







爬取电影评论
爬取的网址如下: 时光网.
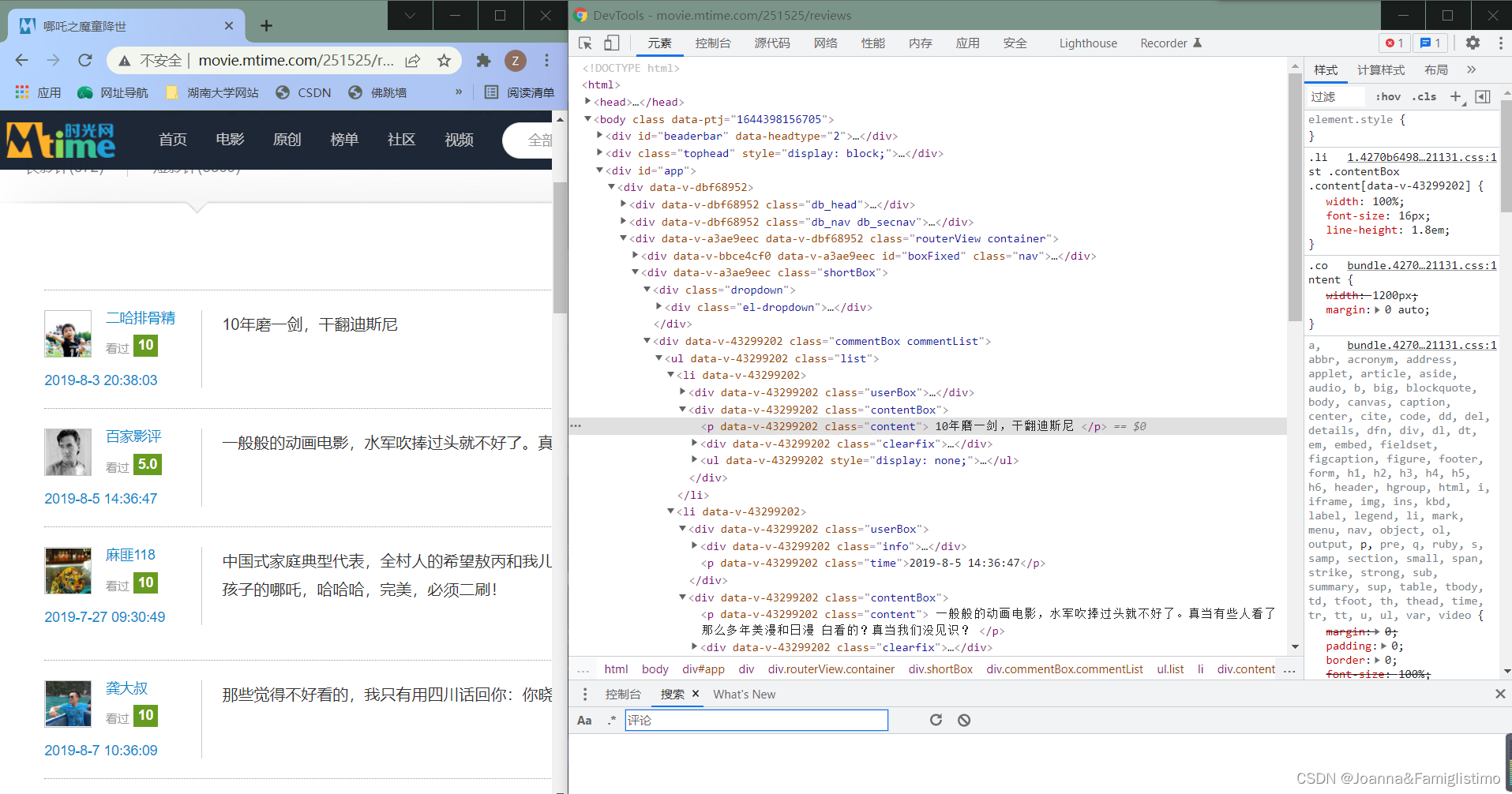
我们可以看到,评论内容在的地址可以用 CSS 选择器表示为 “ul.list > li > div.contentBox > p.content” 的 p 标签
根据以前的知识,我们可以通过 requests 库获取网页源代码,然后使用 BeautifulSoup 库
将其解析成 BeautifulSoup 对象,接着调用 select() 方法提取出评论内容。
代码如下:
import requests
from bs4 import BeautifulSoup
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'
}
res = requests.get('http://movie.mtime.com/251525/reviews', headers=headers)
soup = BeautifulSoup(res.text, 'html.parser')
comments = soup.select('ul.list > li > div.contentBox > p.content')
for comment in comments:
print(comment.text)
如果你运行一下上面的代码就会发现,输出结果为空。所以,我们的代码应该是有问题的,我们从后往前一次排查一下。首先导致输出结果为空的原因可能是 comments 为空列表。我们将 comments 打印出来看看:
print(comments)
# 输出:[]
果然,comments 是空列表,说明可能 comments = soup.select(‘ul.list > li > div.contentBox > p.content’) 这行代码没有找到评论的数据。可是,仔细检查一下就能发现,这行代码是正确的,前面的网址也没错,整个代码看上去都没有问题。
那这就奇了怪了,难道是网页源代码中根本就没有评论的数据吗?🤔
我们来验证一下:首先我们在网页空白处点击鼠标右键,接着在弹出的菜单中点击 显示网页源代码,然后按下 CTRL + F (Mac 电脑为 Command + F)搜索某条评论中的内容。

搜索结果数为 0,果然,网页的 HTML 源代码中并没有评论数据!
那么,为什么在网页开发者工具中有评论的数据,而网页源代码中就没有呢?
