







 本文综述了知识追踪(KT)领域的传统与深度学习方法,包括模型发展、数据集、应用场景及未来研究方向。重点关注深度KT模型,如记忆增强、注意力机制、图表示学习等,并探讨了KT在教育技术中的应用。
本文综述了知识追踪(KT)领域的传统与深度学习方法,包括模型发展、数据集、应用场景及未来研究方向。重点关注深度KT模型,如记忆增强、注意力机制、图表示学习等,并探讨了KT在教育技术中的应用。
(注:为了方便后续阅读KT论文,文中一些名词使用英文。文中保留的序号与原论文参考文献一致。行文会在后续反刍过程中改进。)
原文链接:https://arxiv.org/abs/2201.06953v1
问题:如何在学生与教学材料交互的基础上,有效地追踪一个学生学习的过程?
定义:知识追踪(KT)的目标是观察、表现和量化学生的知识状态。
挑战:
- 解决一个问题可能需要不止一项技能(p.s.:看来如何合理对技能的划定也是一个问题)
- skills 之间的依赖性:例如问题q需要skill 3,但skill 1和skill 2是skill 3的先决条件
- skills 会受遗忘的影响
传统方法:
早期:贝叶斯推方法,但这种方法依赖于过度简化的模型。
后来的另一个方向:parametric factor analysis approaches,在对各种因素进行建模的基础上进行答案预测。考虑的因素有:
学生方面:基础、学习能力(学习速度、学习习惯等)
学习材料:熟悉程度、难度
学习环境:练习or以考代练
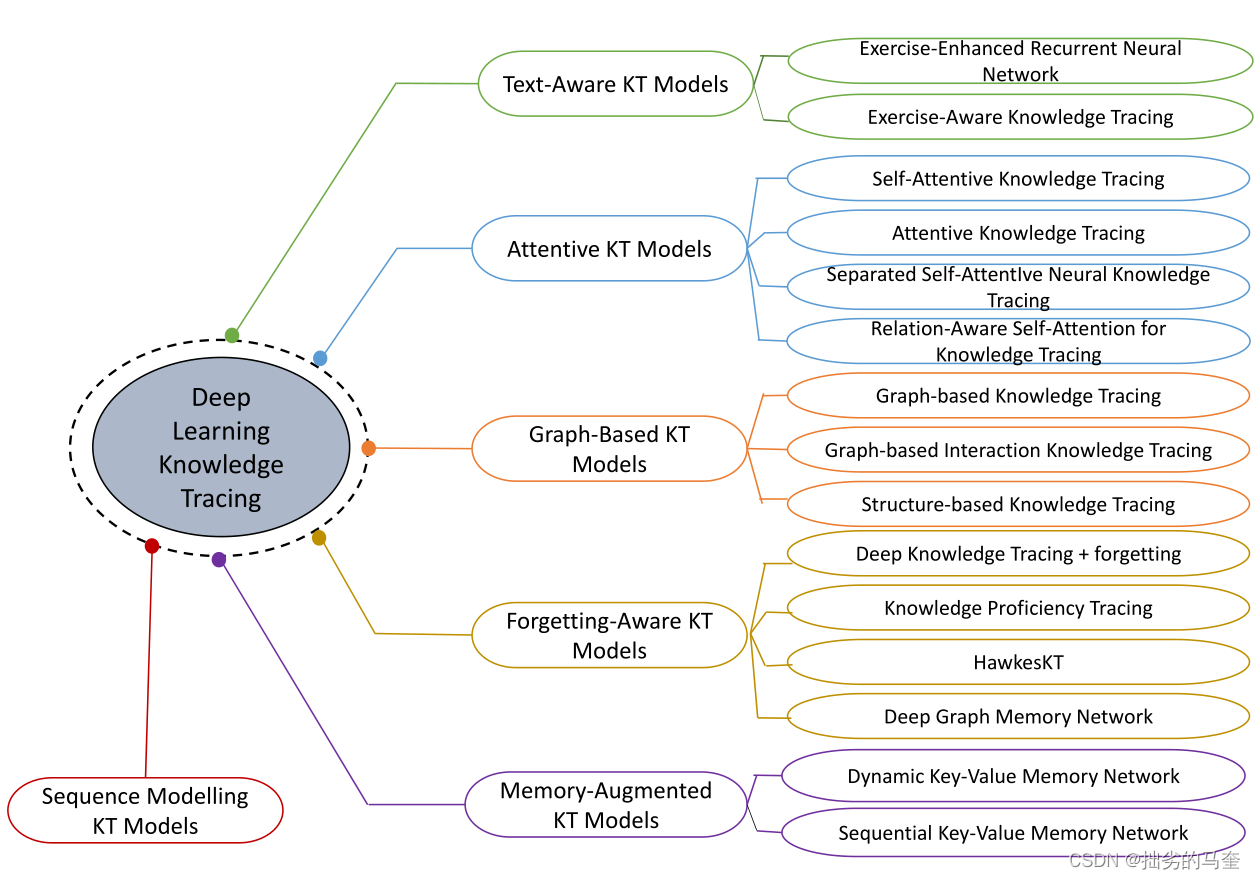
深度学习方法
deep knowledge tracing(DKT)模型,应用递归神经网络RNN捕捉学生的问题和回答之间一系列互动的时间动态。
DKT在多个基准数据集上表现优于传统KT模型。近年来越来越多的研究从不同角度对深度学习KT模型的发展进行了探讨:
- memory structures:受到记忆增强神经网络的启发,深度KT模型使用更强大的memory structures典型的是键值记忆,用于在更细的粒度(如每个单独技能的掌握水平)上动态捕获知识状态
- attention mechanisms:transformer和一些NLP的进展,促使一些研究者探索深度KT模型使用注意力机制捕获问题之间的关系及其与学生知识状态的相关性。
- graph representation learning:利用图中丰富的结构信息,信息可以灵活建模问题和技能之间的关系(p.s.是否有层级结构?能不能用双曲?) (e.g. [78, 108, 120])
- textual features:一些深度KT模型利用来自问题的文本特征来学习问题表示(问题所需技能、问题难度、问题之间的关系等)和学生的知识状态
- forgetting features:将遗忘特征纳入模型,以便在知识追踪时考虑学生的遗忘行为。
这些方面的研究可以帮助将深度学习上取得的成果应用到KT领域,目前深度学习KT模型在大多数基准数据集上都取得了最先进的结果
1. outlines
- [RQ1]:传统KT技术发展?
- [RQ2]:用于解决KT问题的关键深度学习技术?
- [RQ3]:在文献中收集、预处理和用于KT任务基准测试的数据集是什么?
- [RQ4]:什么不同的应用领域可以从KT的研究中受益?
- [RQ5]: KT未来的研究机遇和挑战是什么?
