







文章所涉及知识追踪模型:DIMKT、QIKT、AT-DKT、sparseKT、a survey、DTransformer、OKT……将持续更新
DIMKT:Assessing Student’s Dynamic Knowledge State by Exploring the Question Difficulty Effect
ACM SIGIR 2022
提出了DIfficulty Matching Knowledge Tracing(DIMKT)模型,通过建立学生知识状态和问题难度水平之间的关系来衡量问题难度效应,提高KT的表现。
创新点
(1)提出了一种新的DIfficulty Matching Knowledge Tracing(DIMKT)模型来衡量问题难度对学习的影响
(2)设计了一个自适应序列神经网络(ASNN),以建立学生在实践过程中的知识状态与问题难度水平之间的关系
(3)证明了DIMKT的有效性,DIMKT还具有出色的可解释性
模型
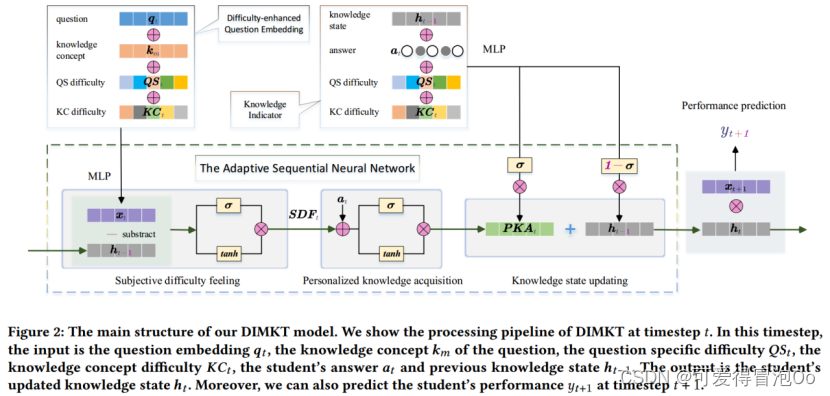
输入是问题qt、知识概念km、问题特定难度QSt、知识概念难度KCt, 学生的回答at和先前的知识状态ht-1.首先利用问题特定难度和知识概念难度来增强问题嵌入。然后,设计了一个自适应序列神经网络(ASNN)来捕捉DNKT中知识状态和问题难度之间的联系,包括练习前的主观难度感受模块、练习中的个性化知识获取模块和练习后的知识状态更新模块。输出是更新的学生知识状态ht。此外,还可以预测学生的表现yt+1。
实验结果
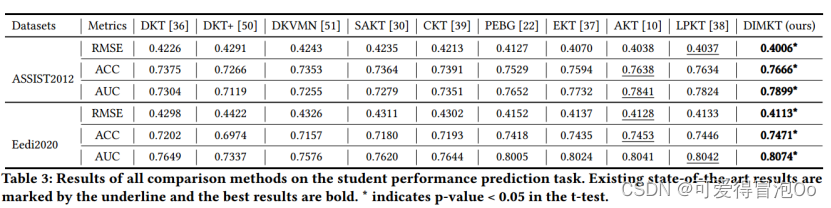
DIMKT在所有数据集和评估指标上都优于所有基线方法。考虑问题难度对学生学习的影响是必要的和有价值的。DIMKT的预测具有很好的可解释性,即难度越低,正确答案的概率就越大。
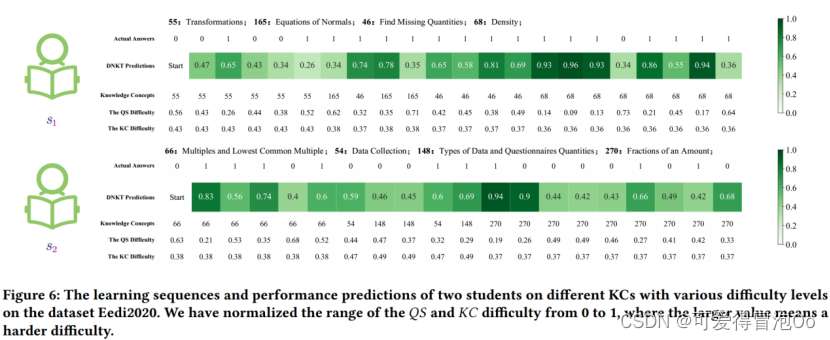
学生1在KC为68的问题上,对于QS难度分别为0.14、0.09和0.13这几个难度较低的题目回答正确了,DIMKT成功预测了该学生不会通过QS难度为0.73题目。
QIKT:Improving interpretability of deep sequential knowledge tracing models with question-centric cognitive representations
The 37th AAAI Conference on Artificial Intelligence. 2023
该模型称为以问题为中心的可解释知识跟踪,即QIKT,通过知识获取模块和问题解决模块学习以问题为中心的认知表征。问题解决模块通过将学生的知识状态投射到两个问题和KC的共同学习表征上来估计学生在每个特定问题上的问题解决能力。可解释预测层建立在心理测量学中的项目反应理论(IRT)的基础上,并将IRT模型的参数集成到以问题为中心的深度序列KT模型中使得QIKT同时实现了优越的预测性能和心理学层面上有意义的可解释性.