这是因为,像电影评论这样的信息是瞬息万变的,可能短短数小时内就多出几百、上千条。如果将每条评论的数据,都通过 HTML 代码的形式写进网页中,那么评论每发生一次变化,就要相应地改变代码,非常繁琐。
那这种实时改变的数据是怎样展现到我们面前的呢?这就要用到 API了——网页可以通过 API 获取数据,实时更新内容。API 即应用程序接口,它规定了网页与服务器之间可以交互什么数据、通过什么样的方式进行交互。
为了找到评论的真正藏身之地,我们得先来看看开发者工具中的 Network。
初识Network
Network 记录的是从打开浏览器的开发者工具到网页加载完毕之间的所有请求。如果你在网页加载完毕后打开,里面可能就是空的,我们开着开发者工具刷新一下网页即可。
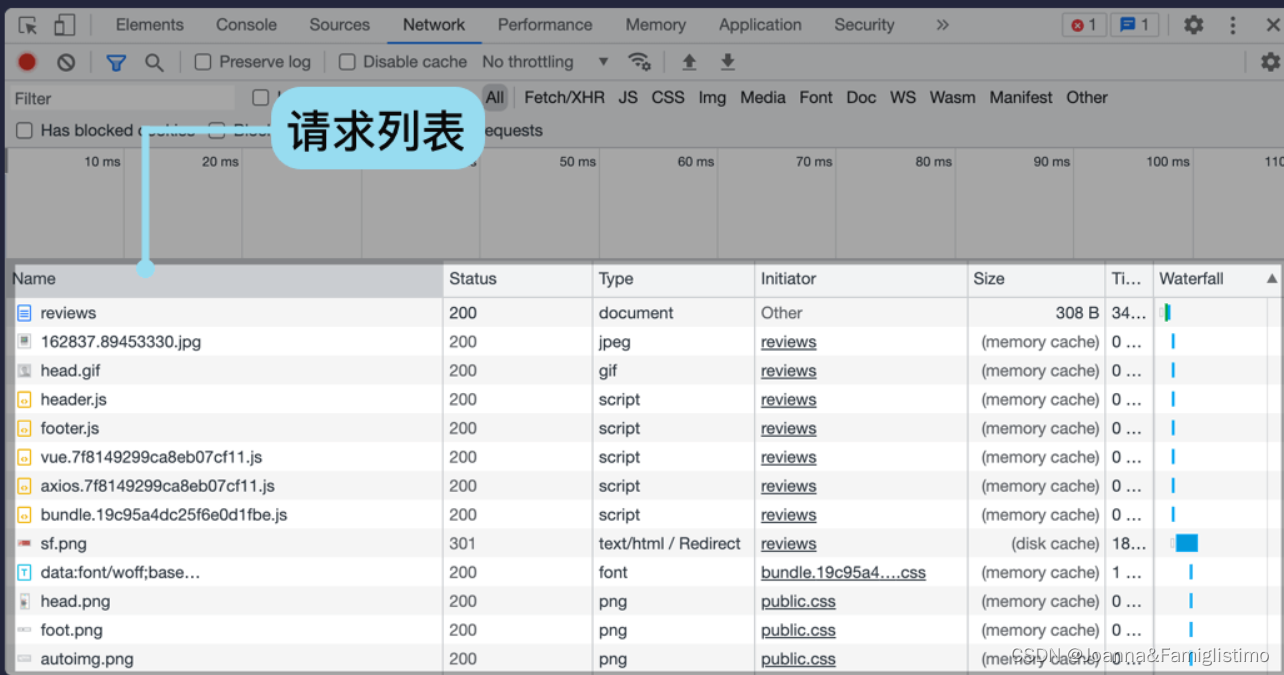
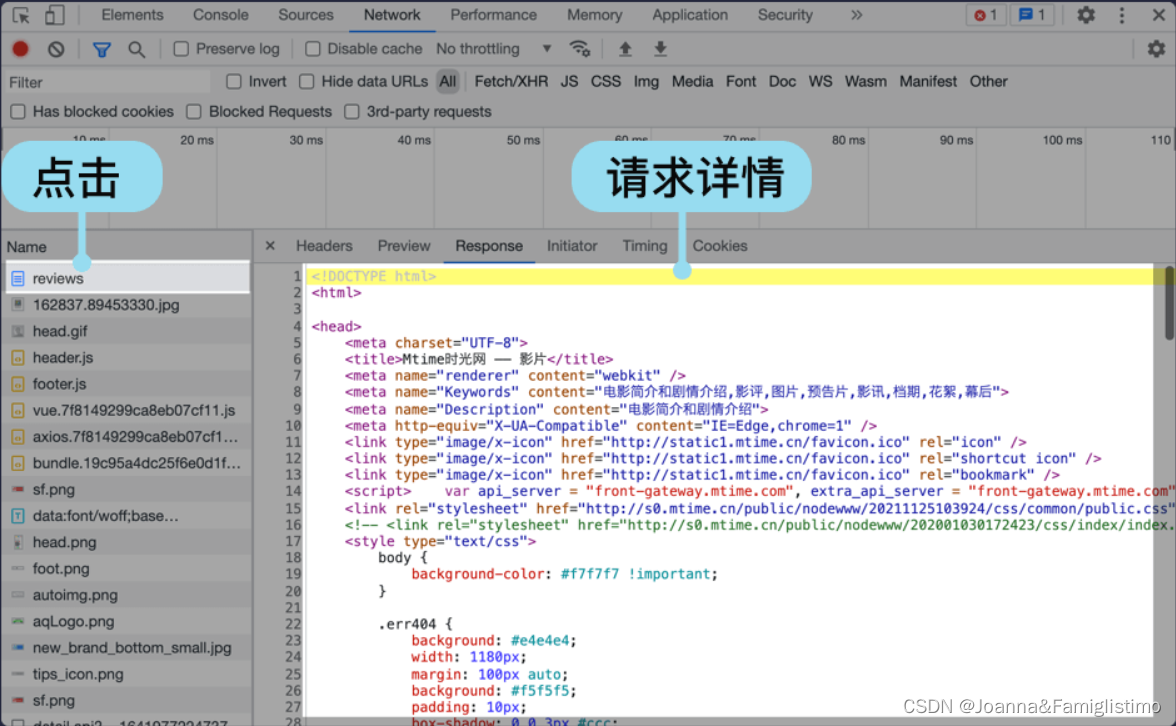
我们还可以点击每一个请求,查看每个请求的详细信息。详细信息里的 Response(响应)里是服务器返回的内容。第一个请求是网页,它的响应是网页源代码,即我们使用 requests.get() 获取到的 res.text 内容。
因为一次性加载整个网站很慢,为了提升网页加载速度,有些网站将网站的骨架和内容拆分开,
加载骨架后再通过多个请求获取内容,最终组成完整的网站。而有些老的网站或轻量级网站,
仍然是一次性返回整个网站的内容,比如豆瓣。
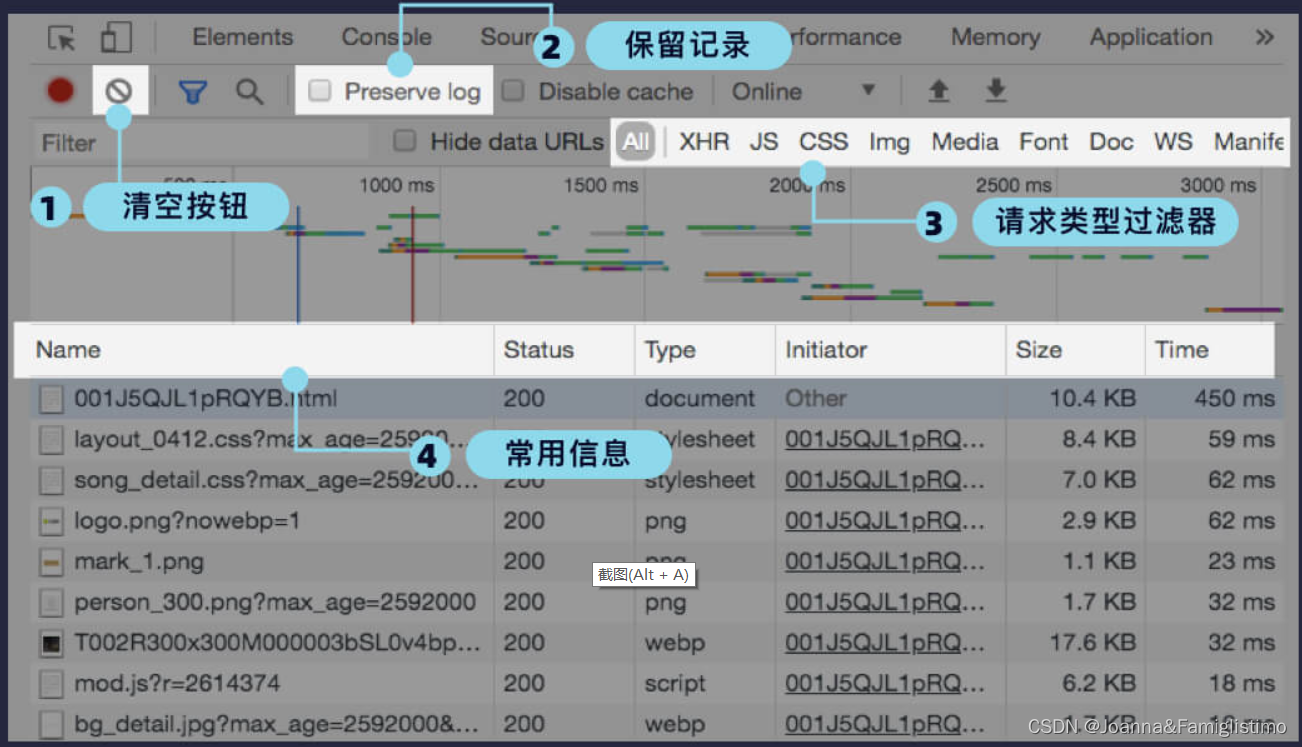
在写爬虫的过程中,我们会经常用到开发者工具中的 Network 面板。接下来我们再来看看 Network 面板 中有哪些常用功能:
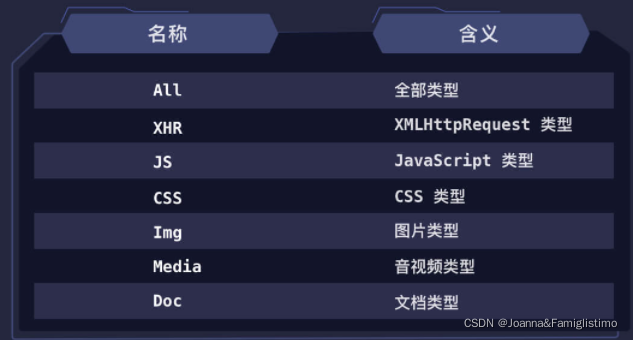
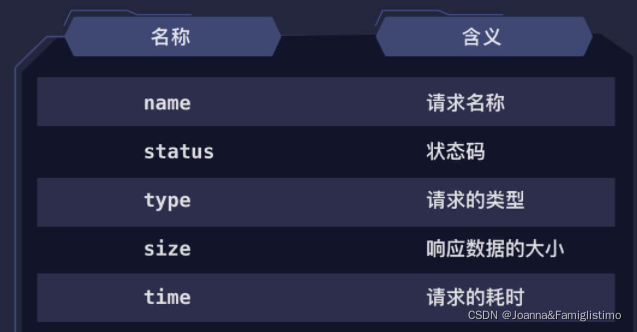
在所有请求类型中,有一类非常重要的类型叫做 XHR。下面介绍一下XHR
XHR
上文我们说过,有些网站为了提升网页加载速度,会先加载骨架,再加载详细的内容。
而加载详细内容的过程,就用到了 XHR 技术。 XHR 全称 XMLHttpRequest,是浏览器
内置的对象。浏览器想要在不刷新网页前提下加载、更新局部内容时,必须通过 XHR
向存放数据的服务器发送请求。反过来说,XHR 类型请求里,就藏着我们需要的搜索结果。
接下来,我们一起在 XHR 中寻找评论。
首先点击 Network 中的 XHR 过滤其他类型的请求。可以看到,仍然有很多的请求,我们要从中找到评论数据。笨一点的方法是一条一条地查看,直到找到评论的数据,但这样耗时又耗力。
聪明一点的方法是通过名称来找,既然是评论的数据,请求名称中可能会带有 comment(评论),这样我们就能极大地缩小查找范围。
还有一个小技巧是:由于数据是分页加载,我们可以先将请求记录清空,再点击下方分页导航的第 2 页,这样,加载第 2 页评论的请求说不定就会被我们“守株待兔”逮个正着。
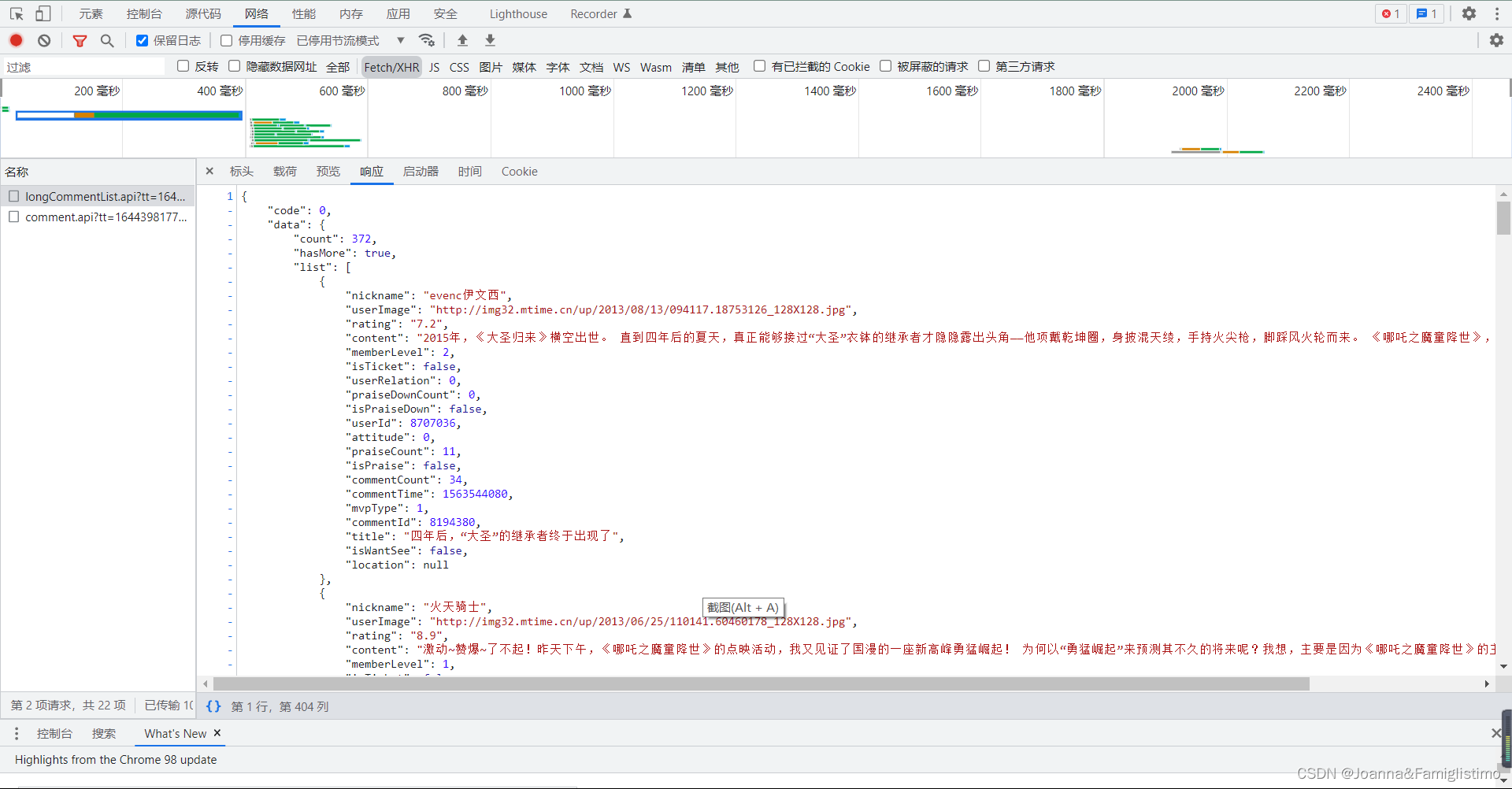 评论数据就在 data 下的 list 中,list 中有 0-19 的索引,每个索引展开都有 content,nickname 等信息。对照网页实际内容,我们可以确认影评的数据就是 content 中的信息。
评论数据就在 data 下的 list 中,list 中有 0-19 的索引,每个索引展开都有 content,nickname 等信息。对照网页实际内容,我们可以确认影评的数据就是 content 中的信息。
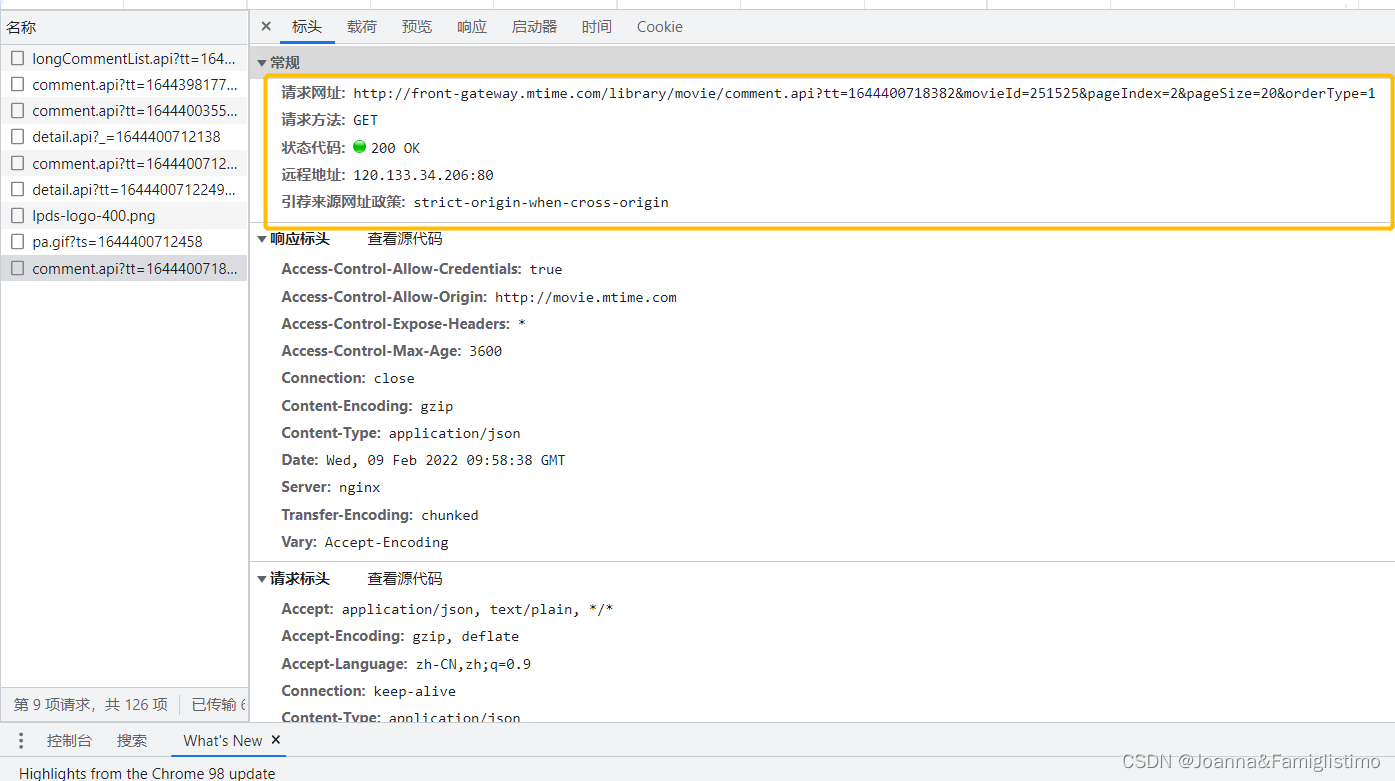
从图中我们可以看到,时光网规定了需要通过 GET 方法,向 Request URL 发送请求。点击第二页查看电影评论的行为,实际上是浏览器帮我们自动填充查询参数,向时光网获取短影评数据,参数详情为:
id 为 251525 (movieId=251525) ;
第 2 页内容 (pageIndex=2);
每页 20 条 (pageSize=20)。
遵循某种规则向指定 URL 发送请求,从而获得相应数据的过程,就是 通过 API 获取数据。
下面的 Status Code 是状态码,之前说过,如果是 200,表示成功。其他信息我们无需关注。
另外,为了防止被网站反爬,我们还要在 Headers 中观察一下 Request Headers(请求头),有两个参数要注意。

user-agent 是将爬虫伪装成浏览器;另外一个 referer 字段,字面意思是“发起者,发送人”
