







 本文探讨了传统检测模型中耦合头的局限性,如YOLOv3和YOLOv4,以及如何通过引入解耦头设计来改进。解耦头将类别预测和位置预测分开,优化各自任务的损失函数,提高了模型灵活性。文章还举例说明了FCOS、YOLOX和FastestDet等模型采用了解耦头技术。
本文探讨了传统检测模型中耦合头的局限性,如YOLOv3和YOLOv4,以及如何通过引入解耦头设计来改进。解耦头将类别预测和位置预测分开,优化各自任务的损失函数,提高了模型灵活性。文章还举例说明了FCOS、YOLOX和FastestDet等模型采用了解耦头技术。
一、传统耦合头局限性
传统的检测模型,如YOLOv3和YOLOv4,使用的是单一的检测头,它同时预测目标类别和框的位置。然而,这种设计存在一些问题。首先,将类别预测和位置预测合并在一个头中,可能导致一个任务的误差对另一个任务的影响。其次,类别预测和位置预测的问题域不同,类别预测是一个多类分类问题,而位置预测是一个回归问题。这意味着它们需要不同的损失函数和网络层。
二、解耦头优势
解耦头的设计解决了上述问题。它将类别预测和位置预测分离开来,分别使用两个独立的网络分支进行处理。其中,类别预测使用一个全连接层来输出各个类别的概率,位置预测使用一系列卷积层来生成边界框的坐标。这样做的好处是可以分别优化类别预测和位置预测的损失函数,并且能够更灵活地设计网络结构和调整超参数。
三、哪些模型使用了解耦头?
1 FCOS

