










一、模型的使用
通过主题模型的使用,可以使得收集的非结构化数据集,分析文档,获得相关文档的主题分类信息。
二、 模型涉及的相关算法和相关模型
SBERT模型、UMAP降维算法、HDBSCAN聚类算法、分词工具、词频统计算法(c-TF-IDF)、模型微调(可选)
三、模型结构组成
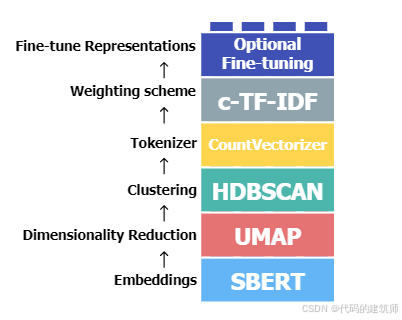
该模型是通过六个部分来进行处理
a.Embeddings部分
将从输入文档通过SBERT这类预训练嵌入模型转化为特征向量,这部分将产生高维向量
b.Dimensionality Reduction部分
这部分将得到的高维向量通过UMAP这类降维方法(类似的还有PCA、TSNE等降维方法),从而得到低维空间的向量表示
c.Clustering部分
利用聚类算法对低维向量表示进行聚类分析,得到聚类分布情况
d.Tokenizer部分
使用分词的方法将聚类后中各类中低维向量对应的原始文本进行分词处理
e.Weighting scheme部分
使用词频统计工具或算法来对分词后的结果进行词频统计
f.Fine-tuning部分
借助一些大模型对生成的结果进行微调处理
四、模型优点
由于BERTopic允许各个部分存在一些独立性,故可以使用一些外部的方法和模型进行替换,也就是可拆解性强!!
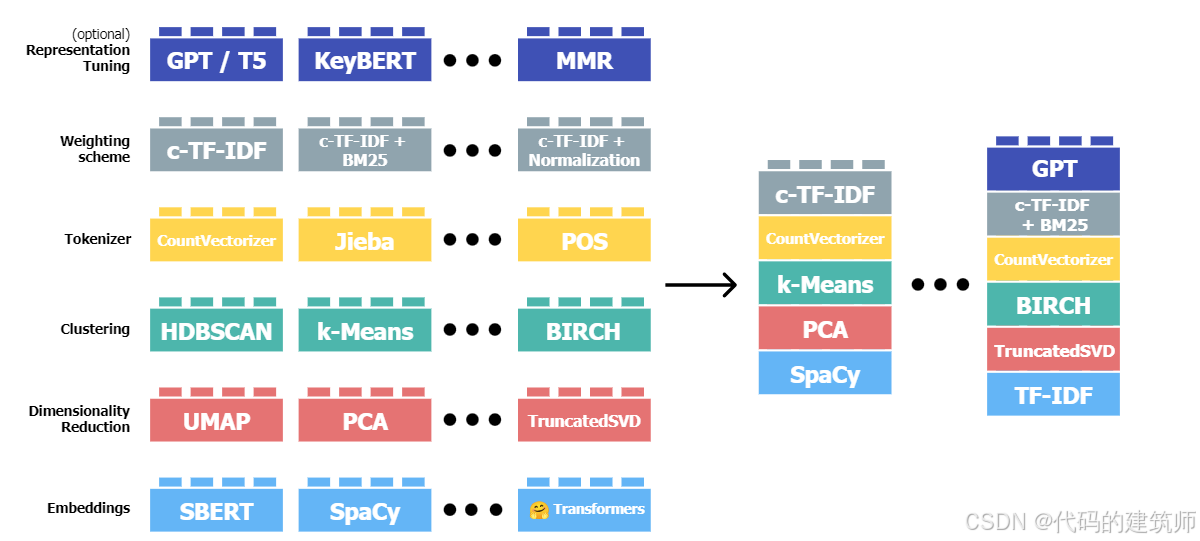
a.Embedding部分
这部分可以进行灵活的拆解,使得对输入文本转化为向量的格式可以使用不同的预训练嵌入模型来进行处理,那么如何进行修改呢?
