







注:仅记录学习,如有侵权,联系删除。
来源:mathworks机器学习入门之旅
机器学习入门之旅
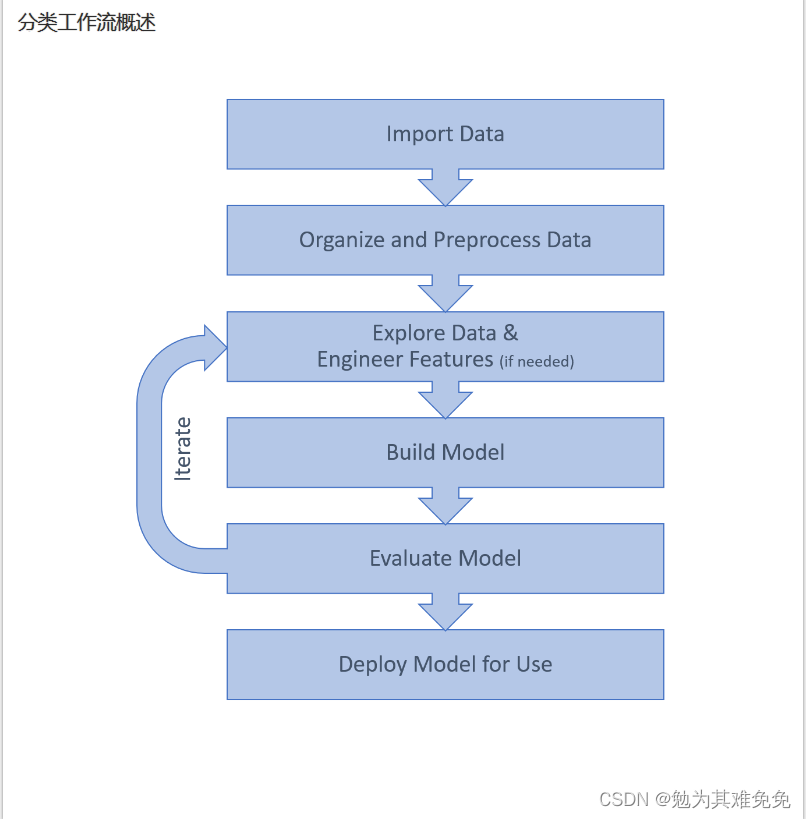
分类工作流程
