







一、文章动机
虽然传统RAG框架能给LLM带来外部知识的补充,在一定程度上减少了知识密集型任务的事实性错误,但是在其输出结果中也带来了一些负面影响,如:
- 过度检索:经典的RAG框架会不加区分的对用户输入的问题进行相关知识检索,由此会引入一些与问题不相关或者没有用的信息,影响输出结果。
- 输出一致性问题:无法确保输出与检索知识中的事实保持一致。(就是假设LLM是一个优秀的学生,那么RAG就是一本参考书,这个问题就是LLM在考试的时候可以翻阅参考书,但是选取的知识点用来解答问题不是考题所涉及的知识点,所以最终会导致回答错误)
SELF-RAG就是试图优化以上两个问题。
二、Self-RAG工作流程
在给定输入提示和前几代的情况下,SELF - RAG首先确定将检索到的内容加入到prompt中是否会有帮助。如果是,则输出一个检索令牌,按需调用检索器模型(步骤1 )。随后,SELF - RAG并发处理多个检索到的段落,评估它们的相关性,然后生成相应的任务输出(步骤2 )。然后,它生成批评令牌来评估自己的输出,并在真实性和总体质量方面选择最佳输出(步骤3 )。
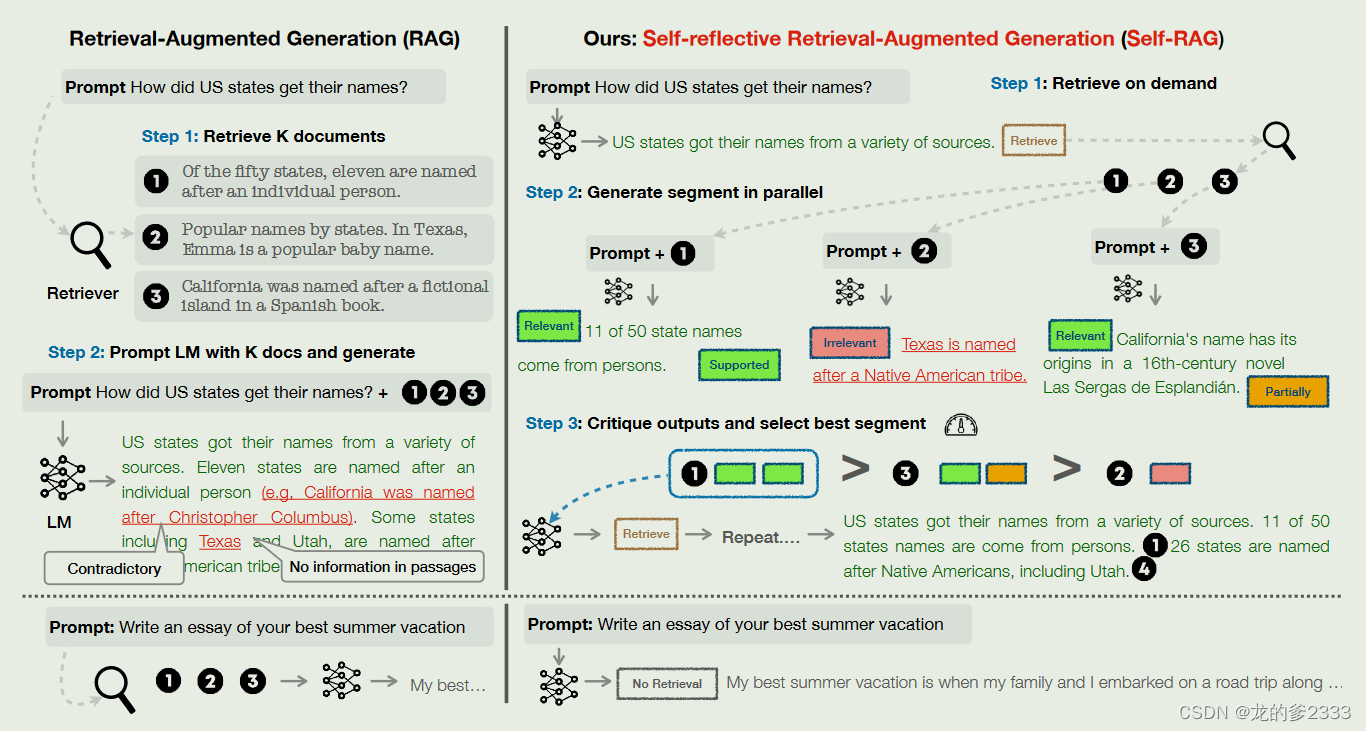
本文所提框架与普通RAG框架不一样的地方是:首先,Self-RAG不会每一次遇到输入都执行检索操作,它会先判断所遇到的问题需不需要执行检索操作,随后再根据判断结果进行下一步工作。其次。普通RAG框架并不能自己判断自己所检索出来的内容的质量。此外,Self-RAG为每个部分提供了引用,其自我评估输出是否得到段落的支持,从而更容易进行事实验证。
可以简单用下图来概括Self-RAG的基本工作流程:(图片转载于微信公众号:AI大模型应用实践)
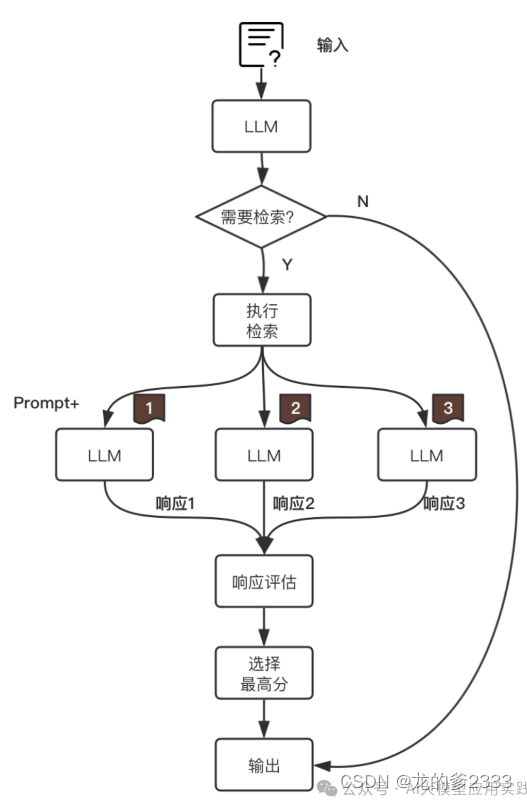
- 检索判断:经典的RAG框架会直接用用户输入的问题检索知识文档,但是Self-RAG会让模型自己判断用户提出的问题需不需要检索。如果不需要检索,模型就会用本身的参数化知识回答问题并输出。
- 按需检索:
不需要检索:(比如:请帮我创作一首关于春天的诗歌。)类似这种问题就可以又模型直接生成。
需要检索:(比如:请给我介绍一下华为公司的盘古大模型。)这种需要用到最新知识来回答的问题则需要让模型执行检索动作,检索出最相关的Top-k知识。
3.增强生成:从检索到的信息中挑选k块(无排序操作)相关内容与提示词结合用于提问,让大语言模型生成K个输出
4.评判、选择与输出:对于第三步生成的响应进行评估打分,选择分数最高的回答作为最终输出。
按照上述流程,LLM会在第1步和第4步进行评判。
文章提出了4个评估指标:

1. Retrieve:是否需要知识检索
表示LLM后续的内容生成是否需要做额外知识检索。
取值:
[No Retrieval] :无需检索,LLM直接生成
[Retrieval] :需要检索
[Continue to Use Evidence] :无需检索,使用之前内容
2. IsRel:知识相关性(知识 => 问题)
表示检索出来的知识是否提供了解决问题所需的信息 。
取值:
[Relevant]:检索出来的知识与需要解决的问题足够相关
[Irrelevant]:检索出来的知识与需要解决的问题无关
3. IsSup:响应支持度(知识 => 响应)
表示生成的响应内容是否得到检索知识的足够支持。
取值:
[Fully supported] :输出内容陈述被检索的知识完全支持。
[Partially supported] :输出内容陈述只有部分被检索的知识所支持。
[No support / Contradictory] :输出内容不被检索的知识所支持(即编造)。
比如提供的知识中只有“中国的首都是北京”,而输出内容中有“北京是中国的首都,北京最受欢迎的景点是长城。",那么这里的后半部分输出在提供的知识中就没有得到支持。所以属于部分支持即[Partially supported]。
4. IsUse:响应有效性(响应 => 问题)
表示生成的响应内容对于回答/解决输入问题是否有用。
取值:
[Utility : x] :按有效的程度x分成1-5分,即最高为[Utility:5]
Self-RAG并不是采用LLM与提示工程的方式来生成以上评估指标,而是通过微调LLM,让LLM在推理过程中实现自我反思,直接输出代表这些指标的标记性Tokens,论文中称为“反思Tokens”
比如,LLM在生成的时候,可能会发现需要额外的知识补充,就会输出[Retrieval]并暂停表示需要知识检索;在获得足够的知识与上下文后,会在输出答案时做自我评估与反省,并插入[Relevant],[Fully supported]等**** 这样的标记性token。
例子:
Response:[Relevant] 字节调动的Coze是一个大语言模型的应用开发平台,其提供了一站式开发LLM应用的相关工具、插件与编码环境.[Partially supported][Utility:5]
三、量化指标
使用 logprobs - 对数概率字段 LLM用于预测下一个Token的字段。
对于上述提到的标记性Tokens,文章是基于对数概率来计算来量化他们的数值。
比如一次输出中出现了[Fully supported]这个token,那么说明LLM推理的时候计算出了[Fully supported]、[Partially supported]等可能的token输出的概率,但最后选择了[Fully supported]。因此,在评估这次输出的IsSup(响应支持度)的分数时,就可以基于logprobs中这些tokens的概率来计算(上面例子中,显然[Fully supported]这个token的概率越高,说明支持度越高)。
- 【Retrival】:无需量化
- 【IsRel】: 知识相关度
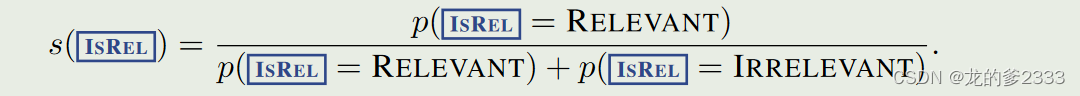
即用“relevant”token的概率占本类型两种token的概率和的比例。
- 【IsSup】: 响应支持度