围绕这5个问题,全文组织结构如下图所示:
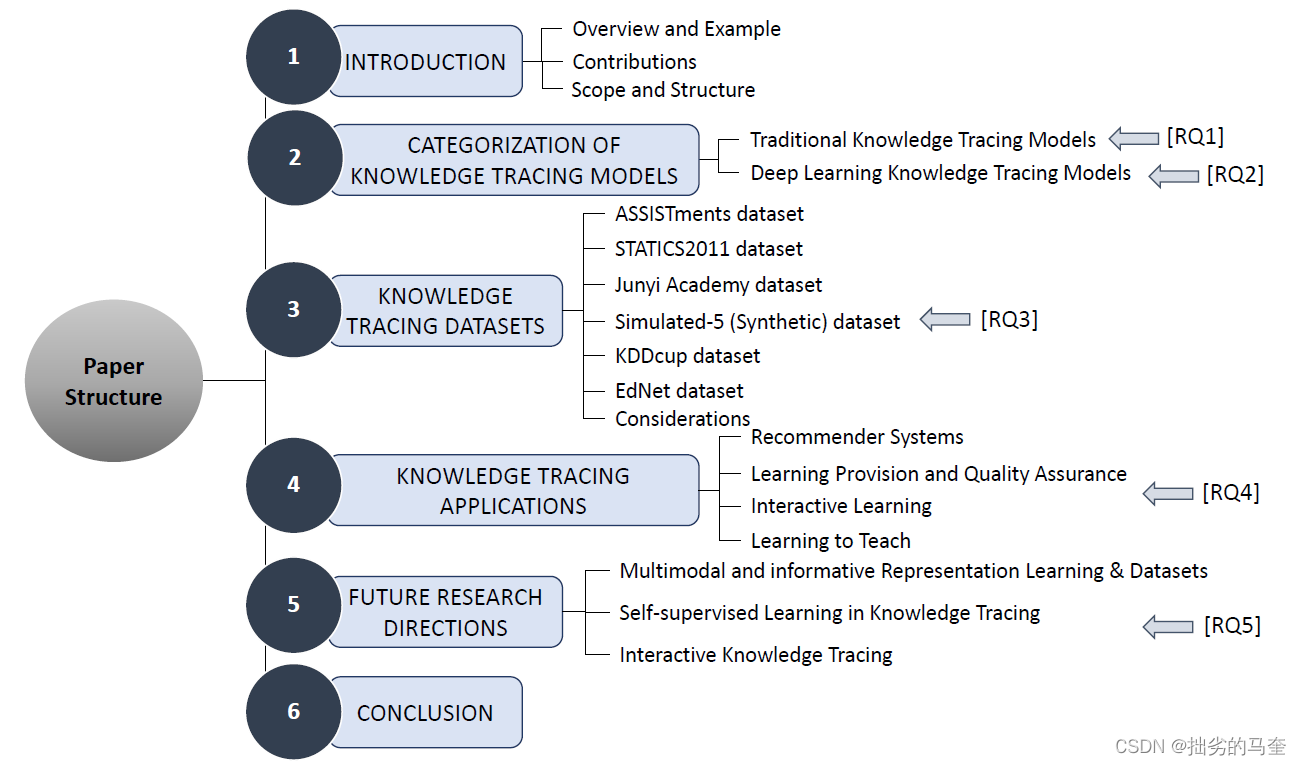
第二节:介绍传统KT模型(RQ1),介绍深度KT模型(RQ2)
第三节:介绍KT常用基准数据集(RQ3)
第四节:讨论KT的几种应用
第五节:探讨KT未来的研究方向
2. KT分类
传统KT模型
贝叶斯KT(BKT)
基于假设mastery learning:
(1)知识被恰当地描述为技能的层次结构;
(2)learning experiences are structured to ensure that students master skills lower than those higher in the hierarchy(在技能金字塔中,学生先前的学习经历已经使它掌握了索要学习技能以下的低层级技能)。
符合mastery learning假设则确保所有学生可以学会该技能。
BKT常用概率图模型如:Hidden Markov Model和bayesian belief network 去追踪学生在练习技能时不断变化的知识状态。
BKT的核心是贝叶斯定理:
p
(
A
∣
B
)
=
p
(
B
∣
A
)
p
(
A
)
p
(
B
)
p(A \mid B)=\frac{p(B \mid A) p(A)}{p(B)}
p(A∣B)=p(B)p(B∣A)p(A)
标准BKT模型方法和他们的一些变式
- 标准BKT模型
第一个BKT模型是由Corbett和Anderson于1994年[24]提出,他将技能状态分为{ learned, unlearned }
缺陷:忽略了遗忘带来的影响,且忽略了学生在学会的情况下也可能出错,在未学会的情况下也可能蒙对。
下表是传统KT模型中一些常用符号的解释。
p
(
L
0
)
p(L_0)
p(L0)是在学习前学生的掌握程度(先验);
p
(
T
)
p(T)
p(T)是从unlearned到learned状态的概率;
p
(
S
)
p(S)
p(S)是learned状态答错的概率;
p
(
G
)
是
p(G)是
p(G)是unlearned状态答对的概率。
![![[Pasted image 20221010200939.png]]](https://i-blog.csdnimg.cn/blog_migrate/39a54ae011152a3b757f0dd5837a5b2b.png)
BKT中有两种二进制变量:
(1)二进制隐变量。描述学生知识状态的(比如是否掌握skill)
(2)二进制可观测变量。描述学生对问题的应对(如问题答案是否正确)
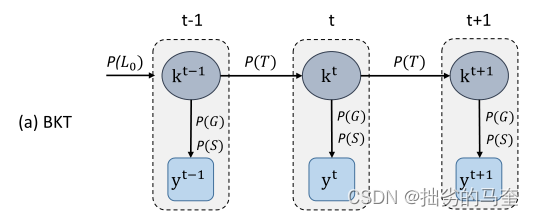
对于每个skill,都有对应的参数集合
{
p
(
T
0
)
,
p
(
T
)
,
p
(
S
)
,
p
(
G
)
}
\{ p(T_0), p(T), p(S), p(G) \}
{p(T0),p(T),p(S),p(G)}。
从skill掌握的先验概率P(L0)开始,skill k的隐变量基于概率P(T)从一个时间步长t-1转换到下一个时间步长t。对应的观察变量y表示答案节点,即学生如何尝试需要技能k的问题,这基于概率p(G)和p(S)。
在每个time step n>=1,模型估计p(Ln):
p
(
L
n
)
=
Posterior
(
L
n
−
1
)
+
(
1
−
Posterior
(
L
n
−
1
)
)
∗
p
(
T
)
p\left(L_{n}\right)=\text { Posterior }\left(L_{n-1}\right)+\left(1-\text { Posterior }\left(L_{n-1}\right)\right) * p(T)
p(Ln)= Posterior (Ln−1)+(1− Posterior (Ln−1))∗p(T)
Posterior
(
L
n
−
1
)
\text { Posterior }\left(L_{n-1}\right)
Posterior (Ln−1)是学生第n次尝试观察的情况下处于learned状态的后验概率
P
o
s
t
e
r
i
o
r
(
L
n
−
1
)
=
{
p
(
L
n
−
1
)
∗
(
1
−
p
(
S
)
)
p
(
L
n
−
1
)
∗
(
1
−
p
(
S
)
)
+
(
1
−
p
(
L
n
−
1
)
)
∗
p
(
G
)
if the
n
-th attempt is correct;
p
(
L
n
−
1
)
∗
p
(
S
)
p
(
L
n
−
1
)
∗
p
(
S
)
+
(
1
−
p
(
L
n
−
1
)
)
∗
(
1
−
p
(
G
)
)
otherwise.
