






 该文介绍了使用PyTorch复现Fast_RCNN目标检测模型的过程,包括初始化COCO数据集、应用SelectiveSearch生成候选框、设置ROIPooling模块、构建VGG19特征提取网络、定义多任务损失函数、训练网络及测试模型性能。项目提供了从数据预处理到模型训练和测试的完整流程。
该文介绍了使用PyTorch复现Fast_RCNN目标检测模型的过程,包括初始化COCO数据集、应用SelectiveSearch生成候选框、设置ROIPooling模块、构建VGG19特征提取网络、定义多任务损失函数、训练网络及测试模型性能。项目提供了从数据预处理到模型训练和测试的完整流程。
目标检测 pytorch复现Fast_RCNN目标检测项目
目标检测 pytorch复现R-CNN目标检测项目
项目源代码下载地址:https://download.csdn.net/download/guoqingru0311/87793353
0、原理简介
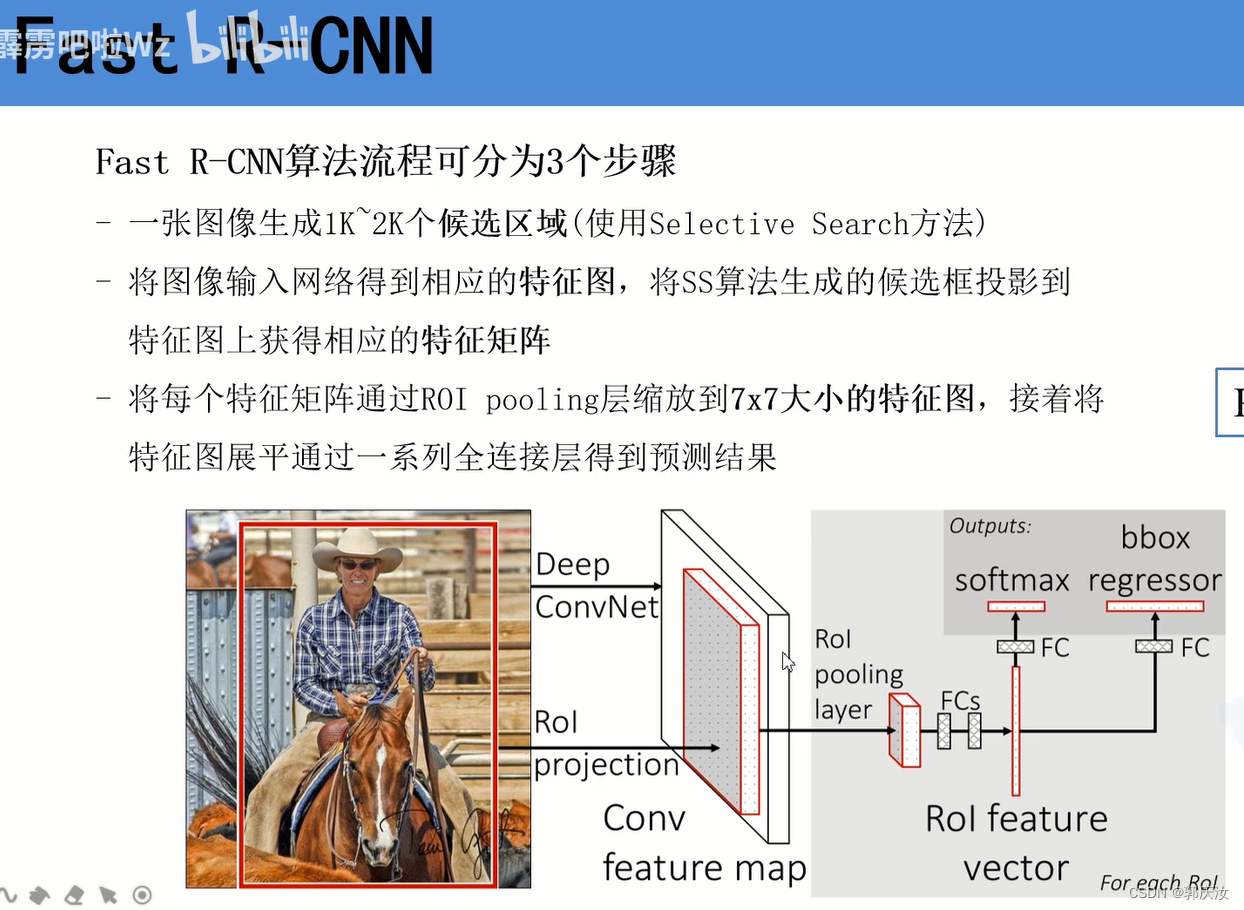
基本流程与R-CNN流程相似,只不过为了减小计算量,加入了ROI Pooling,先利用selective search算法生成系列的候选建议框,将候选区域矿映射到图像经特征提取网路得到的特征图上,大幅度的减小计算量,同时损失函数采用了多任务损失,即交叉熵损失(用于分类)+Smooth L1 Loss(边界框回归)
利用coco2017数据集训练Fast-RCNN模型(训练过程详细步骤记录):
(1)检测数据集利用选择搜索算法(selective-search)生成一定数量的候选框,
(2)将候选框与真实标注框进行IOU(交并比)计算,将真是标注框的作为正样本,将0.1<IOU<0.5的当做负样本
(3)设计网络骨干模型,利用VGG19,利用ROIPlooing方法将建议框映射到输出特征层
(4)设置输出为一个分类分支(类别类数+背景类(1))与标注回归分支
(5)设置交叉熵损失与回归损失
(6)训练网络模型
目录结构如下所示:
1、初始化COCO数据集相关类:
COCOdataset.py
"/devdata/project/ai_learn/COCO2017/"为coco数据集路径地址
import json
import os
import random
import PIL
import torch
from torch.utils.data import Dataset
from torchvision import transforms
import math
class COCOdataset(Dataset):
def __init__(self, dir='/devdata/project/ai_learn/COCO2017/', mode='val',
transform=transforms.Compose([transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, -.406], [0.229, 0.224, 0.225])])):
assert mode in ['train', 'val'], 'mode must be \'train\' or \'val\''
self.dir = dir
self.mode = mode
self.transform = transform
with open(os.path.join(self.dir, '%s.json' % self.mode), 'r', encoding='utf-8') as f:
self.ss_regions = json.load(f)
self.img_dir = os.path.join(self.dir, '%s2017' % self.mode)
def __len__(self):
return len(self.ss_regions)
def __getitem__(self, i, max_num_pos=8, max_num_neg=16):
img = PIL.Image.open(os.path.join(self.img_dir, '%012d.jpg' %
self.ss_regions[i]['id']))
img = img.convert('RGB')
img = img.resize([224, 224])
pos_regions = self.ss_regions[i]['pos_regions']
neg_regions = self.ss_regions[i]['neg_regions']
if self.transform != None:
img = self.transform(img)
if len(pos_regions) > max_num_pos:
pos_regions = random.sample(pos_regions, max_num_pos)
if len(neg_regions) > max_num_neg:
neg_regions = random.sample(neg_regions, max_num_neg)
