






AI框架之分布式系统-上(笔记)
常见的并行方法:
1.data parallel:数据并行是最基本、应用最广泛的并行方法。每个设备都有一套完整的模型参数,并处理不同的小批量训练数据。在训练阶段,每个设备使用自己的小批量计算局部梯度,然后使用 all-reduce 通信对全局梯度进行平均。然后根据平均梯度更新模型参数。
2.model parallel:模型并行将模型参数分布到多个设备上,根据分布方式可分为张量并行和管道并行。
2.1在管道并行中,模型在设备之间垂直(分层)分割。然而,由于不同设备上的计算之间的依赖性,该方法引入了设备空闲。为了提高资源利用率,小批量通常分为微批量,这允许不同设备上的计算之间有更多的重叠。
2.2 tensor parallel中,张量并行性通常强加在线性层上,因为在不同设备上分布矩阵乘法相对容易。为了减少通信开销,Megatron-LM [18]提出了列并行和行并行。在列并行中,权重矩阵W在 N 个设备上按列划分,产生 N 个矩阵 W1,W2, ...,Wn。矩阵乘法 XW1,XW2, ...,XWn 并行进行,产生 N 个输出向量 Y1,Y2, ...,Yn。在行并行中,权重矩阵 W 和输入向量 X 被划分到 N 个设备上,并且并行进行矩阵乘法 X1W1,X2W2,...,XnWn,从而产生 N 个输出向量。通过all-reduce操作得到最终的输出向量Y。在前馈块中,可以在第一线性层中使用列并行性,在第二层中使用行并行性。在 MHA 块中,Megatron-LM 对 QKV 线性层使用列并行性,对输出线性层使用行并行性。
AlphaFold 的 TP 效率不高,原因如下: 1)每个 evoformer 层中频繁的同步通信导致较高的开销; 2)除了attention和feed-forward之外的模块不能并行化; 3)TP的扩展受到关注头数量的限制(AlphaFold中的头在pair stack中是4个,因此TP最多可以扩展到4个设备)。
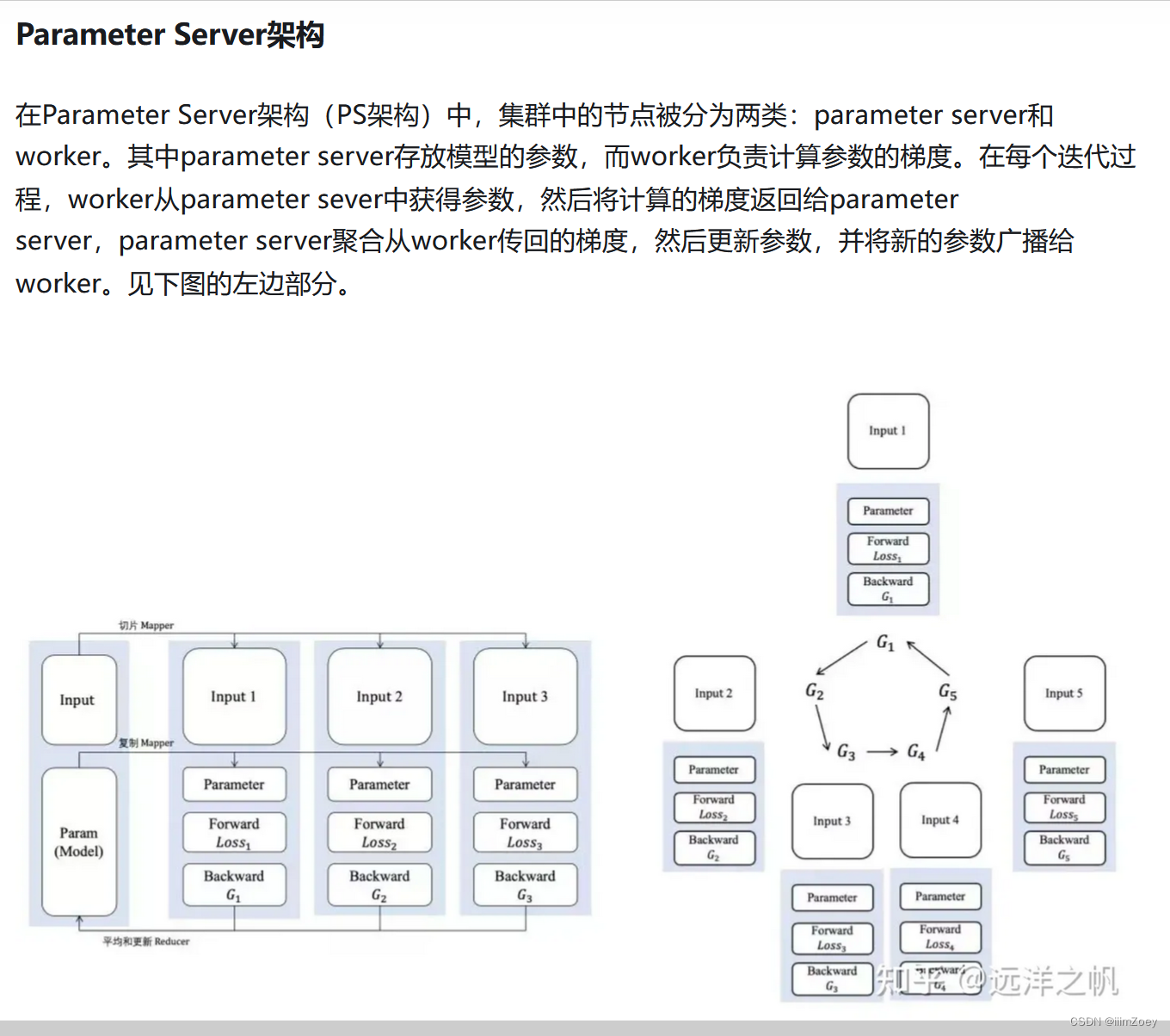
分布式训练系统架构
分布式训练系统架构主要有两种:
- Parameter Server Architecture(就是常见的PS架构,参数服务器)
- Ring-allreduce Architecture