用来验证这个请求的发起方是否合法。也就是说,服务器要验证这个请求是由谁发出的,只接受
从特写网页上发出该请求,比如这里就是时光网的网址。如果这个字段不加,可能会爬取失败。
既然找到了获取评论数据的真正链接,以及相关的请求头参数,接下来我们就可以试着通过爬虫来爬取数据了。我们仍然使用 requests.get() 方法获取刚才找到的 API 地址,但 headers 参数要加上 referer 的信息,假装是由时光网自身发起的请求,代码如下:
import requests
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36',
'referer': 'http://movie.mtime.com/'
}
res = requests.get('http://front-gateway.mtime.com/library/movie/comment.api?tt=1641893701852&movieId=251525&pageIndex=2&pageSize=20&orderType=1', headers=headers)
print(res.text)
上面代码中的链接中,comment.api? 后面的内容,是我们前面说过的 查询字符串。这次的查询字符串内容有些长,直接放在链接里有些乱。好在 requests.get() 方法提供了 params 参数,能让我们以字典的形式传递链接的查询字符串参数,使代码看上去更加的整洁明了。我们看一下官方文档的介绍:
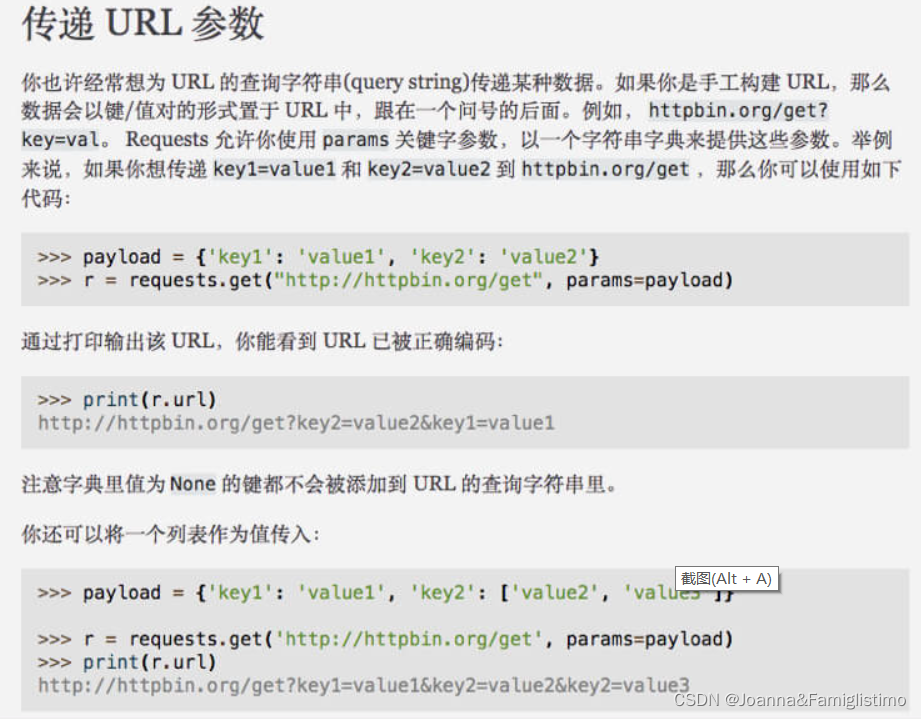 也就是说,链接中的 tt=1641893701852&movieId=251525&pageIndex=2&pageSize=20&orderType=1,可以拆分成一个字典:
也就是说,链接中的 tt=1641893701852&movieId=251525&pageIndex=2&pageSize=20&orderType=1,可以拆分成一个字典:
params = {
"tt": "1641893701852",
"movieId": "251525",
"pageIndex": "2",
"pageSize": "20",
"orderType": "1"
}
res = requests.get(
'http://front-gateway.mtime.com/library/movie/comment.api',
params=params,
headers=headers
)
五个参数中,movieId pageIndex pageSize 的意义我们可以根据字面意思猜到,
应该分别代表 电影在时光网中的 ID,评论的第x页 和 每页评论数。
电影的页面地址 中的 251525 和 movieId 的值一致,可以作为佐证。
那剩下的 orderType 和 tt 是什么?
orderType 字面意思是排序方式,而我们发现,短影评页的右上方的确是有这个选项的。
值为 1 代表的应该就是按最热排序。打开开发者工具后,点击按最新排序,就可以立即看到新请求中的 orderType 值是 2。
tt是时间戳,代表当前时间,可能是为了验证请求是否过期——如果当前时间戳与服务器时间差距过大,服务器可能认为是非法的过期请求,从而拒绝返回结果(猜想而已)。
import requests
import time
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36',
'referer': 'http://movie.mtime.com/'
}
params = {
# 将当前时间戳转为毫秒后取整,作为 tt 的值
"tt": "{}".format(int(time.time() * 1000)),
"movieId": "251525",
"pageIndex": "2",
"pageSize": "20",
"orderType": "1"
}
res = requests.get(
'http://front-gateway.mtime.com/library/movie/comment.api',
params=params,
headers=headers)
print(res.text)
这样就能看到打印的结果:
{
"code": 0,
"data": {
"count": 3307,
"hasMore": true,
"list": [
{
"nickname": "瀛26000",