贡献
(1)当学生在回答问题后吸收知识并应用知识解决问题时,我们引入了知识获取模块和问题解决模块来学习以问题为中心的表征。
(2)我们基于IRT理论设计了一个简单而有效的可解释预测层,并设法将其与现有的深度序列KT模型无缝结合。
(3)我们在三个具有广泛基线的公共数据集上进行了全面的定量和定性实验,以验证QIKT的性能。精心设计的实验说明了我们的方法在预测性能和模型可解释性方面的优越性。据我们所知,我们的QIKT模型能够在公开可用的可重复KT实验设置上实现AUC方面的最佳预测性能。
模型
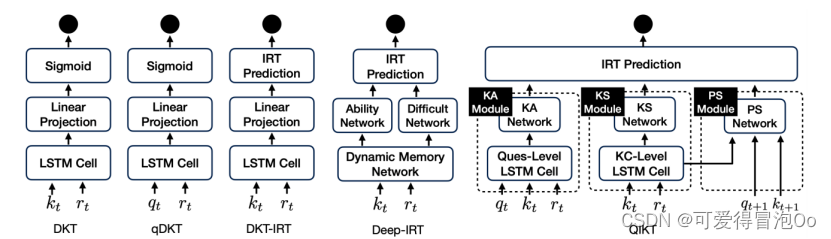
QIKT模型组成:编码器、知识获取模块(包括知识获取(KA)和知识状态(KS)模块)、问题解决模块和可解释预测层。
(1)组装和编码问题和知识概念KC的交互编码器;
(2)知识获取模块用于对学生在收到对特定问题的回答后的知识状态变化进行建模,它通过学生当前知识状态、回答、问题和相应的KC的表示组合表示来估计学生特定问题的知识获取,包括以问题为中心的知识获取(KA)模块和与问题无关的知识状态(KS)模块
(3)以问题为中心的知识获取(KA)模块,考察学生在一段时间内回答特定问题后的知识获取情况;
(4)与问题无关的知识状态(KS)模块,对一般知识状态进行动态建模;
(5)以问题为中心的问题解决(PS)模块,将学生的知识状态投射到问题和KC的组合表示上,评估学生在现有知识状态下解决特定问题的能力;
(6)可解释预测层,利用IRT的心理学理论产生更多可解释的结果
实验结果
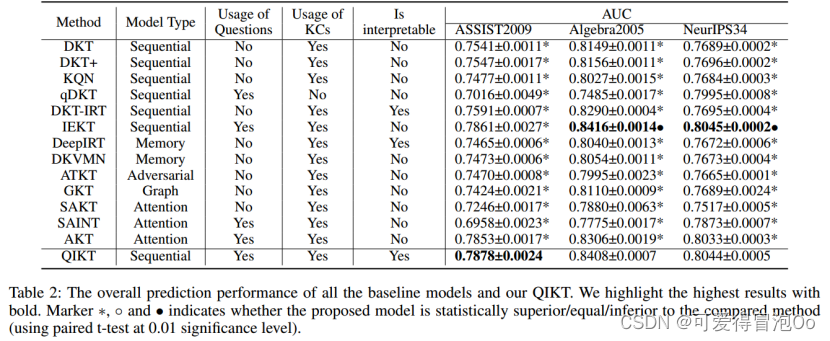
总结
提出了一个具有以问题为中心的认知表征的可解释的深度顺序KT模型学习框架。与现有的DLKT模型相比,QIKT模型能够估计学生的知识获取情况,并衡量学生对每个特定问题的解决能力。此外,我们设计了一个基于IRT的可解释层,使QIKT的预测结果更具可解释性。在三个真实数据集上的定量和定性实验结果表明,QIKT在AUC方面优于其他最先进的DLKT学习方法,并且能够为导师和学生产生可解释的预测。
AT-DKT:Enhancing Deep Knowledge Tracing with Auxiliary Tasks
WWW'23: The 2023 ACM Web Conference, 2023
概述
