







Fast RCNN代码复现
项目源代码下载地址:
Fast-R-CNN-pytorch-master
https://www.alipan.com/s/FqYEYzqCe7k 提取码:ue87 点击链接保存,或者复制本段内容,打开「阿里云盘」APP ,无需下载极速在线查看,视频原画倍速播放。
项目目录如下;
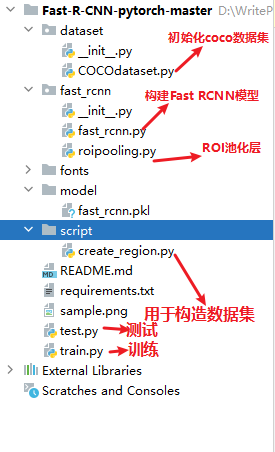
对Fast RCNN的论文理解见专栏的上篇内容,本文介绍Fast RCNN的代码复现。基本流程如下:
利用coco2017数据集训练Fast-RCNN模型(训练过程详细步骤记录):
(1)初始化COCO数据集
(2)构造训练集和验证集:利用选择搜索算法(selective-search)生成一定数量的候选框,将候选框与gound-truth进行IOU(交并比)计算,如果IoU大于等于0.5,则认为候选区域是正样本,0.1<IoU<0.5,则认为候选区域是负样本
(3)设置ROI Pooling模块、特征提取网络模型。利用ROIPlooing方法,从共享特征图抠出各个候选区域特征图
(4)设置输出为一个分类分支(类别类数+背景类(1))与回归分支
(5)设置多目标损失函数:交叉熵损失与回归损失
(6)训练网络模型
1.初始化COCO数据集
COCOdataset.py
import json
import os
import random
import PIL
import torch
from torch.utils.data import Dataset
from torchvision import transforms
import math
'''
COCO数据集的处理
1、读取数据
2、数据的预处理
3、数据的加载
'''
'''
需要修改内容:COCO数据集的存放路径、加载训练集还是验证集(mode为"train"or"val")
'''
class COCOdataset(Dataset):
# todo:注意修改coco数据集的存放路径
def __init__(self, dir='D:\\WritePapers\\object_detection_basics\\Datasets\\COCO2017\\', mode='train',
transform=transforms.Compose([transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, -.406], [0.229, 0.224, 0.225])])):
# transform执行2步操作:1、将PIL.Image转换为torch.Tensor,并自动将数据缩放到[0,1]之间;
# 2.对图像进行标准化。这里的两个参数分别是RGB通道的均值和标准差。这个操作会按照每个通道进行标准化,即(image - mean) / std
# transforms.Normalize([0.485, 0.456, -.406], [0.229, 0.224, 0.225])的两个参数分别是ImageNet数据集的统计得到的RGB通道的均值和标准差
# 这样做的目的是使得模型的输入数据分布和预训练模型(项目使用了在ImageNet预训练的VGG19模型)的输入数据分布一致,从而可以更好地利用预训练模型。
assert mode in ['train', 'val'], 'mode must be \'train\' or \'val\''
self.dir = dir # self关键字代表类的实例
self.mode = mode # train则加载训练集,val则加载验证集
self.transform = transform
with open(os.path.join(self.dir, '%s.json' % self.mode), 'r', encoding='utf-8') as f: #%s是一个字符串占位符。%操作符用于指定要插入的值==>%s会被self.mode的值替换
self.ss_regions = json.load(f)
# with语句并不创建一个新的作用域。在with语句块内部定义的变量,其作用域是包含with语句的那个作用域。
self.img_dir = os.path.join(self.dir, '%s2017' % self.mode)
def __len__(self):
return len(self.ss_regions) # 说明ss_regions是一个列表,每个元素代表一张图片对应的region信息
def __getitem__(self, i, max_num_pos=8, max_num_neg=16):
img = PIL.Image.open(os.path.join(self.img_dir, '%012d.jpg' %
self.ss_regions[i]['id']))
# %012d是一个占位符,表示一个十二位的整数,不足十二位的部分会用0填充==>%012d会被self.ss_regions[i]['id']的值替换,self.ss_regions[i]['id']是从JSON文件中读取的某张图片的ID
img = img.convert('RGB') # 将图片转换为RGB格式
img = img.resize([224, 224])
pos_regions = self.ss_regions[i]['pos_regions'] # 获取正样本区域
neg_regions = self.ss_regions[i]['neg_regions'] # 获取负样本区域
if self.transform != None: # 如果设置了图像预处理方法
img = self.transform(img)
if len(pos_regions) > max_num_pos: # 如果正样本区域的数量大于最大数量,随机选择一部分正样本区域
pos_regions = random.sample(pos_regions, max_num_pos)
if len(neg_regions) > max_num_neg:
neg_regions = random.sample(neg_regions, max_num_neg)
regions = pos_regions + neg_regions # 合并正样本区域和负样本区域
random.shuffle(regions) # 随机打乱区域
rects = [] # 初始化矩形列表
rela_locs = [] # 初始化相对位置列表
cats = [] # 初始化类别列表
