整,以确保与其他模型具有几乎相等的计算成本,从而确保对我们特定焦点的公平比较。我们在第3.2节中系统地引用了每项研究的方法论。
6、结论
在本文中,我们重新回顾了DenseNet过去的成功,它在以ResNet、ConvNeXt和ViT等加法快捷连接为主的模型时代,曾一度超越了ResNet。我们首先重新发现了DenseNet的潜力,通过我们的初步研究,我们关注到一个被低估的事实,即DenseNet的级联快捷连接超越了ResNet风格的加法快捷连接的传统表达能力。然后,我们强调了过时的训练设置和经典的宏块设计,这些都削弱了DenseNet与现代架构相比的有效性。通过实现我们的目标,即使用现代化元素拓宽DenseNet,我们证明了DenseNet的基本原理在实现稳健建模性能方面本身是具有竞争力的。我们的模型在性能方面与最新的现代架构相媲美;多样化级联特征的使用显著提高了密集预测任务的性能,展示了在使用加法快捷连接的模型中被忽视的优势。我们希望我们的工作能够揭示在网络设计中使用级联的优势,并倡导在考虑ResNet风格架构的同时,也考虑DenseNet风格的架构。
附录
在本附录中,我们提供了额外的实验和细节以补充主论文的内容。内容如下:
- A节:评估了在基准测试集上,包括ImageNet-V2[58]、ObjectNet[4]、ImageNet-A[30]、ImageNet-Sketch[77]和ImageNet-R[29]等分布外数据集上,ImageNet-1K预训练模型的鲁棒性;
- B节:报告了使用Cascade Mask-RCNN[8]的进一步COCO目标检测和实例分割结果;
- C节:评估了在各种测试平台上ImageNet顶部准确率与延迟之间的权衡,包括PyTorch和TensorRT A100推理,以及CPU推理结果;
- D节:提供了更多细节,包括我们在第5.1节中描述的初步研究的具体结果和设置;
- E节:介绍了我们在ImageNet和下游任务训练与评估方面的实验设置。
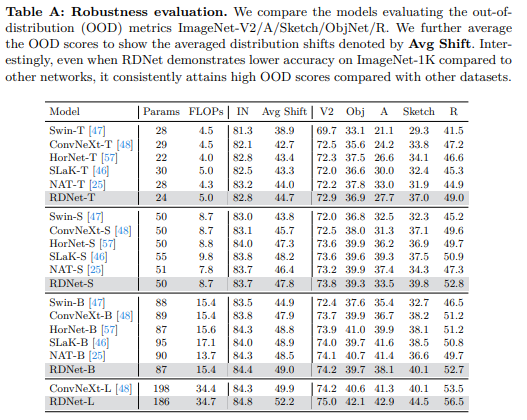
A. 鲁棒性评估
我们进一步使用ImageNet分布外(OOD)基准测试集评估了我们模型的鲁棒性,包括ImageNet-V2[58]、ImageNet-A[30]、ImageNet-Sketch[77]、ImageNet-R[29]和ObjectNet[4]。表A显示,与其他模型相比,我们的RDNet展示了优越的鲁棒性。我们特别选择了具有可比ImageNet-1K准确率的模型(如HorNet、SLaK和NAT),以展示我们的模型在这些模型之外的分布(OOD)性能上的优越性。值得注意的是,即使在ImageNet-1K上RDNet的准确率低于竞争模型,RDNet也在各种基准测试集上实现了高OOD分数。
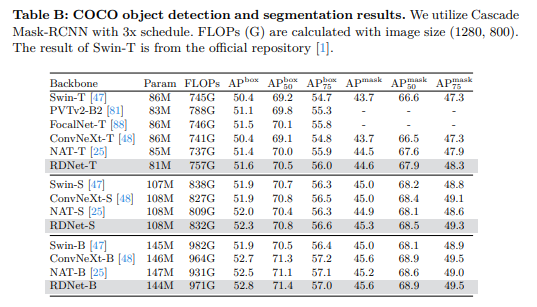
B. 使用Cascade Mask-RCNN进行目标检测
作为主论文中表6中Mask-RCNN[26]结果的扩展,我们采用了Cascade Mask-RCNN头部[8]来进一步评估我们的预训练模型。如表B所示,RDNet展示了具有竞争力的性能。请注意,与ConvNeXt相比,我们的模型没有经历详尽的训练超参数微调以达到最大精度,这表明还有进一步提高准确性的潜力。
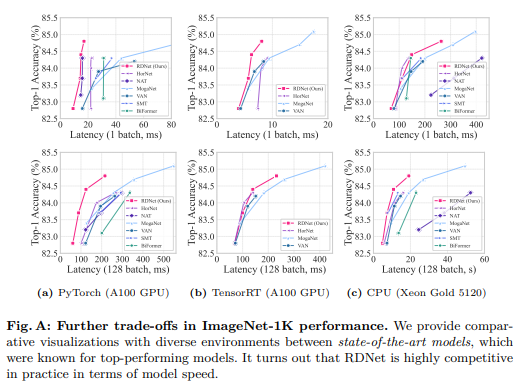
C. 进一步的ImageNet准确性与延迟权衡
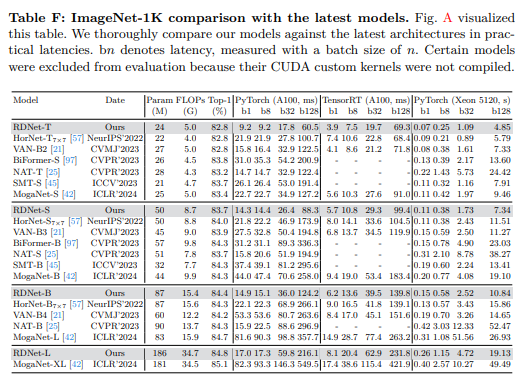
