






 本文系统回顾了超图生成的多种方法,包括基于距离、表示、属性和网络,探讨了超图学习的应用,特别是动态超图的表示和结构优化。提出基于张量的动态超图学习框架t-DHL,解决了现有方法的非凸性和计算效率问题。作者还发布了超图学习工具箱THUHyperG。
本文系统回顾了超图生成的多种方法,包括基于距离、表示、属性和网络,探讨了超图学习的应用,特别是动态超图的表示和结构优化。提出基于张量的动态超图学习框架t-DHL,解决了现有方法的非凸性和计算效率问题。作者还发布了超图学习工具箱THUHyperG。
目录
简介:
在本文中,首先系统地回顾了有关超图生成的现有文献,包括基于距离、基于表示、基于属性和基于网络的方法。然后,介绍了超图上现有的学习方法,包括转导超图学习、归纳超图学习,超图结构更新和多模态超图学习。最后,提出了一个基于张量的动态超图表示和学习框架,该框架可以有效地描述超图中的高阶相关性。顺便对几个典型的应用程序进行了评估,包括对象和动作识别。
引言
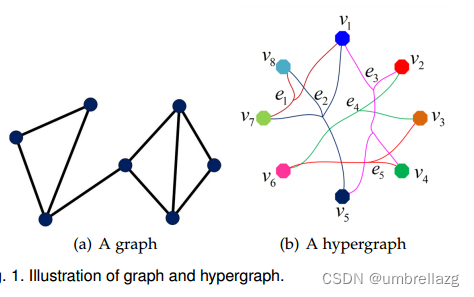
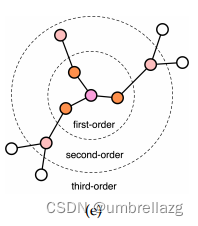
如图所示,超图是图的推广,对于超图来说,一条超边上可以有多个节点。因此在实际数据建模上具有显著的优势。如果一条超边上的节点有k个,那么这条边就是k阶超边,而节点连接k个超边就叫k阶节点,如果超边有权重的话,就是【总权重之和】阶节点。
作为图的广义化,超图在应用上基本与图学习的应用差不多,包括推荐系统、节点分类等,外加超边分类。不同点在于,超图学习将图学习模型扩展到高维、更完整的非线性空间,更符合实际情况——现实世界的关系不止成对那么简单。
以前的超图学习方法有两个主要的局限性:一个是所构建的超图可能没有优化或优化不足,从而使所建立的模型不能很好地拟合数据。另一个是计算成本可能过高,尤其是当超图结构同时更新时,这使得它很难应用于大规模数据集。为了改进,这篇文章提出了基于张量的动态超图表示和学习框架。
作者提到他发布了个THU HyperG的工具箱,提供超图生成和学习算法的练习集合,不知道在哪。
超图初步知识:
这个另外的文章里我已经写过了,不想再写了,偷个懒,主要提一下拉普拉斯矩阵,这个比较重要。在超图中,拉普拉斯矩阵的定义是:,可以被归一化表示为:
D是对角矩阵,H是超图关联矩阵,W是超边权重矩阵,I应该是单位阵。
拉普拉斯矩阵还蛮常用的。
超图构造
超图生成方法通常可分为四类,即基于距离的方法、基于表示的方法、基于属性的方法和基于网络的方法
基于距离的超图生成:
利用特征空间中的距离来表示节点之间的关系,主要目标是在特征空间中找到相邻的节点,并构造超边来连接它们。一般来说,有两种方法可以构造这个超边:最近邻搜索和聚类。
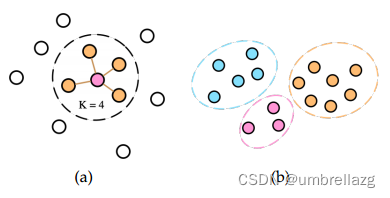
最近邻搜索:给定一个节点(即质心),超边可以连接它自己和它在特征空间中的最近邻居,所选邻居的数量是预定义的参数k,或者由超边距离范围内的节点数量决定。通过该方法,超边可以连接一组连接到同一质心的相似节点。
聚类:通过聚类算法(如k-means)将所有节点直接分组到聚类中,并通过超边连接同一聚类中的所有节点(注意,不同尺度的聚类结果可用于生成多个超边,在这种方法中,每条超边的权重或者置信度可由以下公式: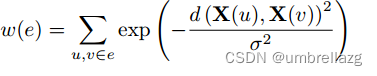 u,v分别是超边中的一对节点,d表示距离,σ可以根据经验设置为所有节点对的距离的中值。
u,v分别是超边中的一对节点,d表示距离,σ可以根据经验设置为所有节点对的距离的中值。
除了特征空间中的相似性外,位置(空间)信息也可以用于基于距离的超边生成,即每个节点都可以找到其空间邻居
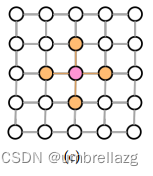
基于距离的方法的主要局限性是,在某些情况下,由于噪声和异常值,节点之间的距离可能不准确,还有最近邻居的规模可能会影响超图学习的性能,因此选邻居的数量是个问题,但可以通过自适应学习解决
基于表示的超图生成:
用一个例子超图来说明,在
超图中,每个节点都充当质心,并且可以由其最近的邻居表示为