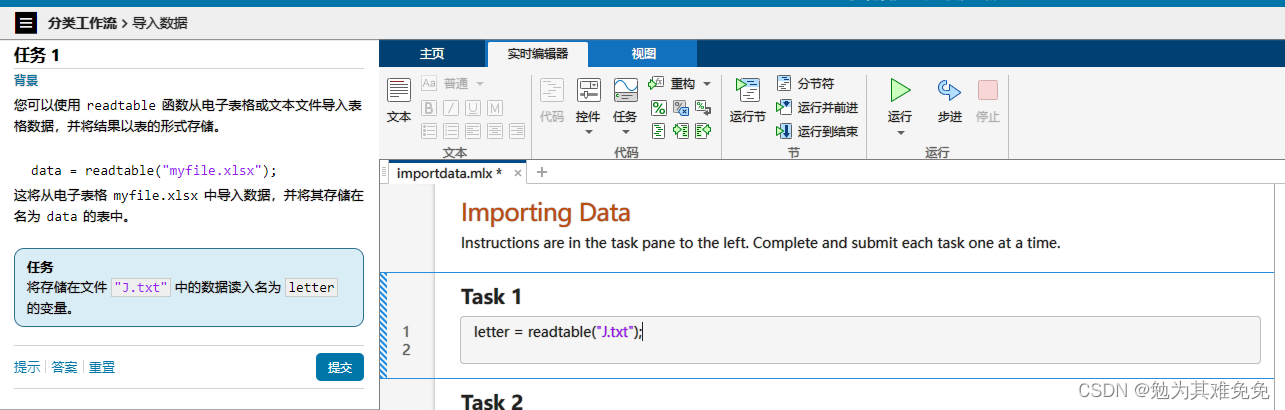
导入数据
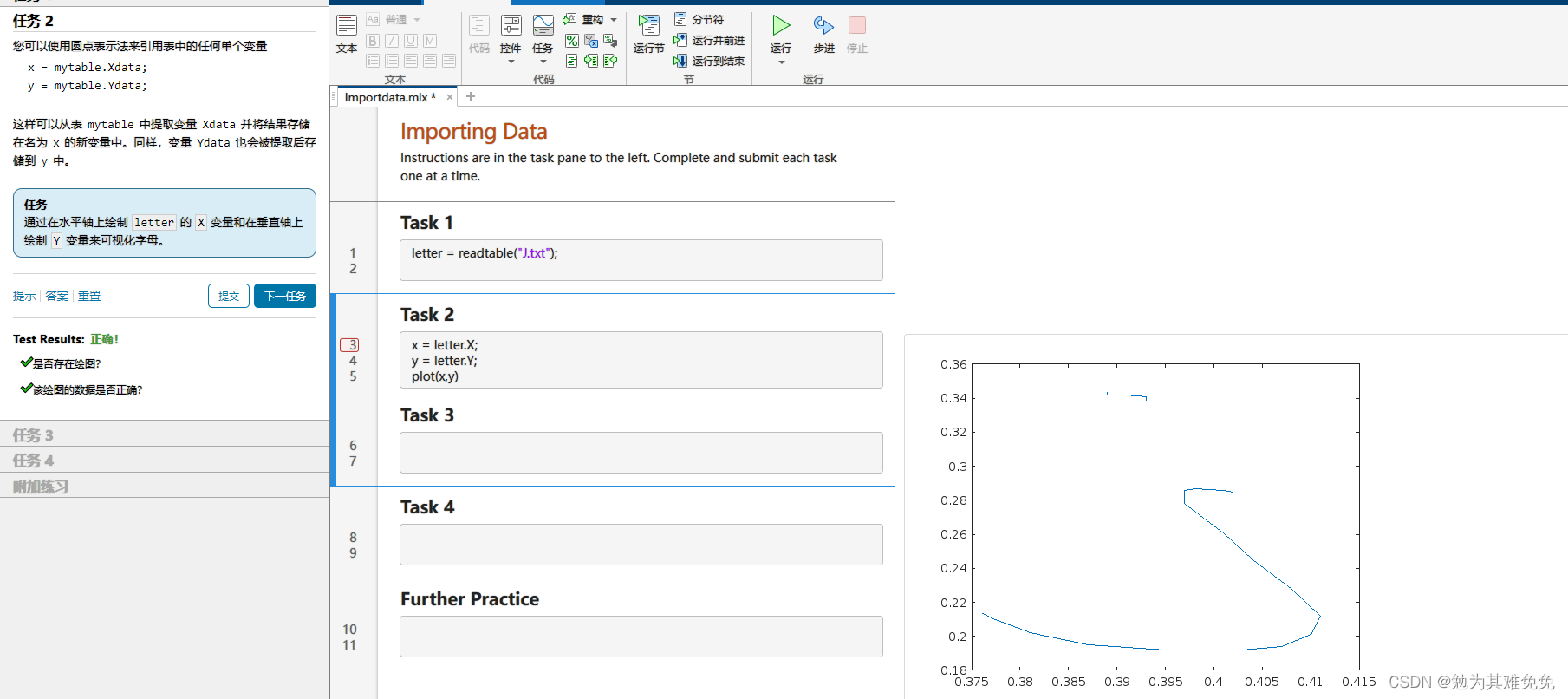