for region in regions:# 遍历第i张图片的得到的区域(包括正样本和负样本区域)
rects.append(region['rect']) # 将区域的矩形信息添加到矩形列表中
p_rect = region['rect'] # 获取区域的矩形信息
g_rect = region['gt_rect'] # 获取区域的真实矩形信息
t_x = (g_rect[0] + g_rect[2] - p_rect[0] - p_rect[2]) / 2 / (p_rect[2] - p_rect[0])
t_y = (g_rect[1] + g_rect[3] - p_rect[1] - p_rect[3]) / 2 / (p_rect[3] - p_rect[1])
t_w = math.log((g_rect[2] - g_rect[0]) / (p_rect[2] - p_rect[0]))
t_h = math.log((g_rect[3] - g_rect[1]) / (p_rect[3] - p_rect[1]))
rela_locs.append([t_x, t_y, t_w, t_h]) # 将区域的相对位置信息添加到相对位置列表中
cats.append(region['category']) # 将区域的类别信息添加到类别列表中
roi_idx_len = len(regions) # 获取区域的数量
return img, rects, roi_idx_len, rela_locs, cats
# dataset = COCOdataset()
# print(dataset[1][0].shape)
# print(dataset[1][1])
# from torch.utils.data import DataLoader
# dataloader = DataLoader(dataset, batch_size=2)
# print(next(iter(dataloader))[1])
if __name__ == '__main__':
dataset = COCOdataset()
print(dataset.__len__())
img, rects, roi_idx_len, rela_locs, cats = dataset.__getitem__(10)
print(img, rects, roi_idx_len, rela_locs, cats)
from torch.utils.data import DataLoader
loader = DataLoader(dataset, batch_size=1)
for i, temp in enumerate(loader):
print(i,type(temp))
2.构造训练集和验证集
利用选择搜索算法(selective-search)生成一定数量的候选框,将候选框与gound-truth进行IOU(交并比)计算,如果IoU大于等于0.5,则认为候选区域是正样本,0.1<IoU<0.5,则认为候选区域是负样本
import argparse # 导入argparse模块,用于处理命令行参数
import json
import os
import random
import sys # 导入sys模块,用于处理Python运行时环境
import time
from progressbar import * # 导入progressbar模块,用于显示进度条
from pycocotools.coco import COCO # 导入pycocotools模块,用于处理COCO数据集
from selectivesearch import selective_search # 从selectivesearch模块导入selective_search函数,用于进行选择性搜索
from skimage import io, util, color # 从selectivesearch模块导入selective_search函数,用于进行选择性搜索
def cal_iou(a, b): # 定义计算IoU(交并比)的函数,输入参数为两个矩形框
# 矩形框的格式为:[左上角x坐标,左上角y坐标,宽度,高度]
a_min_x, a_min_y, a_delta_x, a_delta_y = a
b_min_x, b_min_y, b_delta_x, b_delta_y = b
a_max_x = a_min_x + a_delta_x
a_max_y = a_min_y + a_delta_y
b_max_x = b_min_x + b_delta_x
b_max_y = b_min_y + b_delta_y
# 如果两个矩形框没有交集,则IoU为0
if min(a_max_y, b_max_y) < max(a_min_y, b_min_y) or min(a_max_x, b_max_x) < max(a_min_x, b_min_x):
return 0
else:
# 计算交集的面积
intersect_area = (min(a_max_y, b_max_y) - max(a_min_y, b_min_y) + 1) * \
(min(a_max_x, b_max_x) - max(a_min_x, b_min_x) + 1)
# 计算并集的面积
union_area = (a_delta_x + 1) * (a_delta_y + 1) + \
(b_delta_x + 1) * (b_delta_y + 1) - intersect_area
# 返回IoU
return intersect_area / union_area
def ss_img(img_id, coco, cat_dict, args): # 定义selective_search函数,输入参数为图像id、COCO数据集、类别字典、命令行参数
img_path = os.path.join(args.data_dir, args.mode +
'2017', '%012d.jpg' % img_id) # 获取图像的路径
coco_dict = {cat['id']: cat['name']
for cat in coco.loadCats(coco.getCatIds())} # 创建一个字典,将COCO数据集的类别ID映射到类别名
img = io.imread(img_path) # 读取图像
if img.ndim == 2: # 如果图像是灰度图,则将其转换为RGB图像
