







1.问题引入
有如下R(5,4)矩阵:("-"表示用户没有打分)
其中打分矩阵R(n,m)是n行和m列,n表示user个数,m表示item个数。
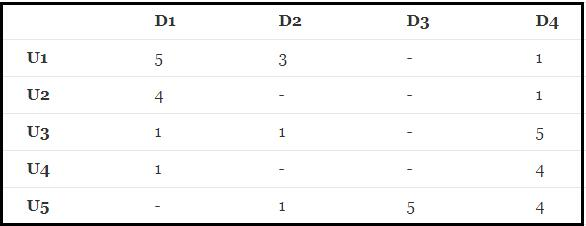
想要根据目前的矩阵R对未打分的商品进行评分的预测。为了解决这个问题,就用到了矩阵分解的方法。
2.问题分析
2.1构造损失函数
为了求出未打分的值,可以将矩阵R(n,m)分解为P(n,k)*Q(K,m),所以可以得到一个预测值
R
^
=
P
∗
Q
\hat{R}=P*Q
R^=P∗Q,来预测矩阵R,那么此时我们的问题就转换成了如何令
R
^
\hat{R}
R^与R最为接近,由此我们引入了损失函数的概念,即让
R
^
−
R
\hat{R}-R
R^−R变小,当小到一定程度后我们即可认为
R
^
≈
R
\hat{R}\approx{R}
R^≈R,为了简化计算(令该式子始终大于0),我们给其加入了一个平方变为
L
o
s
s
(
P
,
Q
)
=
1
2
(
R
−
R
^
)
2
=
1
2
(
∑
i
=
1
m
∑
j
=
1
n
(
R
i
j
−
∑
s
=
1
k
P
i
s
Q
j
s
)
)
2
Loss(P,Q)=\frac{1}{2}(\hat{R-R})^2=\frac{1}{2}(\sum_{i=1}^{m}\sum_{j=1}^{n}({R_{ij}-\sum_{s=1}^{k}P_{is}Q_{js}}))^{2}
Loss(P,Q)=21(R−R^)2=21(i=1∑mj=1∑n(Rij−s=1∑kPisQjs))2
2.1梯度下降
梯度下降法的核心思想即是沿函数的导数方向的不断改变自身参数,从到最终能到达最低点。梯度下降法的一些注意事项在多元线性回归中做了一些介绍,有兴趣可以查看。
故运用梯度下降法,先求其偏导数:
∂
∂
P
i
k
L
(
P
,
Q
)
\frac{\partial}{\partial{P_{ik}}}L(P,Q)
∂Pik∂L(P,Q)
=
1
2
(
R
i
j
−
∑
k
=
1
k
P
i
k
Q
k
j
)
∗
2
∗
(
−
1
)
∗
(
∂
∑
k
=
1
k
P
i
k
Q
k
j
)
∂
P
i
k
)
=\frac{1}{2}(R_{ij}-\sum_{k=1}^{k}P_{ik}Q_{kj})*2*(-1)*(\frac{\partial{\sum_{k=1}^{k}P_{ik}Q_{kj}})}{\partial{P_{ik}}})
=21(Rij−∑k=1kPikQkj)∗2∗(−1)∗(∂Pik∂∑k=1kPikQkj))
=
−
(
R
i
j
−
∑
k
=
1
k
P
i
k
Q
k
j
)
Q
k
j
=-(R_{ij}-\sum_{k=1}^{k}P_{ik}Q_{kj})Q_{kj}
=−(Rij−∑k=1kPikQkj)Qkj
∂
∂
Q
k
j
L
(
P
,
Q
)
\frac{\partial}{\partial{Q_{kj}}}L(P,Q)
∂Qkj∂L(P,Q)
=
1
2
(
R
i
j
−
∑
k
=
1
k
P
i
k
Q
k
j
)
∗
2
∗
(
−
1
)
∗
(
∂
∑
k
=
1
k
P
i
k
Q
k
j
)
∂
P
k
j
)
=\frac{1}{2}(R_{ij}-\sum_{k=1}^{k}P_{ik}Q_{kj})*2*(-1)*(\frac{\partial{\sum_{k=1}^{k}P_{ik}Q_{kj}})}{\partial{P_{kj}}})
=21(Rij−∑k=1kPikQkj)∗2∗(−1)∗(∂Pkj∂∑k=1kPikQkj))
=
−
(
R
i
j
−
∑
k
=
1
k
P
i
k
Q
k
j
)
P
i
k
=-(R_{ij}-\sum_{k=1}^{k}P_{ik}Q_{kj})P_{ik}
=−(Rij−∑k=1kPikQkj)Pik
应用梯度下降法不断修改当前参数值:
P
i
k
=
P
i
k
−
α
∗
(
−
(
R
i
j
−
∑
k
=
1
k
P
i
k
Q