regions = pos_regions + neg_regions
random.shuffle(regions)
rects = []
rela_locs = []
cats = []
for region in regions:
rects.append(region['rect'])
p_rect = region['rect']
g_rect = region['gt_rect']
t_x = (g_rect[0] + g_rect[2] - p_rect[0] - p_rect[2]) / 2 / (p_rect[2] - p_rect[0])
t_y = (g_rect[1] + g_rect[3] - p_rect[1] - p_rect[3]) / 2 / (p_rect[3] - p_rect[1])
t_w = math.log((g_rect[2] - g_rect[0]) / (p_rect[2] - p_rect[0]))
t_h = math.log((g_rect[3] - g_rect[1]) / (p_rect[3] - p_rect[1]))
rela_locs.append([t_x, t_y, t_w, t_h])
cats.append(region['category'])
roi_idx_len = len(regions)
return img, rects, roi_idx_len, rela_locs, cats
# dataset = COCOdataset()
# print(dataset[1][0].shape)
# print(dataset[1][1])
# from torch.utils.data import DataLoader
# dataloader = DataLoader(dataset, batch_size=2)
# print(next(iter(dataloader))[1])
if __name__ == '__main__':
dataset = COCOdataset()
print(dataset.__len__())
img, rects, roi_idx_len, rela_locs, cats = dataset.__getitem__(10)
print(img, rects, roi_idx_len, rela_locs, cats)
from torch.utils.data import DataLoader
loader = DataLoader(dataset, batch_size=1)
for i, temp in enumerate(loader):
print(i,type(temp))
2、利用selective search算法生成推荐框,得到负样本标注框
create_region.py
import argparse
import json
import os
import random
import sys
import time
from progressbar import *
from pycocotools.coco import COCO
from selectivesearch import selective_search
from skimage import io, util, color
def cal_iou(a, b):
a_min_x, a_min_y, a_delta_x, a_delta_y = a
b_min_x, b_min_y, b_delta_x, b_delta_y = b
a_max_x = a_min_x + a_delta_x
a_max_y = a_min_y + a_delta_y
b_max_x = b_min_x + b_delta_x
b_max_y = b_min_y + b_delta_y
if min(a_max_y, b_max_y) < max(a_min_y, b_min_y) or min(a_max_x, b_max_x) < max(a_min_x, b_min_x):
return 0
else:
intersect_area = (min(a_max_y, b_max_y) - max(a_min_y, b_min_y) + 1) * \
(min(a_max_x, b_max_x) - max(a_min_x, b_min_x) + 1)
union_area = (a_delta_x + 1) * (a_delta_y + 1) + \
(b_delta_x + 1) * (b_delta_y + 1) - intersect_area
return intersect_area / union_area
def ss_img(img_id, coco, cat_dict, args):
img_path = os.path.join(args.data_dir, args.mode +
'2017', '%012d.jpg' % img_id)
coco_dict = {cat['id']: cat['name']