img = color.gray2rgb(img)
_, ss_regions = selective_search( # 对图像进行选择性搜索,获取候选区域
img, args.scale, args.sigma, args.min_size) # 'rect': (left, top, width, height)
anns = coco.loadAnns(coco.getAnnIds(
imgIds=[img_id], catIds=coco.getCatIds(catNms=args.cats))) # 获取图像的标注信息
pos_regions = [] # 初始化正样本区域列表
neg_regions = [] # 初始化负样本区域列表
h = img.shape[0] # 获取图像的高度
w = img.shape[1] # 获取图像的宽度
for region in ss_regions: # 遍历每个候选区域
for ann in anns: # 遍历每个标注信息
iou = cal_iou(region['rect'], ann['bbox']) # 计算候选区域和标注区域的IoU
if iou >= 0.1: # 如果IoU大于等于0.1,则认为候选区域是有效的
rect = list(region['rect']) # 获取候选区域的矩形框
rect[0] = rect[0] / w # 将矩形框的x坐标转换为相对于图像宽度的比例
rect[1] = rect[1] / h # 将矩形框的y坐标转换为相对于图像高度的比例
rect[2] = rect[0] + rect[2] / w # 将矩形框的宽度转换为相对于图像宽度的比例
rect[3] = rect[1] + rect[3] / h # 将矩形框的高度转换为相对于图像高度的比例
gt_rect = list(ann['bbox']) # 获取标注区域的矩形框
gt_rect[0] = gt_rect[0] / w # 将矩形框的x坐标转换为相对于图像宽度的比例
gt_rect[1] = gt_rect[1] / h # 将矩形框的y坐标转换为相对于图像高度的比例
gt_rect[2] = gt_rect[0] + gt_rect[2] / w # 将矩形框的宽度转换为相对于图像宽度的比例
gt_rect[3] = gt_rect[1] + gt_rect[3] / h # 将矩形框的高度转换为相对于图像高度的比例
if iou >= 0.5: # 如果IoU大于等于0.5,则认为候选区域是正样本
pos_regions.append({'rect': rect,
'gt_rect': gt_rect,
'category': cat_dict[coco_dict[ann['category_id']]]})
else: # 否则,认为候选区域是负样本
neg_regions.append({'rect': rect,
'gt_rect': gt_rect,
'category': 0})
return pos_regions, neg_regions # 返回正样本区域和负样本区域
def main():
parser = argparse.ArgumentParser('parser to create regions') # 创建一个命令行参数解析器,用于处理命令行参数。
parser.add_argument('--data_dir', type=str, default='D:\\WritePapers\\object_detection_basics\\Datasets\\COCO2017\\') # 指定COCO2017数据集的路径
parser.add_argument('--mode', type=str, default='train') # train/val
parser.add_argument('--save_dir', type=str, default='D:\\WritePapers\\object_detection_basics\\Datasets\\COCO2017\\') #指定保存结果的路径
parser.add_argument('--cats', type=str, nargs='*', default=[
'bird', 'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe']) # 指定需要处理的类别
parser.add_argument('--scale', type=float, default=30.0) # 指定选择性搜索的尺度
parser.add_argument('--sigma', type=float, default=0.8) # 指定选择性搜索的高斯平滑参数
parser.add_argument('--min_size', type=int, default=50) # 指定选择性搜索的最小区域大小
args = parser.parse_args() # 解析命令行参数,并将结果保存在args中
coco = COCO(os.path.join(args.data_dir, 'annotations',
'instances_%s2017.json' % args.mode)) #加载COCO2017数据集的标注信息
cat_dict = {args.cats[i]: i+1 for i in range(len(args.cats))} # 创建一个字典,将类别名称映射到类别ID
cat_dict['background'] = 0 # 将背景类别的ID设置为0
# get relavant image ids
if args.mode == 'train':
num_cat = 400 # 如果运行模式为训练,则每个类别的图像数量设置为400
if args.mode == 'val':
num_cat = 100 # 如果运行模式为验证,则每个类别的图像数量设置为100
img_ids = []
cat_ids = coco.getCatIds(catNms=args.cats) # 获取需要处理的类别的ID
for cat_id in cat_ids:
cat_img_ids = coco.getImgIds(catIds=[cat_id]) # 获取该类别的所有图像ID
if len(cat_img_ids) > num_cat:
cat_img_ids = random.sample(cat_img_ids, num_cat) # 如果该类别的图像数量大于num_cat,则随机选择num_cat个图像