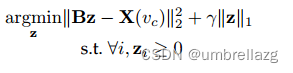 基于该表示,对质心具有非零重构系数的邻居中的节点进行分组以生成超边,并且可以将超边与每个节点之间的连接强度设置为系数。
基于该表示,对质心具有非零重构系数的邻居中的节点进行分组以生成超边,并且可以将超边与每个节点之间的连接强度设置为系数。
与那些基于距离的方法一样,这一系列工作也可能受到数据噪声和异常值的影响,另一个缺陷来自数据采样过程:只选择部分相关样本进行重建,生成的超图可能无法表示完整的数据相关性。
基于属性的超图生成:
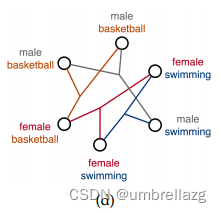
利用属性信息来构造超边,属性相同的节点会在同一超边上。超边的权重是将超边视为一个簇(clique)然后将簇中的成对边的热核(heat kernel weights)权重平均值当作超边权重。
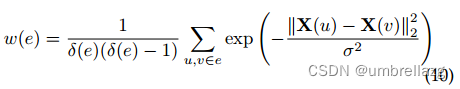
其中,δ代表阶数。
虽然属性信息在表示数据方面具有显著优势,但在某些情况下可能无法获得此类信息。
基于网络的超图生成
网络数据可以用于生成主题相关性。例如,可以用节点表示用户和图像。超边,包括同质和异质超边,用于捕捉多类型关系。使用基于近邻和基于属性的超边生成方法来构造表示图像之间的视觉和文本关系的同构超边。异构超边是利用连接图像和用户的链接关系构建的。
不能直接从原始数据中获得,需要通过建立表示和测量来重建的超边是隐式超边。基于距离和基于表示的方法式隐式方法,可以应用于创建主题和描述样本之间相似性的度量的任务。
显式超边可以直接建立,因为输入数据可能固有地包含一些结构信息。基于属性和基于网络的方法属于显式类别,可以使用属性或网络连接直接获得超边。
每种方法都有其优点和局限性:
基于距离的方法在各种应用中都是直接有效的,但是,它们对相似性测量和超参数设置(例如,基于最近邻居的模式中的邻居数量或聚类过程中的聚类数量)敏感(容易被噪声影响)。
基于表示的方法可以通过稀疏表示来避免噪声节点的影响,但是计算重建系数(之前举例的那个方法中范数就是重建系数)可能会引入额外的计算成本。
基于属性的方法适用于具有特定属性的样本。这些属性可以由输入给定,也可以手动定义,甚至可以自动生成。这一系列方法很简单,但由于只考虑单属性特征(即,只有 有同一属性 的节点和超边会链接),不同属性之间的关系没有得到充分利用。
基于网络的方法应该适用于可以自然地用图表示的数据。但必须用特定的领域知识来构造超图。
通常,在给定特定任务的情况下,可能存在最合适的生成方法。但由于超图的邻接超矩阵的可伸缩性,通常通过将不同方法创建的几个超图合并在一起来创建更复杂的超图
超图学习的应用:
Label Prediction(标签预测):
用于分类的超图学习方法:首先在超图上引入了一个通用的学习模型,然后分别以转导和归纳( transductive and inductive manners)【传导:把二分类的方法推广到多类的场景下(训练和分类全是在线过程,考虑所有数据,计算量比较大)。归纳:目标被定义为,被转换为求投影矩阵M(包括只需要训练数据的离线过程和在线分类过程)】的方式详细描述了超图上的学习过程。给定超图G =(V;E;W),训练节点是那些带有标签的点,标签预测的任务是预测剩余未标记节点的标签,把预测函数记作F,标签向量中的第i个元素表示将相应主题分类为第i类的置信度得分,未标记节点的预测标签被设置为具有最高置信度得分的节点,目标函数有两个部分,第一个部分是习得标签的经验损失
,比如最小二乘损失,第二个部分是超图正则化因子
表示超图结构上标签分布的光滑性
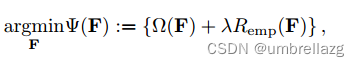 ,λ是权重。
,λ是权重。
Dynamic Hypergraph Structure Learning(动态超图结构学习):
超图的动态结构学习是在学习过程中动态更新超图分量,包括超边权重、节点权重和关联矩阵,以使数据相关性建模更加准确。这个问题对于超图学习非常重要,因为数据相关性建模在很大程度上取决于超图结构的质量。
超边权重的一个例子是Gao等人在[Y. Gao, M. Wang, Z.-J. Zha, J. Shen, X. Li, and X. Wu, “VisualTextual Joint Relevance Learning for Tag-Based Social Image Search,” 2013]中提出的自适应超边加权方法。