知识追踪(Knowledge tracing, KT)是根据学生与智能辅导系统的历史互动来预测学生未来表现的问题。近期不同类型的深度神经网络已经被广泛用于KT任务中。然而,真实场景中依然存在两个重要因素没有被很好地考虑到。首先,大多数现有的工作使用试题和知识点的共现矩阵来对输入的表示进行增强,但未能将这种内在关系明确地集成到最终的预测任务损失函数中;其次,学生的历史表现没有被很好的建模。
本文通过引入两个辅助学习任务来解决上述问题,包括:
(1)问题标记(question tagging,QT)预测任务:自动预测问题是否包含特定的KC。
(2)个性化先验知识(individualized prior knowledge,IK)预测任务:逐步预测隐藏在学生历史学习互动中的学生级先验知识
本文的模型AT-DKT,通过两个辅助学习任务:问题标记(question tagging,QT)预测任务和个性化先验知识(individualized prior knowledge,IK)预测任务来提高原始深度知识追踪模型的预测性能。
QT任务通过预测问题是否包含特定KC来得到更好的问题表示;IK任务通过逐步预测隐藏在学生历史学习互动中的学生水平的先验知识来捕捉学生的全局历史表现。
我们对三个真实世界的教育数据集进行了综合实验,并将所提出的方法与深度序列KT模型和非序列KT模型进行了比较。
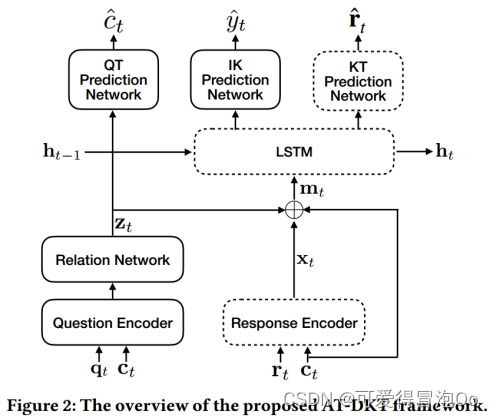
模型框架
虚线部分:原始DKT模型的关键组件,实线部分:AT-DKT中的辅助任务增强组件
这里用虚线概述了原始DKT模型的关键组件,并用实线可视化了AT-DKT中的辅助任务增强组件。在AT-DKT框架中,将QT和IK预测任务与原始的KT预测器结合在一起,以更好地评估学生。QT任务的重点是通过对学生先前的学习结果和IK任务来建模问题和知识点之间的内在关系,预测问题分配给哪些知识点。而IK任务旨在根据学生的学习过程估计每个学生的个性化历史表现。
实验结果
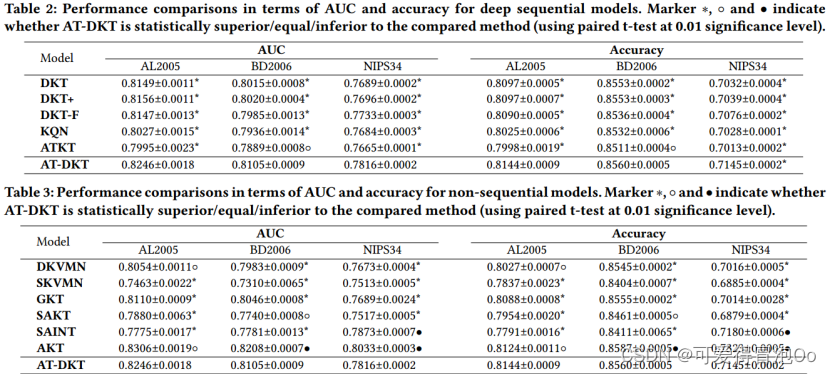
实验结果表明,AT-DKT优于所有序列模型,所有数据集的AUC改善超过0.9%。在非序列模型中基本是第二好的。在AL2005数据集上,AT-DKT与效果最好的模型AKT不相上下,但与BD2006数据集和NIPS34数据集还有一些差距。这是因为AT-DKT中的QT任务在很大程度上依赖于知识概念和问题之间的关系。将AL2005与BD2006和NIPS34进行比较时,AL2005数据集具有更密集的问题KC关联,其每个问题的平均知识概念数量为1.3634。丰富的问题KC关联有助于AT-DKT更好地进行预测。