img_ids += cat_img_ids # 将选择的图像ID添加到图像ID列表
img_ids = list(set(img_ids)) # 去除重复的图像ID
# selective_search each image
# [{'id': 1, 'pos_regions':[...], 'neg_regions':[...]}, ...]
num_imgs = len(img_ids) # 获取图像的数量
ss_regions = [] # 初始化选择性搜索的区域列表
p = ProgressBar(widgets=['Progress: ', Percentage(),
' ', Bar('#'), ' ', Timer(), ' ', ETA()]) # 创建一个进度条
for i in p(range(num_imgs)): # 遍历每个图像
img_id = img_ids[i] # 获取当前图像的ID
pos_regions, neg_regions = ss_img(img_id, coco, cat_dict, args) # 对当前图像进行选择性搜索,获取正样本区域和负样本区域
ss_regions.append({'id': img_id,
'pos_regions': pos_regions,
'neg_regions': neg_regions})# 将当前图像的ID、正样本区域和负样本区域添加到选择性搜索的区域列表中
# save
with open(os.path.join(args.save_dir, '%s.json' % args.mode), 'w', encoding='utf-8') as f:
json.dump(ss_regions, f) # 将选择性搜索的区域列表保存为JSON格式
if __name__ == '__main__':
main()
3.设置ROI Pooling模块、特征提取网络模型及多目标损失函数
ROI Plooing模块
roipooling.py
import numpy as np
import torch
import torch.nn as nn
class ROIPooling(nn.Module):
def __init__(self, output_size): # 初始化函数,设置输出大小
super().__init__()
self.maxpool = nn.AdaptiveMaxPool2d(output_size) # 创建一个自适应最大池化层,输出大小为output_size
self.size = output_size # 设置输出大小
def forward(self, imgs, rois, roi_idx):
"""
:param img: img:批次内的图像
:param rois: rois:[[单张图片内框体],[],[]]
:param roi_idx: [2]*6------->[2, 2, 2, 2, 2, 2]
:return:
"""
n = rois.shape[0] # 获取roi的数量
h = imgs.shape[2] # 获取图像的高度
w = imgs.shape[3] # 获取图像的宽度
x1 = rois[:, 0] # 获取所有区域的左上角x坐标
y1 = rois[:, 1] # 获取所有区域的左上角y坐标
x2 = rois[:, 2] # 获取所有区域的右下角x坐标
y2 = rois[:, 3] # 获取所有区域的右下角y坐标
x1 = np.floor(x1 * w).astype(int) # 将x1坐标转换为图像的实际坐标
x2 = np.ceil(x2 * w).astype(int) # 将x2坐标转换为图像的实际坐标
y1 = np.floor(y1 * h).astype(int) # 将y1坐标转换为图像的实际坐标
y2 = np.ceil(y2 * h).astype(int) # 将y2坐标转换为图像的实际坐标
res = [] # 初始化结果列表
for i in range(n): # 遍历每个区域
img = imgs[roi_idx[i]].unsqueeze(dim=0) # 获取第i个区域所在的图像
img = img[:, :, y1[i]:y2[i], x1[i]:x2[i]] # 对图像进行裁剪,只保留区域内的部分
img = self.maxpool(img) # 对裁剪后的图像进行最大池化操作
res.append(img) # 将处理后的图像添加到结果列表中
res = torch.cat(res, dim=0) # 将所有处理后的图像沿着批次维度拼接起来,最终res保存了所有池化后的ROI区域
return res
if __name__ == '__main__':
import numpy as np
imgs = torch.randn(2, 10, 224, 224) # 创建一个随机的图像张量(batch_size, Channel, Height, Weight)
rois = np.array([[0.2, 0.2, 0.4, 0.4],
[0.5, 0.5, 0.7, 0.7],
[0.1, 0.1, 0.3, 0.3]]) # 创建一个随机的区域张量(x1, y1, x2, y2)
# roi_idx表示每个区域(Region of Interest,ROI)所在的图像的索引
# 表示有三个区域,前两个区域在第一张图像上(索引为0),第三个区域在第二张图像上(索引为1)
roi_idx = np.array([0, 0, 1])
r = ROIPooling((7, 7)) # (7, 7)表示池化后的输出大小为7x7。这意味着无论输入区域的大小如何,ROIPooling层都会将其池化为7x7的大小
print(r.forward(imgs, rois, roi_idx).shape)
fast_rcnn.py
import torch
import torch.nn as nn
import torchvision
from .roipooling import ROIPooling # 从当前目录下的roipooling模块导入ROIPooling类
class FastRCNN(nn.Module):
def __init__(self, num_classes):# 初始化方法,接收一个参数:类别数量
super().__init__()
self.num_classes = num_classes # 将类别数量保存为实例变量
vgg = torchvision.models.vgg19_bn(pretrained=True) # 加载预训练的VGG19模型
# 获取VGG19模型的特征提取部分:通过卷积和池化操作提取图像的特征
# vgg.features.children(): vgg.features获取VGG19模型的特征提取部分,children()方法获取这部分的所有子模块。这些子模块是一系列的卷积层、激活函数和池化层。
# list(vgg.features.children()): 将子模块的迭代器转换为列表
# list(vgg.features.children())[:-1]: 使用切片操作获取除最后一个子模块外的所有子模块。在VGG19模型中,最后一个子模块是一个池化层。
# *list(vgg.features.children())[:-1]: 使用*操作符将列表解包,这样每个子模块都会作为nn.Sequential的一个单独参数传入。
# nn.Sequential(*list(vgg.features.children())[:-1]): nn.Sequential是一个容器,它按照在构造函数中传入的顺序保存各个模块。
self.features = nn.Sequential(*list(vgg.features.children())[:-1])