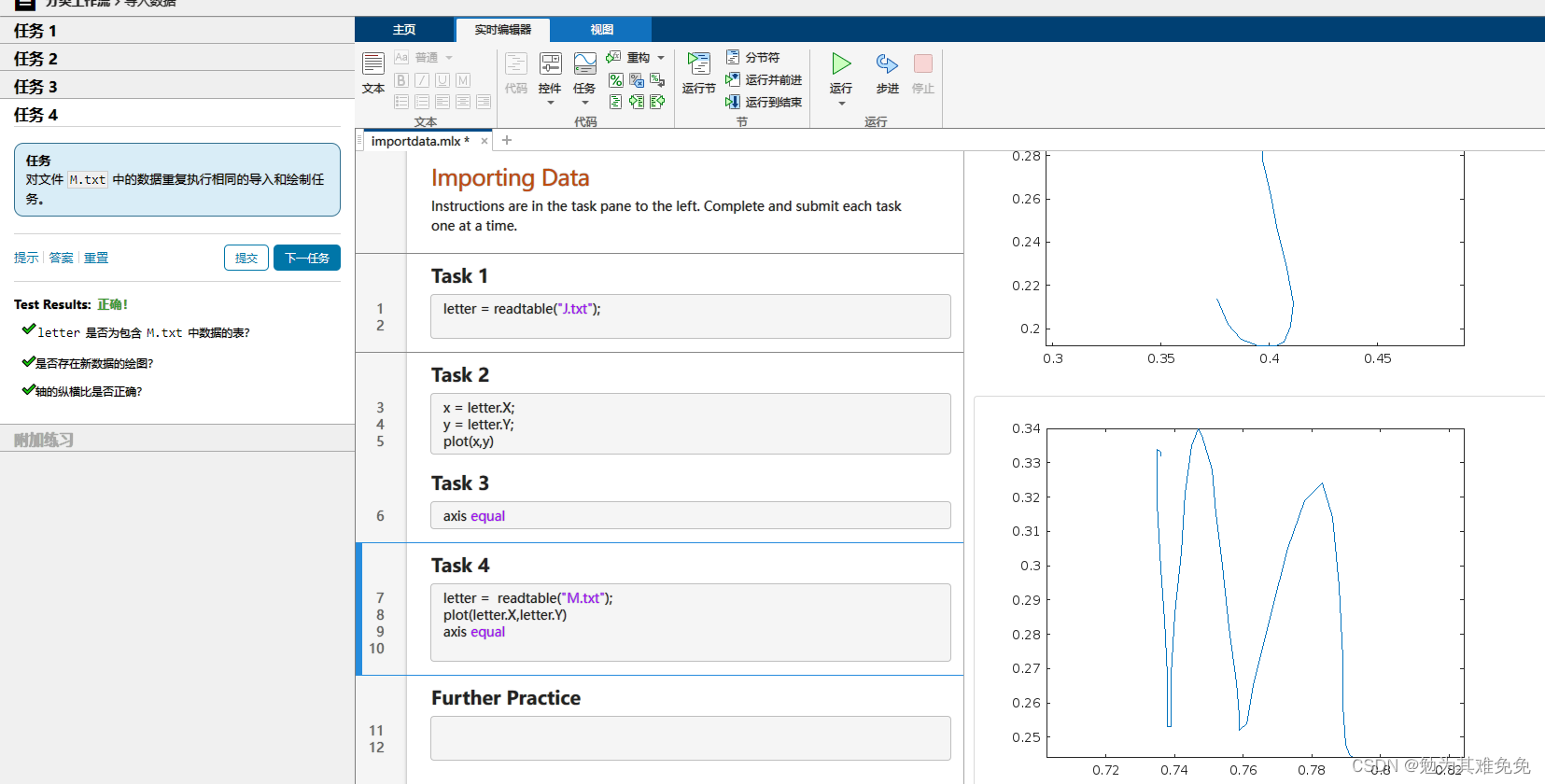

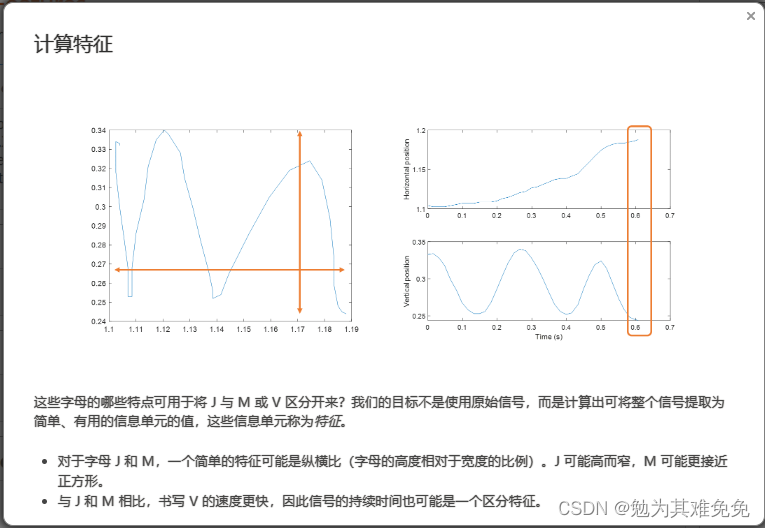
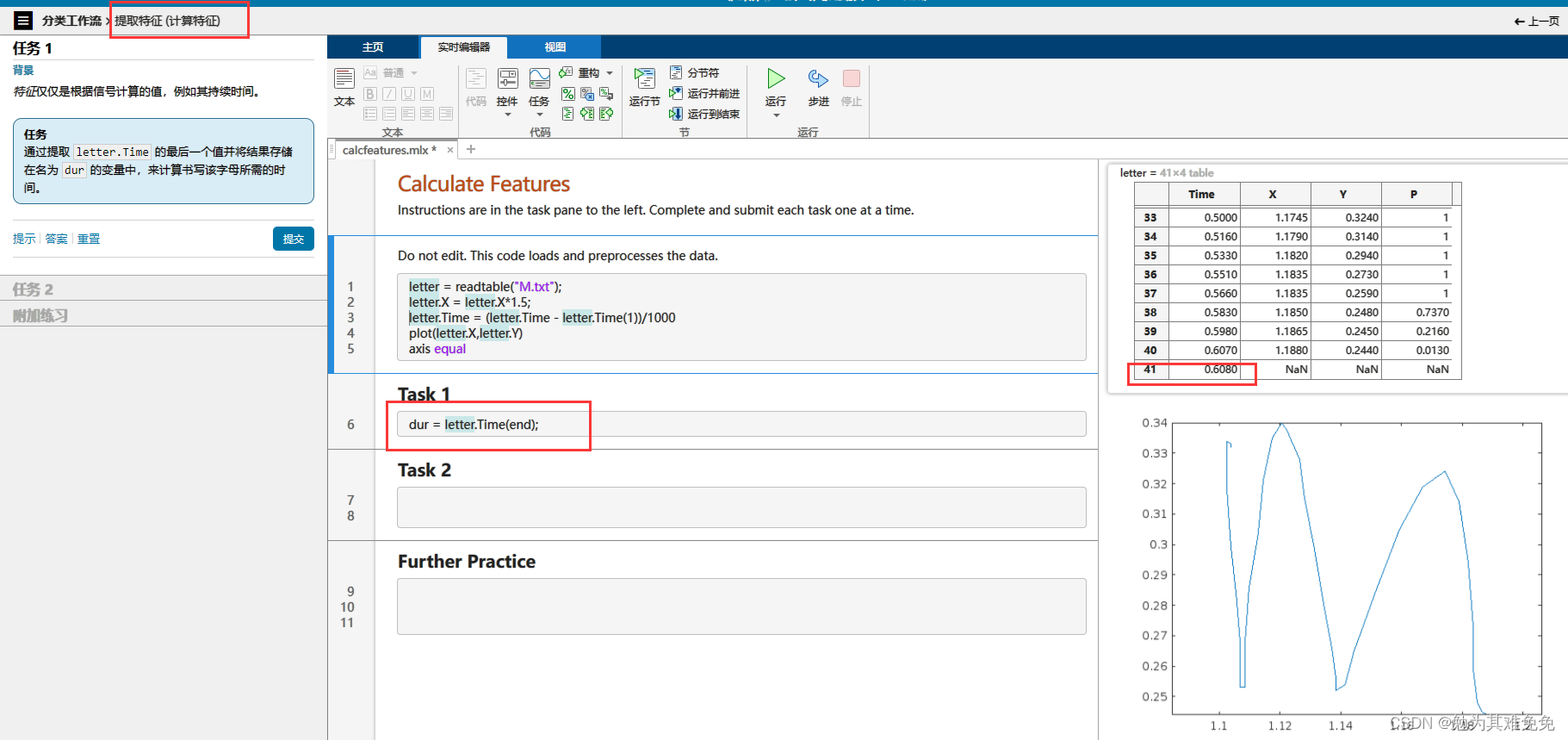
