









摘要
多模态学习中出现的基本问题是不同模态之间的信息水平差异。为了解决这个问题,本文提出了超图注意力网络(HANs),他在具有符号图的模态之间定义了一个共同的语义空间,并基于在语义空间中构建的注意力图提取模态的联合表示。过程:用每个模态的的符号图构建公共的语义空间,匹配符号图子结构之间的语义,在语义空间中构建图之间的共同注意力图,并使用共同注意力图集成多模态输入,以获得最终的联合表示。
介绍
重新强调了存在的问题:来自不同模态的特征向量被视为了同一个level上的上的抽象信息,即使这些特征向量是从不同的预处理步骤中获得的。如何对齐异构模态的信息?
为了解决这个问题,本文建议使用符号图作为多模态学习的常见语义表示。我们将符号图定义为包含节点和边的有向图,节点表示具有文本形式的语义单元,边表示它们之间的关系。例如,场景图可以用作图像模态的符号图,也可以用作文本模态的自然句子中的依存树。通过从每个低层输入中提取符号图,我们可以比较同一抽象层中模态之间的语义。
基于相同语义空间上的符号图,可以有效地集成多模态输入。在这里,本文提出了一种新的基于图神经网络的算法,称为超图注意网络(HANs),它利用图的子结构来集成符号信息。HANs的主要思想是构造多模态输入间的共同注意力图,并将输入与共同注意力图进行集成。传统的注意方法通常独立比较节点值来制作注意图,而HANs通过结构相似度来考虑高层语义相似度。
定性分析后的发现:
1)符号图是表示低层信号信息的强有力的方法
2)模式间的信息水平对齐是根本问题。
相关工作
图匹配算法
以graph的形式集成多模态的输入,回顾了graph的学习相似性,并将其与注意力机制联系起来。
两个图之间的相似性可以被定义为WL图同构测试。具有足够消息传递的表示可以用来确定两个图是否同构。Graph Matching Networks (GMNs)图匹配网络用来学习两个图之间的相似性,在GMN中,不仅通过消息在每个图中的传递来更新节点的表示,还通过跨图注意力机制来学习两个图之间的相似性。由于消息传递可以捕捉图的依赖性,GMN中的跨图注意力可以捕捉到两个图的结构相似性。
使用图结构的VQA
(翻译软件翻译)