sparseKT:Towards Robust Knowledge Tracing Models via k-Sparse Attention
SIGIR ‘23, July 23–27, 2023
概述
目前知识追踪领域的注意力DLKT模型已经有了良好的性能,但其中许多模型容易出现过度拟合的风险,尤其是在小规模的教育数据集上。在KT数据集中,题库通常比知识组件集大,学生的问题回答数量非常少,且并非所有过去的问题回答都对KT预测任务有同等的贡献。为了提高基于注意力机制的深度学习模型在知识追踪方面的鲁棒性和泛化能力,这篇论文提出了sparseKT的框架和两种稀疏化启发式方法:soft-thresholding sparse attention和top-K sparse attention。与三个公开的真实世界教育数据集上的11个最先进的KT模型相比,sparseKT能够帮助注意力KT模型摆脱不相关的学生互动,并提高预测性能。
模型
sparseKT模型是对自注意知识跟踪(SAKT)模型的改进。SAKT能够解决学生过去交互处理数据稀疏性问题。然而,SAKT中的纯注意力机制为学生的每一次历史互动赋予了权重,这可能会给模型带来噪声,并干扰准确的知识状态估计。
该模型包含几个组成部分:
1.嵌入
模型通过引入问题特定的区分因子来提高学生交互的表示。该因子捕捉了相同知识组件上的问题之间的个体差异。
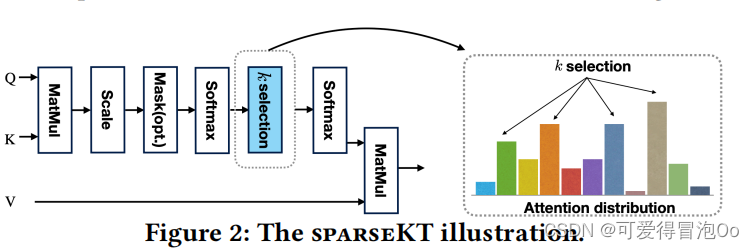
2.k稀疏注意力
模型通过使用稀疏注意力来增强缩放的点积注意力机制,以从学生过去的学习序列中提取最相关信息的几条,只选择topK注意力得分最高的互动,从而在排除其他历史互动的干扰时进行更好的预测。稀疏注意力有两种实现方式:soft-thresholding sparse attention和top-K sparse attention。soft-thresholding根据预定义的阈值选择交互,而top-K选择具有最高注意力分数的前k个交互。
3.预测层
使用一个两层的全连接网络来优化知识状态表示并预测学生未来的表现。
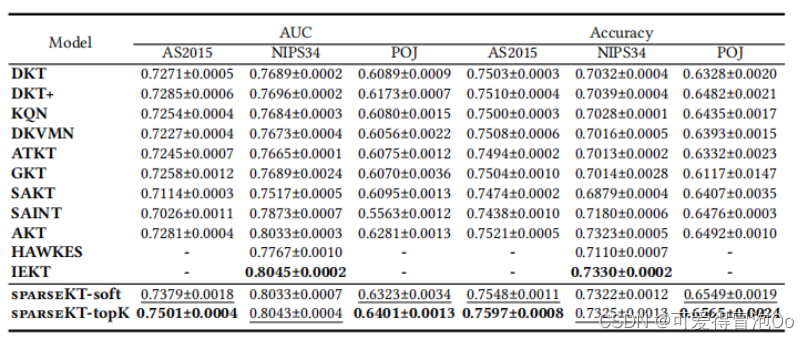
实验结果
该模型在三个公开可用的教育数据集上进行评估:ASSISTments2015,NeurIPS2020教育挑战和POJ。
1.总体性能
模型在AS2015和POJ数据集中都优于11个基线,并且与NIPS34数据集中的IEKT具有相当的性能。SparseKT是SAKT的扩展,仅使用稀疏注意力来代替原始的点积注意力,与SAKT相比,本模型在三个数据集上的AUC都提高了3%、5%左右。这表明稀疏注意力机制限制KT模型关注有限的有影响力的历史信息,是能够提高预测性能的。