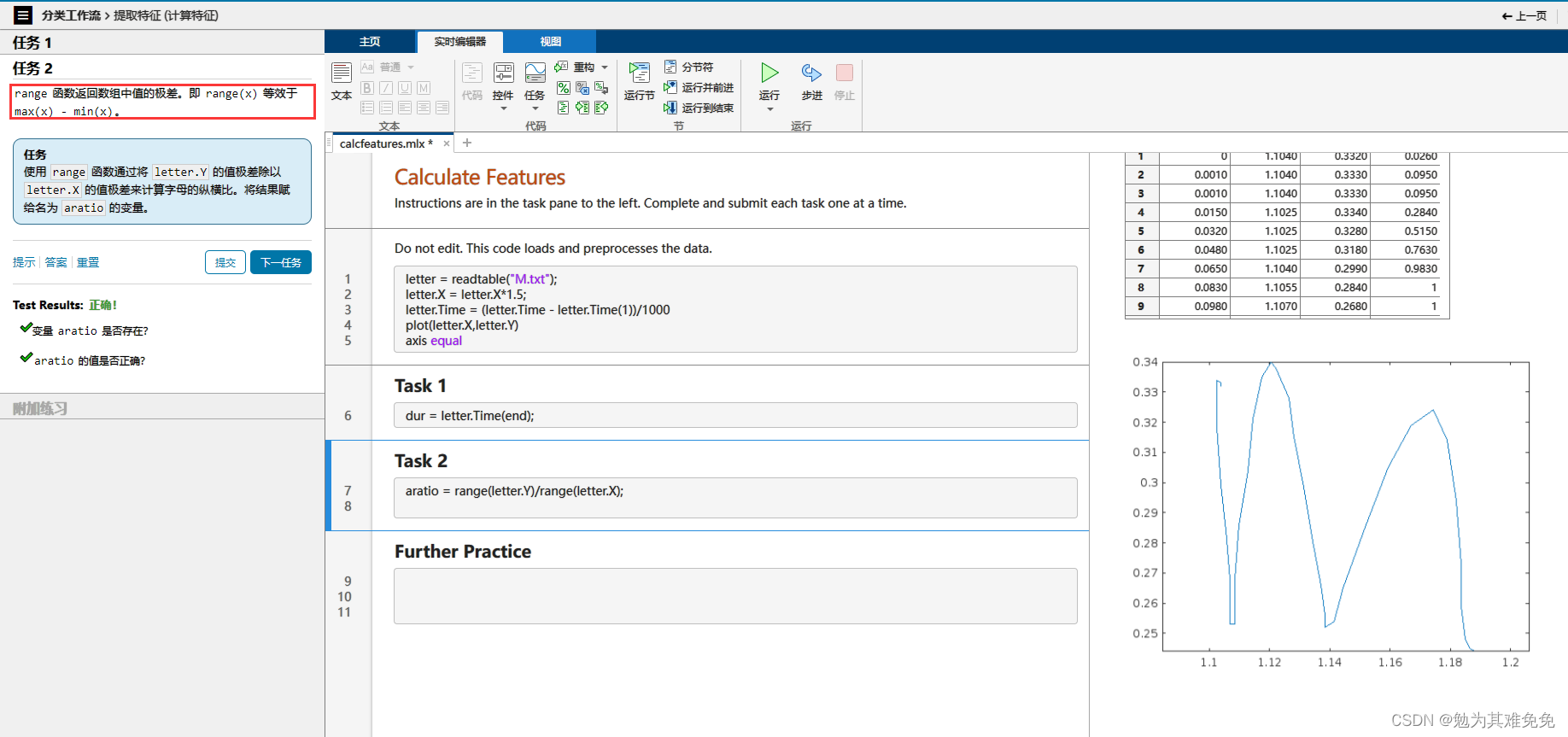
提取特征(计算特征)
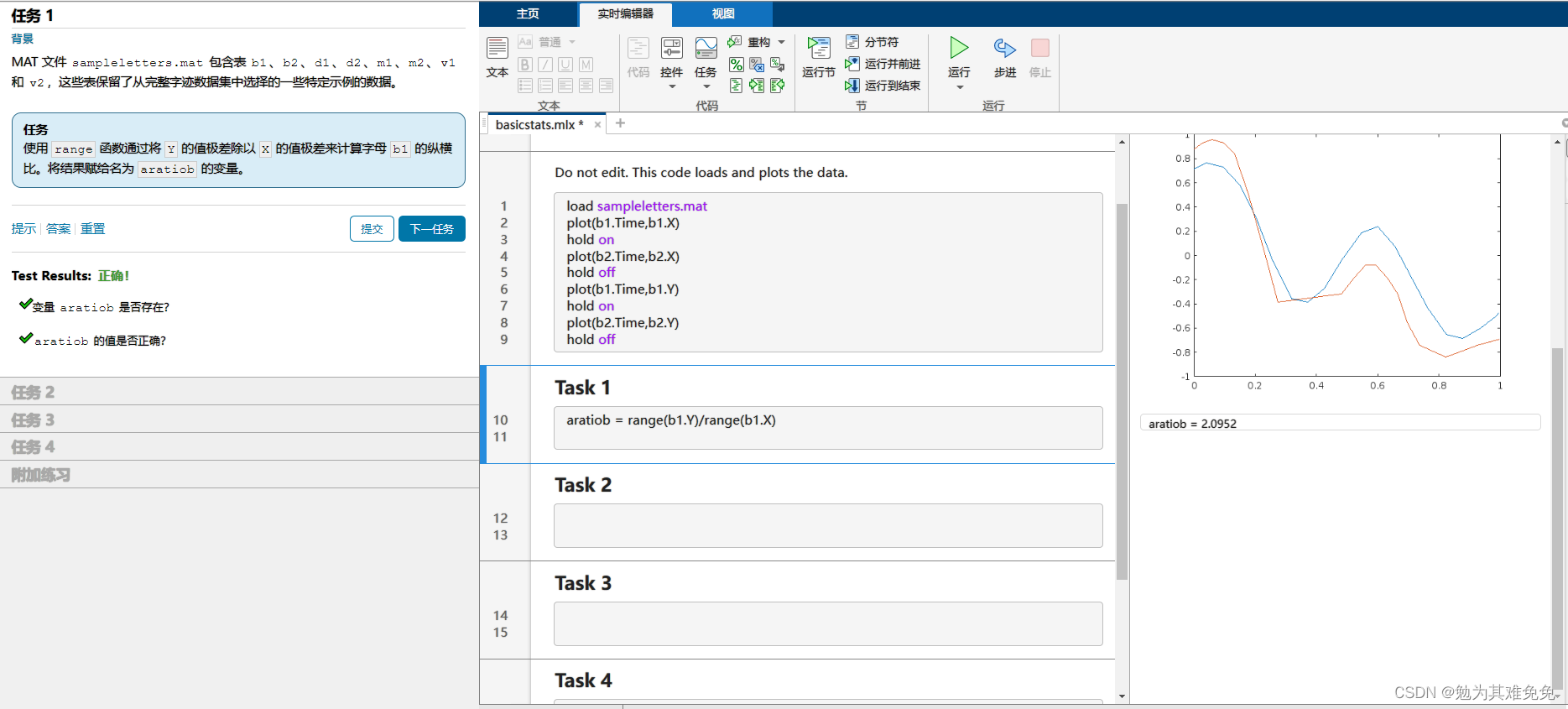
