







一、深度学习环境配置
二、YOLOV5 环境配置
环境要求:Python>=3.8.0 , PyTorch>=1.8.
git clone https://github.com/ultralytics/yolov5 # clone
cd yolov5
pip install -r requirements.txt # install
执行完上述操作后,在 yolov5 文件夹下打开终端,输入以下命令。多了 __pycache__ 、 runs(存放结果的文件夹) 和 yolov5s.pt(模型权重文件) 三个文件。
__pycache__ 文件夹:当 Python 脚本首次运行时,解释器会将 .py 源代码文件编译成字节码文件(.pyc 或 .pyo)。编译后的字节码存储在 __pycache__ 目录中。这些字节码文件使得后续运行相同脚本时,加载速度更快,因为 Python 不需要重新编译源代码。
python detect.py
按照官方给出的指令,detect.py 功能十分强大,支持对多种图像和视频流进行检测的,具体的使用方法如下:
python detect.py --weights yolov5s.pt --source 0 # webcam 电脑默认摄像头
img.jpg # image
vid.mp4 # video
screen # screenshot 屏幕截图
path/ # directory 目录
list.txt # list of images 图片列表文件
list.streams # list of streams 流媒体列表文件
'path/*.jpg' # glob
'https://youtu.be/LNwODJXcvt4' # YouTube
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream 实时流检测结果会保存在 /yolov5/runs/detect/exp/ 文件夹下
(yolov5_env) wu@WP:~/yolo/yolov5$ python3 detect.py
Creating new Ultralytics Settings v0.0.6 file ✅
View Ultralytics Settings with 'yolo settings' or at '/home/wu/.config/Ultralytics/settings.json'
Update Settings with 'yolo settings key=value', i.e. 'yolo settings runs_dir=path/to/dir'. For help see https://docs.ultralytics.com/quickstart/#ultralytics-settings.
detect: weights=yolov5s.pt, source=data/images/zidane.jpg, data=data/coco128.yaml, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_format=0, save_csv=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False, vid_stride=1
YOLOv5 🚀 v7.0-383-g1435a8ee Python-3.10.15 torch-2.5.1 CUDA:0 (NVIDIA GeForce RTX 3060 Ti, 7965MiB)
Downloading https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5s.pt to yolov5s.pt...
100%|███████████████████████████████████████| 14.1M/14.1M [00:20<00:00, 720kB/s]
Fusing layers...
YOLOv5s summary: 213 layers, 7225885 parameters, 0 gradients, 16.4 GFLOPs
image 1/2 /home/wu/yolo/yolov5/data/images/bus.jpg: 640x480 4 persons, 1 bus, 19.9ms
image 2/2 /home/wu/yolo/yolov5/data/images/zidane.jpg: 384x640 2 persons, 2 ties, 20.6ms
Speed: 0.2ms pre-process, 20.2ms inference, 27.8ms NMS per image at shape (1, 3, 640, 640)
Results saved to runs/detect/exp
终端输出分析:
1. Ultralytics 设置初始化
- 日志内容:
Creating new Ultralytics Settings v0.0.6 file ✅ View Ultralytics Settings with 'yolo settings' or at '/home/wu/.config/Ultralytics/settings.json' - 分析:
Ultralytics 的配置文件首次生成并存储在/home/wu/.config/Ultralytics/settings.json,用户可以通过命令yolo settings查看或修改这些设置。
2. 设置更新提示
- 日志内容:
Update Settings with 'yolo settings key=value', i.e. 'yolo settings runs_dir=path/to/dir'. For help see https://docs.ultralytics.com/quickstart/#ultralytics-settings. - 分析:
提供了修改配置的命令示例,例如更改运行目录:yolo settings runs_dir=path/to/dir。详细帮助文档链接也提供了。
3. 命令参数解析
- 日志内容:
detect: weights=yolov5s.pt, source=data/images/zidane.jpg, data=data/coco128.yaml, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_format=0, save_csv=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False, vid_stride=1 - 分析:
YOLOv5 的检测任务被配置为:- 使用
yolov5s.pt模型权重; - 检测源图片为
data/images/zidane.jpg; - 数据集配置文件为
data/coco128.yaml; - 图片输入尺寸为
[640, 640]; - 阈值设置:
- 置信度阈值 (
conf_thres) 为 0.25; - IoU 阈值 (
iou_thres) 为 0.45;
- 置信度阈值 (
- 最大检测目标数为 1000;
- 结果保存在
runs/detect/exp。
- 使用
4. YOLOv5 环境信息
- 日志内容:
YOLOv5 🚀 v7.0-383-g1435a8ee Python-3.10.15 torch-2.5.1 CUDA:0 (NVIDIA GeForce RTX 3060 Ti, 7965MiB) - 分析:
- YOLOv5 版本:
v7.0-383-g1435a8ee; - Python 版本:
3.10.15; - PyTorch 版本:
2.5.1; - 硬件环境:CUDA 支持的 NVIDIA RTX 3060 Ti(显存 7965 MiB)。
- YOLOv5 版本:
5. 权重文件下载
- 日志内容:
Downloading https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5s.pt to yolov5s.pt... 100%|███████████████████████████████████████| 14.1M/14.1M [00:20<00:00, 720kB/s] - 分析:
模型权重yolov5s.pt被从 Ultralytics 官方仓库下载。
6. 模型初始化
- 日志内容:
Fusing layers... YOLOv5s summary: 213 layers, 7225885 parameters, 0 gradients, 16.4 GFLOPs - 分析:
- 模型的层数:213;
- 参数总数:7225885;
- 无梯度(推理模式);
- 计算量:16.4 GFLOPs。
7. 图片检测
- 日志内容:
image 1/2 /home/wu/yolo/yolov5/data/images/bus.jpg: 640x480 4 persons, 1 bus, 19.9ms image 2/2 /home/wu/yolo/yolov5/data/images/zidane.jpg: 384x640 2 persons, 2 ties, 20.6ms Speed: 0.2ms pre-process, 20.2ms inference, 27.8ms NMS per image at shape (1, 3, 640, 640) Results saved to runs/detect/exp - 分析:
- 检测目标:图片1中识别出 4 个 person 和 1 个 bus;图片2中识别出 2 个 person 和 2 个 tie;
- 检测速度:
- 预处理耗时:0.2ms;
- 推理耗时:20.2ms;
- 非极大值抑制 (NMS) 耗时:27.8ms。
三、数据标注