for cat in coco.loadCats(coco.getCatIds())}
img = io.imread(img_path)
if img.ndim == 2: # Python 中灰度图的 img.ndim = 2
img = color.gray2rgb(img)
_, ss_regions = selective_search(
img, args.scale, args.sigma, args.min_size) # 'rect': (left, top, width, height)
anns = coco.loadAnns(coco.getAnnIds(
imgIds=[img_id], catIds=coco.getCatIds(catNms=args.cats)))
pos_regions = []
neg_regions = []
h = img.shape[0]
w = img.shape[1]
for region in ss_regions:
for ann in anns:
iou = cal_iou(region['rect'], ann['bbox'])
if iou >= 0.1:
rect = list(region['rect'])
rect[0] = rect[0] / w
rect[1] = rect[1] / h
rect[2] = rect[0] + rect[2] / w
rect[3] = rect[1] + rect[3] / h
gt_rect = list(ann['bbox'])
gt_rect[0] = gt_rect[0] / w
gt_rect[1] = gt_rect[1] / h
gt_rect[2] = gt_rect[0] + gt_rect[2] / w
gt_rect[3] = gt_rect[1] + gt_rect[3] / h
if iou >= 0.5:
pos_regions.append({'rect': rect,
'gt_rect': gt_rect,
'category': cat_dict[coco_dict[ann['category_id']]]})
else:
neg_regions.append({'rect': rect,
'gt_rect': gt_rect,
'category': 0})
return pos_regions, neg_regions
def main():
parser = argparse.ArgumentParser('parser to create regions')
parser.add_argument('--data_dir', type=str, default='/devdata/project/ai_learn/COCO2017/')
parser.add_argument('--mode', type=str, default='val') # train/val
parser.add_argument('--save_dir', type=str, default='/devdata/project/ai_learn/COCO2017/')
parser.add_argument('--cats', type=str, nargs='*', default=[
'bird', 'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe'])
parser.add_argument('--scale', type=float, default=30.0)
parser.add_argument('--sigma', type=float, default=0.8)
parser.add_argument('--min_size', type=int, default=50)
args = parser.parse_args()
coco = COCO(os.path.join(args.data_dir, 'annotations',
'instances_%s2017.json' % args.mode))
cat_dict = {args.cats[i]: i+1 for i in range(len(args.cats))}
cat_dict['background'] = 0
# get relavant image ids
if args.mode == 'train':
num_cat = 400
if args.mode == 'val':
num_cat = 100
img_ids = []
cat_ids = coco.getCatIds(catNms=args.cats)
for cat_id in cat_ids:
cat_img_ids = coco.getImgIds(catIds=[cat_id])
if len(cat_img_ids) > num_cat:
cat_img_ids = random.sample(cat_img_ids, num_cat)
img_ids += cat_img_ids
img_ids = list(set(img_ids))