k
j
)
Q
k
j
)
P_{ik}=P_{ik}-\alpha*(-(R_{ij}-\sum_{k=1}^{k}P_{ik}Q_{kj})Q_{kj})
Pik=Pik−α∗(−(Rij−∑k=1kPikQkj)Qkj)
=
P
i
k
+
α
(
R
i
j
−
∑
k
=
1
k
P
i
k
Q
k
j
)
Q
k
j
)
=P_{ik}+\alpha(R_{ij}-\sum_{k=1}^{k}P_{ik}Q_{kj})Q_{kj})
=Pik+α(Rij−∑k=1kPikQkj)Qkj)
Q
k
j
=
P
i
k
−
α
∗
(
−
(
R
i
j
−
∑
k
=
1
k
P
i
k
Q
k
j
)
P
i
k
)
Q_{kj}=P_{ik}-\alpha*(-(R_{ij}-\sum_{k=1}^{k}P_{ik}Q_{kj})P_{ik})
Qkj=Pik−α∗(−(Rij−∑k=1kPikQkj)Pik)
=
P
i
k
+
α
(
R
i
j
−
∑
k
=
1
k
P
i
k
Q
k
j
)
P
i
k
)
=P_{ik}+\alpha(R_{ij}-\sum_{k=1}^{k}P_{ik}Q_{kj})P_{ik})
=Pik+α(Rij−∑k=1kPikQkj)Pik)
(
α
\alpha
α为learning rate ,即学习率)
2.3正则化
当训练的数据不够时或特征数量大于样本数量时,就会出现过拟合的情况,我们为了解决过拟合,就会采用正则化的手段或者减少一些非必要的样本特征。常用的有L1范数和L2范数。
①LP范数不是一个范数,而是一组范数
∣
∣
x
∣
∣
p
=
(
∑
i
n
∣
x
i
∣
p
)
1
p
||x||_{p}=(\sum_{i}^{n}|x_{i}|^{p})^{\frac{1}{p}}
∣∣x∣∣p=(∑in∣xi∣p)p1
②p=1时,几位L1范数
∣
∣
x
1
∣
∣
=
∑
i
=
1
n
∣
x
i
∣
||x_{1}||=\sum_{i=1}^{n}|x_{i}|
∣∣x1∣∣=∑i=1n∣xi∣
②L2范数,平方再开方,表示向量的距离。
∣
∣
x
2
∣
∣
=
(
∑
i
=
1
n
∣
x
i
∣
2
)
1
2
||x_{2}||=(\sum_{i=1}^{n}|x_{i}|^{2})^{\frac{1}{2}}
∣∣x2∣∣=(∑i=1n∣xi∣2)21
L1正则化:
J
(
θ
)
=
1
2
m
[
∑
i
=
1
m
(
y
i
−
h
θ
(
x
i
)
)
2
+
λ
∑
j
=
1
n
∣
θ
j
∣
]
J({\theta})=\frac{1}{2m}[\sum_{i=1}^{m}{(y^{i}-h_{\theta}(x^{i}))^{2}+\lambda\sum_{j=1}{n}|\theta_{j}|}]
J(θ)=2m1[i=1∑m(yi−hθ(xi))2+λj=1∑n∣θj∣]
L2正则化:
J
(
θ
)
=
1
2
m
[
∑
i
=
1
m
(
y
i
−
h
θ
(
x
i
)
)
2
+
λ
∑
j
=
1
n
θ
j
2
]
J({\theta})=\frac{1}{2m}[\sum_{i=1}^{m}{(y^{i}-h_{\theta}(x^{i}))^{2}+\lambda\sum_{j=1}{n}\theta_{j}^{2}}]
J(θ)=2m1[i=1∑m(yi−hθ(xi))2+λj=1∑nθj2]
式子中m为样本数量,n为特征个数。
3.代码实现
import numpy as np
import matplotlib.pyplot as plt
R=np.array([[5,3,0,1],
[4,0,0,1],
[1,1,0,5],
[1,0,0,4],
[0,1,5,4]])
M=R.shape[0]
N=R.shape[1]
K=2
P=np.random.rand(M,K)
Q=np.random.rand(K,N)
print(P)
print(Q)
[[0.65360868 0.08726216]
[0.69762591 0.03076026]