即用“fully supported”token的概率占本类型三种类型token概率和的比例,加上“partially supported”token的概率所占比例。 但后者要乘以权重0.5。
- 【IsUse】: 响应有效性
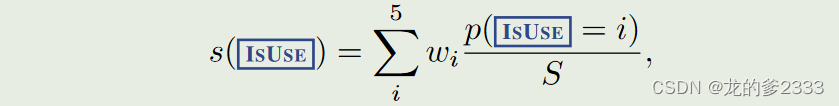
w = {−1, −0.5, 0, 0.5, 1}

即用本类型的5种类型token的概率占总概率的比例乘以对应的权重(分别为从-1到1不等),然后求和。
四、思考与改进
Self-RAG借助在模型层次的微调使得LLM自身具备了自我判断按需检索与自我反省的能力,在很大程度上减少了应用层面的复杂性,且不会降低模型自身的能力。当然,我们完全可以结合RAG其他范式在不同环节的优化方法,来让Self-RAG工作的更加完美。
在上面的原型应用中,有一个比较明显的优化策略来自于这里的Self-RAG的多次生成是基于知识检索出的top_K文档逐个生成,但是在实际测试中我们发现有几个问题:
①由于检索出的文档已经过了语义相似度排序,所以生成的结果评分很多时候会与文档排序一致,这就丧失了评估的意义。
②由于实际应用中知识结构的复杂性,很多时候需要把多个知识一次输入LLM做生成,以给予LLM更完整的“参考”。
③没有采用并行的生成方式。
因此,如果想充分利用Self-RAG的自我评估能力,可以能够根据实际需要优化这里检索(retriever)策略。比如:
做多次知识检索,并针对多次检索的结果分别做生成与评估;而不是针对一次检索的多个文档做生成评估 ,这样既可以给予LLM更多的上下文知识,也能利用Self-RAG的自省机制在多次生成中获取质量最高的输出。实现多次检索的策略可以更加灵活,比如:
①借助查询Rewrite后再次检索知识文档,可使用不同的Rewrite算法。
②使用不同的检索算法(比如关键词检索与语义检索)获得不同的知识文档。
③检索后使用不同的Rerank算法做知识文档的重排后进行多次生成。
参考文献:https://developer.volcengine.com/articles/7370376661030109235















 885
885











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