all-reduce算法:
AllReduce梯度同步
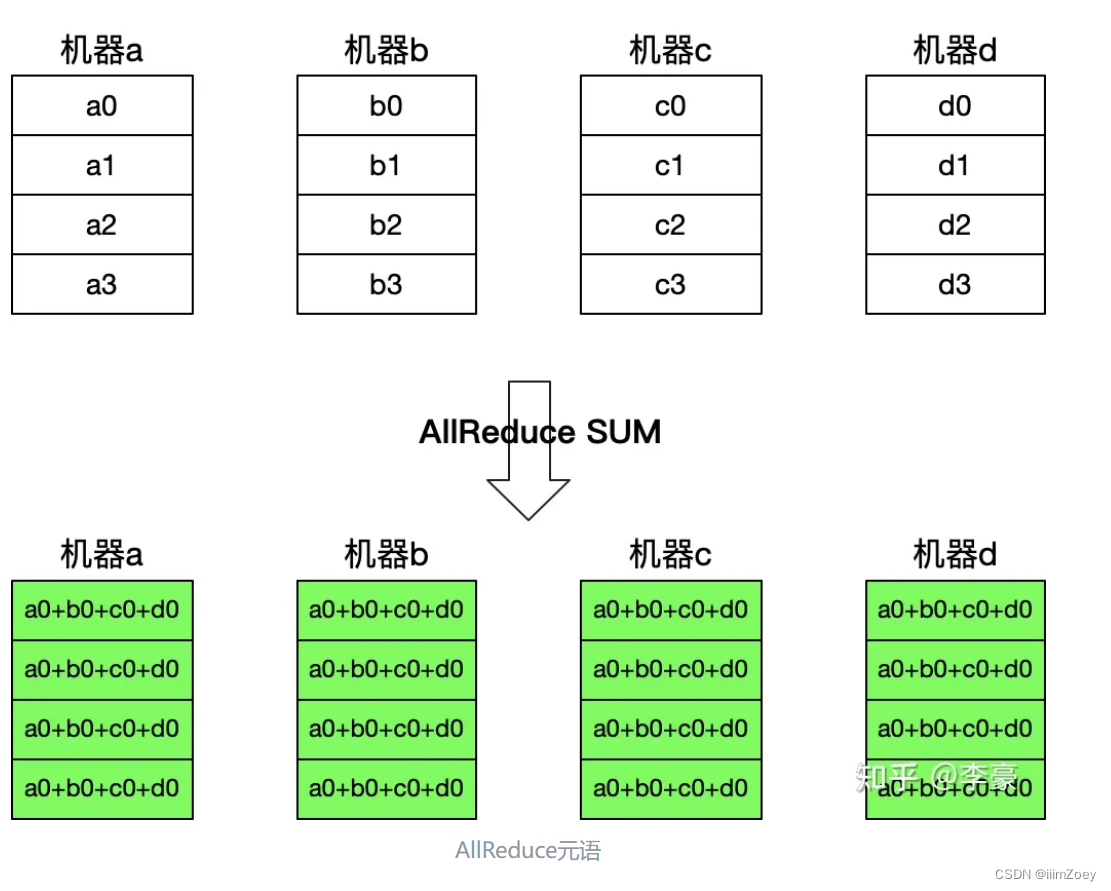
AllReduce是深度学习领域最常用的集合通信元语,主要用于多机/多卡之间的梯度同步。AllReduce诞生于HPC领域,MPI(Message Passing Interface, HPC领域的通信库)用多种方式实现了AllReduce元语,是深度学习领域参考的主要依据。
为什么不直接将MPI的AllReduce用于深度学习?MPI所使用的HPC领域历史悠久,关注更多的是CPU集群,深度学习领域广泛使用的是GPU集群。