下载嵌入模型的链接:https://huggingface.co/spaces/mteb/leaderboard
from bertopic import BERTopic topic_model=BERTopic(embedding_model='修改为已下载好的预训练嵌入模型路径')但是有一个更为灵活的修改方式!!
from sentence_transformers import SentenceTransformer embedding_model=SentenceTransfomer('预训练嵌入模型名') topic_model=BERTopic(embedding_model=embedding_model)同时,也可以使用OpenAI的外部API,并显示调用它在该模型中进行使用
importopenai from bertopic.backend import OpenAIBackend client=openai.OpenAI(api_key='API的密钥') embedding_model=OpenAIBackend(client,'test-embedding-ada-002') topic_model=BERTopic(embedding_model=embedding_model)注意:在使用替换的嵌入模型时,由于得到的TF-IDF矩阵在UMAP中的距离度量cosine不太适用,所以需要创建一个TF-IDF矩阵并将其嵌入fit-transform中
from sklearn.datasets import fetch_20newsgroups from sklearn.feature_extraction.text import TfidfVectorizer # Create TF-IDF sparse matrix docs = fetch_20newsgroups(subset='all', remove=('headers', 'footers', 'quotes'))['data'] vectorizer = TfidfVectorizer(min_df=5) embeddings = vectorizer.fit_transform(docs) # Train our topic model using TF-IDF vectors topic_model = BERTopic(stop_words="english") topics, probs = topic_model.fit_transform(docs, embeddings)以上关于Embedding的相关资料参考如下链接:
1. Embeddings - BERTopic
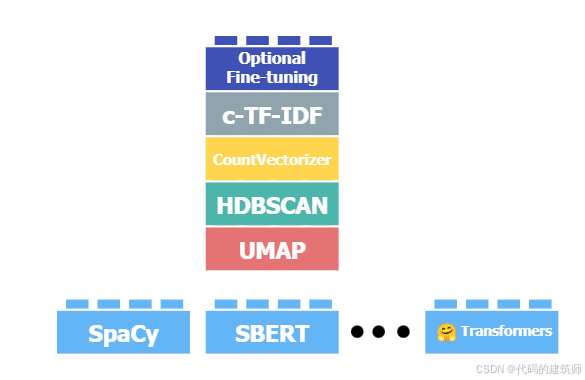
b.Dimensionality Reduction部分
该部分是为了避免出现由于嵌入的维数很高出现维数灾难,使得聚类变得困难,在BERTopic中默认适用UMAP这种处理方式。但是我们可以选择其他的降维算法。
使用UMAP方法相关代码,其中的相关参数可以根据任务进行修改:
from bertopic import BERTopic from umap import UMAP umap_model = UMAP(n_neighbors=15, n_components=5, min_dist=0.0, metric='cosine') topic_model = BERTopic(umap_model=umap_model)如果UMAP难以处理大量数据时,可以使用cuML通过GPU加速UMAP:
from bertopic import BERTopic from cuml.manifold import UMAP umap_model = UMAP(n_components=5, n_neighbors=15, min_dist=0.0) topic_model = BERTopic(umap_model=umap_model)如果我处理的数据不需要降维这一部分的处理,可以直接让其生成一个空的模型,使得其象征性的跳过这部分的处理:
from bertopic import BERTopic from bertopic.dimensionality import BaseDimensionalityReduction # Fit BERTopic without actually performing any dimensionality reduction empty_dimensionality_model = BaseDimensionalityReduction() topic_model = BERTopic(umap_model=empty_dimensionality_model)以上关于Dimensionality Reduction的相关资料参考如下链接:
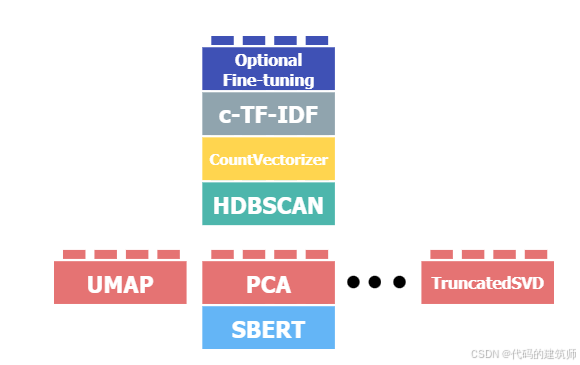
c. Clustering部分
该部分是非常重要的一步,如果聚类表现得性能越好,主题表示就越准确。该BERTopic默认使用HDBSCAN的方式捕获不同密度的数据结构来执行聚类。推荐使用其默认的这种聚类方法!!!!
