






 本文详细介绍了A*巡逻算法的工作原理,该算法结合了起点估量代价【G】和终点估量代价【H】来计算综合估量代价【F】,用于路径规划。在遇到障碍时,即使代价小也不会选择通过。算法通过排序估量代价,从最小值开始搜索,并采用发现者机制避免重复计算。这一方法在寻路问题中表现出高效性和准确性。
本文详细介绍了A*巡逻算法的工作原理,该算法结合了起点估量代价【G】和终点估量代价【H】来计算综合估量代价【F】,用于路径规划。在遇到障碍时,即使代价小也不会选择通过。算法通过排序估量代价,从最小值开始搜索,并采用发现者机制避免重复计算。这一方法在寻路问题中表现出高效性和准确性。
A*巡逻算法:根据估量代价,起点估量代价和终点估量代价来寻路,如果遇到障碍物的话,即便代价再小也不会去寻路。(估量代价:可以理解为从某一点到终点所用的距离)
先排序,排序出来最小的估量代价。从最小的估量代价为起点再计算估量代价。以起点作为中心发散的不再计算。
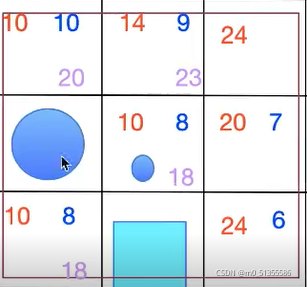
当过中心格子的放到列表里面,不参与综合估量代价计算
发现者机制,一个格子被发现回溯机制
起点估量代价【G】+终点估量代价【H】=综合估量代价【F】

A*巡逻算法:根据估量代价,起点估量代价和终点估量代价来寻路,如果遇到障碍物的话,即便代价再小也不会去寻路。(估量代价:可以理解为从某一点到终点所用的距离)
先排序,排序出来最小的估量代价。从最小的估量代价为起点再计算估量代价。以起点作为中心发散的不再计算。
当过中心格子的放到列表里面,不参与综合估量代价计算
发现者机制,一个格子被发现回溯机制
起点估量代价【G】+终点估量代价【H】=综合估量代价【F】
 1240
1240

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