[0.88861613 0.75595254]
[0.31559948 0.49104854]
[0.33077934 0.40914307]]
[[0.68124148 0.49563369 0.14058849 0.73546283]
[0.31494592 0.86798718 0.48578754 0.95628464]]
L o s s = 1 2 ( R − P Q ) 2 = 1 2 ( ∑ i = 1 m ∑ j = 1 n ( R i j − ∑ s = 1 k P i s Q j s ) ) 2 Loss=\frac{1}{2}(R-PQ)^{2}=\frac{1}{2}(\sum_{i=1}^{m}\sum_{j=1}^{n}({R_{ij}-\sum_{s=1}^{k}P_{is}Q_{js}}))^{2} Loss=21(R−PQ)2=21(i=1∑mj=1∑n(Rij−s=1∑kPisQjs))2
#损失函数
def cost(R,P,Q):
e=0
for i in range(R.shape[0]):
for j in range(R.shape[1]):
if(R[i,j]>0):
e+=(R[i,j]-np.dot(P[i,:],Q[:,j]))**2
return e/2
L2正则化:
L
o
s
s
=
1
2
(
R
−
P
Q
)
2
=
1
2
(
∑
i
=
1
m
∑
j
=
1
n
)
R
i
j
−
∑
s
=
1
k
P
i
s
Q
j
s
)
2
+
λ
2
∑
s
=
1
k
(
P
i
k
2
+
Q
k
j
2
)
Loss=\frac{1}{2}(R-PQ)^{2}=\frac{1}{2}(\sum_{i=1}^{m}\sum_{j=1}^{n}){R_{ij}-\sum_{s=1}^{k}P_{is}Q_{js}})^{2}+\frac{\lambda}{2}\sum_{s=1}{k}({P_{ik}^{2}}+Q_{kj}^{2})
Loss=21(R−PQ)2=21(i=1∑mj=1∑n)Rij−s=1∑kPisQjs)2+2λs=1∑k(Pik2+Qkj2)
#损失函数正则
def cost_re(R,P,Q,lambda1):
e=0
for i in range(R.shape[0]):
for j in range(R.shape[1]):
if(R[i][j]>0):
e+=(R[i,j]-np.dot(P[i,:],Q[:,j]))**2
for k in range(P.shape[1]):
e+=lambda1*(P[i,k]**2+Q[k,j]**2)/2
return e/2
对损失函数求偏导:
∂
∂
P
i
k
L
(
P
,
Q
)
\frac{\partial}{\partial{P_{ik}}}L(P,Q)
∂Pik∂L(P,Q)
=
1
2
(
R
i
j
−
∑
k
=
1
k
P
i
k
Q
k
j
)
∗
2
∗
(
−
1
)
∗
(
∂
∑
k
=
1
k
P
i
k
Q
k
j
)
∂
P
i
k
)
=\frac{1}{2}(R_{ij}-\sum_{k=1}^{k}P_{ik}Q_{kj})*2*(-1)*(\frac{\partial{\sum_{k=1}^{k}P_{ik}Q_{kj}})}{\partial{P_{ik}}})
=21(Rij−∑k=1kPikQkj)∗2∗(−1)∗(∂Pik∂∑k=1kPikQkj))
=
−
(
R
i
j
−
∑
k
=
1
k
P
i
k
Q
k
j
)
Q
k
j
=-(R_{ij}-\sum_{k=1}^{k}P_{ik}Q_{kj})Q_{kj}
=−(Rij−∑k=1kPikQkj)Qkj
∂
∂
Q
k
j
L
(
P
,
Q
)
\frac{\partial}{\partial{Q_{kj}}}L(P,Q)
∂Qkj∂L(P,Q)
=
1
2
(
R
i
j
−
∑
k
=
1
k
P
i
k
Q
k
j
)
∗
2
∗
(
−
1
)
∗
(
∂
∑
k
=
1
k
P
i
k
Q
k
j
)
∂
P
k
