







文章目录
什么是Attention
- Attention(注意力机制)是一种机制,可以应用到许多不同的模型中,像CNN、RNN、seq2seq等。Attention通过权重给模型赋予了区分辨别的能力,从而抽取出更加关键及重要的信息,使模型做出更加准确的判断,同时不会对模型的计算和存储带来更大的开销。
- Attention模型的基本表述可以这样理解成:当我们人在看一样东西的时候,我们当前时刻关注的一定是我们当前正在看的这样东西的某一地方,换句话说,当我们目光移到别处时,注意力随着目光的移动野在转移,这意味着,当人们注意到某个目标或某个场景时,该目标内部以及该场景内每一处空间位置上的注意力分布是不一样的。
- 这一点在如下情形下同样成立:当我们试图描述一件事情,我们当前时刻说到的单词和句子和正在描述的该事情的对应某个片段最先关,而其他部分随着描述的进行,相关性也在不断地改变。
举个例子:
Attention 机制很像人类看图片的逻辑,当我们看一张图片的时候,我们并没有看清图片的全部内容,而是将注意力集中在了图片的焦点上。大家看一下下面这张图: 像上面这张图,密码这俩个字比较大,我们一般先看到的是密码,其次是上面的NLP智慧语言的魔力人际沟通的…,但是很少会有人注意到右下角的https://blog.csdn.net/qq_19409848这个网址。
像上面这张图,密码这俩个字比较大,我们一般先看到的是密码,其次是上面的NLP智慧语言的魔力人际沟通的…,但是很少会有人注意到右下角的https://blog.csdn.net/qq_19409848这个网址。
这就是我们的视觉系统就是一种 Attention机制,将有限的注意力集中在重点信息上,从而节省资源,快速获得最有效的信息。
为什么需要Attention?
- 最基本的seq2seq模型包含一个encoder和一个decoder,通常的做法是将一个输入的句子编码成一个固定大小的state,然后作为decoder的初始状态(当然也可以作为每一时刻的输入),但这样的一个状态对于decoder中的所有时刻都是一样的。
- 序列输入时,随着序列的不断增长,原始根据时间步的方式的表现越来越差,这是由于原始的这种时间步模型设计的结构有缺陷,即所有的上下文输入信息都被限制到固定长度,整个模型的能力都同样收到限制,我们暂且把这种原始的模型称为简单的编解码器模型。
- 编解码器的结构无法解释,也就导致了其无法设计。
- 在RNN的原始问题中,对于长序列的文本效果不是很好,因为长时间的长序列导致长时依赖为题。前面的一些信息被丢失
下图中是没有加入Attention时的seq2seq:

- attention即为注意力,需要attention的原因是非常直观的。比如,我们期末考试的时候,我们需要老师划重点,划重点的目的就是为了尽量将我们的attention放在这部分的内容上,以期用最少的付出获取尽可能高的分数;
下图中是加入Attention时的seq2seq: 动图:
动图:
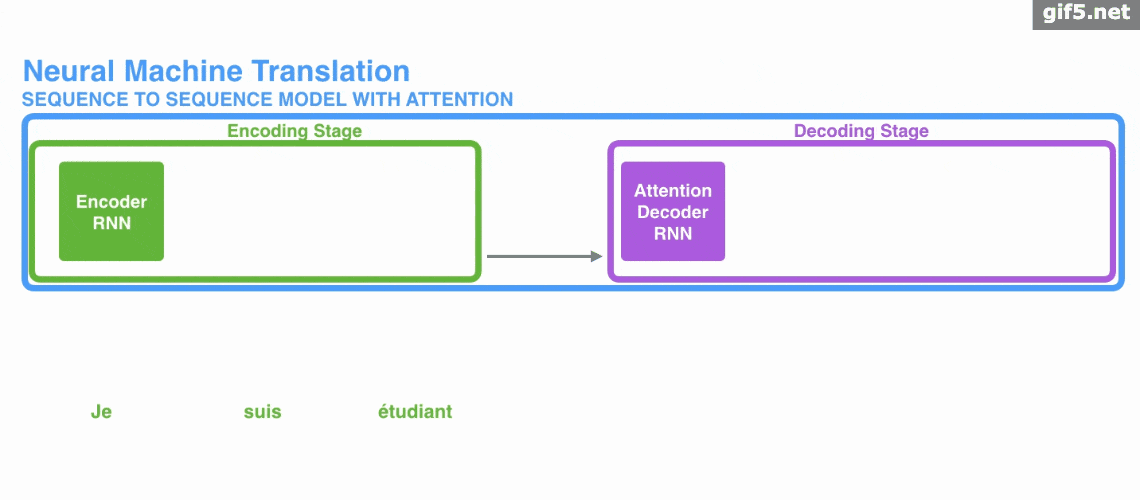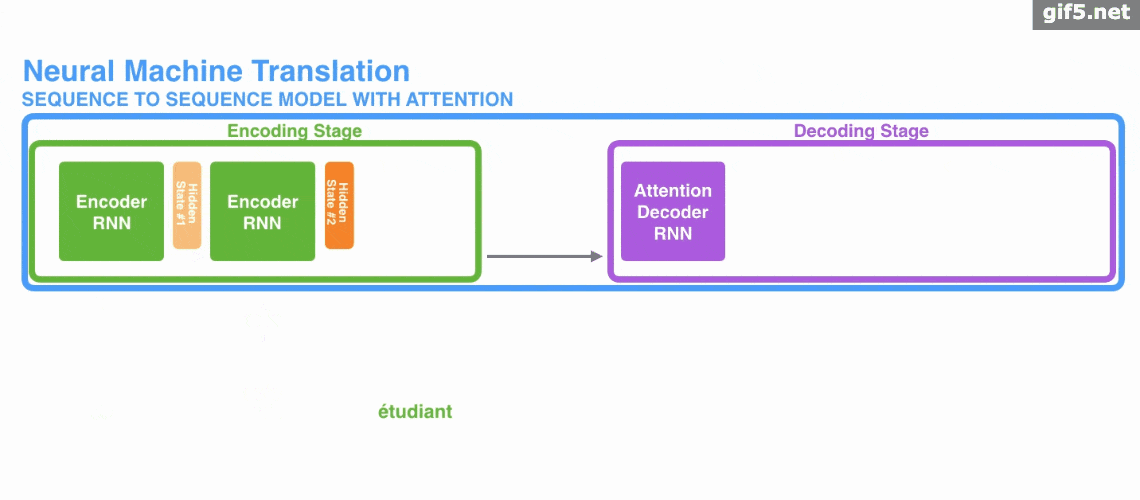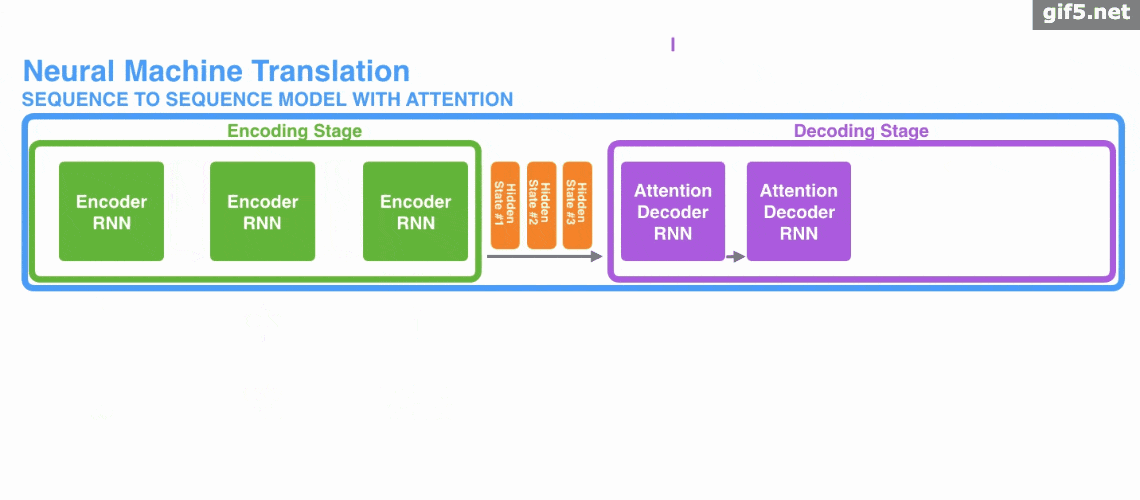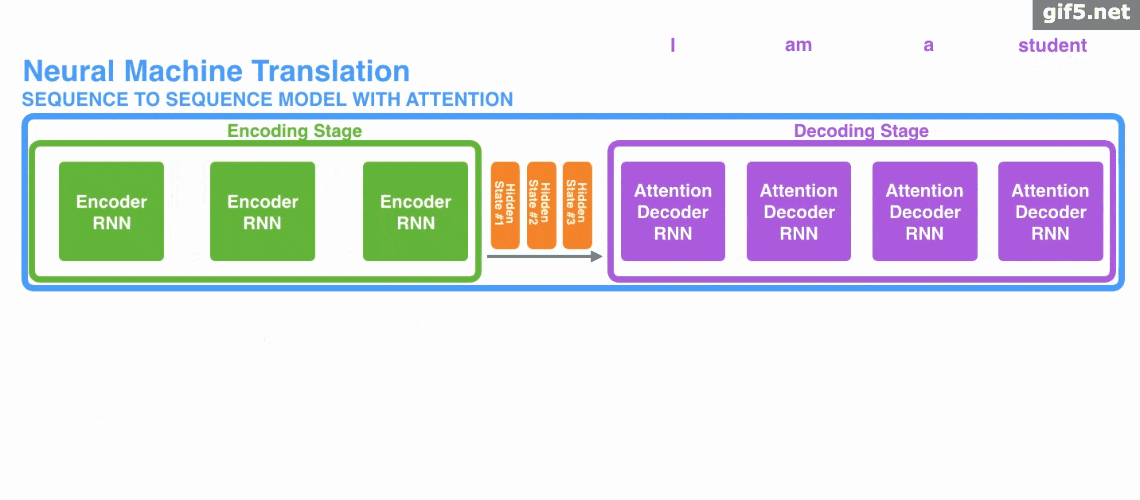
Attention 的3大优点
- 参数少:模型复杂度跟 CNN、RNN 相比,复杂度更小,参数也更少。所以对算力的要求也就更小。
- 速度快:Attention 解决了 RNN 不能并行计算的问题。Attention机制每一步计算不依赖于上一步的计算结果,因此可以和CNN一样并行处理。
- 效果好:在 Attention 机制引入之前,有一个问题大家一直很苦恼:长距离的信息会被弱化,就好像记忆能力弱的人,记不住过去的事情是一样的。Attention 是挑重点,就算文本比较长,也能从中间抓住重点,不丢失重要的信息。下图红色的预期就是被挑出来的重点。