为了评估我们模型的实用性,我们在不同的测试平台上测量了速度。我们使用PyTorch框架在NVIDIA A100 GPU、Intel Xeon Gold 5120 CPU以及NVIDIA A100 GPU上的TensorRT推理引擎上精确测量了推理速度。我们的测试环境包括PyTorch版本1.13.1、CUDA版本11.6和TensorRT版本8.5.3,用于这些实验。图A显示,在所有评估设置中,我们的模型始终表现出优越的准确性与延迟权衡。请注意,A中的(b)部分包含的模型较少,因为那些由于使用CUDA自定义内核等因素而难以转换为推理引擎的模型没有被评估。我们在表F中报告了所有数字。
D. 我们试点研究的更多细节
我们展示了在受控设置下进行的RandNet个别实验结果。我们针对每种预算配置、块类型和跳跃连接类型进行了200次实验。在图B和表C中,对于参数空间
A
\mathcal{A}
A、
B
\mathcal{B}
B和
C
\mathcal{C}
C,拼接操作在性能上优于加法操作。对于使用数据增强的参数空间
D
\mathcal{D}
D和
E
\mathcal{E}
E,我们在实验中使用以下超参数:对于RandAugment[13],我们限制幅度值的集合为
3
,
5
,
7
{3, 5, 7}
3,5,7;对于MixUp[93]和CutMix[92],我们分别使用alpha值为
0.1
,
0.3
,
0.5
{0.1, 0.3, 0.5}
0.1,0.3,0.5;Dropout[63]比例和随机深度[34](Stochastic Depth)比例分别设置为
0.1
,
0.2
{0.1, 0.2}
0.1,0.2和
0.05
,
0.1
{0.05, 0.1}
0.05,0.1;标签平滑[66]固定为0.1;随机擦除[95]也固定为0.25。
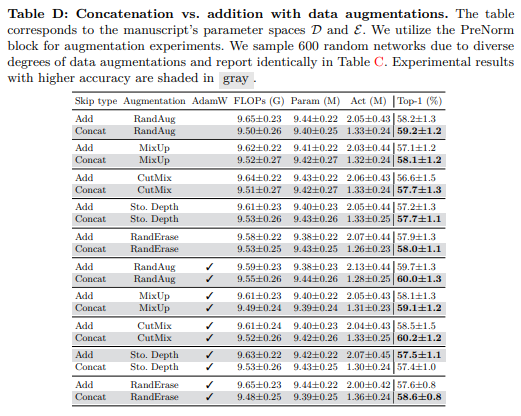
由于每个数据增强设置的不同,我们对每个元素进行了600次实验。此外,即使将优化器更改为AdamW,我们也针对每种增强训练了600个随机网络。图C和表D表明,数据增强缩小了加法和拼接式跳跃连接之间的性能差距,特别是注意到使用随机深度和AdamW训练的元素(即)从加法跳跃连接中受益更多。然而,我们仍然观察到,即使在AdamW训练配置中,基于拼接的模型仍然优于加法跳跃连接。
E. 实验设置
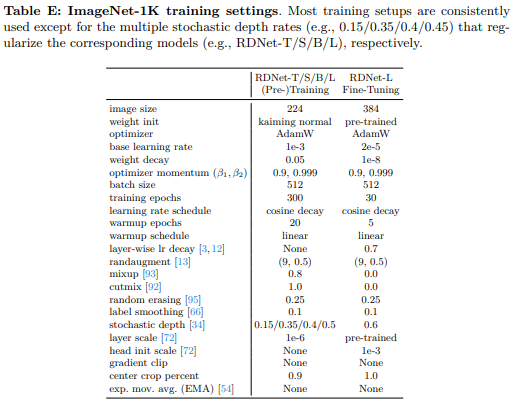
E.1 ImageNet 训练
在表E中,我们展示了在ImageNet 1K数据集上训练RDNet的配置。RDNet的每个变体都遵循这些设置,除了随机深度率[34]是根据每个模型变体进行定制的。对于微调,我们将三个连续的特征混合块组合在一起进行逐层学习率衰减[3,12],这与ConvNeXt采用的方法类似。我们使用timm Python包[83]进行模型训练。
E.2 下游任务
我们遵循[48]中概述的超参数扫描协议,但扫描得更加轻量级。对于在ADE20K上训练的UperNet[86],我们探索了以下超参数:学习率
8
e
−
5
,
1
e
−
3
{8e-5, 1e-3}
8e−5,1e−3,权重衰减
0.01
,
0.03
,
0.05
{0.01, 0.03, 0.05}
0.01,0.03,0.05。对于在COCO上训练的Mask-RCNN[26],我们探索了学习率
2
e
−
3
,
3
e
−
3
{2e-3, 3e-3}
2e−3,3e−3,权重衰减
0.05
,
0.1
{0.05, 0.1}
0.05,0.1,随机深度
0.1
,
0.2
{0.1, 0.2}
0.1,0.2等超参数。对于在COCO上训练的Cascade Mask-RCNN[8],我们探索了学习率
8
e
−
5
,
1
e
−
4
{8e-5, 1e-4}