目标检测---利用labelimg制作自己的深度学习目标检测数据集
labelimg标注闪退报错:TypeError: arguments did not match any overloaded call
下载 labelimg 之后, 终端输入 labelImg 打开。
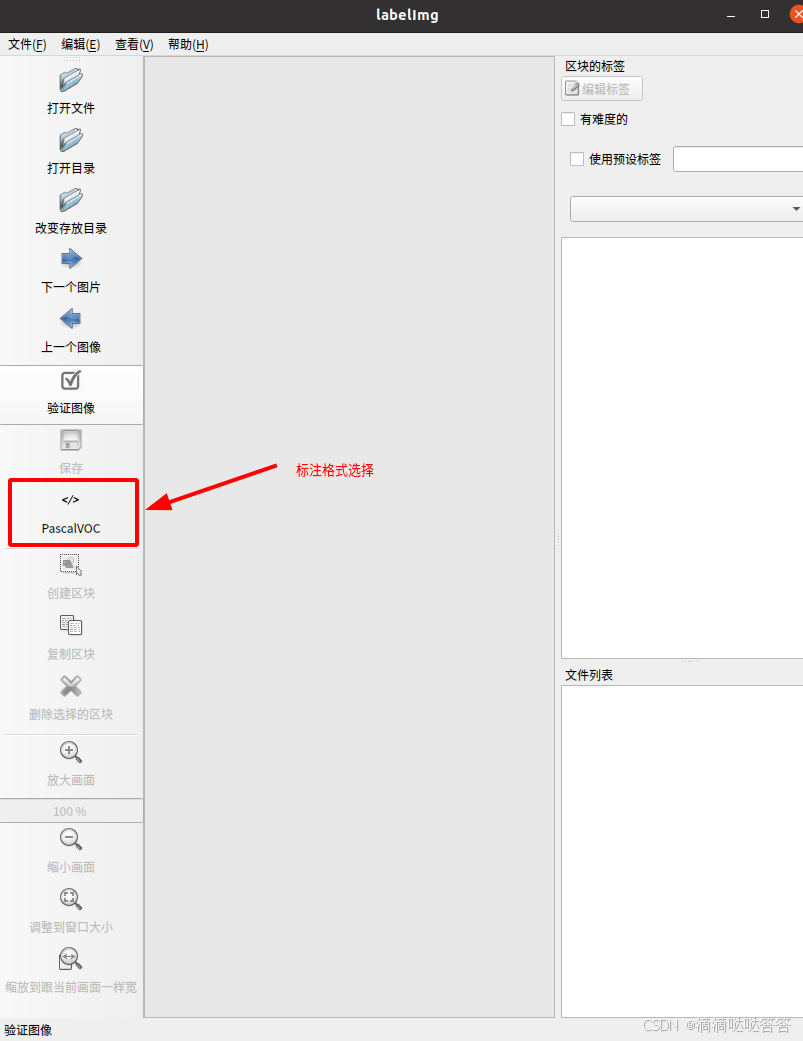
Labelimg是一款开源的数据标注工具,可以标注三种格式。
1 VOC 标签格式,保存为 xml 文件。
2 yolo 标签格式,保存为 txt 文件。
3 createML 标签格式,保存为 json 格式。
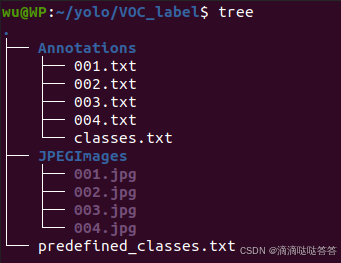
首先准备我们需要打标注的数据集。建议新建一个 VOC_label 文件夹(有利于使用 labelimg 打标签),里面创建一个名为 JPEGImages 的文件夹存放我们需要打标签的图片;再创建一个名为Annotations 的文件夹存放标注的标签文件;最后创建一个名为 predefined_classes.txt 的 txt 文件来存放所要标注的类别名称。
VOC_label 的目录结构为:
├── VOC_label
│├── JPEGImages 存放需要打标签的图片文件
│├── Annotations 存放标注的标签文件
│├── predefined_classes.txt 定义要标注的所有类别
在 VOC_label 文件夹下打开终端,使用如下命令打开 labelimg
labelImg JPEGImages predefined_classes.txt当我们打完全部标签后, Annotations 文件夹里面会生成标签文件和一个 classes.txt 的类别文件(和 predefined_classes.txt 文件相同)。
四、模型训练
1. 获取预训练模型
在人工智能和机器学习的领域,预训练(pre-training)是指在一个较小的、特定任务的数据集上进行微调(fine-tuning)之前,在一个大数据集上训练一个模型的过程。这个初始训练阶段允许模型从数据中学习般的特征和表征,然后可以针对具体任务进行微调。
预训练背后的主要动机是利用从大规模数据集获得的知识来提高模型在较小的、更集中的数据集上的性能。通过这样的方式,研究人员可以用较少的标记实例获得更好的结果,减少对大量特定任务、标记数据的需求。
yolov5 的给我们提供了几个预训练模型,我们可以对应我们不同的需求选择不同的版本的预训练模型。这里我们使用上面下载好的 yolov5s.pt 作为预训练模型。新建文件夹 pretrain,将 yolov5s.pt 放入其中。
2. 修改模型配置文件(.yaml)
复制 yolov5/models/yolov5s.yaml 文件,重命名为 test_yolov5s.yaml 文件,修改类别数量。

3. 修改数据配置文件(.yaml)
test_data.yaml
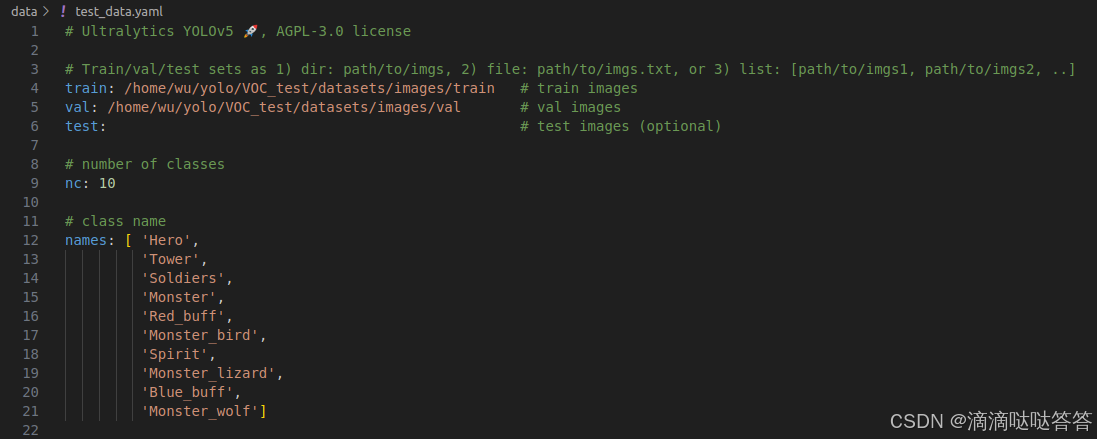
4. 修改模型参数 + 模型训练
- 预训练模型权重文件路径:--weights pretrain/yolov5s.pt
- 模型配置文件地址:--cfg models/test_yolov5s.yaml
- 数据配置文件地址:--data data/test_data.yaml
- 超参数:学习轮次:--epoch 30
- 超参数:批量大小:-batch-size 8
- 指定训练使用的设备:--device 0
python train.py --weights pretrain/yolov5s.pt --cfg models/test_yolov5s.yaml --data data/test_data.yaml --epoch 30 --batch-size 8 --device 0注意:模型参数参考 深度学习训练参数详解。
- (1)epoch:在每个 epoch 中,我们使用
data_iter函数 遍历整个数据集, 并将训练数据集中所有样本都使用一次(假设样本数能够被批量大小整除)。 - (2)batch_size:批量大小,通常为 2 的指数,一次训练中 小批量随机梯度下降 所选取的用来计算梯度的样本数量,在训练集中取 batch_size 个样本计算 损失函数关于模型参数的导数(即梯度);
- (3)iter:1个 iter 等于使用 batch_size 个样本训练一次,iter 可在训练日志中看到。在每次 iter 中,会更新模型的参数;
如训练集有240个样本,设置batch_size=6,那么:训练完整个样本集需要:40个iter,1个epoch。
一个能打乱数据集中的样本并以小批量方式获取数据 的示例 data_iter函数 如下。注意:该函数中的 for 循环会将训练集中的数据分批输出,最终遍历整个数据集!
def data_iter(batch_size, features, labels):
"""