# selective_search each image
# [{'id': 1, 'pos_regions':[...], 'neg_regions':[...]}, ...]
num_imgs = len(img_ids)
ss_regions = []
p = ProgressBar(widgets=['Progress: ', Percentage(),
' ', Bar('#'), ' ', Timer(), ' ', ETA()])
for i in p(range(num_imgs)):
img_id = img_ids[i]
pos_regions, neg_regions = ss_img(img_id, coco, cat_dict, args)
ss_regions.append({'id': img_id,
'pos_regions': pos_regions,
'neg_regions': neg_regions})
# save
with open(os.path.join(args.save_dir, '%s.json' % args.mode), 'w', encoding='utf-8') as f:
json.dump(ss_regions, f)
if __name__ == '__main__':
main()
3、设置ROI Plooing模块、特征提取网络模型以及多目标损失函数
fast_rcnn.py
import torch
import torch.nn as nn
import torchvision
from .roipooling import ROIPooling
class FastRCNN(nn.Module):
def __init__(self, num_classes):
super().__init__()
self.num_classes = num_classes
vgg = torchvision.models.vgg19_bn(pretrained=True)
self.features = nn.Sequential(*list(vgg.features.children())[:-1])
self.roipool = ROIPooling(output_size=(7, 7))
self.output = nn.Sequential(*list(vgg.classifier.children())[:-1])
self.prob = nn.Linear(4096, num_classes+1)
self.loc = nn.Linear(4096, 4 * (num_classes + 1))
self.cat_loss = nn.CrossEntropyLoss()
self.loc_loss = nn.SmoothL1Loss()
def forward(self, img, rois, roi_idx):
"""
:param img: img:批次内的图像
:param rois: rois:[[单张图片内框体],[],[]]
:param roi_idx: [2]*6------->[2, 2, 2, 2, 2, 2]
:return:
"""
res = self.features(img)
res = self.roipool(res, rois, roi_idx)
res = res.view(res.shape[0], -1)
features = self.output(res)
prob = self.prob(features)
loc = self.loc(features).view(-1, self.num_classes+1, 4)
return prob, loc
def loss(self, prob, bbox, label, gt_bbox, lmb=1.0):
"""
:param prob: 预测类别
:param bbox:预测边界框
:param label:真实类别
:param gt_bbox:真实边界框
:param lmb:
:return:
"""
loss_cat = self.cat_loss(prob, label)
lbl = label.view(-1, 1, 1).expand(label.size(0), 1, 4)
mask = (label != 0).float().view(-1, 1, 1).expand(label.shape[0], 1, 4)
loss_loc = self.loc_loss(gt_bbox * mask, bbox.gather(1, lbl).squeeze(1) * mask)
loss = loss_cat + lmb * loss_loc
return loss, loss_cat, loss_loc
ROI Plooing模块
roipooling.py
import numpy as np
import torch
import torch.nn as nn
class ROIPooling(nn.Module):
def __init__(self, output_size):
super().__init__()
self.maxpool = nn.AdaptiveMaxPool2d(output_size)
self.size = output_size
def forward(self, imgs, rois, roi_idx):
"""
:param img: img:批次内的图像
:param rois: rois:[[单张图片内框体],[],[]]
:param roi_idx: [2]*6------->[2, 2, 2, 2, 2, 2]
:return:
"""
n = rois.shape[0]
h = imgs.shape[2]
w = imgs.shape[3]
x1 = rois[:, 0]
y1 = rois[:, 1]
x2 = rois[:, 2]
y2 = rois[:, 3]
x1 = np.floor(x1 * w).astype(int)
x2 = np.ceil(x2 * w).astype(int)
y1 = np.floor(y1 * h).astype(int)
y2 = np.ceil(y2 * h).astype(int)
res = []
for i in range(n):
img = imgs[roi_idx[i]].unsqueeze(dim=0)
img = img[:, :, y1[i]:y2[i], x1[i]:x2[i]]
img = self.maxpool(img)
res.append(img)
res = torch.cat(res, dim=0)
return res
if __name__ == '__main__':
import numpy as np
img = torch.randn(2, 10, 224, 224)
rois = np.array([[0.2, 0.2, 0.4, 0.4],