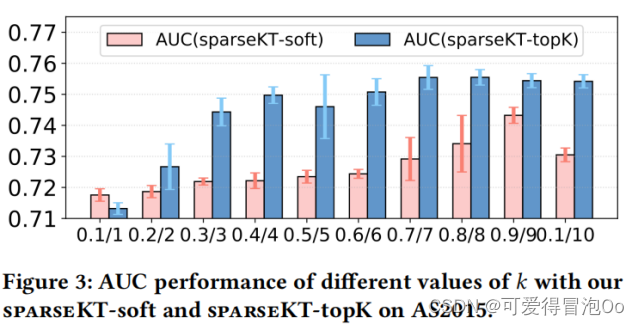
2.稀疏度水平的影响
实验结果显示,稀疏注意力中的稀疏度水平(k)对模型的性能有影响,存在一个平衡选择有影响力的交互和噪声的最佳值K=0.9/8。
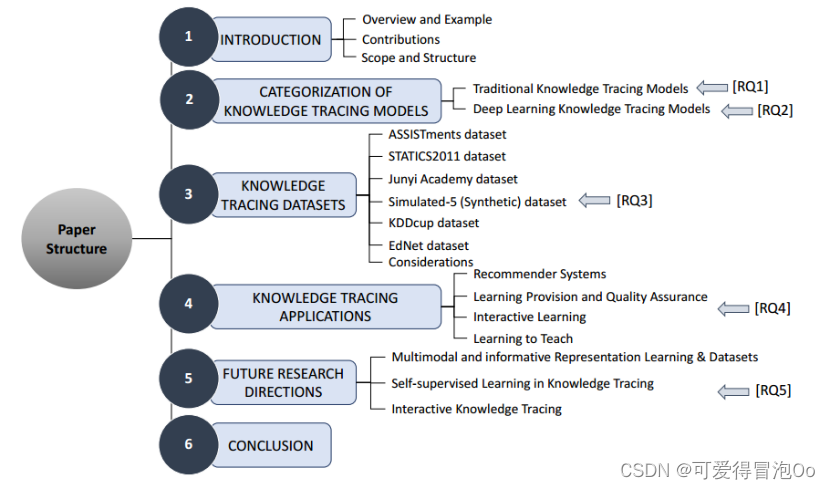
Knowledge Tracing: A Survey
2023 年 2 月收录于 ACM Computing Surveys
研究问题
[RQ1]:传统KT技术发展的历史概况是什么
[RQ2]:用于解决KT问题的关键深度学习技术是什么
[RQ3]:文献中收集、预处理和用于基准测试KT任务的数据集是什么
[RQ4]:KT研究的不同应用领域有哪些
[RQ5]:KT未来的研究机遇和挑战是什么
目前的挑战(RQ1)
1.每个题目可能对应多个技能
2.技能之间存在依赖性,例如k1是k2的先决条件
3.学生的遗忘行为会导致认知下降,对遗忘特征建模,技能可以根据遗忘相关性排序
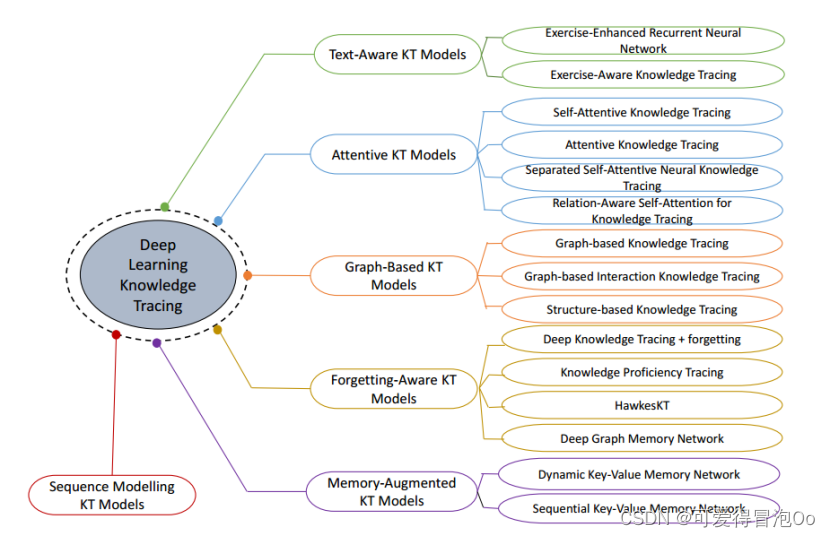
模型分类(RQ2)
1.传统KT
(1)贝叶斯知识追踪:BKT、个性化BKT、动态BKT
(2)因子分析模型: IRT、AFM、PFA、KTM
2.深度学习KT
(1)序列建模的KT模型
DKT、DKT+、DKT-DSC
(2)记忆增强的KT模型
DKVMN、SKVMN
(3)注意力KT模型
SAKT、AKT、SAINT、SAINT+、RKT、CKT、CoKT
(4)图KT模型
GKT、GIKT、SKT、PEBG
(5)文本感知的KT模型
EERNN、EKT、AdaptKT、RKT、HGKT
3.遗忘感知的KT模型
DKT+Forgetting、KPT、HawkesKT、DGMN、LPKT
DLKT的方向:1. 记忆结构 2. 注意力机制 3. 图表示学习 4. 文本特征 5. 遗忘特征
KT 数据集(RQ3)
1.ASSISTments Datasets
小学数学练习 包括多选、文本题、开放式题
A09:123个技能,只有2/3有技能,一个问题最多四个技能
A12:大部分问题没有对应的技能,因此总体性能较低
A15:100个问题(题目id、答题学生id、答题正确率、日志)稀疏度很低 答题密集
ASSISTChall:102个技能 也是密集数据集
2.Statics2011