Seq2Seq Attention计算过程
在计算Attention的时候使用的是编码器的输出,在计算状态的时候使用的是编码器的状态信息。

- Encoder hidden states(编码器的输出)/output values(状态): h i h_i hi; 总Encoder时刻n个。
- 时刻t,Decoder hidden states(解码器的状态): s t s_t st;
- 基于每个时刻Encoder输出以及上一个时刻Decoder的状态来构建Attention Scores(评分/置信度): e t , i = F ( h i , s t − 1 ) e t = ( e t , 1 , e t , 2 , . . . , e t , n ) ( t 表 示 解 码 器 的 时 刻 , i 表 示 编 码 器 的 时 刻 ) e_{t,i}=F(h_i,s_{t-1})\\ e_t=(e_{t,1},e_{t,2},...,e_{t,n})\\(t表示解码器的时刻,i表示编码器的时刻) et,i=F(hi,st−1)et=(et,1,et,2,...,et,n)(t表示解码器的时刻,i表示编码器的时刻)
- 对e进行softmax转换,得到概率分布: α t = s o f t max ( e t ) \alpha_t=soft\max(e_t) αt=softmax(et)
- 基于概率分布以及所有Encoder的状态计算出Attention值: a t = ∑ i = 1 n α t , i h i a_t=\sum_{i=1}^n\alpha_{t,i}h_i at=i=1∑nαt,ihi
- 将Decoder当前时刻的输入和Attention值结合形成新的输入数据 y t ′ = [ y t ; a t ] y'_t=[y_t;a_t] yt′=[yt;at]然后进行普通的RNN Decoder操作
Attention Scores计算方式
乘法Attention:
e t , i = s t − 1 T h i e_{t,i}=s^T_{t-1}h_i et,i=st−1Thi e t , i = s t − 1 T h i d e_{t,i}=\frac{s^T_{t-1}h_i}{\sqrt{d}} et,i=dst−1Thi e t , i = s t − 1 T W h i e_{t,i}=s^T_{t-1}Wh_i et,i=st−1TWhi
加法Attention:
e t , i = u T tanh ( W 1 h i + W 2 s t − 1 ) ( t e n s o r f l o w 默 认 的 方 式 ) e_{t,i}=u^T\tanh(W_1h_i+W_2s_{t-1})\ (tensorflow默认的方式) et,i=uTtanh(W1hi+W2st−1) (tensorflow默认的方式) e t , i = W 1 h i + W 2 s t − 1 e_{t,i}=W_1h_i+W_2s_{t-1} et,i=W1hi+W2st−1 e t , i = W h i e_{t,i}=Wh _i et,i=Whi
一种更通用的Attention的计算方式(QKV)
-
此时给定Target中的某个元素Query,通过计算Query和各个Key的相似性或 者相关性,得到每个Key对应Value的权重系数,然后对Value进行加权求和, 即得到了最终的Attention数值。
-
所以本质上Attention机制是对Source中元素 的Value值进行加权求和,而Query和Key用来计算对应Value的权重系数。

-
第一步: query 和 key 进行相似度计算,得到权值
-
第二步:将权值进行归一化,得到直接可用的权重
-
第三步:将权重和 value 进行加权求和

Attention又一种计算方式

Seq2Seq Attention形状
形状一

形状二

形状三

Attention的计算区域
根据Attention的计算区域,可以分成以下几种:
Soft Attention
计算Attention的时候,是与编码器所有时刻输出计算,受序列长度的影响,序列越长计算量就越大,运行数度就慢
- 这是比较常见的Attention方式,对所有key求权重概率,每个key都有一个对应的权重,是一种全局的计算方式(也可以叫Global Attention)。这种方式比较理性,参考了所有key的内容,再进行加权。但是计算量可能会比较大一些。

Hard Attention
把概率最大的设置为1,剩下的设置为0解决Soft Attention序列太长计算量大的问题
- 这种方式是直接精准定位到某个key,其余key就都不管了,相当于这个key的概率是1,其余key的概率全部是0。因此这种对齐方式要求很高,要求一步到位,如果没有正确对齐,会带来很大的影响。另一方面,因为不可导,一般需要用强化学习的方法进行训练。(或者使用gumbel softmax之类的)

Local Attention
- 这种方式其实是以上两种方式的一个折中,对一个窗口区域进行计算。先用Hard方式定位到某个地方,以这个点为中心可以得到一个窗口区域,在这个小区域内用Soft方式来算Attention。
- 和Global Attention在同一篇论文中被提出;相当于Soft Attention 和Hard Attention中间状态(半硬半软Attention)
- 对于时刻t的词汇,模型首先产生一个对齐位置pt(aligned position), context vector c由编码器中的隐状态计算得到,编码 器的隐状态不是所有的隐状态,而是在区间[pt-D, pt+D]中,D的 大小由经验给定。
D是超参数,人为给定。在计算Attention的时候是计算前后左右的D个Attention