self.roipool = ROIPooling(output_size=(7, 7)) # 创建ROIPooling层,输出大小为7x7
# vgg.classifier.children(): vgg.classifier获取VGG19模型的分类部分,children()方法获取这部分的所有子模块。这些子模块是一系列的全连接层、激活函数和Dropout层。
# list(vgg.classifier.children())[:-1]: 使用切片操作获取除最后一个子模块外的所有子模块。在VGG19模型中,最后一个子模块是一个全连接层,用于输出每个类别的概率。
self.output = nn.Sequential(*list(vgg.classifier.children())[:-1]) # 获取VGG19模型的分类部分
self.prob = nn.Linear(4096, num_classes+1)# 创建一个线性层,用于输出每个类别的概率
self.loc = nn.Linear(4096, 4 * (num_classes + 1)) # 创建一个线性层,用于输出每个类别的边界框位置
self.cat_loss = nn.CrossEntropyLoss() # 创建交叉熵损失函数,用于计算类别损失
self.loc_loss = nn.SmoothL1Loss() # 创建Smooth L1损失函数,用于计算位置损失
def forward(self, img, rois, roi_idx): # 接收三个参数:图像、区域、区域索引
"""
:param img: img:批次内的图像
:param rois: rois:[[单张图片内框体],[],[]]
:param roi_idx: [2]*6------->[2, 2, 2, 2, 2, 2]
:return:
"""
res = self.features(img) # 对图像进行特征提取
res = self.roipool(res, rois, roi_idx) # 对特征图进行ROIPooling
res = res.view(res.shape[0], -1) # 将ROIPooling的结果展平
features = self.output(res) # 对展平的结果进行分类
prob = self.prob(features) # 计算每个类别的概率
loc = self.loc(features).view(-1, self.num_classes+1, 4) # 计算每个类别的边界框位置
# 输出的张量的形状就变成了(N, num_classes + 1, 4),其中N是批次大小,num_classes + 1是类别数量(包括背景类别),4是边界框的参数数量。
# 相当于最终输出是==>每个图像都会输出:每个类别对应的一个边界框,这个边界框由4个参数确定。
return prob, loc
def loss(self, prob, bbox, label, gt_bbox, lmb=1.0): # 计算损失的方法,接收五个参数:预测类别概率、预测边界框、真实类别标签、真实边界框、lambda
"""
:param prob: 预测类别
:param bbox:预测边界框
:param label:真实类别
:param gt_bbox:真实边界框
:param lmb:
:return:
"""
loss_cat = self.cat_loss(prob, label) # 计算类别损失
lbl = label.view(-1, 1, 1).expand(label.size(0), 1, 4) # 将标签扩展为与边界框相同的形状 (N, 1, 4),N:标签的数量 1:每个标签对应一个边界框 4:边界框的参数数量
mask = (label != 0).float().view(-1, 1, 1).expand(label.shape[0], 1, 4) # 将标签扩展为与边界框相同的形状
loss_loc = self.loc_loss(gt_bbox * mask, bbox.gather(1, lbl).squeeze(1) * mask) # 计算位置损失
loss = loss_cat + lmb * loss_loc # 计算总损失
return loss, loss_cat, loss_loc # 返回总损失、类别损失和位置损失
4.训练网络模型
train.py
import argparse # 导入argparse模块,用于处理命令行参数
import numpy as np
import torch
import torchvision
from torch import nn, optim
from torchvision import transforms
from dataset import COCOdataset
from fast_rcnn import FastRCNN
from torch.utils.data import DataLoader
import tqdm
# 定义训练函数,输入参数为模型、训练数据集、优化器和命令行参数
# 训练时要用gpu,记得把参数--cuda的默认值改为True
def train(model, train_dataset, optimizer, args):
model.train()
num_batches = len(train_dataset) // args.batch_size # 计算批次数量
indexes = np.random.shuffle(np.arange(len(train_dataset))) # 随机打乱数据集的索引
# 初始化损失和准确率
loss_all = 0
loss_cat_all = 0
loss_loc_all = 0
accuracy = 0
num_samples = 0
# 遍历每个批次
for i in range(num_batches):
# 初始化图像、区域、ROI索引、相对位置和类别列表
imgs = []
rects = []
roi_idxs = []
rela_locs = []
cats = []
# 遍历每个样本
for j in range(args.batch_size):
# img:原始图像; rect:建议框体;roi_idx_len:正负样本框体总数;rela_loc:调整后框体;cat:类别
img, rect, roi_idx_len, rela_loc, cat = train_dataset[i *
args.batch_size+j]
# print(img, rect, roi_idx_len, gt_rect, cat)
# 添加到对应的列表中
imgs.append(img.unsqueeze(0))
rects += rect
rela_locs += rela_loc
roi_idxs += ([j] * roi_idx_len) # [2]*6------->[2, 2, 2, 2, 2, 2]
cats += cat
# 将列表转换为张量或数组
imgs = torch.cat(imgs, dim=0)
rects = np.array(rects)
rela_locs = torch.FloatTensor(rela_locs)
cats = torch.LongTensor(cats)
# print(imgs, rects, roi_idxs, rela_locs, cats)
# 如果使用CUDA,则将张量移动到GPU上
if args.cuda:
imgs = imgs.cuda()
rela_locs = rela_locs.cuda()
cats = cats.cuda()
# 清空梯度
optimizer.zero_grad()
# 前向传播,计算预测的概率和边界框
prob, bbox = model.forward(imgs, rects, roi_idxs)