按批量生成数据样本的迭代器(用于小批量梯度下降)。
参数:
batch_size (int): 每个批次的样本数量。
features (Tensor): 特征矩阵,形状为 (样本数, 特征维度)。
labels (Tensor): 标签向量,形状为 (样本数, 1) 或 (样本数, )。
返回:
生成器(Generator):每次迭代返回一个批次的特征和标签,
即一个二元组 (X_batch, y_batch),
其中 X_batch 的形状为 (batch_size, 特征维度),
y_batch 的形状为 (batch_size, 1) 或 (batch_size,)。
"""
num_examples = len(features) # 样本总数
indices = list(range(num_examples)) # 索引列表,例如 [0, 1, 2, ..., num_examples-1]
# 打乱索引顺序,随机打乱数据(实现随机抽样)
random.shuffle(indices)
# 按照 batch_size 进行分批处理(每次移动步长为 batch_size,即每次循环都会输出一批数据;)
for i in range(0, num_examples, batch_size):
# 获取当前批次的索引
batch_indices = torch.tensor(
indices[i: min(i + batch_size, num_examples)]) # 防止越界
# 使用索引选出对应的样本特征和标签,并通过 yield 返回(生成器)
yield features[batch_indices], labels[batch_indices]
训练完成后终端输出如下所示。其中包含两个训练好的权重文件:
best.pt:是在训练过程中评估得到的最佳模型权重,通常基于验证集上的最佳性能(例如最小的损失函数值、最佳的 mAP 等指标)来保存。
last.pt :是训练过程结束时保存的模型权重,代表了最后一轮训练后的模型状态。
30 epochs completed in 0.015 hours.
Optimizer stripped from runs/train/exp/weights/last.pt, 14.4MB
Optimizer stripped from runs/train/exp/weights/best.pt, 14.4MB
Validating runs/train/exp/weights/best.pt...
Fusing layers...
test_YOLOv5s summary: 157 layers, 7037095 parameters, 0 gradients, 15.8 GFLOPs
Class Images Instances P R mAP50 mAP50-95: 100%|██████████| 1/1 [00:00<00:00, 36.28it/s]
all 6 41 0.658 0.909 0.875 0.467
Hero 6 8 0.468 0.875 0.814 0.444
Tower 6 6 0.989 1 0.995 0.614
Soldiers 6 27 0.517 0.852 0.818 0.343
Results saved to runs/train/exp5. 模型验证
使用训练好的模型在事先划分好的验证集上进行验证:
python val.py --weights runs/train/exp/weights/best.pt --data data/test_data.yaml运行结果:
(yolov5_env) wu@WP:~/yolo/yolov5$ python val.py --weights runs/train/exp/weights/best.pt --data data/test_data.yaml
val: data=data/test_data.yaml, weights=['runs/train/exp/weights/best.pt'], batch_size=32, imgsz=640, conf_thres=0.001, iou_thres=0.6, max_det=300, task=val, device=, workers=8, single_cls=False, augment=False, verbose=False, save_txt=False, save_hybrid=False, save_conf=False, save_json=False, project=runs/val, name=exp, exist_ok=False, half=False, dnn=False
YOLOv5 🚀 v7.0-385-gb968b2d7 Python-3.10.15 torch-2.5.1 CUDA:0 (NVIDIA GeForce RTX 3060 Ti, 7965MiB)
Fusing layers...