8e−5,1e−4,权重衰减
0.05
,
0.1
{0.05, 0.1}
0.05,0.1,随机深度
0.4
,
0.5
,
0.6
{0.4, 0.5, 0.6}
0.4,0.5,0.6,以及逐层学习率衰减
0.7
,
0.8
{0.7, 0.8}
0.7,0.8等超参数。我们注意到,我们的搜索空间与ConvNeXt[48]中已知的搜索空间相似或更小(例如,ADE20K上为6(我们)vs. 12(ConvNeXt),COCO实验上为8/24(我们)vs. 48(ConvNeXt))。
E.3 基准测试设置
我们使用PyTorch 1.13.1和CUDA 11.6在V100 GPU上测量延迟和内存。在所有测量中,我们都采用了channels-last内存格式[51]。在训练阶段,我们使用批量大小为16来测量内存。
测试结果
YOLOv8l summary (fused): 208 layers, 31570800 parameters, 12060480 gradients, 116.8 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 15/15 [00:02<00:00, 5.82it/s]
all 230 1412 0.968 0.96 0.99 0.751
c17 40 131 0.99 0.992 0.995 0.833
c5 19 68 0.966 1 0.994 0.825
helicopter 13 43 0.975 0.906 0.977 0.602
c130 20 85 1 0.998 0.995 0.653
f16 11 57 0.982 0.95 0.993 0.702
b2 2 2 0.889 1 0.995 0.822
other 13 86 0.981 0.965 0.972 0.519
b52 21 70 0.975 0.971 0.986 0.826
kc10 12 62 1 0.973 0.989 0.851
command 12 40 0.993 1 0.995 0.824
f15 21 123 0.961 1 0.994 0.694
kc135 24 91 0.988 0.989 0.99 0.709
a10 4 27 1 0.474 0.936 0.44
b1 5 20 0.985 1 0.995 0.76
aew 4 25 0.951 1 0.995 0.801
f22 3 17 0.95 1 0.995 0.75
p3 6 105 1 0.972 0.995 0.81
p8 1 1 0.895 1 0.995 0.697
f35 5 32 0.966 0.969 0.987 0.551
f18 13 125 0.992 0.989 0.991 0.837
v22 5 41 0.986 1 0.995 0.75
su-27 5 31 0.981 1 0.995 0.861
il-38 10 27 0.991 1 0.995 0.827
tu-134 1 1 0.85 1 0.995 0.895
su-33 1 2 1 0.768 0.995 0.796
an-70 1 2 0.89 1 0.995 0.824
tu-22 8 98 0.997 1 0.995 0.824
Speed: 0.1ms preprocess, 4.3ms inference, 0.0ms loss, 0.9ms postprocess per image
















 36
36











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