Local Attention,这种方式只使用内部信息,key和value以及query只和输入原文有关,在self attention中,key=value=query。既然没有外部信息,那么在原文中的每个词可以跟该句子中的所有词进行Attention计算,相当于寻找原文内部的关系。
Attention层次结构
结构方面根据是否划分层次关系,分为单层attention,多层attention和多头attention:
- 单层Attention,这是比较普遍的做法,用一个query对一段原文进行一次attention。
- 多层Attention,一般用于文本具有层次关系的模型,假设我们把一个document划分成多个句子,
- 在第一层,我们分别对每个句子使用attention计算出一个句向量(也就是单层attention);
- 在第二层,我们对所有句向量再做attention计算出一个文档向量(也是一个单层attention),
- 最后再用这个文档向量去做任务。
- 多头Attention,这是Attention is All You Need中提到的multi-head attention,用到了多个query对一段原文进行了多次attention,每个query都关注到原文的不同部分,相当于重复做多次单层attention:
h e a d i = A t t e t i o n ( q i , K , V ) head_i=Attetion(q_i,K,V) headi=Attetion(qi,K,V) - 最后再把这些结果拼接起来: M u l t H e a d ( Q , K , V ) = C o n c a t ( h e a d 1 , . . . , h e a d h ) W o MultHead(Q,K,V)=Concat(head_1,...,head_h)W^o MultHead(Q,K,V)=Concat(head1,...,headh)Wo
模型方面
从模型上看,Attention一般用在CNN和LSTM上,也可以直接进行纯Attention计算。
CNN+Attention
CNN的卷积操作可以提取重要特征,我觉得这也算是Attention的思想,但是CNN的卷积感受视野是局部的,需要通过叠加多层卷积区去扩大视野。另外,Max Pooling直接提取数值最大的特征,也像是hard attention的思想,直接选中某个特征。
CNN上加Attention可以加在这几方面:
- a. 在卷积操作前做attention,比如Attention-Based BCNN-1,这个任务是文本蕴含任务需要处理两段文本,同时对两段输入的序列向量进行attention,计算出特征向量,再拼接到原始向量中,作为卷积层的输入。
- b. 在卷积操作后做attention,比如Attention-Based BCNN-2,对两段文本的卷积层的输出做attention,作为pooling层的输入。
- c. 在pooling层做attention,代替max pooling。比如Attention pooling,首先我们用LSTM学到一个比较好的句向量,作为query,然后用CNN先学习到一个特征矩阵作为key,再用query对key产生权重,进行attention,得到最后的句向量。
LSTM+Attention
LSTM内部有Gate机制,其中input gate选择哪些当前信息进行输入,forget gate选择遗忘哪些过去信息,我觉得这算是一定程度的Attention了,而且号称可以解决长期依赖问题,实际上LSTM需要一步一步去捕捉序列信息,在长文本上的表现是会随着step增加而慢慢衰减,难以保留全部的有用信息。
LSTM通常需要得到一个向量,再去做任务,常用方式有:
-
a. 直接使用最后的hidden state(可能会损失一定的前文信息,难以表达全文)
-
b. 对所有step下的hidden state进行等权平均(对所有step一视同仁)。
-
c. Attention机制,对所有step的hidden state进行加权,把注意力集中到整段文本中比较重要的hidden state信息。性能比前面两种要好一点,而方便可视化观察哪些step是重要的,但是要小心过拟合,而且也增加了计算量。
纯Attention
Attention is all you need,没有用到CNN/RNN,乍一听也是一股清流了,但是仔细一看,本质上还是一堆向量去计算attention。
相似度计算方式
在做attention的时候,我们需要计算query和某个key的分数(相似度),常用方法有:
- 点乘:最简单的方法,
s ( q , k ) = q T k s(q,k)=q^Tk s(q,k)=qTk - 矩阵相乘:
s ( q , k ) = q T k s(q,k)=q^Tk s(q,k)=qTk - cos相似度:
s ( q , k ) = q T k ∣ ∣ q ∣ ∣ ⋅ ∣ ∣ k ∣ ∣ s(q,k)=\frac{q^Tk}{||q||\cdot||k||} s(q,k)=∣∣q∣∣⋅∣∣k∣∣qTk - 串联方式:把q和k拼接起来,
s ( q , k ) = W [ q : k ] s(q,k)=W[q:k] s(q,k)=W[q:k] - 用多层感知机也可以:
s ( q , k ) = υ a T tanh ( W q + U k ) s(q,k)=\upsilon^T_a\tanh(Wq+Uk) s(q,k)=υaTtanh(Wq+Uk)
引用
https://easyai.tech/ai-definition/attention/
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