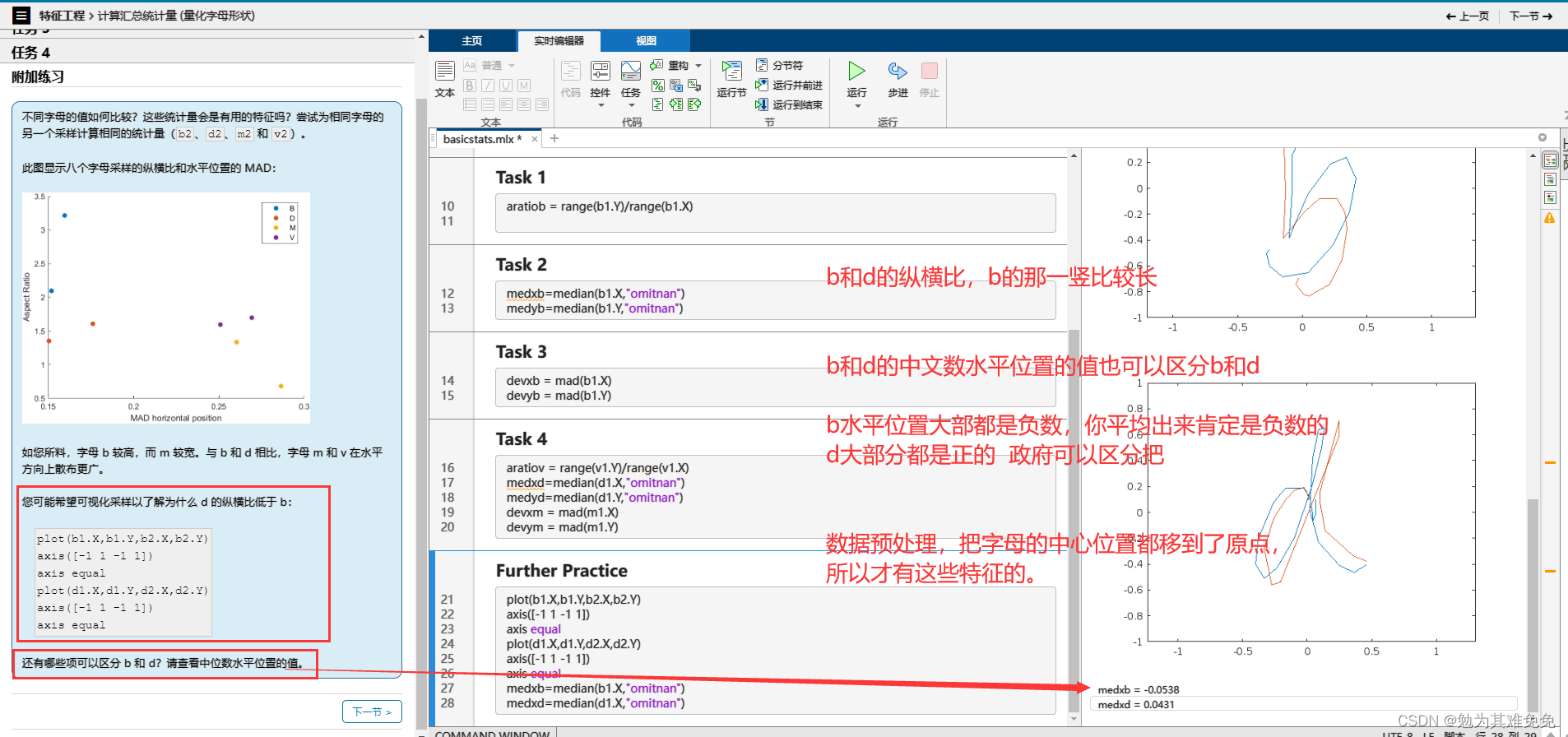
更改文件名,然后重新运行脚本,为 J.txt 和 V.txt 中的字母计算相同的两个特征。这些特征的值与您对这些字母的期望是否一致?