# 计算损失
loss, loss_cat, loss_loc = model.loss(prob, bbox, cats, rela_locs)
# 反向传播,计算梯度
loss.backward()
# 更新参数
optimizer.step()
# 更新损失和准确率
num_samples += len(cats)
loss_all += loss.item() * len(cats)
loss_cat_all += loss_cat.item() * len(cats)
loss_loc_all += loss_loc.item() * len(cats)
accuracy += (torch.argmax(prob.detach(), dim=-1) == cats).sum().item()
# 返回模型、损失和准确率
return model, loss_all/num_samples, loss_cat_all/num_samples, loss_loc_all/num_samples, accuracy/num_samples
# 定义测试函数,输入参数为模型、验证数据集和命令行参数
def test(model, val_dataset, args):
model.eval()
num_batches = len(val_dataset) // args.batch_size # 计算批次数量
indexes = np.random.shuffle(np.arange(len(val_dataset))) # 随机打乱数据集的索引
# 初始化损失和准确率
loss_all = 0
loss_cat_all = 0
loss_loc_all = 0
accuracy = 0
num_samples = 0
# 遍历每个批次
for i in range(num_batches):
# 初始化图像、区域、ROI索引、相对位置和类别列表
imgs = []
rects = []
roi_idxs = []
rela_locs = []
cats = []
# 遍历每个样本
for j in range(args.batch_size):
# 加载图像、区域、ROI索引长度、相对位置和类别
img, rect, roi_idx_len, rela_loc, cat = val_dataset[i *
args.batch_size+j]
# print(img, rect, roi_idx_len, gt_rect, cat)
# 添加到对应的列表中
imgs.append(img.unsqueeze(0))
rects += rect
rela_locs += rela_loc
roi_idxs += ([j] * roi_idx_len)
cats += cat
# 将列表转换为张量或数组
imgs = torch.cat(imgs, dim=0)
rects = np.array(rects)
rela_locs = torch.FloatTensor(rela_locs)
cats = torch.LongTensor(cats)
# print(imgs, rects, roi_idxs, rela_locs, cats)
# 如果使用CUDA,则将张量移动到GPU
if args.cuda:
imgs = imgs.cuda()
rela_locs = rela_locs.cuda()
cats = cats.cuda()
# 前向传播,计算预测的概率和边界框
prob, bbox = model.forward(imgs, rects, roi_idxs)
# 计算损失
loss, loss_cat, loss_loc = model.loss(prob, bbox, cats, rela_locs)
# 更新损失和准确率
num_samples += len(cats)
loss_all += loss.item() * len(cats)
loss_cat_all += loss_cat.item() * len(cats)
loss_loc_all += loss_loc.item() * len(cats)
accuracy += (torch.argmax(prob.detach(), dim=-1) == cats).sum().item()
# 返回模型、损失和准确率
return model, loss_all/num_samples, loss_cat_all/num_samples, loss_loc_all/num_samples, accuracy/num_samples
def main():
parser = argparse.ArgumentParser('parser for fast-rcnn') # 创建一个命令行参数解析器
parser.add_argument('--batch_size', type=int, default=16) # 添加一个命令行参数--batch_size,用于指定批次大小,默认值为16
parser.add_argument('--num_classes', type=int, default=10) # 添加一个命令行参数--num_classes,用于指定类别数量,默认值为10
parser.add_argument('--learning_rate', type=float, default=2e-4) # 添加一个命令行参数--learning_rate,用于指定学习率,默认值为2e-4
parser.add_argument('--epochs', type=int, default=20) # 添加一个命令行参数--epochs,用于指定训练的轮数,默认值为20
parser.add_argument('--save_path', type=str,
default='./model/fast_rcnn.pkl') # 添加一个命令行参数--save_path,用于指定模型保存的路径,默认值为'./model/fast_rcnn.pkl'
parser.add_argument('--cuda', type=bool, default=False)
args = parser.parse_args() # 解析命令行参数,并将结果保存在args中
train_dataset = COCOdataset(mode='train') # 解析命令行参数,并将结果保存在args中
print("-----------------",train_dataset.__len__())
valid_dataset = COCOdataset(mode='val') # 创建一个COCOdataset实例,模式为'val'
print("-----------------", valid_dataset.__len__())
model = FastRCNN(num_classes=args.num_classes) # 创建一个FastRCNN模型实例,类别数量为args.num_classes
if args.cuda:# 如果args.cuda为True,则将模型移动到GPU上
model.cuda()
optimizer = optim.Adam(model.parameters(), lr=args.learning_rate) # 创建一个Adam优化器,优化目标为模型的参数,学习率为args.learning_rate
for epoch in range(args.epochs):# 对于每一个训练轮次
print("Epoch %d:" % epoch)# 打印当前轮次
model, train_loss, train_loss_cat, train_loss_loc, train_accuracy = train(
model, train_dataset, optimizer, args) # 调用train函数进行训练,并获取模型、总损失、类别损失、位置损失和准确率