同时在处理大量数据时,也可以使用cuML通过GPU加速HDBSCAN:
from bertopic import BERTopic from cuml.cluster import HDBSCAN hdbscan_model = HDBSCAN(min_samples=10, gen_min_span_tree=True, prediction_data=True) topic_model = BERTopic(hdbscan_model=hdbscan_model)以上关于Clustering的相关资料参考如下链接:
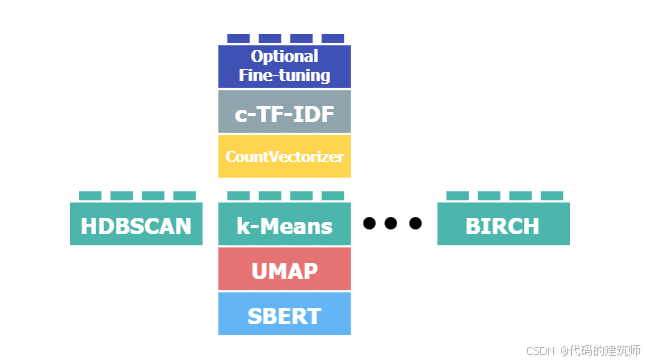
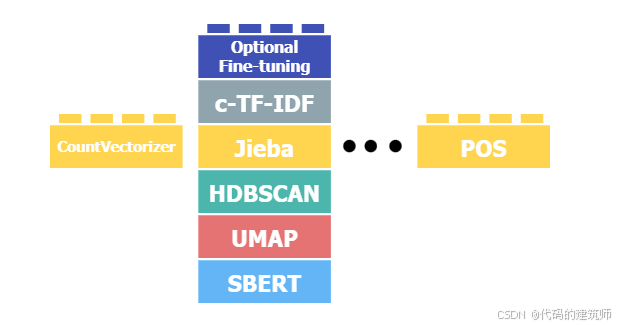
d.Vectorizers部分
该部分负责创建主题表示
该部分的使用方法直接可以参考以下链接,这个链接全在讲该部分的参数怎么修改以及各参数的含义:
4. Vectorizers - BERTopic
e. c-TF-IDF
这部分为什么叫c-TF-IDF,而不叫TF-IDF?
因为:TF-IDF是在以文档为最小单元上工作,而c-TF-IDF是将TF-IDF调整到聚类主题上工作(这里是将一个集群看作一个文档处理,而不是一组文档来处理),这里的c指的是class,故称其为c-TF-IDF。该计算方式在BERTopic中默认使用
其TF-IDF计算方式:
c-TF-IDF计算方式:
以上关于c-TF-IDF的相关资料参考如下链接,其中涉及的变式TF-IDF的使用方法也在该链接中:
5. c-TF-IDF - BERTopic




f. Fine-tuning部分
该部分与相关的仅有,模型更换的部分代码的修改:
6A. Representation Models - BERTopic
提示工程、文档文本截断:
6B. LLM & Generative AI - BERTopic
主题多重表示:
以上资料均参考于The Algorithm - BERTopic
以上均是与我自己的兴趣相关的内容进行的理解,仅自用!!


















 1695
1695

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