Posterior \left(L_{n-1}\right)= \left\{\begin{array}{l}\frac{p\left(L_{n-1}\right) *(1-p(S))}{p\left(L_{n-1}\right) *(1-p(S))+\left(1-p\left(L_{n-1}\right)\right) * p(G)} \text { if the } n \text {-th attempt is correct; } \\ \frac{p\left(L_{n-1}\right) * p(S)}{p\left(L_{n-1}\right) * p(S)+\left(1-p\left(L_{n-1}\right)\right) *(1-p(G))} \text { otherwise. }\end{array}\right.
Posterior(Ln−1)={p(Ln−1)∗(1−p(S))+(1−p(Ln−1))∗p(G)p(Ln−1)∗(1−p(S)) if the n-th attempt is correct; p(Ln−1)∗p(S)+(1−p(Ln−1))∗(1−p(G))p(Ln−1)∗p(S) otherwise.
学生在每个时间步长n中正确回答问题的概率是要么掌握skill但犯了错误,要么不掌握skill但做出正确的“猜测”的概率之和,即:
p
(
L
n
)
∗
(
1
−
p
(
S
)
)
+
(
1
−
p
(
L
n
)
)
∗
p
(
G
)
)
\left.p\left(L_{n}\right) *(1-p(S))+\left(1-p\left(L_{n}\right)\right) * p(G)\right)
p(Ln)∗(1−p(S))+(1−p(Ln))∗p(G))
-
individualized BKT模型
标准BKT模型没有考虑学生的个体差异(假设学生拥有了相同的先验知识和学习速度),IBKT模型引入特定于学生的参数来扩展标准BKT模型。(数字为对应论文在原文参考文献中的序号)
24 为每个学生的四参集合每个参数各添加一个权重。
83 基于启发式方法对每个学生的p(L0)进行个体化
62 对学生的标准BKT模型中的四种参数进行了个体化
the combined effects of skill-specific and student-specific parameters were unexplored.
123 对每个学生的p(L0)和p(T)进行个体化
同样使用基本的隐马尔可夫模型,发现p(T)比p(L0)更能提高模型精度
56 对每个学生的p(G)和p(S)进行了个体化(前两个参数未个体化) -
dynamic BKT模型
先前的网络假设每个问题只需要一种skill解决,且skills之间无依赖关系。
[54]提出利用动态贝叶斯网络(DBN)对多种技能和不同技能之间的依赖关系进行联合建模。他们的目标是在单一模型中捕捉先决条件技能层次结构,例如,如果前者是掌握后者的先决条件,则一种技能有条件地依赖于另一种技能。
加入遗忘概率p(F)和描述不同技能之间依赖关系的对数线性模型的权重w。
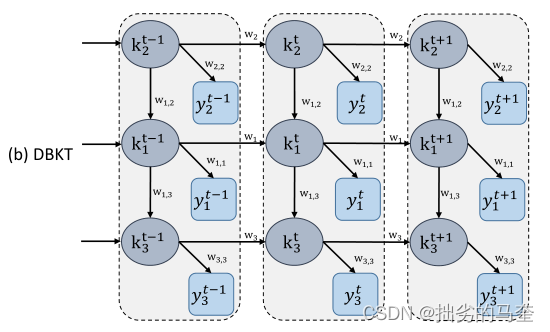
在每一个时间步,一个隐变量和一个可观测变量联系起来,
f
:
X
×
O
→
R
d
f: X \times O \rightarrow \mathbb{R}^{d}
f:X×O→Rd表示隐空间X和显空间O到d维特征向量的一个映射。则这个对数线性模型的任务是找到可以最小化
x
i
∈
X
and
y
i
∈
O
x_{i} \in X \text { and } y_{i} \in O
xi∈X and yi∈O联合概率的似然的参数集合
{
p
(
L
0
)
,
p
(
T
)
,
p
(
S
)
,
p
(
G
)
,
p
(
F
)
,
w
}
\left\{p\left(L_{0}\right), p(T), p(S), p(G), p(F), \mathbf{w}\right\}
{p(L0),p(T),p(S),p(G),p(F),w},似然表达式为:
L
(
w
)
=
∑
i
ln
(
∑
x
i
exp
(
w
⊤
f
(
x
i
,
y
i
)
−
c
)
)
.
L(\mathbf{w})=\sum_{i} \ln \left(\sum_{x_{i}} \exp \left(\mathbf{w}^{\top} f\left(x_{i}, y_{i}\right)-c\right)\right) .
L(w)=i∑ln(xi∑exp(w⊤f(xi,yi)−c)).
factor analysis 模型
factor analysis models核心是item response theory(IRT):通过学习一个函数来评估学生的表现,该函数通常是基于解决一组问题的学生中的各种因素的一个逻辑函数。
item和skill之间的映射通常以Q矩阵的形式表示。Q矩阵中的元素
q
j
k
q_{jk}
qjk的值,如果item j 需要 skill k 则为1,否则为0。
-
IRT:IRT假设
(1)学生正确回答一个item的概率可以定义为一个item response function,这个函数基于学生和item的参数
(2)这个函数关于一个学生 i 的ability θ i \theta _i θi 单调增加
(3)一个学生 ability 为 θ i \theta_i θi,items是条件独立的。
最简单的IRT模型:Rasch model,他的item response function被定义为单参数逻辑回归模型(1PL)
p i j = L ( θ i − b j ) = exp ( θ i − b j ) 1 + exp ( θ i − b j ) p_{i j}=\mathcal{L}\left(\theta_{i}-b_{j}\right)=\frac{\exp ^{\left(\theta_{i}-b_{j}\right)}}{1+\exp ^{\left(\theta_{i}-b_{j}\right)}} pij=L(θi−bj)=1+exp(θi−bj)exp(θi−bj)
L ( ⋅ ) \mathcal{L}(·) L(⋅)是逻辑函数, p i j p_{ij} pij是学生i正确回答item j的概率, b j b_j bj表示item j的难度。
4PL model(四参数模型):
p i j = c j + ( d j − c j ) L ( a j ( θ i − b j ) ) = c j + ( d j − c j ) exp a j ( θ i − b j ) 1 + exp a j ( θ i − b j ) , p_{i j}=c_{j}+\left(d_{j}-c_{j}\right) \mathcal{L}\left(a_{j}\left(\theta_{i}-b_{j}\right)\right)=c_{j}+\left(d_{j}-c_{j}\right) \frac{\exp ^{a_{j}\left(\theta_{i}-b_{j}\right)}}{1+\exp ^{a_{j}\left(\theta_{i}-b_{j}\right)}}, pij=cj+(dj−cj)L(aj(θi−bj))=cj+(dj−cj)1+expaj(θi−bj)expaj(θi−bj),
其他三个参数,aj反映item的区分度,cj模拟猜测效果,dj模拟粗心导致的错误
IRT的扩展有 hierarchical IRT,Temporal IRT。 -