节点权重:一旦生成超图,就根据每个类的训练样本的分布来计算每个节点的初始权重,可以用拉普拉斯矩阵或者拉格朗日矩阵来算:
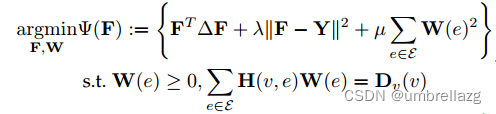
超图结构:优化关联矩阵,可以与同一框架内未标记节点的标签预测一起执行,一种典型方法是【Dynamic Hypergraph Structure Learning,2018】
Hypergraph Learning for Multi-Modal Data(多模态超图学习):
转导超图学习方法和归纳超图学习法都可以进一步将超图学习扩展到多模态情况,多模态是指数据有多种类型,比如文本、图片、视频等,不细说了。
转导法:假设一个主体有m个模态;每个模态可以生成超边,并通过将每个主体视为节点来构造超图。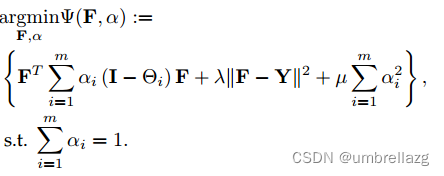
归纳法:基本思想是学习从特征空间到标签空间的投影矩阵
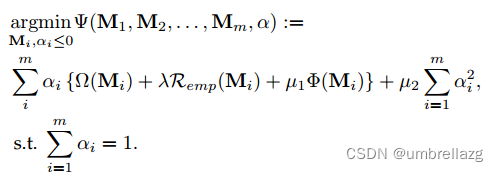
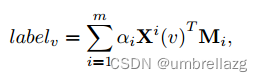
TENSOR-BASED DYNAMIC HYPERGRAPH LEARNING(基于张量的动态超图学习):
动态超图学习问题中的挑战的有三个方面:
- 无论是优化超边权重[36]还是优化节点和超边之间的相关性,在学习过程中,超边的数量和顺序都是固定的,因此超图结构仅被部分优化。
- 现有的动态超图结构学习方法的优化模型大多是非凸的,可能导致严重的收敛问题
- 现有方法的时间复杂度特别高,可能需要更多的时间来更新关联矩阵。关联矩阵的高表示复杂度使得计算梯度和优化目标函数的成本很高。
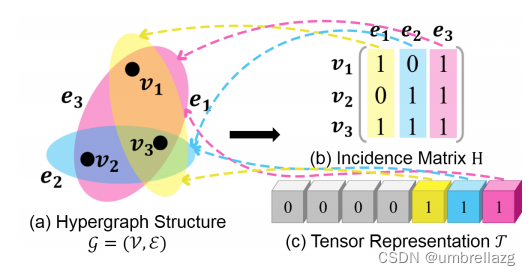
为了解决上述问题,本文利用张量表示来更灵活地刻画动态超图结构,并提出了基于张量的动态超图学习方法(t-DHL)来有效地学习动态超图,在优化张量表示时,不仅可以改变权重,还可以改变超边的数量和顺序,因为张量可以表示所有阶数的超边,如下图所示。(关联矩阵不可以改数量和顺序)
基于张量的动态超图学习被公式化为双凸模型,以确保模型能够有效地收敛到最优解,如图所示 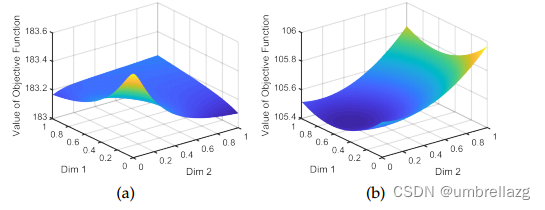
超图的张量表示:
给定超图G=(V;E;W),我们使用2-D空间中的N阶(N-order)张量来表示具有N个节点的超图,比如说三个节点的超图可以用2*2*2的张量表示,如图所示: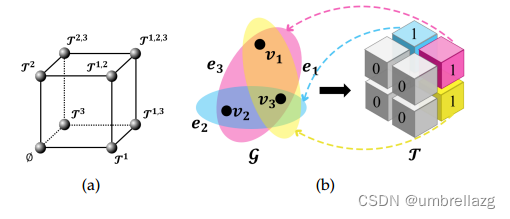
为了简洁,将张量T表示为为展开形式,即维向量如下图所示
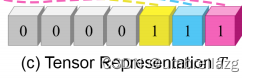
假设是
的幂集,
是张量
中
个元素的索引,
表示
中的一个子集,称作簇,
代表簇的连接强度(connect strength)。这样,
记录了所有可能的派系和相关的连接强度。如果
,那么在簇
中就存在一条超边连接簇中的所有节点,假设
代表初始超图结构,超图结构的调整可以通过直接修改相应元素的值来实现。
因为在学习过程中,超边的数量、顺序和权值都是可变的,所以通过张量表示超图突破了传统关联矩阵的局限性。
具体表示方法:
对于每个簇,使用一个势(potential)函数来估计其上的数据分布。因为有预测的标签信息和输入特征,所以代价函数关于标签空间和特征空间。数据分布密集的簇应该比数据分布分散的簇具有更高的势。的势函数可以表示如下:
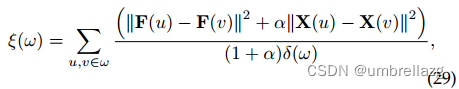
其中α是平衡标签信息和特征信息重要性的权重,基于超图的损失项 鼓励 势较高的簇权重较低低,反之亦然。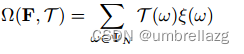
进一步应用T和F的经验损失作为正则化项: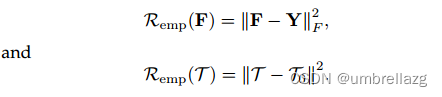
在动态超图上学习的目标函数可以写成以下对偶优化问题:
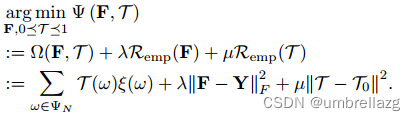