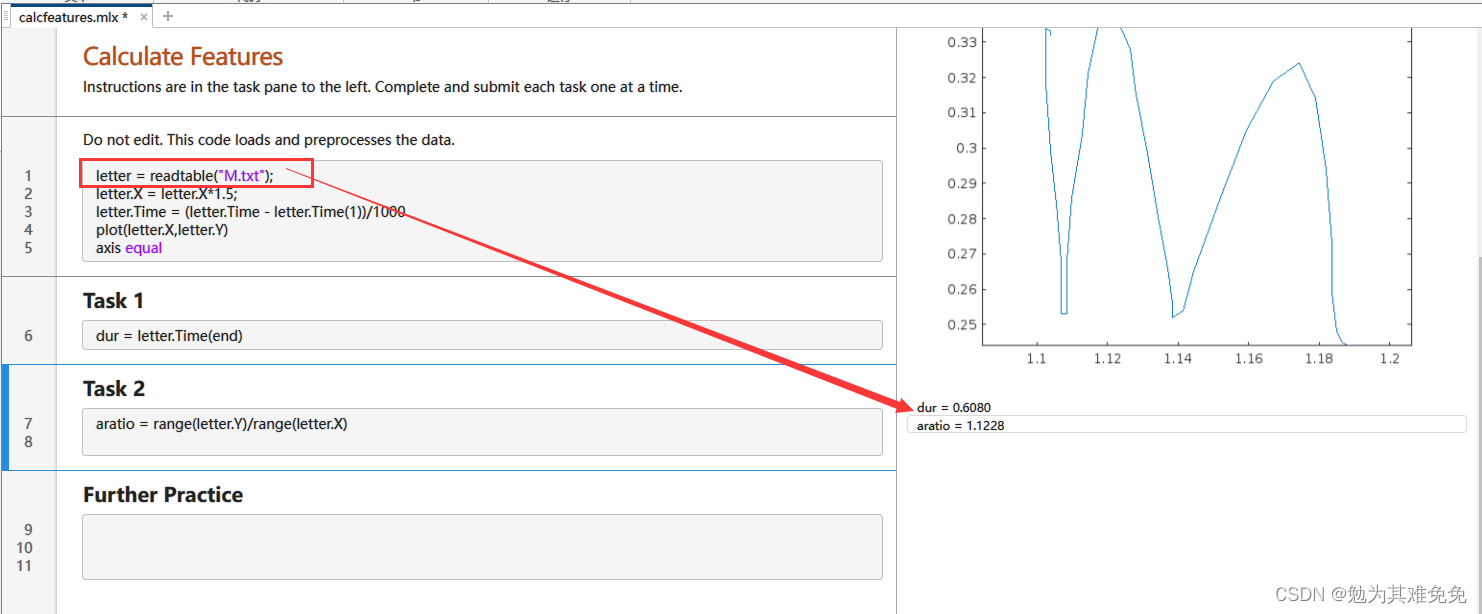
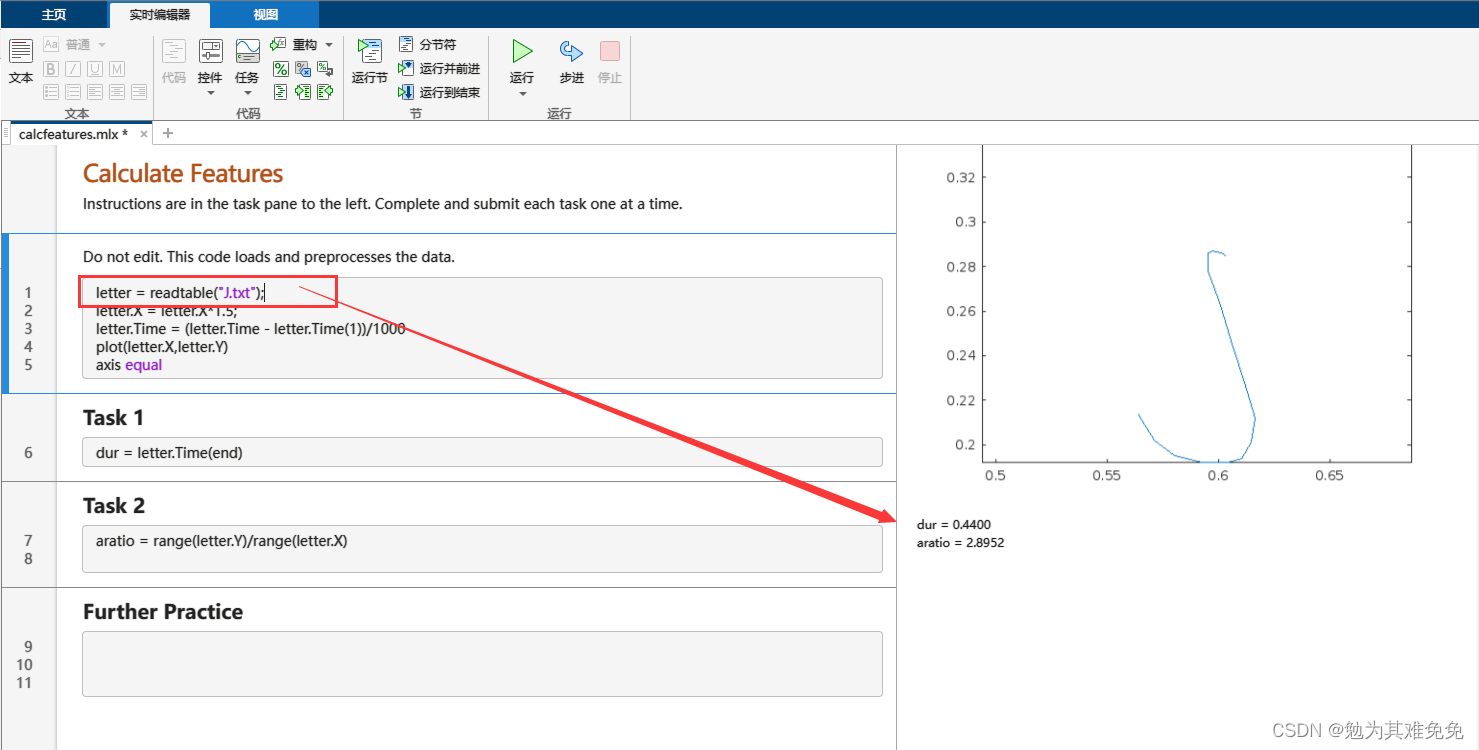