[0.5, 0.5, 0.7, 0.7],
[0.1, 0.1, 0.3, 0.3]])
roi_idx = np.array([0, 0, 1])
r = ROIPooling((7, 7))
print(r.forward(img, rois, roi_idx).shape)
4、训练网络模型
train.py
import argparse
import numpy as np
import torch
import torchvision
from torch import nn, optim
from torchvision import transforms
from dataset import COCOdataset
from fast_rcnn import FastRCNN
from torch.utils.data import DataLoader
import tqdm
def train(model, train_dataset, optimizer, args):
model.train()
num_batches = len(train_dataset) // args.batch_size
indexes = np.random.shuffle(np.arange(len(train_dataset)))
loss_all = 0
loss_cat_all = 0
loss_loc_all = 0
accuracy = 0
num_samples = 0
for i in range(num_batches):
imgs = []
rects = []
roi_idxs = []
rela_locs = []
cats = []
for j in range(args.batch_size):
# img:原始头像; rect:建议框体;roi_idx_len:正负样本框体总数;rela_loc:调整后框体;cat:类别
img, rect, roi_idx_len, rela_loc, cat = train_dataset[i *
args.batch_size+j]
# print(img, rect, roi_idx_len, gt_rect, cat)
imgs.append(img.unsqueeze(0))
rects += rect
rela_locs += rela_loc
roi_idxs += ([j] * roi_idx_len) # [2]*6------->[2, 2, 2, 2, 2, 2]
cats += cat
imgs = torch.cat(imgs, dim=0)
rects = np.array(rects)
rela_locs = torch.FloatTensor(rela_locs)
cats = torch.LongTensor(cats)
# print(imgs, rects, roi_idxs, rela_locs, cats)
if args.cuda:
imgs = imgs.cuda()
rela_locs = rela_locs.cuda()
cats = cats.cuda()
optimizer.zero_grad()
prob, bbox = model.forward(imgs, rects, roi_idxs)
loss, loss_cat, loss_loc = model.loss(prob, bbox, cats, rela_locs)
loss.backward()
optimizer.step()
num_samples += len(cats)
loss_all += loss.item() * len(cats)
loss_cat_all += loss_cat.item() * len(cats)
loss_loc_all += loss_loc.item() * len(cats)
accuracy += (torch.argmax(prob.detach(), dim=-1) == cats).sum().item()
return model, loss_all/num_samples, loss_cat_all/num_samples, loss_loc_all/num_samples, accuracy/num_samples
def test(model, val_dataset, args):
model.eval()
num_batches = len(val_dataset) // args.batch_size
indexes = np.random.shuffle(np.arange(len(val_dataset)))
loss_all = 0
loss_cat_all = 0
loss_loc_all = 0
accuracy = 0
num_samples = 0
for i in range(num_batches):
imgs = []
rects = []
roi_idxs = []
rela_locs = []
cats = []
for j in range(args.batch_size):
img, rect, roi_idx_len, rela_loc, cat = val_dataset[i *
args.batch_size+j]
# print(img, rect, roi_idx_len, gt_rect, cat)
imgs.append(img.unsqueeze(0))
rects += rect
rela_locs += rela_loc
roi_idxs += ([j] * roi_idx_len)
cats += cat
imgs = torch.cat(imgs, dim=0)
rects = np.array(rects)
rela_locs = torch.FloatTensor(rela_locs)
cats = torch.LongTensor(cats)
# print(imgs, rects, roi_idxs, rela_locs, cats)
if args.cuda:
imgs = imgs.cuda()
rela_locs = rela_locs.cuda()
cats = cats.cuda()
prob, bbox = model.forward(imgs, rects, roi_idxs)
loss, loss_cat, loss_loc = model.loss(prob, bbox, cats, rela_locs)
num_samples += len(cats)
loss_all += loss.item() * len(cats)
loss_cat_all += loss_cat.item() * len(cats)
loss_loc_all += loss_loc.item() * len(cats)
accuracy += (torch.argmax(prob.detach(), dim=-1) == cats).sum().item()