"userImage": "https://img2.mtime.cn/u/285/2016285/7c677c7f-4503-42e9-a63f-683e9f97148c/128X128.jpg",
"rating": "8.5",
"content": "这是我看过的最有血有肉有人情味还紧跟时代潮流的一版哪吒了,没有金吒木吒只有哪吒,李靖没有让人讨厌的琵琶精小老婆,敖丙也不是奸淫掳掠无恶不作的龙二代,申公豹的口吃设计也承包了一部分笑点,太乙真人的火锅味",
...省略剩下的内容
},
...省略剩下的内容
}
从打印结果上看,res.text 是多层级的字典吗?并不是,只是长得像字典的字符串罢了,我们可以验证一下。
print(type(res.text))
# 输出:<class 'str'>
这种长得像字典的字符串,是一种名为 JSON 的数据格式。我们需要将其转换成真正的 字典/列表,才能从中提取出评论数据。所以,接下来我们介绍 JSON 来将其转换成字典/列表。
JSON
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式。 易于人阅读和编写,同时也易于机器解析和生成。
JSON 建构于两种结构:键值对的集合 和 值的有序列表,分别对应 Python 里的字典和列表,这些都是常见的数据结构。大部分现代计算机语言都支持 JSON,所以 JSON 是在编程语言之间通用的数据格式。
JSON 本质上就是一个字符串,只是该字符串符合特定的格式要求。也就是说,我们将字典、列表等用字符串的形式写出来就是 JSON,就像下面这样:
# 字典
dict = {'price': 233}
# JSON
json = '{"price": 233}'
# 列表
list = ['x', 'y', 'z']
# JSON
json = '["x", "y", "z"]'
#Python 字符串使用单引号或双引号没有区别,但 JSON 中,字符串必须使用英文的双引号来包裹。
如何解析 JSON
我们刚才获取到的字符串格式的数据,其实就是 JSON。那么我们要如何解析它呢?requests 库早就帮我们提供了方法,我们再次打开 requests 库官方文档,使用 CTRL + F (Mac 电脑上使用 CMD +F)搜索找到 JSON 响应内容,然后点击它进入介绍页。
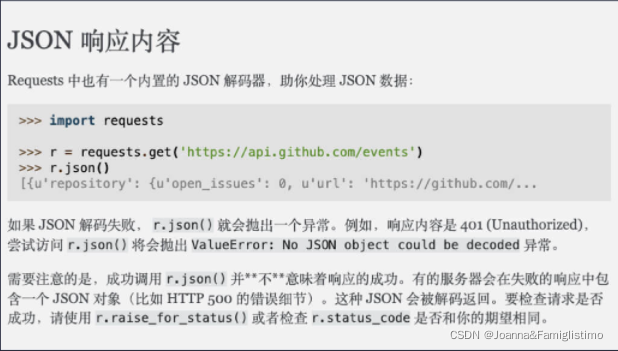
转换后的结果是 Python 中对应的字典或列表,我们便可根据 Python 的基础知识提取我们需要的数据。不再需要通过 BeautifulSoup 对网页源代码解析,然后再提取数据了。
我们试着调用一下 json() 方法,并查看它的返回值类型:
import requests
import time
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36',
'referer': 'http://movie.mtime.com/'
}
params = {
# 将当前时间戳转为毫秒后取整,作为 tt 的值
"tt": "{}".format(int(time.time() * 1000)),
"movieId": "251525",
"pageIndex": "2",
"pageSize": "20",
"orderType": "1"
}
res = requests.get(
'http://front-gateway.mtime.com/library/movie/comment.api',
params=params,
headers=headers)
print(type(res.json()))
# 输出:<class 'dict'>
result = res.json()
print(result['data']['list'][0]['content'])
# 输出:
# 这是我看过的最有血有肉有人情味还紧跟时代潮流的一版哪吒了,没有金吒木吒只有哪吒,李靖没有让人讨厌的琵琶精小老婆,敖丙也不是奸淫掳掠无恶不作的龙二代,申公豹的口吃设计也承包了一部分笑点,太乙真人的火锅味
#如果要获取该页所有的评论,只需要改一下即可
comment_list = res.json()['data']['list']
for i in comment_list:
print("用户:", i['nickname'])
print("评论:", i['content'])