additive factor model(AFM)
起源于learning factors analysis(LFA),是一个逻辑回归模型
假设:
(1)学生的先验知识可能不同;
(2)学习速度不同;
(3)有些技能比其他技能更容易为人所知;
(4)有些技能比其他技能更容易学习。
在AFM模型中,每个skill k都对应一个难度参数 β k \beta_k βk和learning rate参数 γ k \gamma_k γk
AFM的关键点在于,一个学生正确回答回答一个item的概率,与【学生的ability、item涉及skill的难度、尝试解答的次数】的加和成正比。
K(j) 表示 item j需要的skills集合,可以在Q矩阵中找到。 T i k T_{ik} Tik表示学生i在需要技能k的item尝试的次数。则AFM定义一个学生正确回答一个item的概率为:
p i j = L ( θ i + ∑ k ∈ K ( j ) ( β k + γ k T i k ) ) . p_{i j}=\mathcal{L}\left(\theta_{i}+\sum_{k \in K(j)}\left(\beta_{k}+\gamma_{k} T_{i k}\right)\right) . pij=L⎝ ⎛θi+k∈K(j)∑(βk+γkTik)⎠ ⎞. -
performance factor analysis(PFA)
绩效因素分析(PFA)克服了AFM的局限性,即在学生对项目的成功和失败尝试中忽略了学习证据。把表示学生ability的参数 θ i \theta_i θi换为将成功尝试次数和失败尝试次数分开表示。对于每个skill,PFA有三个参数:
(1) β k \beta_k βk是skill k的难度;(2) γ k S \gamma_k^S γkS表示skill k在多次成功过尝试后的效果;(3) γ k F \gamma_k^F γkF表示skill k在多次失败过尝试后的效果。
γ k S \gamma_k^S γkS 反映技能成功使用后的学习率
γ k F \gamma_k^F γkF 反映技能成功使用后的学习率
T i k S T_{ik}^S TikS 表示学生i成功使用skill k的次数
T i k F T_{ik}^F TikF 表示学生i失败使用skill k的次数
则PFA计算学生i正确回答item j的概率 p i j p_{ij} pij为:
p i j = L ( ∑ k ∈ K ( j ) ( β k + γ k S T i k S + γ k T T i k F ) ) p_{i j}=\mathcal{L}\left(\sum_{k \in K(j)}\left(\beta_{k}+\gamma_{k}^{S} T_{i k}^{S}+\gamma_{k}^{T} T_{i k}^{F}\right)\right) pij=L⎝ ⎛k∈K(j)∑(βk+γkSTikS+γkTTikF)⎠ ⎞ -
Knowledge Tracing Machine(KTM)
知识追踪机,是factorization machine的推广
KTM考虑任意数量的factors(students、items、skills、successful or unsuccessful attempts、etc.)N维向量x,一维表示一个factor,对于其中一个值 x k x_k xk,如果该factor对事件有影响,则 x k x_k xk值大于0,否则值为0。则 p i j p_{ij} pij的表达式为:
p i j = L ( ∑ k = 1 N w k x k + ∑ 1 ⩽ k < l ⩽ N x k x l ⟨ v k , v l ⟩ + μ ) p_{i j}=\mathcal{L}\left(\sum_{k=1}^{N} w_{k} x_{k}+\sum_{1 \leqslant k<l \leqslant N} x_{k} x_{l}\left\langle v_{k}, v_{l}\right\rangle+\mu\right) pij=L(k=1∑Nwkxk+1⩽k<l⩽N∑xkxl⟨vk,vl⟩+μ)
其中, μ \mu μ是全局bias,每个factor k被一个权重 w k w_k wk和一个embedding v k v_k vk建模, w k w_k wk一维, v k v_k vk维数根据embedding而定。
第一项建模所有factors的逻辑回归,第二项建模不同的成对factors之间的交互作用。当 L \mathcal{L} L是logistic函数时,IRT, ATM 和 PFA 是KTM的特殊情况。
KTM-DLF,引入了遗忘带来的影响。
小结
模型参数:早期模型仅考虑关于skill的四个参数 { p ( T 0 ) , p ( T ) , p ( S ) , p ( G ) } \{ p(T_0), p(T), p(S), p(G) \} {p(T0),p(T),p(S),p(G)};后来的模型考虑学生个体差异,引入学生的一些参数,提高了KT模型的性能;最近的模型考虑了学生的遗忘特征。
模型推理:BKT模型通常假设一阶马尔可夫链,这种假设限制了模型的表征能力。最近的动态BKT模型如DBN在准确性和计算效率之间作权衡。factor model目标不明确地对学生的知识状态做出推断(例如,通过追踪知识状态来决定学生是否已经达到一定水平的技能掌握),他们的目标是最大化其他模型参数,如学习率。
时间分析:BKT模型本质上处理基于学生学习历史的序列的预测问题。相比之下,factor model不考虑学生回答问题的顺序。例如,给定一个学生的两个问题及其相应的答案,一个问题是否在另一个问题之前得到回答对于factor model并不重要。factor model可以引入时间特征来提升性能。
可以结合BKT和factor analysis model来获取各自的优点。比如:
(1)IRT使用贝叶斯推理来根据每个学生的观察定制问题难度的估计。
(2)引入因素方法来反映学生的个体特征,或item的个体特征。
深度学习KT模型
面向KT的序列建模
机器学习角度:KT任务近似于序列预测问题
Q
=
{
q
1
,
.
.
.
,
q
∣
Q
∣
}
Q=\{q_1,...,q_{|Q|}\}
Q={q1,...,q∣Q∣}是一个数据集中不同的问题,各自有不同的难度。当学生与其交互时会产生一个交互序列
X
=
<
x
1
,
x
2
,
.
.
.
,
x
∣
Q
∣
>
X=<x_1,x_2,...,x_{|Q|}>
X=<x1,x2,...,x∣Q∣>,每个
x
i
=
(
q
i
,
y
i
)
q
i
是问题,
y
i
x_i=(q_i,y_i) q_i \text{是问题,} y_i
xi=(qi,yi)qi是问题,yi是答案,回答错误值为0,回答正确值为1。
定义:给一个X序列,反应的是先前的问题和学生的答案,KT问题是在其基础上预测正确答对新问题的概率,即
p
t
=
(
y
t
=
1
∣
q
t
,
X
)
p_{t}=\left(y_{t}=1 \mid q_{t}, X\right)
pt=(yt=1∣qt,X)
DKT(Deep Knowledge Tracing)利用RNN(Recurrent Neural Network)和LSTM(Long Short Term Memory)预测每个时间步正确回答问题的概率。在每个时间步t,DKT会在之前交互的基础上计算出一个隐状态序列
<
h
1
,
h
2
,
.
.
.