λ和µ是平衡目标函数中不同分量的参数。
THU-HyperG:
一个专门实现超图学习的python库,可以用在聚类和分类任务上,也是这篇文章作者开发的
1 Title
Hypergraph Learning: Methods and Practices(Yue Gao,Zizhao Zhang, Haojie Lin, Xibin Zhao, Shaoyi Du,and Changqing Zou)【IEEE 2020】
2 Good sentence
- In general, given a specific task, there may be a most suitable hyperedge generation method. Lastly, due to the scalability of a hypergraph’s adjacency hypermatrices, it is common to create a more complicated hypergraph by merging several hypergraphs created by different approaches together(The common methods of related works)
- Although there have been attempts on optimizing the hypergraph structure, there still exists a long way to model the dynamic correlations in the learning process well.(The reason why this research has been done)
- By means of tensor representation, the hypergraph structure can be optimized more flexibly, since the number, order, and weights of hyperedges are all variable during the learning process, which breaks through the limitations of the traditional incidence matrix.(The advantages of tensor representation)
3 Conclusion
This paper systematically review recent progresses on hypergraph learning, with a focus on hypergraph generation, learning models and their applications. Previous dynamic hypergraph structure learning methods have the problems of non-convex, under-optimized and high computational cost in real applications. To address these limitations, this research has also proposed a tensorbased dynamic hypergraph learning method called t-DHL which can achieve a good balance between effectiveness and efficiency. In addition, to facilitate the research of hypergraph learning, it has released THU-HyperG which is a comprehensive toolbox for hypergraph learning methods and practices.

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