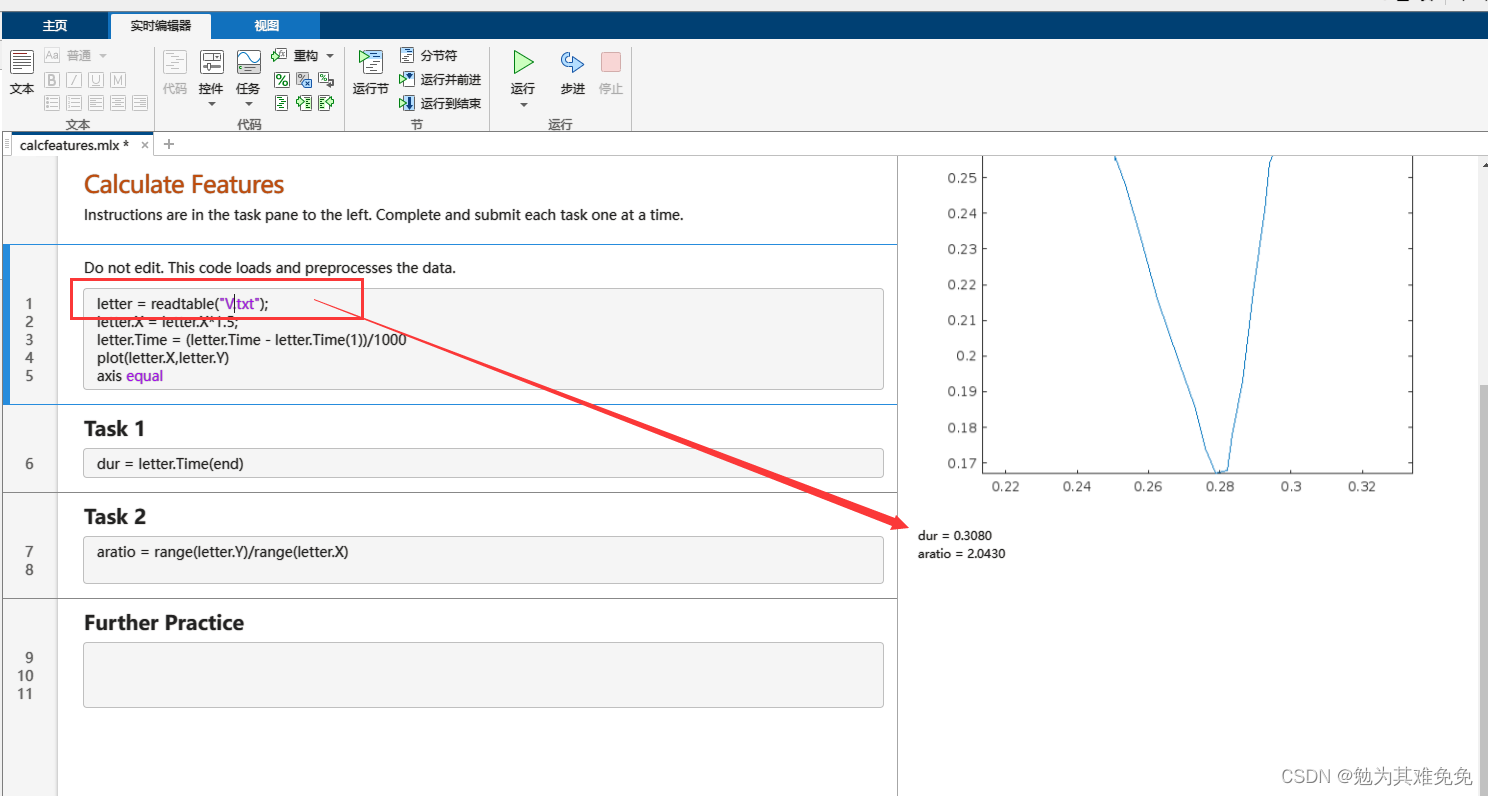
由上面三幅图可以看出,J和M的的纵横比区别较大,V和M的时间区别较大。