修改参数 pageIndex 的值,就能获取多页的评论数据了。因为评论过多,我们以获取前 5 页的评论为例,看一下如何实现:
import requests
import time
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36',
'referer': 'http://movie.mtime.com/'
}
for num in range(1, 6):
params = {
"tt": "{}".format(int(time.time() * 1000)),
"movieId": "251525",
"pageIndex": "{}".format(num),
"pageSize": "20",
"orderType": "1"
}
res = requests.get(
'http://front-gateway.mtime.com/library/movie/comment.api',
params=params,
headers=headers)
comment_list = res.json()['data']['list']
for i in comment_list:
print("用户:", i['nickname'])
print("评论:", i['content'])
# 暂停一下,防止爬取太快被封
time.sleep(1)
上面的代码获取了前 5 页的评论数据,如果我们需要,只要控制好爬取速度防止被封,完全可以将所有的短影评全部爬取下来。
小结
根据网站是静态的还是动态的,我们爬虫的策略有所不同。静态网页使用 BeautifulSoup 解析网页源代码,动态网页直接找到加载数据的 API,从 API 中爬取数据。

简单模拟登陆
示例登录一个网站之后打开看看
POST请求
和 GET 一样,POST 也是请求方式的一种。除此之外还有 PUT、DELETE 等方式,但最常用的还是 GET 和 POST。
那么它俩的区别是什么呢?下面我给你从本质和形式上进行对比:
GET 和 POST 本质上的区别是:GET 用于获取数据,比如刷微博;POST 用于提交数据,比如登录微博。
GET 和 POST 形式上的区别是:GET 的参数显示在请求地址里;POST 的参数隐藏在 Form Data 里。
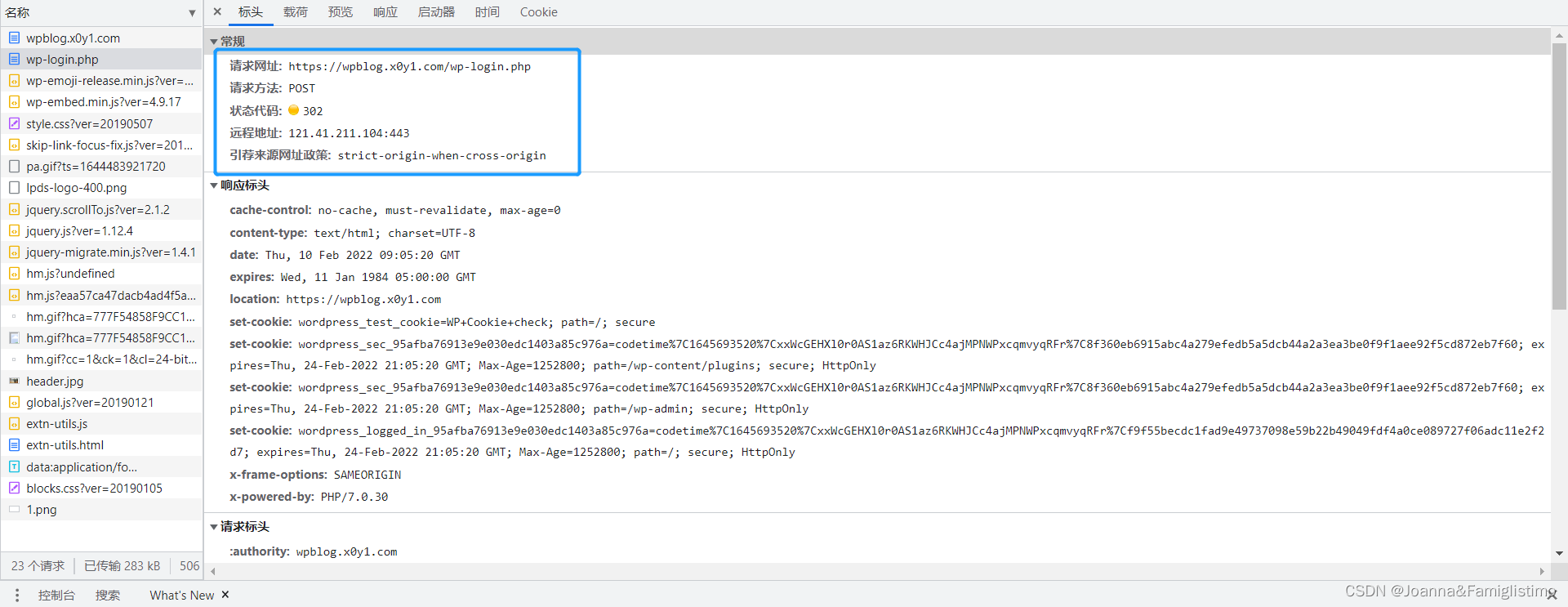
我们在请求详情里的 Form Data 中可以看到 POST 请求的参数:
其中log 是用户名,pwd 是密码,wp-submit 是提交类型,redirect_to 是登录后的跳转地址,test_cookie 不知道,可以先不管。

和发送 GET 请求一样,requests 库发送 POST 请求也很简单。我们看看官方文档中的介绍:
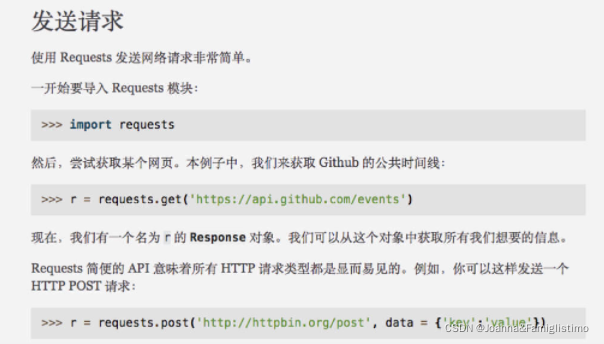
可以看到,我们通过 requests.post() 发送 POST 请求,而 POST 请求的参数通过字典的形式传递给 data 参数。因此,博客的登录操作可以用代码这样写:
import requests
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'
}
data = {
'log': '你的用户名',
'pwd': '你的密码',
'wp-submit': '登录',
'redirect_to': '跳转地址',
'testcookie': '1'
}
requests.post('https://wpblog.x0y1.com/wp-login.php', data=data, headers=headers)
在发出 POST 请求之后,服务器会在 Response Headers(响应头)里返回一些关于该请求的信息。有内容的格式、内容大小、过期时间等信息,我们重点关注的是有关登录的信息——set-cookie。
我们回到网页开发者工具看一下响应头里的 set-cookie:
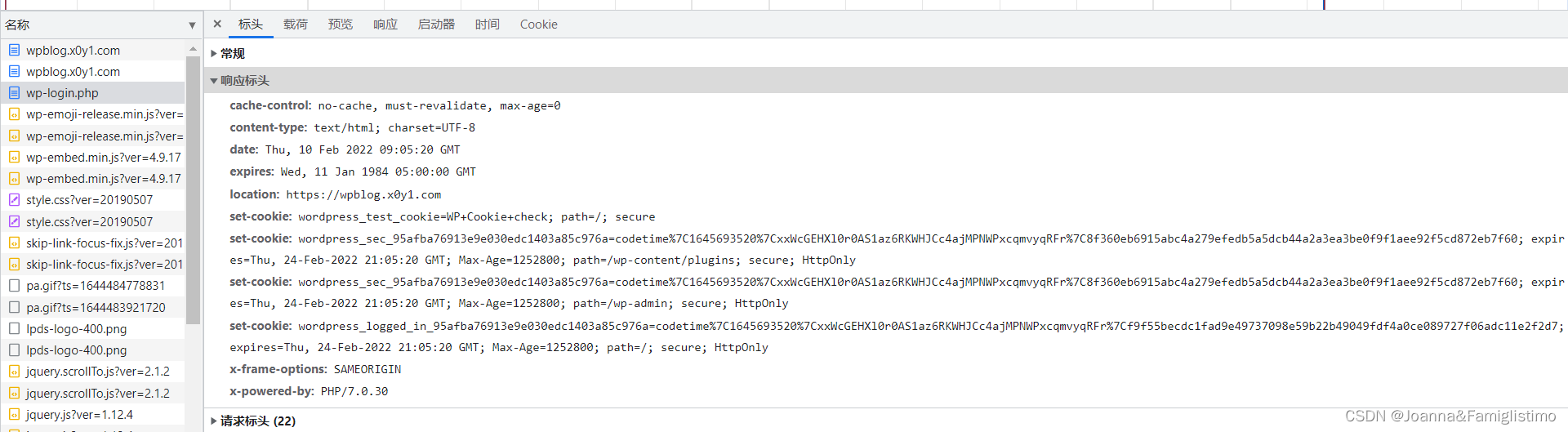
set-cookie 的作用是在浏览器中写入 cookie,之后的请求中会带上 cookie 信息。而我们的登录信息就藏在其中,所以在登录后,服务器能判断出我们是否已经登录。
Cookie
简单地说,cookie 是浏览器储存在用户电脑上的一小段文本文件。该文件里存了加密后的用户信息,过期时间等,且每次请求都会带上 cookie。所以,你登录过某网站后,下次再次打开该网站便不再需要登录。