通过图形表示对对象交互进行建模的方法已经在计算机视觉领域引起了越来越多的兴趣。针对VQA任务,Teneyet al.[28]最初提出了一种将问题和抽象图像的图表示与图形神经网络(GraphNeural Networks, GNN)相结合的方法。针对计数问题,提出了通过隐式和显式图结构对对象之间的交互行为进行建模的方法[40,29]。[20,37,32,31]还利用了属性和可视关系等高级语义信息,使模型更加强大和可解释。norcliff - brown等人[24]引入了一种以问题为条件在图像中构造语义结构的方法。后来,Cadene等人[5]将这一思想扩展到建模所有区域对之间的空间语义对关系。最近,提出了一种用于VQA和GQA数据集的条件迭代消息传递算法,以学习基于给定问题[9]的上下文感知节点表示。同时,hudson -son等人[12]建议使用神经状态机(NSM)在符号层面上处理视觉和语言信息。为了解决GQA任务,NSM首先预测一个概率场景图。然后,为了回答给定的问题,他们基于迭代节点遍历算法对图进行顺序推理。
方法:超图注意力网络
该方法称为超图注意力网络(HANs),由四个部分组成:(1)构造符号图,(2)在符号图上采样随机行走路径以构造超图,(3)匹配超边之间的语义以构造共同注意力图,(4)整合超图以获得多模态输入的最终表示。
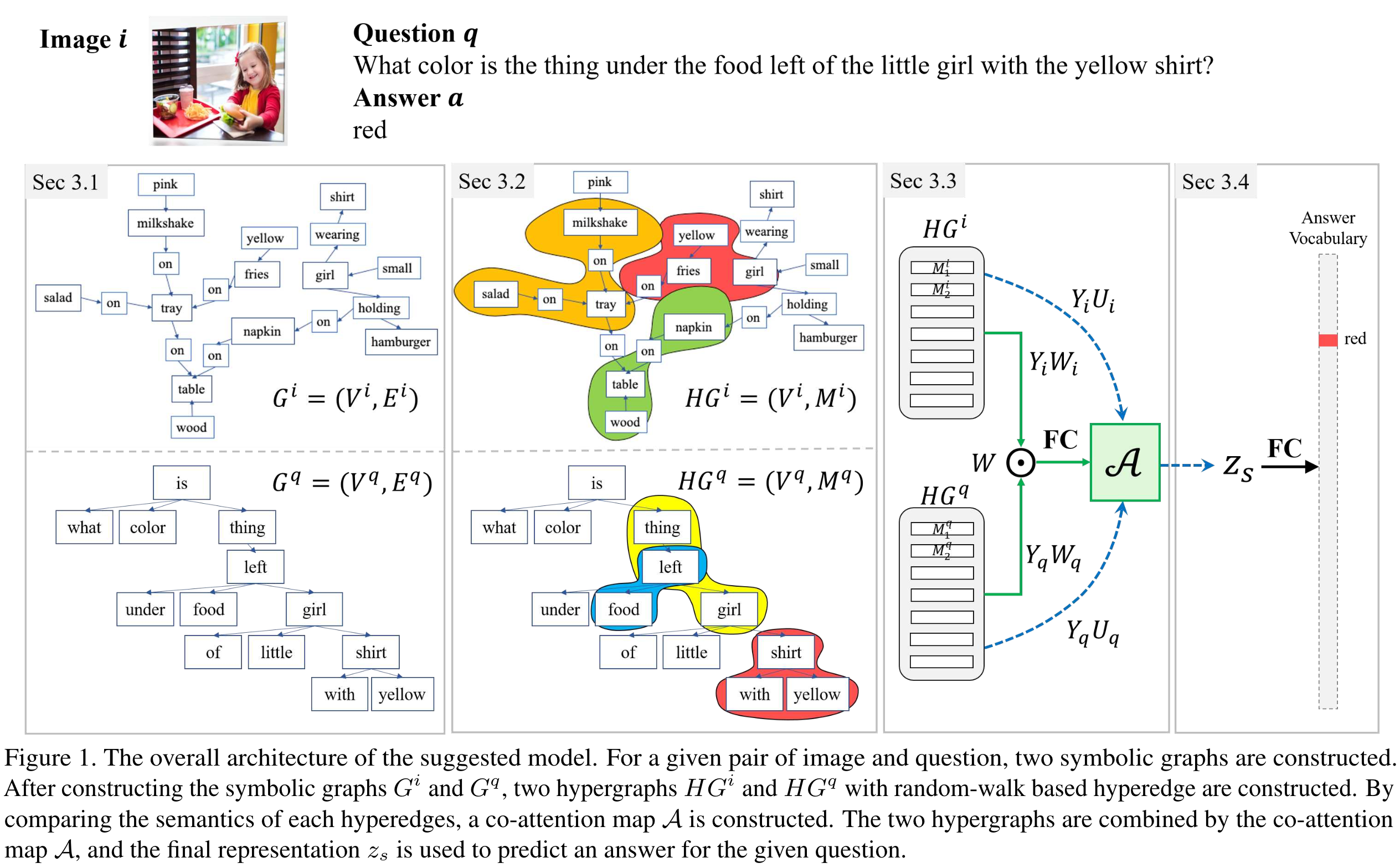
构建符号图
图像模态:使用[14]中的场景图来构建符号图,节点是对象的标签,属性和节点之间关系对应的单词。边按照以下规则进行定义:1)如果对象节点
v
j
i
\ v^i_j
vji 有属性
v
k
i
\ v^i_k
vki,那么
(
j
,
k
)
∈
E
i
\ (j,k) \in E^i
(j,k)∈Ei,2)如果两个对象节点
v
j
i
\ v^i_j
vji 和
v
k
i
\ v^i_k
vki 有关系
v
l
i
\ v^i_l
vli,那么
(
j
,
l
)
∈
E
i
\ (j,l) \in E^i
(j,l)∈Ei和
(
l
,
k
)
∈
E
i
\ (l,k) \in E^i
(l,k)∈Ei。The reason to make edge-labeled scene graphs flat is to align the structure between
G
q
\ G^q
Gq and
G
i
\ G^i
Gi.
