







作者:无名,某小公司算法专家
排版:一元,四品炼丹师
公众号:炼丹笔记关于Attention和Transformer的灵魂拷问
背景
现在几乎很多搞深度学习的朋友都把attention和Transformer等当做是基础知识去考察,但是经过我的几轮面试发现,我发现好像90%的朋友都回答不上来或者不是很令我们满意,因为平时工作繁忙,也知道大家都不容易,为了尊重所有的候选人,我们也做了很多功课。
一般我们问的很多基础问题都是直接从网上拿过来或者是业务中碰到的,大家都知道准备面试的朋友会准备面试的问题,但其实我们面试官也需要针对企业业务和候选人的简历准备诸多问题,这可能是第一次公开我的部分面试记录,诸多的细节大家可以参考文末的参考文献。本文分享部分我的面试笔记,应该算是比较基础的。
一般在搜索推荐或者深度学习相关的面试中,我们会考察一下Transformer和Attention相关的问题,而核心主要集中在下面两张图上面:
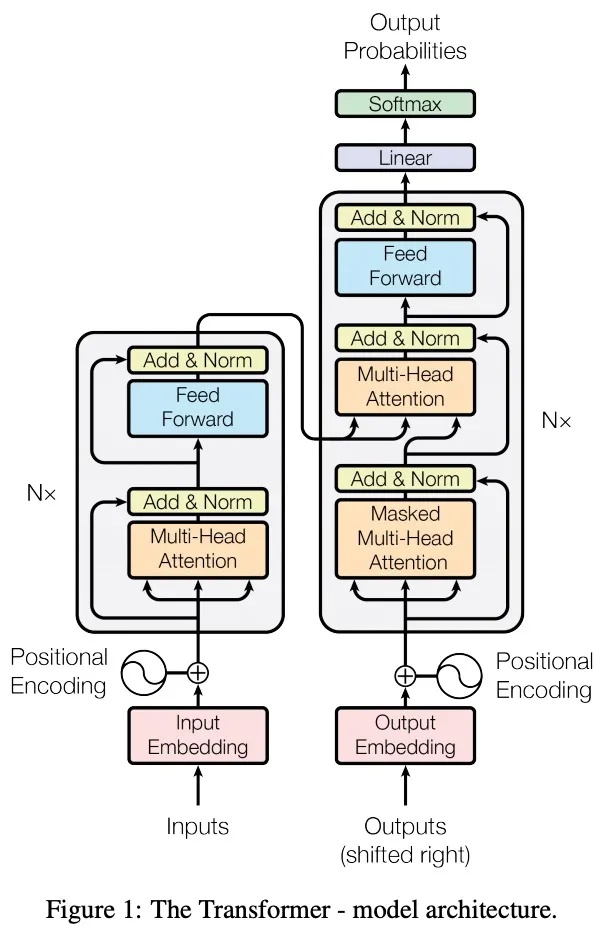
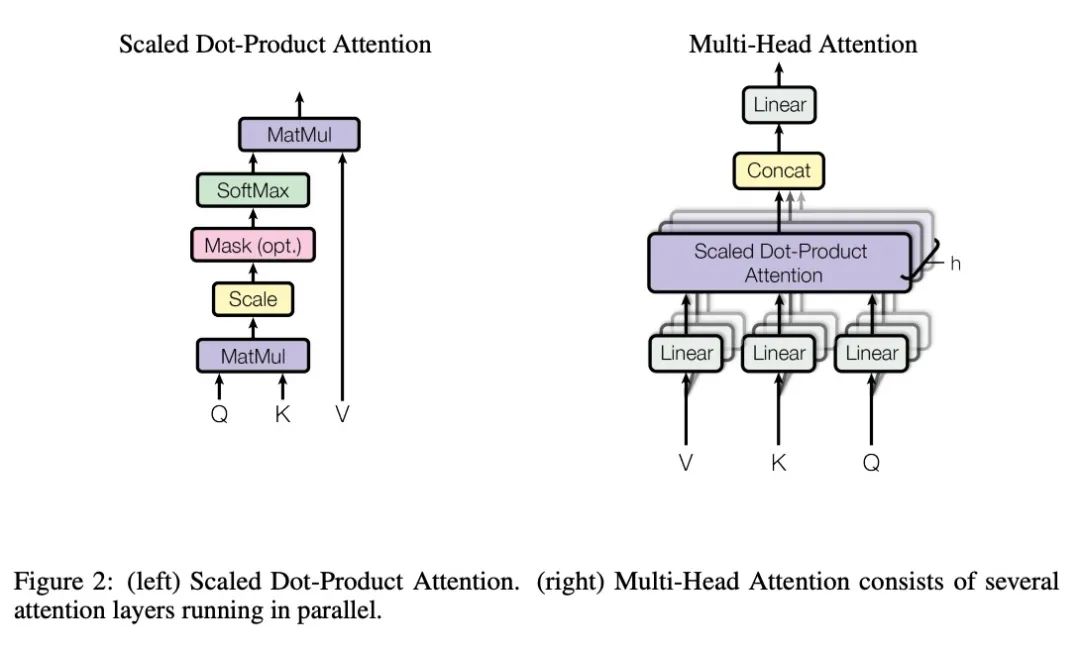
1. 为什么Transformer 需要进行 Multi-head Attention?
Multi-Head的数学形式如下:
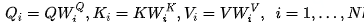
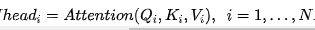
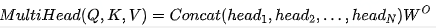
关于为什么使用Transformer进行Multi-head Attention的理由解释的不错的有下面两点:
- 将模型分为多个头,形成多个子空间,可以让模型去关注不同方面的信息;
- 把多头注意力看作是一种ensemble,模型内部的集成,类似于CNN中我们经常会使用多个滤波器一样,所以很多时候我们会认为多头注意力可以帮助我们捕捉到更为丰富的特征/信息。
但在个人的时间中,我们发现并不是multi-head的参数设置越大越好,有的时候1就已经非常好了,去掉一些头效果依然有不错的效果(而且效果下降可能是因为参数量下降),这是因为在头足够的情况下,这些头已经能够有关注位置信息、关注语法信息、关注罕见词的能力了,再多一些头,无非是一种enhance或noise而已。
2. Transformer为什么Q和K使用不同的权重矩阵生成,为何不能使用同一个值进行自身的点乘?
如果Q,K,V都是一个值,那么就变为了Self-Attention的形式
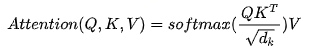
在实践中,Q和K的乘法是为了得到二者的相似度,一般我们的K和V是相同的,Q和K进行操作是为了得到一个attention score矩阵,这样可以得到Q关于V的表示,但一般我们再计算Q,K,V的时候会先都分别乘上一个不同的矩阵W,这么做可以增加模型的表达能力,实践中经常也会带来一定的帮助。
3.Transformer中的attention为什么要进行scaled?
数学上的理解:首先我们看attention score的计算,它的数学形式如下:
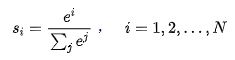
从上面的式子中,我们发现只要我们的数字中,出现了差异相对较大的情况,例如[1,2,10], 那么就会出现下面的情况。这种情况还会带来一个问题,梯度更新困难,具体细节可以参考引文。