卡内基梅隆大学工程静力学课程,通常被预处理为129297次交互
3.Junyi
台湾电子学习平台junyi学院收集,722个题目 41个技能 数学
4.Synthetic
由Piech提出的模拟合成数据集,训练集和测试集都包含50个题目 1个技能 ,每个题目被回答4000次,不需要预处理。
5.KDDCup
2010年KDDcup教育数据挖掘挑战赛 对代数题的回答 来自卡内基公司的智能导学系统“The Cognitive Tutors”,包含3个子集
Algebra 2005-2006:每个题目被分为子问题 且和1个或多个技能相关
Algebra 2006-2007:类似05,该数据集时间戳存在问题,采用率低
Bridge to Algebra:493个技能。
6.EdNet
分层数据集由KT1-4表示不同类型的学生活动。KT1 188个技能 KT2 包含用户解决问题时的活动 KT3包含 学生学习方式(看讲座) KT4 最完整,包含各类信息包括购买 Riid TUTOR在线导学平台 致力于为国际交流练习英语 韩国
综合考虑
相同数据集不同数量的技能以及不同实验设置会影响报告结果。通常来自特定领域(主要是数学)和特定地区(例如,来自美国的ASSISTment数据集和来自韩国的最新公开数据集EdNet)。大多数数据集不提供人口统计信息,因此无法进行基于性别或其他类似的预测。基准数据集一直在更新,公开数据集版本有助于获得一致可比的结果
KT应用(RQ4)
1.教育推荐系统
用KT模型评估学生的知识状态 用推荐模型根据知识状态来推荐学习材料
2.学习提供和质量保证
教师用KT模型根据学生历史记录模拟,识别最合适的课程,最大化学生的知识增益
使用KT模型评估每个模块的影响来评估课程结构在实现其预定目标方面的有效性,对学生知识增长的影响
3.通过交互学习提高学生参与度
交互式教育(奖励、动作) 教育游戏可以比传统方式(课本、课堂)更好地适应自然学习能力
4.Learning to teach
KT模型跟踪学生的知识状态,把输出作为教师模型的输入,定制学生代理模型的学习过程,教师优化处理教学策略。
KT未来研究方向(RQ5)
1.多模态与信息表征学习/数据集
(1)哪些信息数据可以用于改进KT模型的性能
(2)如何为KT任务表示这些数据
(3)如何为KT任务创建数据集来实现更丰富的嵌入表征学习
2.自监督学习
SSL采用对比损失来自动生成标签,这种预训练模型可以被转移到下游任务以利用有限的标记数据以监督学习方式进行训练。创建预训练模型来生成KT的信息表示,探索在冷启动场景或数据不准确的情况下,它如何缓解这类限制