文本模态:使用Spacy library获取问题句子的依存树,符号表示包含了token和token之间的依赖关系。
由于两种符号图都对应于words的表示,所以可以认为两种符号图处于(公共)相同的信息级别。
构建超图
在构建了两个符号图之后,将通过匹配子图的语义来构建共同注意力图(co-attention map)。由于子图匹配问题是NP-hard问题之一,本文提出了一种简单但功能强大的近似算法HANs。本文将每个超边(通过随机游走算法采样的带有有向边的节点序列)视为一个子图,因此通过计算 G i \ G^i Gi和 G q \ G^q Gq的超边之间的相似性来构建 A \ A A。
节点
v
i
\ v_i
vi 被选中的初始概率定义为:
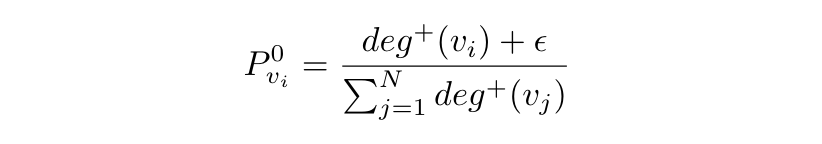
N
\ N
N 表示总节点数,
d
e
g
(
v
i
)
\ deg(v_i)
deg(vi) 表示节点
v
i
\ v_i
vi 的出度。转移概率
P
q
\ P^q
Pq 和
P
i
\ P^i
Pi 的定义如下:
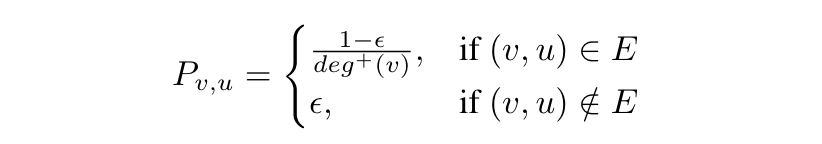
(这一段超图的构建自己缺乏理论上的一些知识,所以有点看不明白)
在超图之间构建共同注意力图
现在,用超边缘间语义匹配的方法来近似获得共同注意力图的子图匹配问题。在本节中,定义了每个超边缘
M
\ M
M 的语义,并说明了比较超边缘之间语义的方法。
超边的语义定义如下:
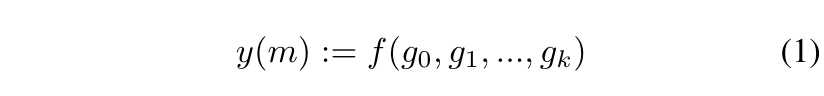
采用的是GloVe词嵌入,然后求均值获取超边的语义。
现在,通过测量两个超边
y
(
m
i
)
\ y(m^i)
y(mi) 和
y
(
m
q
)
\ y(m^q)
y(mq) 语义之间的相似性来构建共同注意力映射
A
\ A
A。对于相似性度量,使用低秩双线性池化的方法如下:
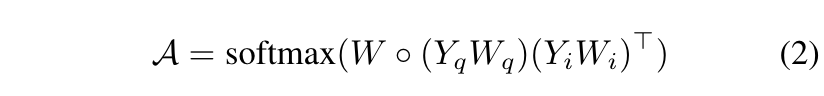
在这里,共同注意图有两个有趣的特征。首先,共同注意图
A
\ A
A是基于语义和符号表征的比较,而以往研究的是具有不同信息层次的神经表征。其次,所提出的方法不仅考虑了两个节点之间的单一关系,而且通过构造超图来考虑其内在结构,而以往的图匹配研究大多是比较两个节点之间的(神经)表示。
此外,根据超边
y
(
m
)
\ y(m)
y(m)的语义,我们可以考虑利用符号图的结构信息。为了通过考虑相邻节点的信息来获得信息性节点表示,设计了基于消息传递的图神经网络。节点特征矩阵
X
∈
R
S
×
d
\ X \in \mathbb{R}^{S \times d}
X∈RS×d更新方式如下:
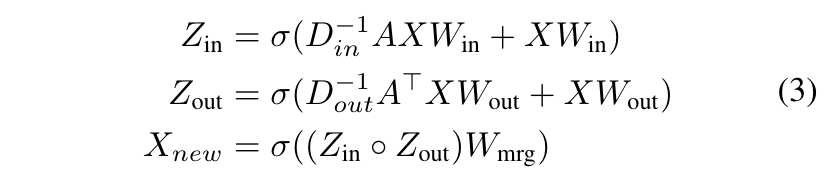
(???)
获取最终表示
因为公式2获得了共同注意力矩阵
A
\ A
A,所以可以使用双线性算子
B
\ B
B,例如BAN或者MFB来集成两个模态的超图。
如果采用的是BAN:

合并视觉特征
使用BUTD提取出的视觉特征
V
i
∈
R
N
v
×
d
\ V_i \in \mathbb{R}^{N^v \times d}
Vi∈RNv×d,利用公式(2)也生成共同注意力图
A
∗
\ A^*
A∗,然后获取视觉语义特征
z
v
\ z_v
zv:
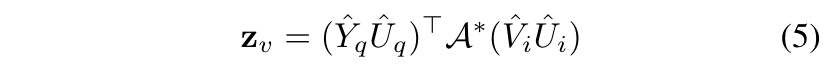
最后将
z
s
\ z_s
zs和
z
v
\ z_v
zv进行组合来进行答案预测。















 203
203











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