j
)
=\frac{1}{2}(R_{ij}-\sum_{k=1}^{k}P_{ik}Q_{kj})*2*(-1)*(\frac{\partial{\sum_{k=1}^{k}P_{ik}Q_{kj}})}{\partial{P_{kj}}})
=21(Rij−∑k=1kPikQkj)∗2∗(−1)∗(∂Pkj∂∑k=1kPikQkj))
=
−
(
R
i
j
−
∑
k
=
1
k
P
i
k
Q
k
j
)
P
i
k
=-(R_{ij}-\sum_{k=1}^{k}P_{ik}Q_{kj})P_{ik}
=−(Rij−∑k=1kPikQkj)Pik
梯度下降法:
P
i
k
=
P
i
k
−
α
∗
(
−
(
R
i
j
−
∑
k
=
1
k
P
i
k
Q
k
j
)
Q
k
j
)
P_{ik}=P_{ik}-\alpha*(-(R_{ij}-\sum_{k=1}^{k}P_{ik}Q_{kj})Q_{kj})
Pik=Pik−α∗(−(Rij−∑k=1kPikQkj)Qkj)
=
P
i
k
+
α
(
R
i
j
−
∑
k
=
1
k
P
i
k
Q
k
j
)
Q
k
j
)
=P_{ik}+\alpha(R_{ij}-\sum_{k=1}^{k}P_{ik}Q_{kj})Q_{kj})
=Pik+α(Rij−∑k=1kPikQkj)Qkj)
Q
k
j
=
P
i
k
−
α
∗
(
−
(
R
i
j
−
∑
k
=
1
k
P
i
k
Q
k
j
)
P
i
k
)
Q_{kj}=P_{ik}-\alpha*(-(R_{ij}-\sum_{k=1}^{k}P_{ik}Q_{kj})P_{ik})
Qkj=Pik−α∗(−(Rij−∑k=1kPikQkj)Pik)
=
P
i
k
+
α
(
R
i
j
−
∑
k
=
1
k
P
i
k
Q
k
j
)
P
i
k
)
=P_{ik}+\alpha(R_{ij}-\sum_{k=1}^{k}P_{ik}Q_{kj})P_{ik})
=Pik+α(Rij−∑k=1kPikQkj)Pik)
#梯度下降
def grad(R,P,Q,lr,epochs):
costList=[]
for s in range(epochs+1):
for i in range(R.shape[0]):
for j in range(R.shape[1]):
if(R[i][j]>0):
e=R[i,j]-np.dot(P[i,:],Q[:,j])
for k in range(P.shape[1]):
grad_p=e*Q[k][j]
grad_q=e*P[i][k]
P[i][k]=P[i][k]+lr*grad_p
Q[k][j]=Q[k][j]+lr*grad_q
if s%50==0:
e=cost(R,P,Q)
costList.append(e)
#print(e)
return P,Q,costList
lr=0.0001
epochs=10000
p,q,costList=grad(R,P,Q,lr,epochs)
print(np.dot(p,q))
[[5.06116901 2.87426131 2.43375669 1.00254423]
[3.96425112 2.26334177 2.08974137 0.96504113]
[1.0366021 0.90360134 5.30277467 4.91333664]
[0.99043153 0.81279639 4.2952649 3.93863408]
[1.64541544 1.19616657 4.78417292 4.23883696]]
x=np.linspace(0,10000,201)
plt.plot(x,costList,'r')
plt.xlabel('epochs')
plt.ylabel('cost')
plt.show()

加入正则项后:
P
i
k
=
P
i
k
−
α
∗
(
−
(
R
i
j
−
∑
k
=
1
k
P
i
k
Q
k
j
)
P
i
k
)
+
λ
P
i
k