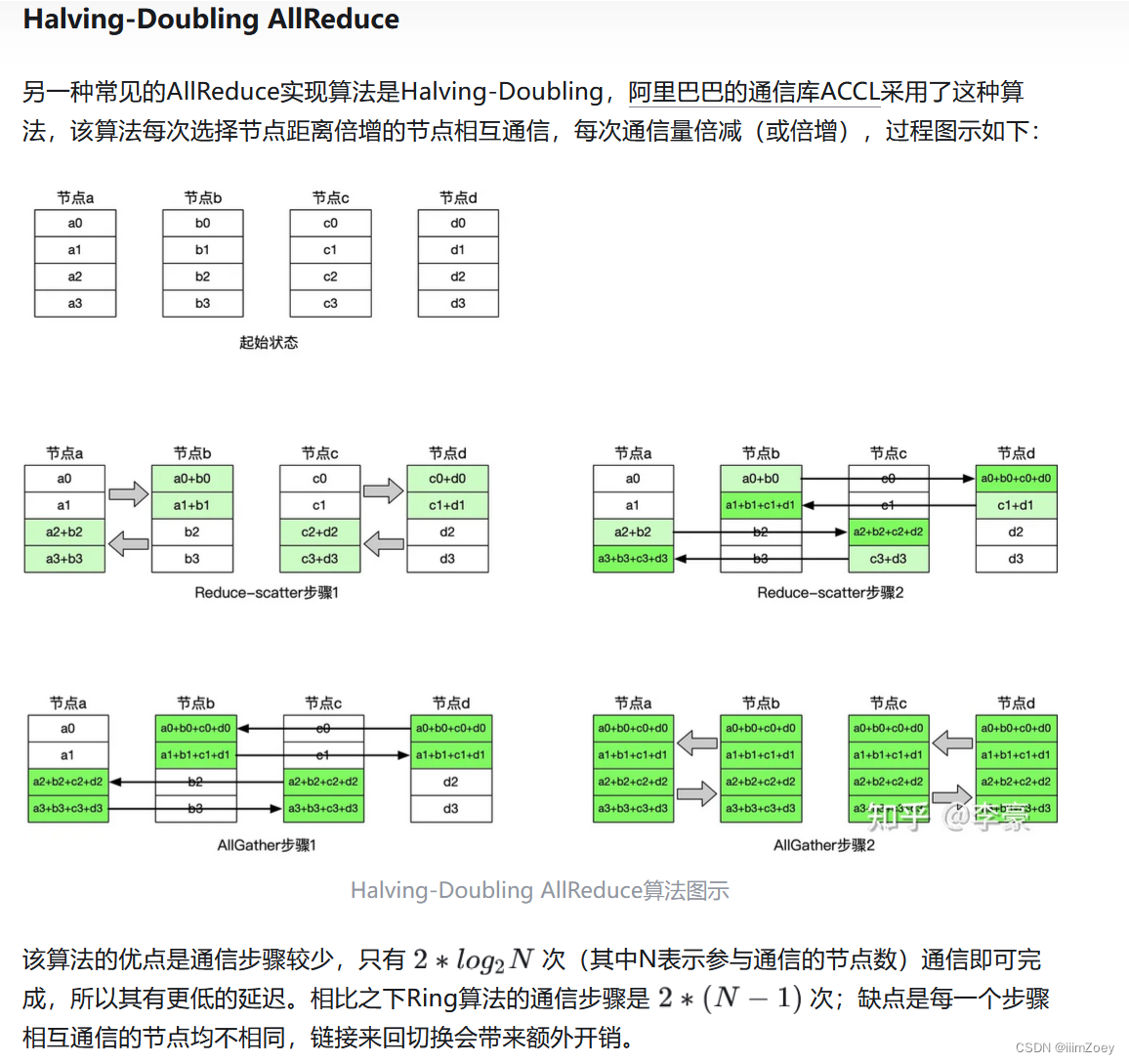
NCCL通信库
Collective Operations — NCCL 2.19.3 documentation
Collective Operations
Collective operations have to be called for each rank (hence CUDA device) to form a complete collective operation. Failure to do so will result in other ranks waiting indefinitely.需要为每个秩(因此是CUDA设备)调用集体操作,以形成完整的集体操作。未能这样做将导致其他秩无限期等待
AllReduce
The AllReduce operation is performing reductions on data (for example, sum, min, max) across devices and writing the result in the receive buffers of every rank.(AllReduce 操作对跨设备的数据执行归约操作(例如求和、最小值、最大值),并将结果写入每个秩的接收缓冲区。)
In an allreduce operation between k ranks and performing a sum, each rank will provide an array Vk of N values, and receive an identical arrays S of N values, where S[i] = V0[i]+V1[i]+…+Vk-1[i].