print("Train: loss=%.4f, loss_cat=%.4f, loss_loc=%.4f, accuracy=%.4f" %
(train_loss, train_loss_cat, train_loss_loc, train_accuracy))# 打印训练的损失和准确率
model, valid_loss, valid_loss_cat, valid_loss_loc, valid_accuracy = test(
model, valid_dataset, args)# 打印训练的损失和准确率
print("Valid: loss=%.4f, loss_cat=%.4f, loss_loc=%.4f, accuracy=%.4f" %
(valid_loss, valid_loss_cat, valid_loss_loc, valid_accuracy))# 打印验证的损失和准确率
torch.save(model.state_dict(), args.save_path) # 将模型的状态字典保存到args.save_path指定的路径
if __name__ == '__main__':
main() # 如果当前脚本被直接运行,则调用main函数
5.测试
import argparse
import numpy as np
import skimage
import torch
import torchvision
from PIL import Image, ImageDraw, ImageFont
from selectivesearch import selective_search # 从selectivesearch模块导入selective_search函数,用于进行选择性搜索
from torchvision import transforms
from fast_rcnn import FastRCNN
# 测试时如果用gpu,则:
# 1. 将模型加载到gpu上:trained_net = torch.load(args.model),不加 map_location = 'cpu'
# 2. 把参数--cuda的默认值改为True
# 定义计算IoU(交并比)的函数,输入参数为两个矩形框
def cal_iou(a, b):
a_min_x, a_min_y, a_max_x, a_max_y = a
b_min_x, b_min_y, b_max_x, b_max_y = b
if min(a_max_y, b_max_y) < max(a_min_y, b_min_y) or min(a_max_x, b_max_x) < max(a_min_x, b_min_x):
return 0
else:
intersect_area = (min(a_max_y, b_max_y) - max(a_min_y, b_min_y) + 1) * \
(min(a_max_x, b_max_x) - max(a_min_x, b_min_x) + 1)
union_area = (a_max_x - a_min_x + 1) * (a_max_y - a_min_y + 1) + \
(b_max_x - b_min_x + 1) * (b_max_y - b_min_y + 1) - intersect_area
return intersect_area / union_area
def main():
parser = argparse.ArgumentParser('parser for testing fast-rcnn')
parser.add_argument('--jpg_path', type=str,
default='D:\\WritePapers\\object_detection_basics\\Datasets\\COCO2017\\val2017\\000000241326.jpg')# 添加一个命令行参数--jpg_path,用于指定待测试的图像的路径,默认值为'/devdata/project/ai_learn/COCO2017/val2017/000000241326.jpg'
parser.add_argument('--save_path', type=str, default='sample.png')
parser.add_argument('--save_type', type=str, default='png')
parser.add_argument('--model', type=str, default='./model/fast_rcnn.pkl') # 添加一个命令行参数--model,用于指定模型的路径,默认值为'./model/fast_rcnn.pkl'
parser.add_argument('--num_classes', type=int, default=10)
parser.add_argument('--scale', type=float, default=30.0) # 添加一个命令行参数--scale,用于指定选择性搜索的尺度,默认值为30.0
parser.add_argument('--sigma', type=float, default=0.8) # 添加一个命令行参数--sigma,用于指定选择性搜索的高斯平滑参数,默认值为0.8
parser.add_argument('--min_size', type=int, default=50) # 添加一个命令行参数--min_size,用于指定选择性搜索的最小区域大小,默认值为50
parser.add_argument('--cats', type=str, nargs='*', default=[
'bird', 'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe']) # 添加一个命令行参数--cats,用于指定需要处理的类别,默认值为一系列动物的名称
parser.add_argument('--cuda', type=bool, default=False)
args = parser.parse_args() # 解析命令行参数,并将结果保存在args中
# trained_net = torch.load(args.model) # 加载模型
trained_net = torch.load(args.model, map_location = 'cpu') # 加载模型
model = FastRCNN(num_classes=args.num_classes) # 创建一个FastRCNN模型实例,类别数量为args.num_classes
model.load_state_dict(trained_net) # 将加载的模型的状态字典加载到FastRCNN模型实例中
if args.cuda: # 如果args.cuda为True,则将模型移动到GPU上
model.cuda()
img = skimage.io.imread(args.jpg_path) # 读取图像
h = img.shape[0] # 获取图像的高度
w = img.shape[1] # 获取图像的宽度
_, ss_regions = selective_search(
img, args.scale, args.sigma, args.min_size) # 对图像进行选择性搜索,获取候选区域
rois = []
for region in ss_regions: # 遍历每个候选区域
rect = list(region['rect']) # 获取候选区域的矩形框
rect[0] = rect[0] / w # 将矩形框的x坐标转换为相对于图像宽度的比例
rect[1] = rect[1] / h # 将矩形框的y坐标转换为相对于图像高度的比例
rect[2] = rect[0] + rect[2] / w # 将矩形框的宽度转换为相对于图像宽度的比例