0.9995413380353424. 维度与点积大小的关系是怎么样的,为什么使用维度的根号来放缩?
可以控制方差,有效缓解梯度消失的问题。详细细节可参考参考文献[3]
5. Transformer 如何并行化的?
Transformer在Decoder侧是没有并行的,一个一个解码,当前时刻的输入依赖于上一个时刻的输出。
所以Transformer的并行主要集中在Encoder侧,不同词(Token)或者元素(推荐系统中的每一个历史点击商品)是可以并行的。
Transformer是可以并行处理在Encoder端的整个序列信息的,例如在self-attention模块,对于某个序列X1,X2,...Xn,self-attention模块可以直接计算Xi,Xj的点乘结果,而 RNN的模型就必须按照顺序从到的顺序进行计算。
6. Attention相较于CNN和RNN的优势有哪些?
- 参数少:模型复杂度跟 CNN、RNN 相比,复杂度更小,参数也更少。所以对算力的要求也就更小。
- 速度快:Attention 解决了 RNN 不能并行计算的问题。Attention机制每一步计算不依赖于上一步的计算结果,因此可以和CNN一样并行处理。
- 效果好:在 Attention 机制引入之前,有一个问题大家一直很苦恼:长距离的信息会被弱化,就好像记忆能力弱的人,记不住过去的事情是一样的。Attention 是挑重点,就算文本比较长,也能从中间抓住重点,不丢失重要的信息。下图红色的预期就是被挑出来的重点。
7. 为什么引入Attention机制?
此处回答摘自引文[6]
Attention又叫做注意力机制,顾名思义,就是希望可以让模型对重要信息重点关注并充分学习吸收的技术,它不是一个完整的模型,可以应用于任何序列化的模型中。
传统的编码是无法体现对一个句子序列中不同语素的关注程度,在自然语言中,一个句子中的不同部分是有不同含义和重要性的,比如:I hate this movie.如果做情感分析,明显对hate这个词语应当关注更多。当然是用CNN和RNN能够编码这种信息。但是如果序列长度很长的情况下,这种方法会有一定的瓶颈。CNN的核心就是卷积核能够变相学习n-gram的信息,如果是用hierarchical的卷积核,那么越上层的卷积核越能编码原始距离较远的词组的信息。但是这种编码能力也是有上限的,对于较长的文本,模型效果不会再提升太多。RNN也是同理。基于参加达观文本分类的经历,对于这种长文本处理,使用RNN+attention的效果比使用单纯的RNN+pooling的效果要好不少。
8. Attention中权重的常见计算方式有哪些?

参考文献
- 为什么Transformer 需要进行 Multi-head Attention?:https://www.zhihu.com/question/341222779
- Transformer为什么Q和K使用不同的权重矩阵生成,为何不能使用同一个值进行自身的点乘?:https://www.zhihu.com/question/319339652
- transformer中的attention为什么scaled?:https://www.zhihu.com/question/339723385/answer/782509914
- 1分钟|聊聊Transformer的并行化:https://zhuanlan.zhihu.com/p/157884112
- Attention Is All You Need:https://arxiv.org/pdf/1706.03762.pdf
- Attention机制简单总结:https://zhuanlan.zhihu.com/p/46313756
http://weixin.qq.com/r/XSjP1zrEzGezrX60931P (二维码自动识别)


















 1587
1587

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