3.交互式KT
目前主要是观察交互历史来估计状态的被动方法。由题目回答反应来驱动的交互式方式未被探索。交互式方法很适合冷启动场景,通过提问或不同技能的问题来揭示学生的知识状态。优化问题的抽象策略也是可探索方向,利用强化学习方法来给出最大的reward
4.可解释XAI
(1)解释KT预测过程的技术,算法决策如何影响学习过程or课程设计
(2)知识蒸馏来理解解释其他模型预测可用于KT
DTransformer:Tracing Knowledge Instead of Patterns: Stable Knowledge Tracing with Diagnostic Transformer
Proceedings of the ACM Web Conference 2023 (WWW '23)(CCF A)
背景
目前基于深度神经网络的KT模型都存在信息偏差问题,通过得到学习者不同的交互后,预测下一步表现,推断出知识状态发生的变化,这通常使他们对知识状态的推断不稳定(b)
一个稳定的知识跟踪DTransformer跟踪学习者的知识演变,然后预测对未来问题的反应(a)
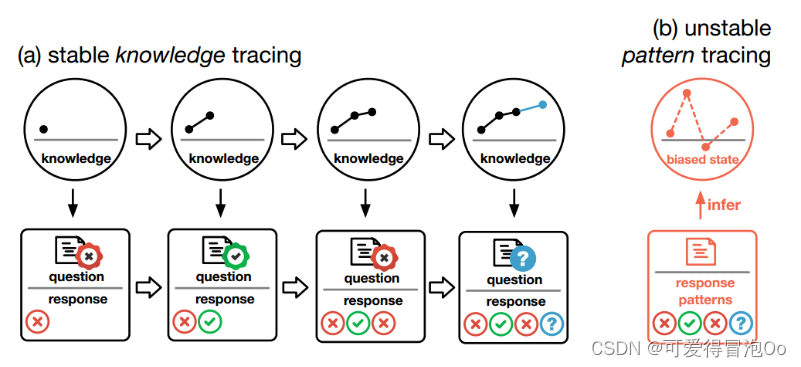
为了真正实现对知识的跟踪,这篇论文提出了一种新的体系结构:诊断转换器(DTransformer)和新的训练范式(基于对比学习的训练算法),以实现更稳定的知识跟踪。这是第一个基于transformer的,关注于稳定的知识状态估计和跟踪。
模型
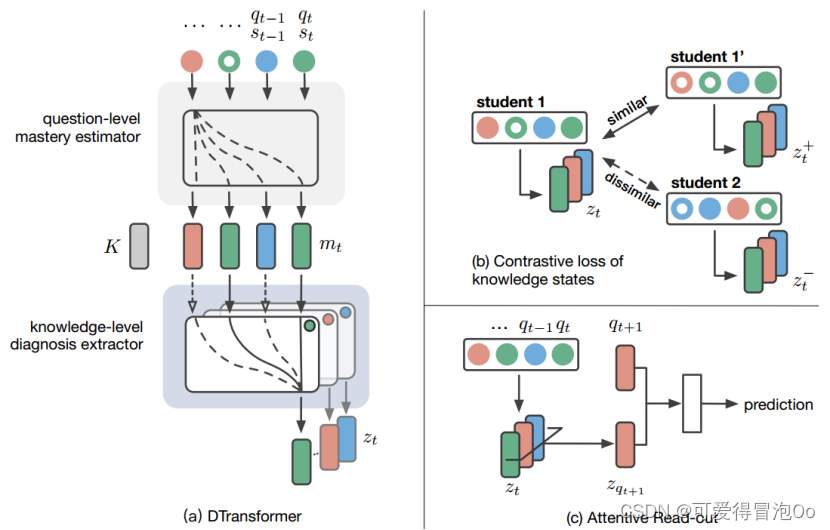
图为DTransformer模型的总体架构
左边的DTansformer由两部分组成。首先评估问题水平的掌握程度,然后诊断知识水平的熟练程度。问题级掌握估计器、知识级诊断提取器两个模块都基于多头注意机制,作者受AKT中首次引入的单调多头注意的启发,设计了一个时间和累积注意(TCA)机制,考虑:(1)学习过程中的时间效应,(2)累积努力
右边的训练过程由两个主要部分组成。首先通过对比损失函数对学习者知识状态进行诊断,然后从学习者的知识状态演变中预测他们下一步的表现。
实验结果
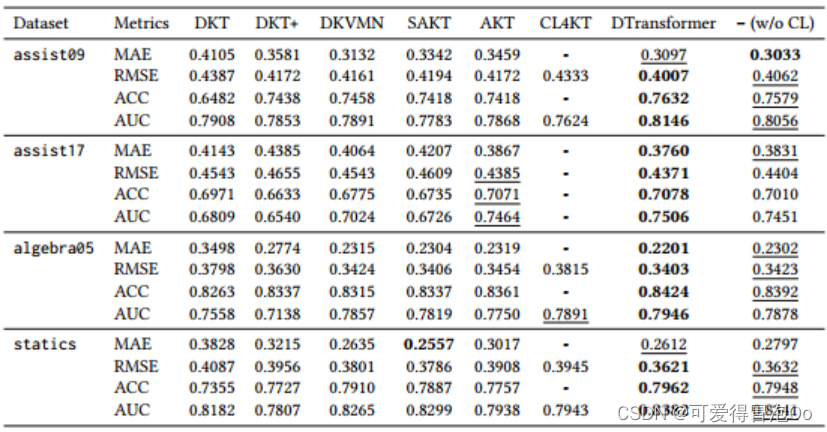
DTransformer在大多数指标下具有最佳性能,而没有对比损失的DTransformer在3个数据集上的性能优于所有基线模型。AKT、CL4KT和我们的模型都引入了注意机制,结果上来看DTransformer模型效果更好。