,
h
n
>
<h_1,h_2,...,h_n>
<h1,h2,...,hn>,然后在其基础上计算
p
t
p_t
pt
h
t
=
Tanh
(
W
h
x
x
t
+
W
h
h
h
t
−
1
+
b
h
)
p
t
=
σ
(
W
h
y
h
t
+
b
p
)
\begin{array}{c} h_{t}=\operatorname{Tanh}\left(W_{h x} x_{t}+W_{h h} h_{t-1}+b_{h}\right) \\ p_{t}=\sigma\left(W_{h y} h_{t}+b_{p}\right) \end{array}
ht=Tanh(Whxxt+Whhht−1+bh)pt=σ(Whyht+bp)
Tanh
(
u
i
)
=
(
e
u
i
−
e
−
u
i
)
/
(
e
u
i
+
e
−
u
i
)
\operatorname{Tanh}\left(u_{i}\right)=\left(e^{u_{i}}-e^{-u_{i}}\right) /\left(e^{u_{i}}+e^{-u_{i}}\right)
Tanh(ui)=(eui−e−ui)/(eui+e−ui)
σ
(
u
i
)
=
1
/
(
1
+
e
−
u
i
)
\sigma\left(u_{i}\right)=1 /\left(1+e^{-u_{i}}\right)
σ(ui)=1/(1+e−ui) 是激活函数
W
h
x
,
W
h
h
,
W
h
y
W_{h x}, W_{h h},W_{h y}
Whx,Whh,Why 是权重矩阵,
b
h
,
b
p
b_{h},b_{p}
bh,bp 是 bias
DKT的局限性:1.假设一个学生的知识状态
h
t
h_t
ht仅有一个隐藏KC(knowledge components)(i.e. a skill);2.不能建模不同KCs之间的关系;3. 假设所有问题之间的相关性相同。
提升能力推广DKT,如Extended-Deep Knowledge Tracing,DKT+,Deep Knowledge Tracing with Dynamic Student Classification (DKT-DSC)
Memory-Augmented Knowledge Tracing Models
启发于memory-augmented neural networks,DKT加入memory structure来建模复杂的KCs。启发于Key-Value Memory Network (KVMN),DKT使用key-value memory来表征知识状态,这比DKT使用隐变量具有更强的表征能力。
key-value memory由key矩阵和value矩阵构成。key矩阵存储每个KCs的表征,value矩阵存储学生对每个KC的掌握程度。
两个受欢迎的key-value memory networks:
- Dynamic Key-Value Memory Network (DKVMN)
KVMN的key、value矩阵均为静态,DKVMN的value矩阵动态,key矩阵静态。
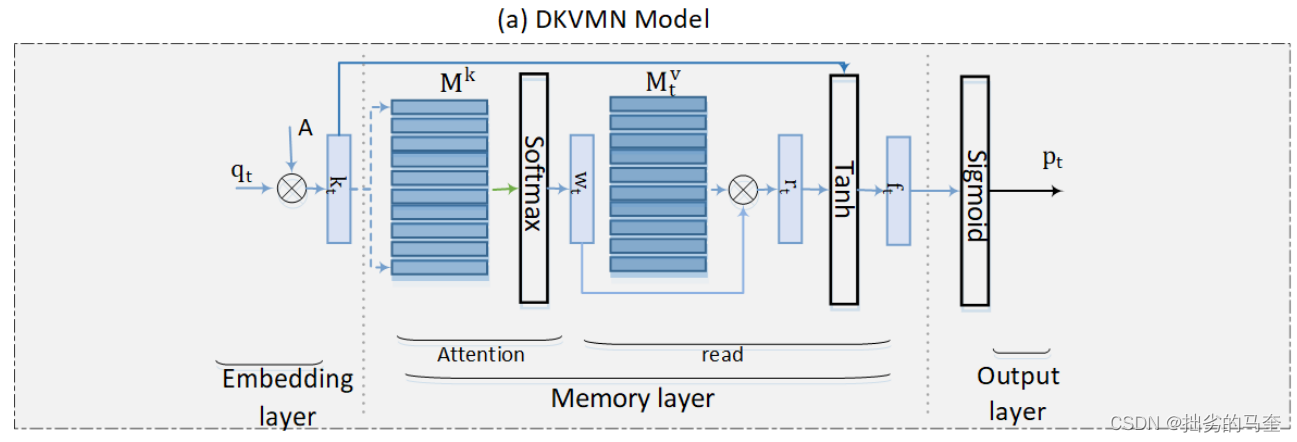
假设学习任务中的所有问题下都有N个潜在的KCs,key矩阵 M k ∈ R N × d k \mathbf{M}^{k} \in \mathbb{R}^{N \times d_{k}} Mk∈RN×dk, M t v ∈ R N × d v \mathbf{M}_{t}^{v} \in \mathbb{R}^{N \times d_{v}} Mtv∈RN×dv是在t时间步时的value矩阵。对于一个t时间步时的问题 q t q_t qt会计算一个对应的权重 w t w_t wt,表达问题与key矩阵中的KCs之间的相关性。
该模型首先根据t时间步时的value矩阵计算学生关于 q t q_t qt的知识状态:
r t = ∑ i = 1 N w t ( i ) M t v ( i ) r_{t}=\sum_{i=1}^{N} w_{t}(i) \mathbf{M}_{t}^{v}(i) rt=i=1∑Nwt(i)Mtv(i)
然后根据只是状态预测学生对 q t q_t qt的反应,在学生回答问题后,更新value矩阵来反映学生知识水平的提升。 - Sequential Key-Value Memory Network (SKVMN)