return model, loss_all/num_samples, loss_cat_all/num_samples, loss_loc_all/num_samples, accuracy/num_samples
def main():
parser = argparse.ArgumentParser('parser for fast-rcnn')
parser.add_argument('--batch_size', type=int, default=16)
parser.add_argument('--num_classes', type=int, default=10)
parser.add_argument('--learning_rate', type=float, default=2e-4)
parser.add_argument('--epochs', type=int, default=20)
parser.add_argument('--save_path', type=str,
default='./model/fast_rcnn.pkl')
parser.add_argument('--cuda', type=bool, default=True)
args = parser.parse_args()
train_dataset = COCOdataset(mode='train')
print("-----------------",train_dataset.__len__())
valid_dataset = COCOdataset(mode='val')
print("-----------------", valid_dataset.__len__())
model = FastRCNN(num_classes=args.num_classes)
if args.cuda:
model.cuda()
optimizer = optim.Adam(model.parameters(), lr=args.learning_rate)
for epoch in range(args.epochs):
print("Epoch %d:" % epoch)
model, train_loss, train_loss_cat, train_loss_loc, train_accuracy = train(
model, train_dataset, optimizer, args)
print("Train: loss=%.4f, loss_cat=%.4f, loss_loc=%.4f, accuracy=%.4f" %
(train_loss, train_loss_cat, train_loss_loc, train_accuracy))
model, valid_loss, valid_loss_cat, valid_loss_loc, valid_accuracy = test(
model, valid_dataset, args)
print("Valid: loss=%.4f, loss_cat=%.4f, loss_loc=%.4f, accuracy=%.4f" %
(valid_loss, valid_loss_cat, valid_loss_loc, valid_accuracy))
torch.save(model.state_dict(), args.save_path)
if __name__ == '__main__':
main()
5、测试模型效果
test.py
import argparse
import numpy as np
import skimage
import torch
import torchvision
from PIL import Image, ImageDraw, ImageFont
from selectivesearch import selective_search
from torchvision import transforms
from fast_rcnn import FastRCNN
def cal_iou(a, b):
a_min_x, a_min_y, a_max_x, a_max_y = a
b_min_x, b_min_y, b_max_x, b_max_y = b
if min(a_max_y, b_max_y) < max(a_min_y, b_min_y) or min(a_max_x, b_max_x) < max(a_min_x, b_min_x):
return 0
else:
intersect_area = (min(a_max_y, b_max_y) - max(a_min_y, b_min_y) + 1) * \
(min(a_max_x, b_max_x) - max(a_min_x, b_min_x) + 1)
union_area = (a_max_x - a_min_x + 1) * (a_max_y - a_min_y + 1) + \
(b_max_x - b_min_x + 1) * (b_max_y - b_min_y + 1) - intersect_area
return intersect_area / union_area
def main():
parser = argparse.ArgumentParser('parser for testing fast-rcnn')
parser.add_argument('--jpg_path', type=str,
default='/devdata/project/ai_learn/COCO2017/val2017/000000241326.jpg')
parser.add_argument('--save_path', type=str, default='sample.png')
parser.add_argument('--save_type', type=str, default='png')
parser.add_argument('--model', type=str, default='./model/fast_rcnn.pkl')
parser.add_argument('--num_classes', type=int, default=10)
parser.add_argument('--scale', type=float, default=30.0)
parser.add_argument('--sigma', type=float, default=0.8)
parser.add_argument('--min_size', type=int, default=50)
parser.add_argument('--cats', type=str, nargs='*', default=[
'bird', 'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe'])