rect[3] = rect[1] + rect[3] / h # 将矩形框的高度转换为相对于图像高度的比例
rois.append(rect) # 将处理后的矩形框添加到列表中
img = Image.fromarray(img) # 将图像数组转换为PIL图像
img_tensor = img.resize([224, 224]) # 将图像大小调整为224x224
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize([
0.485, 0.456, -.406], [0.229, 0.224, 0.225])]) # 创建一个图像预处理管道,包括将PIL图像转换为张量和标准化
img_tensor = transform(img_tensor).unsqueeze(0) # 对图像进行预处理,并添加一个新的维度
if args.cuda: # 如果args.cuda为True,则将图像张量移动到GPU
img_tensor = img_tensor.cuda()
rois = np.array(rois) # 将候选区域的列表转换为数组
roi_idx = [0] * rois.shape[0] # 创建一个列表,长度为候选区域的数量,所有元素都为0
prob, rela_loc = model.forward(img_tensor, rois, roi_idx) # 前向传播,计算预测的概率和边界框
prob = torch.nn.Softmax(dim=-1)(prob).cpu().detach().numpy() # 对预测的概率进行softmax操作,并将结果转换为numpy数组
# rela_loc = rela_loc.cpu().detach().numpy()[:, 1:, :].mean(axis=1)
labels = []
max_probs = []
bboxs = []
for i in range(len(prob)): # 遍历每个预测的概率
if prob[i].max() > 0.8 and np.argmax(prob[i], axis=0) != 0: # 如果最大概率大于0.8且对应的类别不是背景,则认为候选区域是有效的
# proposal regions is directly used because of limited training epochs, bboxs predicted are not precise
# bbox = [(rois[i][2] - rois[i][0]) * rela_loc[i][0] + 0.5 * (rois[i][2] + rois[i][0]),
# (rois[i][3] - rois[i][1]) * rela_loc[i][1] + 0.5 * (rois[i][3] + rois[i][1]),
# np.exp(rela_loc[i][2]) * rois[i][2],
# np.exp(rela_loc[i][3]) * rois[i][3]]
# bbox = [bbox[0] - 0.5 * bbox[2],
# bbox[1] - 0.5 * bbox[3],
# bbox[0] + 0.5 * bbox[2],
# bbox[1] + 0.5 * bbox[3]]
labels.append(np.argmax(prob[i], axis=0)) # 将有效候选区域的类别添加到列表中
max_probs.append(prob[i].max()) # 将有效候选区域的最大概率添加到列表中
rois[i] = [int(w * rois[i][0]), int(h * rois[i][1]),
int(w * rois[i][2]), int(w * rois[i][3])] # 将候选区域的矩形框的坐标和大小转换为相对于原图的像素值
bboxs.append(rois[i]) # 将处理后的矩形框添加到列表中
labels = np.array(labels) # 将类别的列表转换为数组
max_probs = np.array(max_probs) # 将最大概率的列表转换为数组
bboxs = np.array(bboxs) # 将矩形框的列表转换为数组
order = np.argsort(-max_probs) # 对最大概率进行降序排序,获取排序后的索引
labels = labels[order] # 根据排序的索引重新排序类别
max_probs = max_probs[order]
bboxs = bboxs[order]
# 下面的代码是进行非极大值抑制(NMS),用于去除重叠的候选区域
nms_labels = []
nms_probs = []
nms_bboxs = []
del_indexes = []
for i in range(len(labels)):
if i not in del_indexes:
for j in range(len(labels)):
if j not in del_indexes and cal_iou(bboxs[i], bboxs[j]) > 0.3:
del_indexes.append(j)
nms_labels.append(labels[i])
nms_probs.append(max_probs[i])
nms_bboxs.append(bboxs[i])
# 将预测结果绘制到图像上
cat_dict = {(i + 1): args.cats[i] for i in range(len(args.cats))}
cat_dict[0] = 'background'
font = ImageFont.truetype('./fonts/chinese_cht.ttf', size=16)
draw = ImageDraw.Draw(img)
for i in range(len(nms_labels)):
draw.polygon([(nms_bboxs[i][0], nms_bboxs[i][1]), (nms_bboxs[i][2], nms_bboxs[i][1]),
(nms_bboxs[i][2], nms_bboxs[i][3]), (nms_bboxs[i][0], nms_bboxs[i][3])], outline=(255, 0, 0))
draw.text((nms_bboxs[i][0] + 5, nms_bboxs[i][1] + 5), '%s %.2f%%' % (
cat_dict[nms_labels[i]], 100 * max_probs[i]), fill=(255, 0, 0), font=font)
img.save(args.save_path, args.save_type) # 将绘制了预测结果的图像保存到指定的路径
if __name__ == '__main__':
main()
测试结果如下:

参考资料
1.博客:目标检测 pytorch复现Fast_RCNN目标检测项目-CSDN博客
2.COCO数据集下载:
训练集: http://images.cocodataset.org/zips/train2017.zip 验证集: http://images.cocodataset.org/zips/val2017.zip 训练集和验证集对应的标签: http://images.cocodataset.org/annotations/annotations_trainval2017.zip 测试集: http://images.cocodataset.org/zips/test2017.zip















 1611
1611











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









