





一种自适应感知路径的GNN:GeniePath
一、需要提前知道一些
1.感受野(receptive field)
图中一个节点的感受野为包含从这个节点出发到目标节点的路径上所有节点构成的子图
2.排列不变性(permutation invariant)
输入参数的顺序对输出结果没有影响
3.自适应路径层
自适应路径层包含两个互补的功能单元:
- 广度搜索:学习一阶邻居节点的权重(决定了哪些邻居是重要的,即引导探索的方向)
- 深度搜索:提取和过滤高阶邻居内汇聚的信息(决定了距离目标节点多少hop的邻居仍然有用)
二、为什么要感知路径
GNN领域的主要工作是设计有效的聚集器功能,可以传播信号周围的t阶邻域的每个节点。他们中很少有人试图学习指导传播的有意义的路径。
为什么学习接受路径很重要?原因可能有两方面:(1)图可能有噪声,在学习基于邻域的聚合时把噪声节点也聚合进去了。(2)不同的节点扮演不同的角色,因此产生不同的接受路径。
所以感知路径能够更有效地对传播最有用的信息。
三、GeniePath
1.GeniePath算法核心
使用排列不变性的条件和结合律来设计传播层,当沿着已经学过的路径传播信号时学习感受路径,而不是根据预先定义的路径。这个问题就等价于对每一个节点通过广度和深度扩展检测一个子图。
2.自适应路径层
- 自适应宽度函数:
H
t
m
p
H^{tmp}
Htmp =
ϕ
\phi
ϕ (A,
H
t
−
1
H^{t-1}
Ht−1;
Θ
\Theta
Θ)
它自适应地分配不同的重要程度给不同的单跳邻居来聚合信号,可以理解为一种邻域的注意力机制。 - 自适应深度函数: H t H^{t} Ht = φ \varphi φ ( H t m p H^{tmp} Htmp | { H T H^{ T} HT | τ \tau τ∈ {t-1,…,0 } } ; Φ \Phi Φ)
通过对不同深度的聚合信号之间的依赖关系建模,进一步提取并过滤离中心节点i 的t 阶距离处的聚合信号。自适应的广度函数
φ
\varphi
φ定义为:
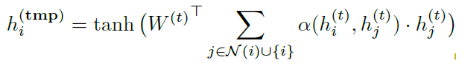
其中,α ( . , . )是注意力算子,用于衡量结点 i 和 j 之间的相似程度或者邻居节点 i 对中心节点 j 的影响

门机制和LSTM的长短记忆:基于新观察到的邻居聚合信息
h
i
t
h_{i}^t
hit
更新门:将新的有用信息加到记忆中,遗忘门参考过滤无用的老记忆,故在探索更远的邻居时起到了选择抽取与过滤的作用,并基于输出门和最新的记忆,输出节点 i 的第t+1层embedding,即
h
i
t
+
1
h_{i}^{t+1}
hit+1
3. 变体:GeniePath-Lazy
先通过叠加Adaptive Breadth 函数传播T阶内的邻居信息,得到{
h
i
h_i
hi (0) ,
h
i
h_i
hi (1) , … ,
h
i
h_i
hi (T) },再通过adaptive depth函数作用在它们上面进一步提取和过滤在不同深度层的信号。初始化
μ
i
0
μ_i^0
μi0 =
W
x
T
W_x^T
WxT
X
i
X_i
Xi ,并且
μ
i
T
μ_i^T
μiT放入最终的损失函数中,输出 {
h
i
(
t
)
h_i^{(t)}
hi(t)}。

GeniePath-Lazy 延迟了自适应深度函数的评估,其实就是把上一步φ ( . ) 与ϕ ( . ) 的输出拼接在了一起,再进行深度的自适应更新,由排列不变性定理可知,φ ( . ) 与ϕ ( . ) 都满足置换不变性,二者的叠加依旧满足置换不变性的基本要求。
总结
本文研究了图卷积网络中识别有意义的接受路径的问题。我们提出了具有自适应宽度和深度功能的自适应路径层来引导接受路径。我们在大型基准数据上的实验表明,GeniePath的性能明显优于最先进的方法,并且对堆叠层的深度或手工设置的邻域范围不太敏感。GeniePath的成功表明,为不同的节点选择合适的接受路径是重要的。















 514
514











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