parser.add_argument('--cuda', type=bool, default=True)
args = parser.parse_args()
trained_net = torch.load(args.model)
model = FastRCNN(num_classes=args.num_classes)
model.load_state_dict(trained_net)
if args.cuda:
model.cuda()
img = skimage.io.imread(args.jpg_path)
h = img.shape[0]
w = img.shape[1]
_, ss_regions = selective_search(
img, args.scale, args.sigma, args.min_size)
rois = []
for region in ss_regions:
rect = list(region['rect'])
rect[0] = rect[0] / w
rect[1] = rect[1] / h
rect[2] = rect[0] + rect[2] / w
rect[3] = rect[1] + rect[3] / h
rois.append(rect)
img = Image.fromarray(img)
img_tensor = img.resize([224, 224])
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize([
0.485, 0.456, -.406], [0.229, 0.224, 0.225])])
img_tensor = transform(img_tensor).unsqueeze(0)
if args.cuda:
img_tensor = img_tensor.cuda()
rois = np.array(rois)
roi_idx = [0] * rois.shape[0]
prob, rela_loc = model.forward(img_tensor, rois, roi_idx)
prob = torch.nn.Softmax(dim=-1)(prob).cpu().detach().numpy()
# rela_loc = rela_loc.cpu().detach().numpy()[:, 1:, :].mean(axis=1)
labels = []
max_probs = []
bboxs = []
for i in range(len(prob)):
if prob[i].max() > 0.8 and np.argmax(prob[i], axis=0) != 0:
# proposal regions is directly used because of limited training epochs, bboxs predicted are not precise
# bbox = [(rois[i][2] - rois[i][0]) * rela_loc[i][0] + 0.5 * (rois[i][2] + rois[i][0]),
# (rois[i][3] - rois[i][1]) * rela_loc[i][1] + 0.5 * (rois[i][3] + rois[i][1]),
# np.exp(rela_loc[i][2]) * rois[i][2],
# np.exp(rela_loc[i][3]) * rois[i][3]]
# bbox = [bbox[0] - 0.5 * bbox[2],
# bbox[1] - 0.5 * bbox[3],
# bbox[0] + 0.5 * bbox[2],
# bbox[1] + 0.5 * bbox[3]]
labels.append(np.argmax(prob[i], axis=0))
max_probs.append(prob[i].max())
rois[i] = [int(w * rois[i][0]), int(h * rois[i][1]),
int(w * rois[i][2]), int(w * rois[i][3])]
bboxs.append(rois[i])
labels = np.array(labels)
max_probs = np.array(max_probs)
bboxs = np.array(bboxs)
order = np.argsort(-max_probs)
labels = labels[order]
max_probs = max_probs[order]
bboxs = bboxs[order]
nms_labels = []
nms_probs = []
nms_bboxs = []
del_indexes = []
for i in range(len(labels)):
if i not in del_indexes:
for j in range(len(labels)):
if j not in del_indexes and cal_iou(bboxs[i], bboxs[j]) > 0.4:
del_indexes.append(j)
nms_labels.append(labels[i])
nms_probs.append(max_probs[i])
nms_bboxs.append(bboxs[i])
cat_dict = {(i + 1): args.cats[i] for i in range(len(args.cats))}
cat_dict[0] = 'background'
font = ImageFont.truetype('./fonts/chinese_cht.ttf', size=16)
draw = ImageDraw.Draw(img)
for i in range(len(nms_labels)):
draw.polygon([(nms_bboxs[i][0], nms_bboxs[i][1]), (nms_bboxs[i][2], nms_bboxs[i][1]),
(nms_bboxs[i][2], nms_bboxs[i][3]), (nms_bboxs[i][0], nms_bboxs[i][3])], outline=(255, 0, 0))
draw.text((nms_bboxs[i][0] + 5, nms_bboxs[i][1] + 5), '%s %.2f%%' % (
cat_dict[nms_labels[i]], 100 * max_probs[i]), fill=(255, 0, 0), font=font)
img.save(args.save_path, args.save_type)
if __name__ == '__main__':
main()



















 1933
1933

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