DKT和DKVMN局限,过去回答的一序列问题所需的KCs不是一定与当前问题所需的KCs相关。因此,SKVMN采用改进的LSTM进行序列建模,称为Hop-LSTM,同时保持与DKVMN相同的键值存储结构和损失函数。与LSTM不同之处是,HOP-LSTM能够显式地捕获交互序列中问题之间的顺序依赖关系,并根据学生对相关问题的回答来更新学生的知识状态。
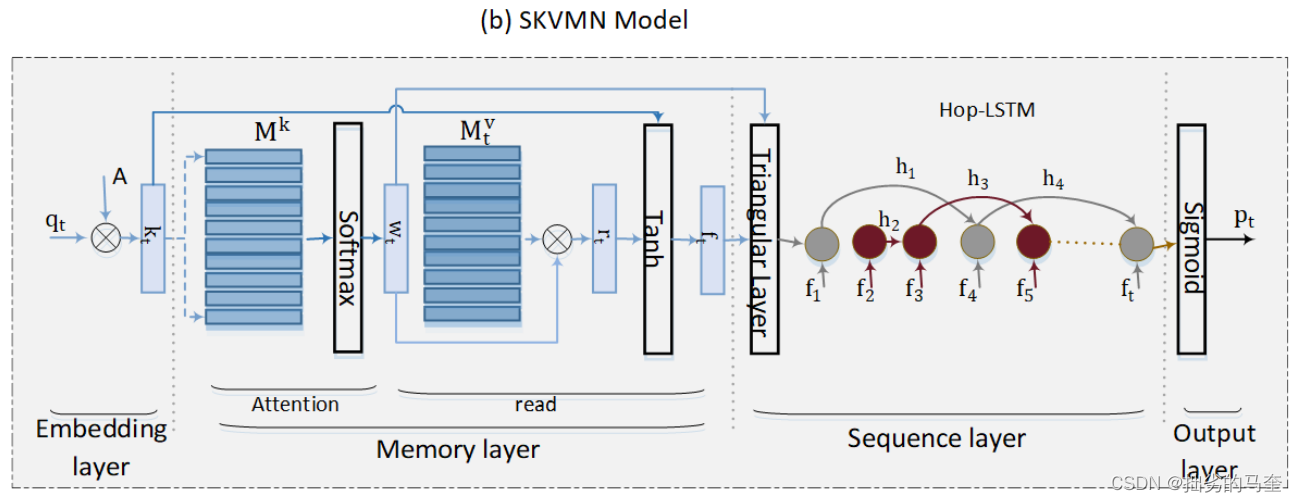
只有当一个LSTM信元的输入问题顺序地依赖于另一个LSTM信元的输入问题时,Hop-LSTM中的两个LSTM信元才被连接。这意味着当输入问题与当前问题无关时,HOP-LSTM可以在LSTM单元之间跳跃的能力。因此,HOP-LSTM可以捕获所需KCs类似的问题之间的长期的依赖关系。
Attentive Knowledge Tracing Models
在Transformer架构提出后,一些paper尝试将注意力机制融入KT模型。
核心思想:解决DKT局限将交互序列中的所有问题视为同等重要的问题,在一序列互动中学习问题的注意力权重,反映这些问题对预测正确回答下一个问题的概率的相对重要性。
关键Attentive Knowledge Tracing Models如表所示:
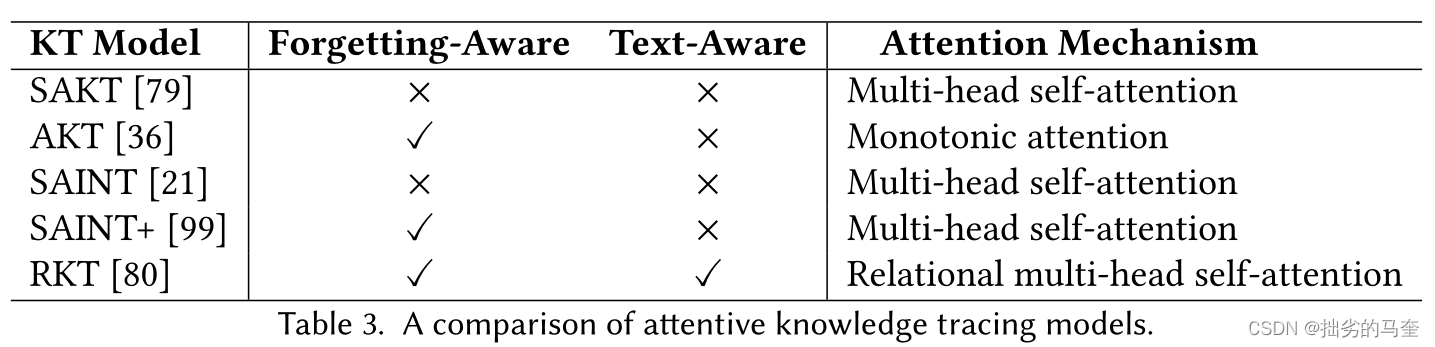
- Self-Attentive Knowledge Tracing (SAKT)
使用scaled dot-product attention mechanism学习拥有多个attention heads的attention矩阵。每个attention矩阵包含一个representative子空间的相对权重,这个representative子空间中是过去的交互序列中对于预测学生对当前问题答案的重要性。 - Attentive Knowledge Tracing (AKT)
修改scaled dot-product attention mechanism得到monotonic attention,以考虑随时间推移遗忘带来的影响。 - Separated Self-AttentIve Neural Knowledge Tracing (SAINT)
将问题的embedding序列和回答的embedding序列分开输入到注意网络。新型的SAINT+考虑了回答所用时间&两个回答之间的时间间隔。 - Relation-Aware Self-Attention for Knowledge Tracing (RKT)
RKT将注意力权重和关系系数结合在一起,关系系数是通过练习关系建模和遗忘行为建模得到的。对于练习关系建模,它利用问题的文本信息(例如,问题的文本信息)来表示问题并估计过去交互序列中问题之间的关系。遗忘行为建模,认为学生的遗忘行为随时间推移呈指数衰减。
( p . s . h y p e r b o l i c + t r a n s f o r m e r + K T ) \color{#ff111f}{(p.s. hyperbolic+transformer+KT)} (p.s.hyperbolic+transformer+KT)
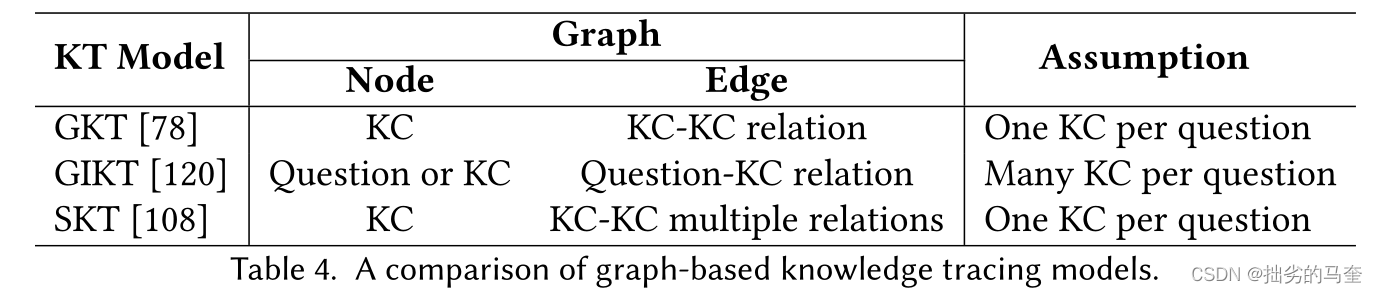
Graph-Based Knowledge Tracing Models
KCs之间有一定的关系,可以用GNN捕捉这种关系。
Text-Aware Knowledge Tracing Models
深度KT模型主要关注学生与问题的交互序列,预测学生正确回答最新问题的概率。
然而,并没有太多地考虑问题本身的 textual features,故有paper通过textual features提升KT任务的处理性能。
(p.s. fully hyperbolic NLP是否能提高性能?)
著名模型:
- Exercise-Enhanced Recurrent Neural Network (EERNN)
- Exercise-Aware Knowledge Tracing (EKT)
- Relation-A ware Self-Attention for Knowledge Tracing (RKT)
- Hierarchical Graph Knowledge Tracing (HGKT)
Forgetting-Aware Knowledge Tracing Models
遗忘是学习中需要考虑的一个重要因素。传统KT模型添加过去尝试的次数或先前交互的滞后时间等来引入遗忘行为。对遗忘产生影响的两个效应:forgetting effect和learning effect。
几种深度KT模型考虑学生追踪知识状态时的遗忘行为:
- Deep Knowledge Tracing (DKT) + forgetting