因为 cookie 有过期时间,因此一段时间之后,cookie 便会失效,需要你再次重新登录,生成新的 cookie。cookie 就像一张通行证,当没有或通行证过期了,就无法通过,需要重新办理通行证才行。
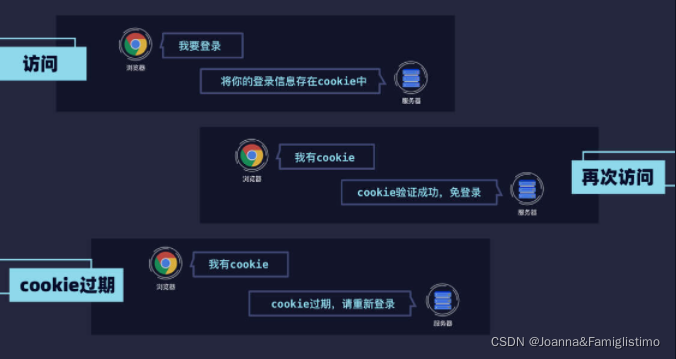
我们可以将登录后获得的 cookie 传递给后续的请求,以保持登录状态。但这样每次都要传递 cookie 很是麻烦,有没有什么方法可以让登录状态在多个请求之间共享呢?当然有!那就是 session。
Session----会话
因为 HTTP 是无状态的,在一次请求、响应结束过后,连接就断开了。再次发起请求时,之前的状态全都丢失了,服务器也不再“认识你”。有了 cookie 之后,我们可以将一些信息存到其中,比如用户身份信息等。但因为 cookie 容量有限,只有 4KB。因此,不可能将所有的用户信息都存到里面。这时候,session 就出现了。
session 相当于在服务器上建立的一份用户档案,cookie 中只要存储用户的身份信息,服务器通过身份信息在 session 中查询用户的其他信息。这样一来,我们的所有操作都会被保留。比如我们添加到购物车的商品,重新打开页面后仍会被保留。
这么好用的东西,requests 库当然也支持。我们来看看官方文档中的关于 session 介绍:

文档说,我们可以通过 requests.Session() 创建一个 session,注意 S 要大写。然后我们就可以像使用 requests 一样使用 session 对象了,get()、post() 等方法统统都有,只需将原先的 requests 替换成我们创建的 session 即可。
有了 session,多个请求之间就可以共享 cookie 了,后续请求便不再需要传 cookies 参数。
除了 cookies 参数每次都要传很麻烦,headers 参数每次都要传也很麻烦。如果想要共享 headers 的话,可以像下面这样写:
import requests
session = requests.Session()
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'
}
# 设置 session 的全局 headers
session.headers.update(headers)
# 默认使用全局的 headers
session.get('https://wpblog.x0y1.com')
# 自定义 headers
custom_headers = { 'referer': 'https://wpblog.x0y1.com' }
session.get('https://wpblog.x0y1.com', headers=custom_headers)
# 既有全局的 user-agent 也有自定义的 referer
我们可以通过 session.headers.update() 方法来更新全局的 headers,通过该 session 发送的请求都会使用我们设置的全局 headers。
当全局 headers 不满足我们的需求时,也可以给某个请求单独设置 headers。这时,该请求将同时拥有全局和单独设置的 headers。如果两个 headers 里的字段重复,会优先使用单独设置的 headers 字段的值。
浏览器自动化----selenium
我们先来看看如何用selenium打开 Chrome 浏览器,代码如下:
# 从 selenium 中导入 webdriver(驱动)
from selenium import webdriver
# 选择 Chrome 浏览器并打开
browser = webdriver.Chrome()
# 打开网页
browser.get('https://wpblog.x0y1.com')
# 关闭浏览器
browser.quit()
browser 是我们实例化的浏览器。我们将网址传给 browser 对象的 get() 方法,即可打开对应的网页。最后调用 quit() 方法将浏览器关闭。
我们的目的是获取数据,接下来让我们用 browser 对象的 page_source 属性来获取网页的源代码。值得注意的是,用 selenium 获取的网页源代码是数据加载完毕后最终的源代码,也就是网页加载后通过 API 获取的数据也在这个源代码中。
因此,我们就不用再区分要爬取的网页是静态网页还是动态网页了,在 selenium 眼里统统都一样。我们来试着用 selenium 打印出博客的网页源代码:
from selenium import webdriver
# 引入 time 模块
import time
browser = webdriver.Chrome()
browser.get('https://baidu.com')
# 等待 2 秒
time.sleep(2)
# 打印出网页源代码
print(browser.page_source)
browser.quit()

我们之前掌握了用 BeautifulSoup 对获取的网页源代码进行处理,提取出我们需要的内容。selenium 也同样可以进行数据的处理,它俩原理类似,只是语法上有所不同。
接下来,我们来看看如何用 selenium 处理数据。我们以获取博客的 h1 标签为例,代码可以这样写:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://baidu.com')
h1 = browser.find_element_by_tag_name('h1')
print(h1.text)
browser.quit()
selenium 还有很多方法来查找元素,方法名同样的一看就知道是干嘛的:

但上述方法可能已经废弃了,selenium 新增了一种更统一的方法 find_element(),而具体通过什么来查找(tag name, class name 等)放进了参数中。
# <p>Joanna带你打开编程世界的大门</p>
browser.find_element('tag name', 'p')
# <p class="slogan">Joanna带你打开编程世界的大门</p>
browser.find_element('class name', 'slogan')
# <p id="slogan">Joanna带你打开编程世界的大门</p>
browser.find_element('id', 'slogan')
# <p name="slogan">Joanna带你打开编程世界的大门</p>
browser.find_element('name', 'slogan')
# <a href="http://code.shanbay.com">Joanna</a>
browser.find_element('link text', 'Joanna')
browser.find_element('partial link text', 'Joanna')
这些方法找到的元素(返回值)都是 WebElement 对象,它和 BeautifulSoup 里的 Tag 对象一样,也有一个 text 属性,一样也是获取元素里的文本内容。
不同的是,Tag 对象通过字典取值的方式获取元素的属性值,而 WebElement 对象则使用 get_attribute() 方法来获取。

BeautifulSoup 中通过 find() 方法查找第一个符合条件的元素,通过 find_all() 方法查找所有符合条件的元素。刚才介绍的那些方法都是查找第一个符合条件的元素,接下来我们来看看 selenium 中查找所有符合条件的元素的方法。
这些方法非常简单,老版本只要把刚才介绍的那些方法名中的 element 改成 elements 即可,如果是新版本的 selenium,直接把 find_element() 方法改成 find_elements() 方法即可
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://baidu.com')
# 注意下面是 elements
a_tags = browser.find_elements_by_tag_name('a')
# 新版本写法:
# a_tags = browser.find_elements('tag name', 'a')
for tag in a_tags:
print(tag.text)
browser.quit()
值得一提的是,WebElement 对象也可以调用 selenium 查找元素的方法。这样就和 BeautifulSoup 中的 Tag 对象一样,可以一层一层的查找元素,直到找到为止。
如果你觉得 selenium 的方法名又长又难记,觉得还是 BeautifulSoup 的方法名简单好记。那么,接下来的内容你肯定喜欢。
BeautifulSoup 的原理是将网页源代码的字符串形式解析成 BeautifulSoup 对象,然后通过 BeautifulSoup 对象 的属性和方法提取出我们需要的数据。发现没有?BeautifulSoup 只需要一个网页源代码的字符串形式即可。