OKT:Open-Ended Knowledge Tracing for Computer Science Education
2022 Empirical Methods in Natural Language Processing(CCF B)
背景
几乎所有现有的KT方法的一个限制是,它们只分析和预测学生对问题的binary-valued回答,即回答的正确性。针对计算机科学教育领域的编程问题,提出了OKT问题的解决方案,将重点放在分析学生提交的编程问题代码上,使用语言模型的程序合成方法与学生知识跟踪方法相结合。
模型
OKT的三个关键组件:知识表示(KR),解决了如何表示编程问题和学生提交的代码的问题;知识状态(KE),解决了如何来估计学生知识状态的问题;响应生成(RG),解决了如何将知识状态与问题提示结合起来生成学生代码的问题(是OKT和现有KT方法之间的关键区别)。
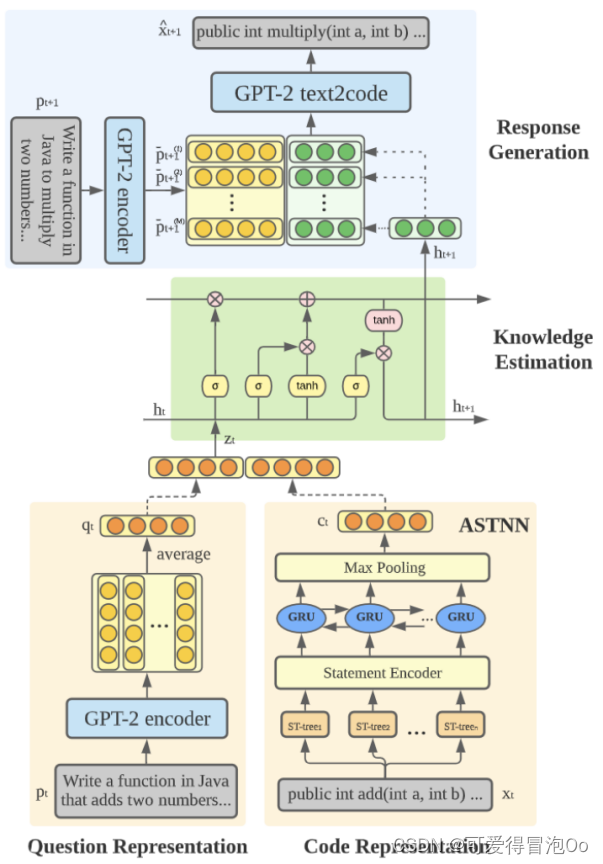
KR组件的目的是将学生回答的问题提示/陈述以及他们提交的相应代码转换为连续表示。代码表示:为了在嵌入向量中保留编程代码的语义和语法属性,我们使用了ASTNN (Zhang等人,2019),这是一种代码解析表示模型。
KE组件的目的是将学生过去的问题/代码信息转化为对他们当前知识状态的估计。继现有流行的KT方法DKT之后,我们使用长短期记忆(LSTM)模型来更新学生当前的知识状态ht+1。理论上,我们可以使用任何现有的二值KT方法作为OKT的KE组件。在论文中验证了能够使用DKVMN和AKT,这两种方法基于外部记忆和注意力网络。
OKT的核心组件RG的目的是预测开放式的响应,即生成预测的学生代码,将GPT-2生成模型微调为文本到代码模型,并在代码数据上调用参数。
实验结果
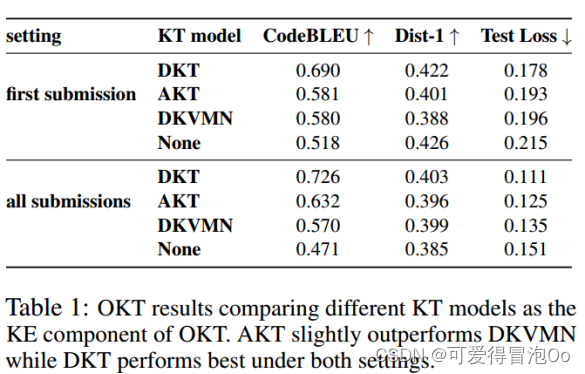

总结
基于微调GPT-2的文本到代码模型解决了将学生知识表示集成到代码生成方法中的关键技术挑战
OKT有几个明显的局限性。首先,OKT预测学生相应变化的能力取决于这个经过微调的语言模型生成正确答案的能力。因此,无法确定OKT是否推广到语言模型在生成正确的开放式响应方面没有显示出高度准确性的领域。其次,OKT需要大量的学生编码数据,这可能会限制其在早期阶段没有大量学生用户的学习平台的适用性。

















 1514
1514

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