(1)学生回答具有相同KCs问题的次数;(2)自上次就具有相同KCs的问题进行交互以来的时间间隔;(3)自上次关于问题的交互以来的时间间隔,与其相关的KC无关。
(1)反映learning effect,(2)(3)反映forgetting effect - Knowledge Proficiency Tracing (KPT)
这是一种利用先验信息进行知识跟踪的概率矩阵分解模型。该模型考虑了两种先验:(1)问题先验:该模型使用由专家标记的Q-矩阵来刻画问题与知识中心之间的关系,以生成问题表征;
(2)学生先验:该模型通过联合应用学习曲线和遗忘曲线理论来捕捉学生知识状态随时间的变化。学习和遗忘因素的设计是基于这样的假设,即学生当前的知识状态主要受两个潜在原因的影响:(A)练习越多,她获得的相关知识状态就越高;(B)时间越长,她忘记的知识就越多。 - HawkesKT
认为:学生对某一知识认知能力的掌握不仅受先前对同一知识认知问题的交互作用的影响,也受其他问题的交互作用(交叉效应)的影响。
不同KC随时间的衰减率不同。 - Deep Graph Memory Network (DGMN)
给定一序列交互,DGMN使用注意力机制将问题与其相关的KC相关联。然后,计算序列上的遗忘特征,并使用门控机制融合问题嵌入、KC图嵌入和遗忘特征。门控输出用于预测下一个问题的概率。
小结
-
knowledge state:使用隐变量来对单个KC上的知识状态进行建模的DKT,到后来有记忆增强的KT模型(例如,DKVMN和SKVMN)表征能力提升,后来使用矩阵来对多个KC上的知识状态进行建模的文本感知KT模型(例如,EKT)。
-
KC dependencies:通常使用Q矩阵反映KC之间的关联。处理KC之间关联的方法有:
(1)使用注意机制来学习问题在其所需的KC方面如何相互关联;
(2)使用基于图的学习模型,如图神经网络,根据其所需的KC来学习KC之间或问题之间的关系。 -
feature augmentation:在一些特定的KT任务中,增加特征(如与遗忘行为有关的时间特征和与问题文本有关的文本特征)可以提高模型的性能。
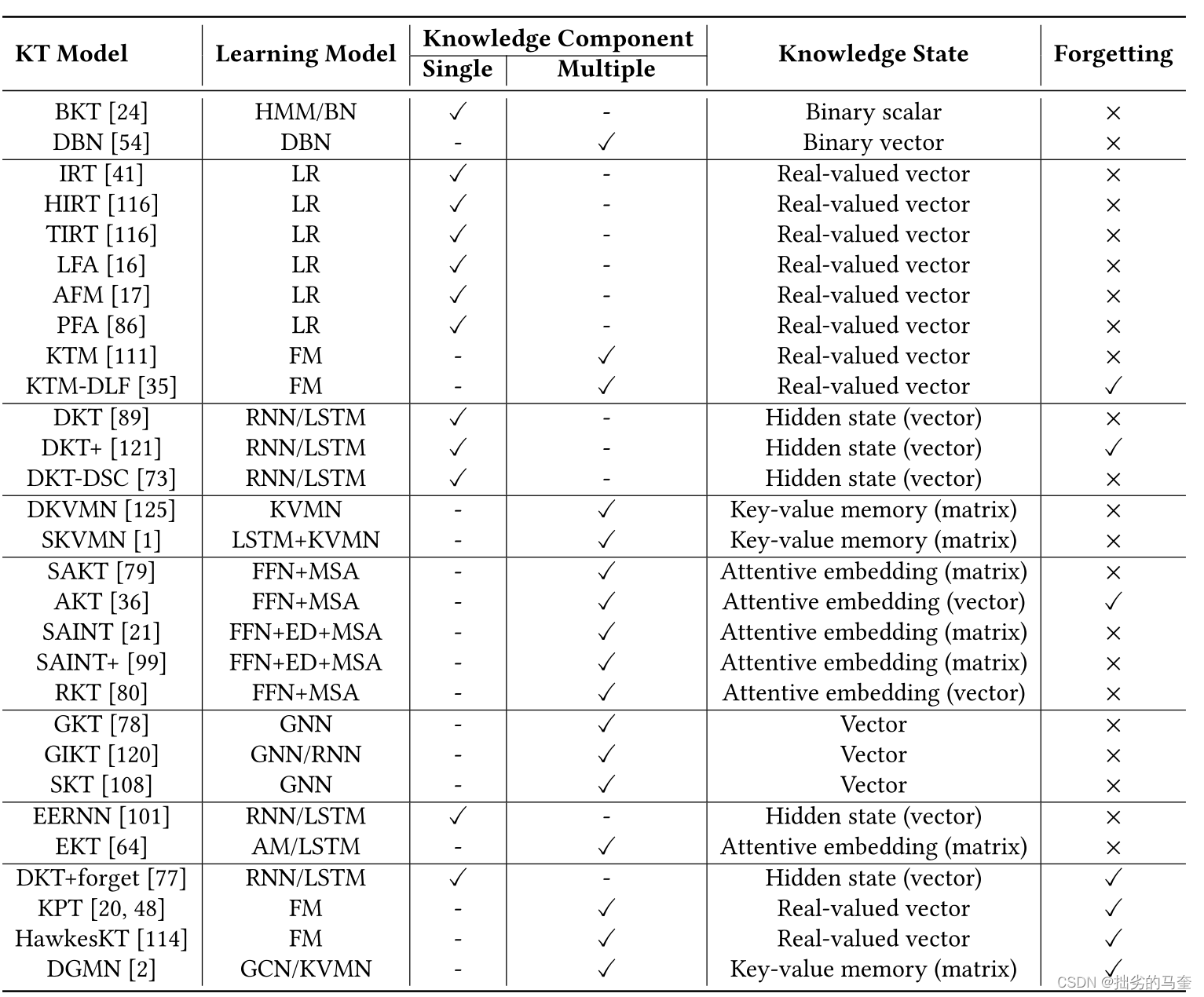
下表总结了各个KT模型的特点。HMM是隐马尔可夫模型的缩写,BN是贝叶斯网络的缩写,DBN是动态贝叶斯网络的缩写,LR是Logistic回归的缩写,FM是因式分解机器的缩写,GNN是图形神经网络的缩写,FFN是前馈网络的缩写,KVMN是关键值记忆网络的缩写,ED是编解码器模型的缩写,MSA是多头自我注意机制或变体的缩写),AM是注意机制的缩写。
3. 数据集
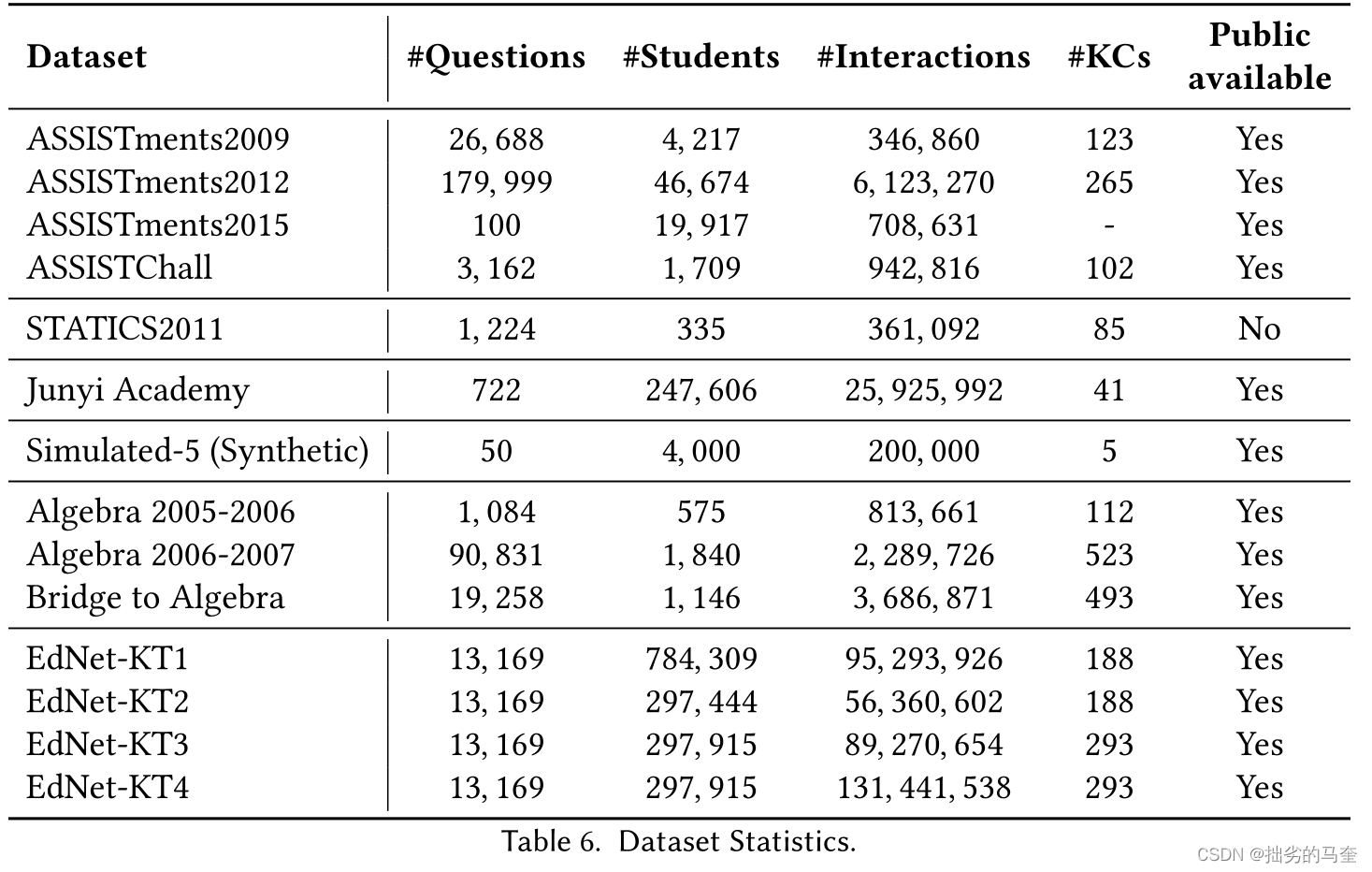
- ASSISTments
包含问题最多,最受欢迎。搜集自在线教育平台ASSISTment,随时间发有多个版本。包含多选题、开放式主观题等,包含问题-学生互动记录,未分配有标记。 - STATICS2011
包含361,092个互动、335个学生和1,224个问题。 - Junyi Academy Dataset
包含11,468,379个互动,25,649名学生,以及1,701个不同的问题,其中没有给出任何提示,学生只尝试了每个问题一次。 - Simulated-5 (Synthetic) Dataset
模拟虚拟学生在受控环境中回答关于一组KC的相同问题序列,总共有4000名虚拟学生回答了每个问题,产生了20万次互动。 - KDDcup Dataset
包含2005至2007年间13-14岁学生对代数问题的回答,分成三个子集。不同在于会根据问题相关KC将问题分为若干子问题。 - EdNet Dataset
四个子集组成:‘KT1’、‘KT2’、‘KT3’和‘KT4’。
KT1中有的问题会被打包,并要求全部都填写。KT2中包含用户在解决期间的活动(比如更换选项).KT3包含学生如何通过学习来解决问题。KT4是完整数据。
(p.s.标准设置实验才能比较结果,比如存在重复项可能会导致结果虚高。)
4. KT的应用
推荐系统
在线教育系统:
(1)使用KT模型估计学生的知识状态;
(2)使用推荐模型以知识状态为条件推荐学习材料。
Learning Provision and Quality Assurance
基于学生的知识状态为特定目标提供学习课程。教师使用根据学生的历史练习记录训练的KT模型识别课程的学习材料的合适课程,从而最大化学生的知识增长。
使用DKT模型来跟踪学生在学习特定课程模块后的知识状态的进展,为学生选择下一个学习模块,最大化他们的知识收获。