之前我们都是使用 requests 库获取网页源代码,并通过 text 属性取得其字符串形式。而 selenium 获取网页后的 page_source 属性值正是字符串格式的!
接下来我要做什么,我想你应该也猜到了。对,就是将 selenium 和 BeautifulSoup 结合起来,共同完成爬虫的获取数据和处理数据。
以上面获取博客网页源代码中所有的 a 标签 为例,加上 BeautifulSoup 可以这样写:
from selenium import webdriver
from bs4 import BeautifulSoup
browser = webdriver.Chrome()
browser.get('https://baidu.com')
# 用 BeautifulSoup 解析网页源代码
soup = BeautifulSoup(browser.page_source, 'html.parser')
a_tags = soup.find_all('a')
for tag in a_tags:
print(tag.text)
browser.quit()
自动登录博客并获取文章内容的代码如下:
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 打开博客
browser.get('你的网址')
# 找到登录按钮
login_btn = browser.find_element_by_link_text('登录')
# 点击登录按钮
login_btn.click()
# 等待 2 秒钟,等页面加载完毕
time.sleep(2)
# 找到用户名输入框
user_login = browser.find_element_by_id('user_login')
# 输入用户名
user_login.send_keys('你的用户名')
# 找到密码输入框
user_pass = browser.find_element_by_id('user_pass')
# 输入密码
user_pass.send_keys('你的密码')
# 找到登录按钮
wp_submit = browser.find_element_by_id('wp-submit')
# 点击登录按钮
wp_submit.click()
# 找到 Python 分类文章链接
python_cat = browser.find_element_by_css_selector('section#categories-2 ul li a')
# 上一句用新版本的写法如下
# python_cat = browser.find_element('css selector', 'section#categories-2 ul li a')
# 点击该分类
python_cat.click()
# 找到跳转的页面中的所有文章标题标签
titles = browser.find_elements_by_css_selector('h2.entry-title a')
# 上一句用新版本的写法如下
# titles = browser.find_elements('css selector', 'h2.entry-title a')
# 找到标题标签中内含的链接
links = [i.get_attribute('href') for i in titles]
# 依次打开 links 中的文章链接
for link in links:
browser.get(link)
# 获取文章正文内容
content = browser.find_element_by_class_name('entry-content')
print(content.text)
browser.quit()
我们主要关注 click() 和 send_keys() 这两个方法。通过 selenium 查找元素的方法找到对应的元素后,调用其 click() 方法就可以模拟点击该元素,一般用于点击链接或按钮;调用其 send_keys() 方法用于模拟按键输入,传入要输入的内容即可,常用于账号密码等输入框的表单填写。
如果想继续学习,可参考链接: selenium.
总结
就先写到这里吧,创作不易,喜欢的可以关注呀~
不定期更新的小博主一枚

















 208
208

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