test_YOLOv5s summary: 157 layers, 7037095 parameters, 0 gradients, 15.8 GFLOPs
val: Scanning /home/wu/yolo/VOC_test/datasets/labels/val.cache... 6 images, 0 backgrounds, 0 corrupt: 100%|██████████| 6/6 [00:00<?, ?it/s]
Class Images Instances P R mAP50 mAP50-95: 100%|██████████| 1/1 [00:00<00:00, 3.01it/s]
all 6 41 0.658 0.909 0.876 0.476
Hero 6 8 0.468 0.875 0.814 0.444
Tower 6 6 0.989 1 0.995 0.642
Soldiers 6 27 0.517 0.852 0.82 0.342
Speed: 0.1ms pre-process, 7.4ms inference, 21.6ms NMS per image at shape (32, 3, 640, 640)
Results saved to runs/val/exp五、模型训练可视化
1. 使用 Tensorbord 可视化训练过程
TensorBoard 是一个由 Google 开发的可视化工具,最初是为 TensorFlow 提供支持,但如今也支持其他框架如 PyTorch、Keras 和 JAX 等。它用于追踪和分析机器学习模型的训练过程,可以动态显示各种指标(如损失函数、准确率等),帮助用户优化模型。
# 使用 tensorboard 过程中如果报错
RuntimeError: module compiled against API version 0xf but this version of numpy is 0xd TensorFlow installation not found - running with reduced feature set.
# 解决方法:
pip install --upgrade tensorboard numpy查看模型的训练过程:
# log_dir:模型的信息保存目录
tensorboard --logdir=runs/train --load_fast=true
如果模型已经训练好了,但是我们还想查看此模型的训练过程,就需要输入如下的命令:
tensorboard --logdir=runs --load_fast=true
2. 使用 Comet 可视化
Comet 是一种实验管理平台,用于实时追踪和可视化深度学习模型的训练过程,同时可以保存超参数、数据集、模型权重等内容,便于实验管理和团队协作。
# 1. install
pip install comet_ml
# 2. 前往 Comet 官网 注册并登录,粘贴 API key
export COMET_API_KEY=<Your API Key>
# 3. train
python train.py --weights pretrain/yolov5s.pt --cfg models/test_yolov5s.yaml --data data/test_data.yaml --epoch 30 --batch-size 8 --device 03. 使用 ClearML 可视化
ClearML 是一个强大的实验管理和自动化工具,可以管理实验过程、数据集版本,并支持远程训练任务的执行。它的功能类似于 Comet,但更注重自动化和可复现性。
六、使用新模型进行推理测试
使用训练好的模型在新数据集上进行推理:
python detect.py --weight runs/train/exp/weights/best.pt --source ../VOC_test/datasets/images/test/test_001.jpg七、USB 摄像头实时目标检测
1. 检查摄像头设备
- 使用以下命令查看是否存在摄像头设备:
ls /dev/video*- 如果没有输出,说明系统未检测到摄像头,检查硬件连接或系统驱动。
2. 检查摄像头是否被占用
- 使用以下命令查看摄像头是否正在被其他程序占用:
fuser /dev/video0- 如果有输出,说明设备被占用。关闭相关程序或更换摄像头索引(如
--source 1)。
3. 修改设备权限
- 如果是权限问题,可以尝试以下命令:
sudo chmod 666 /dev/video0- 然后重新运行脚本
4. 测试摄像头功能
- 使用 OpenCV 测试摄像头是否正常工作:
#! /usr/bin/python3
import cv2
cap = cv2.VideoCapture(0)
if cap.isOpened():
print("Camera opened successfully!")
else:
print("Failed to open camera.")
cap.release()- 如果仍然失败,可能需要更换摄像头索引或检查系统配置。
5.测试摄像头视频流:
ffplay /dev/video0- 如果视频能正常播放,说明摄像头硬件和驱动没有问题。
参考
https://docs.ultralytics.com/yolov5/tutorials/train_custom_data/
【大作业-05】手把手教你使用YOLOV5训练自己的目标检测模型-口罩检测-视频教程
Ubuntu20.04配置YOLOV5算法相关环境,并运行融合YOLOV5的ORB-SLAM2开源代码

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