P_{ik}=P_{ik}-\alpha*(-(R_{ij}-\sum_{k=1}^{k}P_{ik}Q_{kj})P_{ik})+\lambda{P_{ik}}
Pik=Pik−α∗(−(Rij−∑k=1kPikQkj)Pik)+λPik
=
P
i
k
+
α
(
R
i
j
−
∑
k
=
1
k
P
i
k
Q
k
j
)
P
i
k
)
−
λ
P
i
k
=P_{ik}+\alpha(R_{ij}-\sum_{k=1}^{k}P_{ik}Q_{kj})P_{ik})-\lambda{P_{ik}}
=Pik+α(Rij−∑k=1kPikQkj)Pik)−λPik
Q
k
j
=
Q
k
j
−
α
∗
(
−
(
R
i
j
−
∑
k
=
1
k
P
i
k
Q
k
j
)
Q
k
j
)
+
λ
Q
k
j
Q_{kj}=Q_{kj}-\alpha*(-(R_{ij}-\sum_{k=1}^{k}P_{ik}Q_{kj})Q_{kj})+\lambda{Q_{kj}}
Qkj=Qkj−α∗(−(Rij−∑k=1kPikQkj)Qkj)+λQkj
=
P
i
k
+
α
(
R
i
j
−
∑
k
=
1
k
P
i
k
Q
k
j
)
Q
k
j
)
−
λ
Q
k
j
=P_{ik}+\alpha(R_{ij}-\sum_{k=1}^{k}P_{ik}Q_{kj})Q_{kj})-\lambda{Q_{kj}}
=Pik+α(Rij−∑k=1kPikQkj)Qkj)−λQkj
#梯度下降(正则)
def grad_re(R,P,Q,lr,epochs,lambda1):
costList=[]
for s in range(epochs+1):
for i in range(R.shape[0]):
for j in range(R.shape[1]):
if(R[i][j]>0):
e=R[i,j]-np.dot(P[i,:],Q[:,j])
for k in range(P.shape[1]):
grad_p=e*Q[k][j]#求梯度
grad_q=e*P[i][k]
#对PQ同时进行梯度下降,改变其值
P[i][k]=P[i][k]+lr*grad_p-lambda1*P[i][k]
Q[k][j]=Q[k][j]+lr*grad_q-lambda1*Q[k][j]
if s%50==0:#求损失
e=cost_re(R,P,Q,lambda1)
costList.append(e)
#print(e)
return P,Q,costList
lambda1=0.0001
p,q,costList=grad_re(R,P,Q,0.003,epochs,lambda1)
print(np.dot(p,q))
[[4.92262848 2.9460198 2.02962105 1.00548811]
[3.9420148 2.37520018 1.85600337 0.99804788]
[1.00407789 0.99148638 6.03037773 4.90035828]
[0.99660486 0.90775439 4.8875762 3.94603309]
[1.15092516 1.00009806 4.95103649 3.97741499]]
x=np.linspace(0,10000,201)
plt.plot(x,costList,'r')
plt.xlabel('epochs')
plt.ylabel('cost')
plt.show()
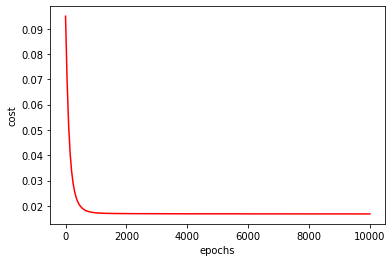
通过观察代价函数随迭代步数的变化图可以看出:进行正则化后的代价函数的图像比没有进行正则化的图像较为圆滑了些许,可以得出正则化确实是一种解决过拟合问题的一种手段。
此外,除了正则化以外,还可以通过增加样本数据集的数量或者减少样本特征,抛弃一些不必要的样本特征来避免过拟合。














 1762
1762











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