Interactive Learning
人类思维的本质主要是为通过现实世界的实践进行学习而设计的,而现实世界的实践通常是一种互动体验的形式(即状态、行动和奖励)。因此,教育游戏可以提供比传统教育方式(例如,教科书、讲座等)更符合我们自然学习能力的类似体验。
为了使教育游戏更加有效,KT模型通过评估玩家的知识进步来相应地调整游戏体验(调整挑战的难度,在游戏中打开新的部分,或者调整电脑对手的能力)。
learning to teach
虚拟学生,例如采用强化学习设定或者机器学习模型的intelligent agents,可以看作是真实世界的学生,这些agents也是要在不同的机器学习任务中学习一系列的skills。例如:DNN模型在图像分类任务中学习标签分类的技能,强化学习agent在游戏中掌握不同的技能。
Curriculum learning (CL)旨在学习一系列任务,使学生代理掌握一套技能。一个CL策略将意味着学习任务的统计分布,逐渐推动学生agent走向收敛。
另一个相关的范例是机器教学(MT),其目的是最小化机器学习场景中从训练数据中提取的训练样本的大小所表示的教学成本。MT包括两种模式:教师模式和学生模式。前者的目标是对训练数据进行采样,后者则学习最优的参数集,使任务中的损失函数最小。
(L2T)通过优化三个主要方面,包括训练数据采样、神经结构设计和损失函数设计,有针对性地定制学生agent/model的学习过程。在L2T中,教师agent遵循强化学习方法来优化处理前面提到的三个方面中的一个或多个方面的教学策略。可以观察到,增强传统机器学习过程的这些不同尝试的共同特征是需要跟踪学生模型的知识状态。因此,KT模型通过在训练过程中跟踪学生模型的知识状态,在这一应用领域有很大的潜力。KT模型的输出将形成教师模型的输入/状态,该教师模型旨在定制训练过程以加速学生模型的收敛。
知识扩充数据教学Knowledge Augmented Data Teaching (KADT)旨在通过跟踪学生学习任务中多个知识成分的知识进度来改进学生ML模型的数据教学策略。KADT方法包括一个知识跟踪模型,该模型根据潜在的知识成分动态地捕捉学生模型的知识进程。作者开发了一种注意力池机制来提取关于类别标签的学生模型的知识表示,这使得在重要的训练样本上制定数据教学策略成为可能。作者评估了Kadt方法在四种不同的机器学习任务上的性能,包括知识跟踪、情感分析、电影推荐和图像分类。结果与最先进的机器教学方法相比,实验证明,KADT在所有任务中的表现始终优于其他方法。
5. KT未来的研究方向(Research Direction, RD)
Multimodal and informative representation learning & datasets
RD1:什么information/satellite 数据可以用来提升KT模型的性能?
RD2:如何将这些数据针对KT任务进行表征?
RD3:如何创建KT任务的数据集来保证embedding更富有信息量?
提升embedding的信息量来提升KT模型的精度仍然有较大的提升空间,尤其融合多个特征空间的信号可以减少噪声,提升embedding质量。
对于RD3,数据集中要包含上下文信息,而不仅仅时使用ID编码的数据。需要跨越不同知识领域以及来自不同文化和教育水平的数据集,因为KT模型的性能在应用于其他人口和教育背景时可能会受到影响。
Self-supervised learning in knowledge tracing
监督学习有一个重大缺陷:需要大量高质量的标签数据来进行训练。自监督学习(SSL)已被证明在几个领域(NLP CV …)从未标记数据中学习是有效的。SSL可以自动生成标签,然后用有限数量的标记数据以有监督的学习方式进行训练。
RD4:借助预训练好的模型(比如NLP CV模型)针对KT任务生成更富含信息的表征。
RD5:如何能够在冷启动场景(初始数据过少)或不对称数据的情况下减小对模型训练带来的影响。
Interactive knowledge tracing
RD6:优化问题采样策略,提高KT模型在不限于冷启动场景中的性能。强化学习(RL)的最大回报策略可以从这个方向提升KT效果。
RD7:KT模型过程的透明化可以帮助提升教育系统的效果,所以研究KT模型的可解释性也是研究方向之一。
总结
这篇survey系统介绍了传统KT模型和深度KT模型,KT模型常用的数据集,KT模型的常见应用,KT模型未来可研究的几个方向。

















 641
641

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