2 YOLOX
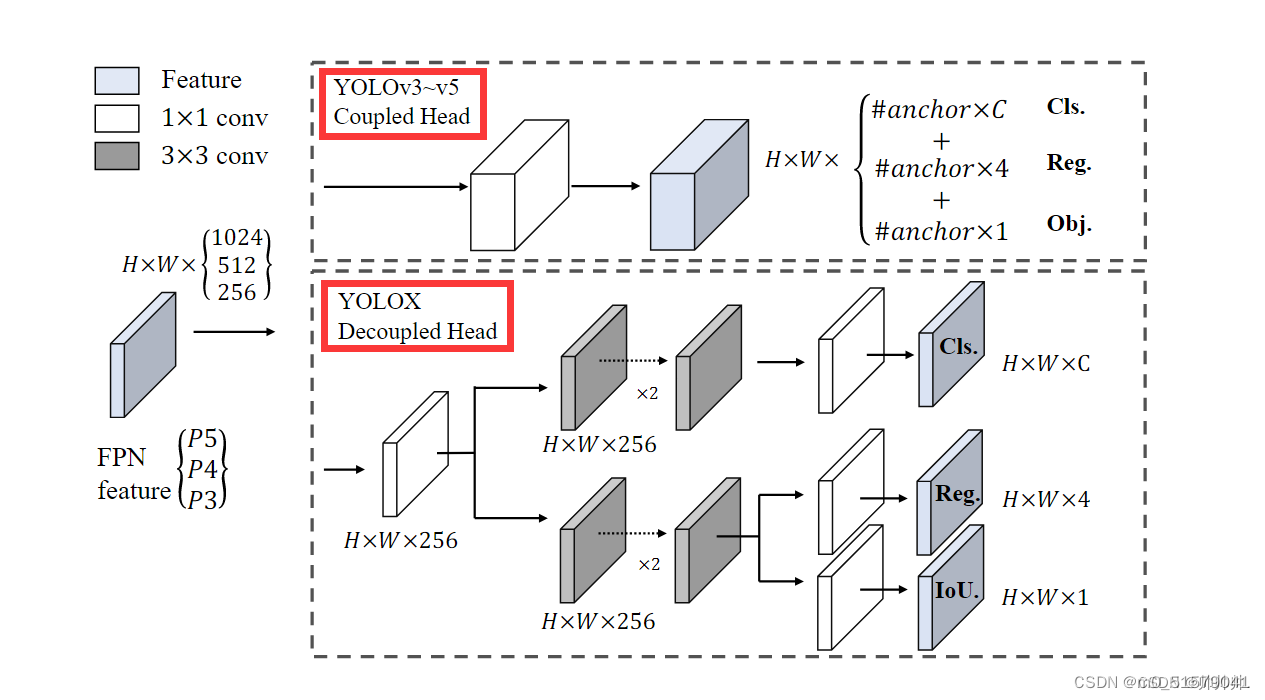
3 FastestDet
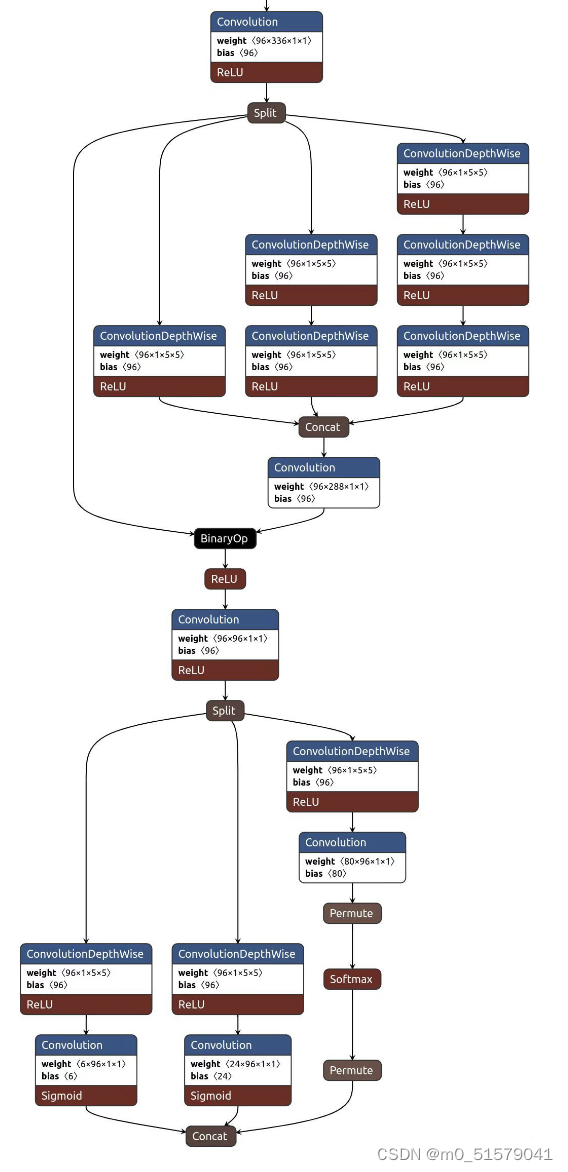
四 代码示例
耦合头demo
import torch
import torch.nn as nn
import torchvision.models as models
class CouplingHead(nn.Module):
def __init__(self, num_classes, num_boxes):
super(CouplingHead, self).__init__()
self.num_classes = num_classes
self.num_boxes = num_boxes
# 使用预训练的ResNet18作为基础模型
self.base_model = models.resnet18(pretrained=True)
# 修改最后一层的输出通道数
num_ftrs = self.base_model.fc.in_features
self.base_model.fc = nn.Conv2d(num_ftrs, num_classes + 5 * num_boxes, kernel_size=1)
# 分类分支
self.classification = nn.Conv2d(num_classes, num_classes, kernel_size=1)
# 回归分支
self.regression = nn.Conv2d(5 * num_boxes, 5 * num_boxes, kernel_size=1)
def forward(self, x):
x = self.base_model(x)
# 目标类别预测
classification = self.classification(x[:, :self.num_classes, :, :])
# 目标框回归
regression = self.regression(x[:, self.num_classes:, :, :])
return classification, regression
# 创建耦合头模型
num_classes = 10 # 类别数量
num_boxes = 4 # 每个目标的边界框数量
model = CouplingHead(num_classes, num_boxes)
# 随机生成输入数据
batch_size = 8
input_size = (224, 224)
x = torch.randn(batch_size, 3, *input_size)
# 前向传播
classification, regression = model(x)
# 输出结果
print("分类结果尺寸:", classification.shape)
print("回归结果尺寸:", regression.shape)
解耦头demo
import torch.nn as nn
import torch
# 定义解耦头模型
class DecouplingHeader(nn.Module):
def __init__(self, num_classes=20):
super(CouplingHeader, self).__init__()
self.num_classes = num_classes
# 分类模块
self.classification = nn.Sequential(
nn.Conv2d(512, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, num_classes, kernel_size=1)
)
# 回归模块
self.regression = nn.Sequential(
nn.Conv2d(512, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 4, kernel_size=1)
)
def forward(self, x):
classification = self.classification(x)
regression = self.regression(x)
return classification, regression
# 创建ResNet18主干网络
def resnet18():
model = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
nn.Sequential(
BasicBlock(64, 64, stride=1),
BasicBlock(64, 64, stride=1)
),
nn.Sequential(
BasicBlock(64, 128, stride=2),
BasicBlock(128, 128, stride=1)
),
nn.Sequential(
BasicBlock(128, 256, stride=2),
BasicBlock(256, 256, stride=1)
),
nn.Sequential(
BasicBlock(256, 512, stride=2),
BasicBlock(512, 512, stride=1)
),
nn.AvgPool2d(7, stride=1),
nn.Flatten()
)
return model
# 定义BasicBlock模块
class BasicBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.stride != 1:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
# 创建一个输入样本进行测试
input_sample = torch.randn(1, 3, 224, 224)
# 创建ResNet18主干网络实例
backbone = resnet18()
# 创建解耦头模型实例
header = DecouplingHeader()
# 将输入样本通过主干网络和解耦模型进行前向传播
features = backbone(input_sample)
classification, regression = header(features)
# 打印输出结果的形状
print("Classification output shape:", classification.shape)
print("Regression output shape:", regression.shape)

















 421
421

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