All-Reduce operation: each rank receives the reduction of input values across ranks.
Related links: ncclAllReduce().
Broadcast
The Broadcast operation copies an N-element buffer on the root rank to all ranks.

Broadcast operation: all ranks receive data from a “root” rank.
Important note: The root argument is one of the ranks, not a device number, and is therefore impacted by a different rank to device mapping.
Related links: ncclBroadcast().
Reduce
The Reduce operation is performing the same operation as AllReduce, but writes the result only in the receive buffers of a specified root rank.
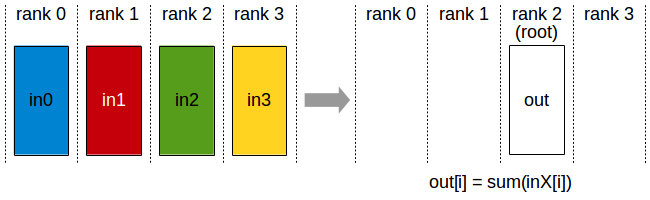
Reduce operation : one rank receives the reduction of input values across ranks.
Important note : The root argument is one of the ranks (not a device number), and is therefore impacted by a different rank to device mapping.
Note: A Reduce, followed by a Broadcast, is equivalent to the AllReduce operation.
Related links: ncclReduce().
AllGather
The AllGather operation gathers N values from k ranks into an output of size k*N, and distributes that result to all ranks.
The output is ordered by rank index. The AllGather operation is therefore impacted by a different rank or device mapping.
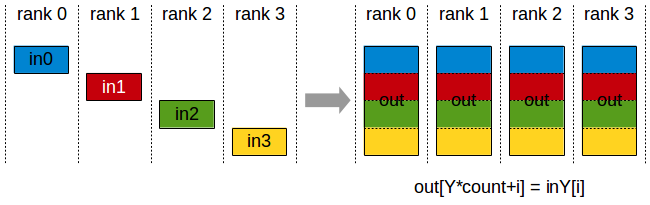
AllGather operation: each rank receives the aggregation of data from all ranks in the order of the ranks.
Note: Executing ReduceScatter, followed by AllGather, is equivalent to the AllReduce operation.
Related links: ncclAllGather().
ReduceScatter
The ReduceScatter operation performs the same operation as the Reduce operation, except the result is scattered in equal blocks between ranks, each rank getting a chunk of data based on its rank index.
The ReduceScatter operation is impacted by a different rank or device mapping since the ranks determine the data layout.
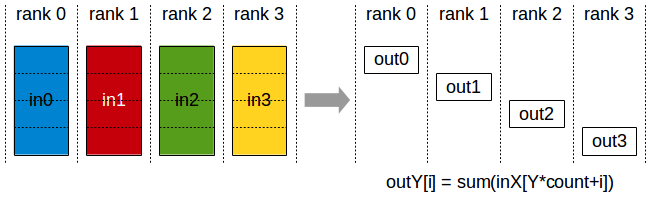
Reduce-Scatter operation: input values are reduced across ranks, with each rank receiving a subpart of the result.
Related links: ncclReduceScatter()
以上是存在的并行问题,接下来如何处理?
误差反向传播(Error Back Propagation, BP)算法。BP算法的基本思想是,学习过程由信号的正向传播与误差的反向传播两个过程组成。















 1751
1751











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