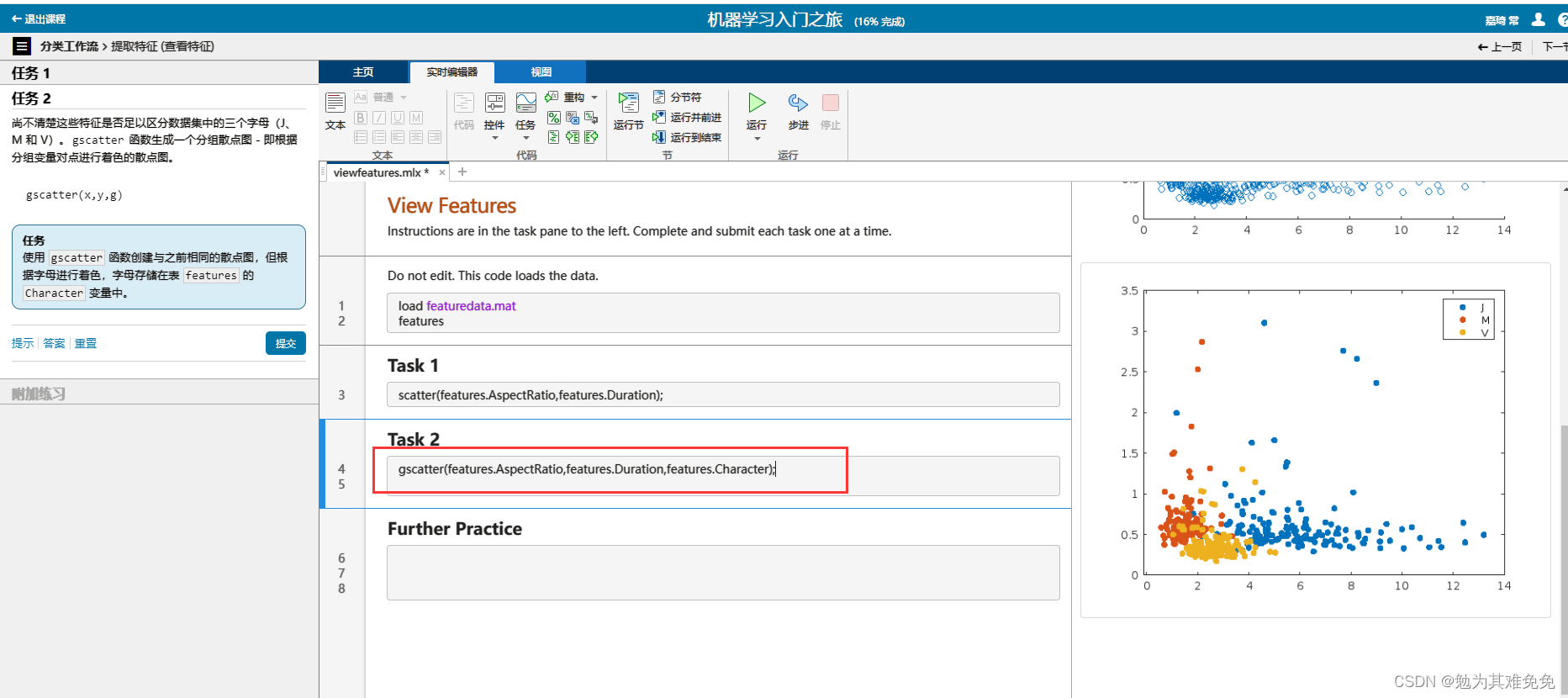
提取特征(查看特征)

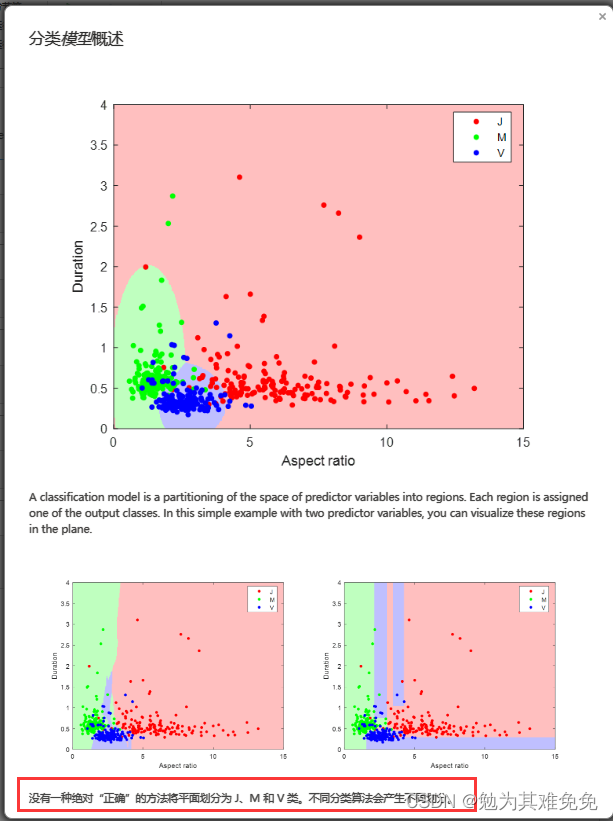
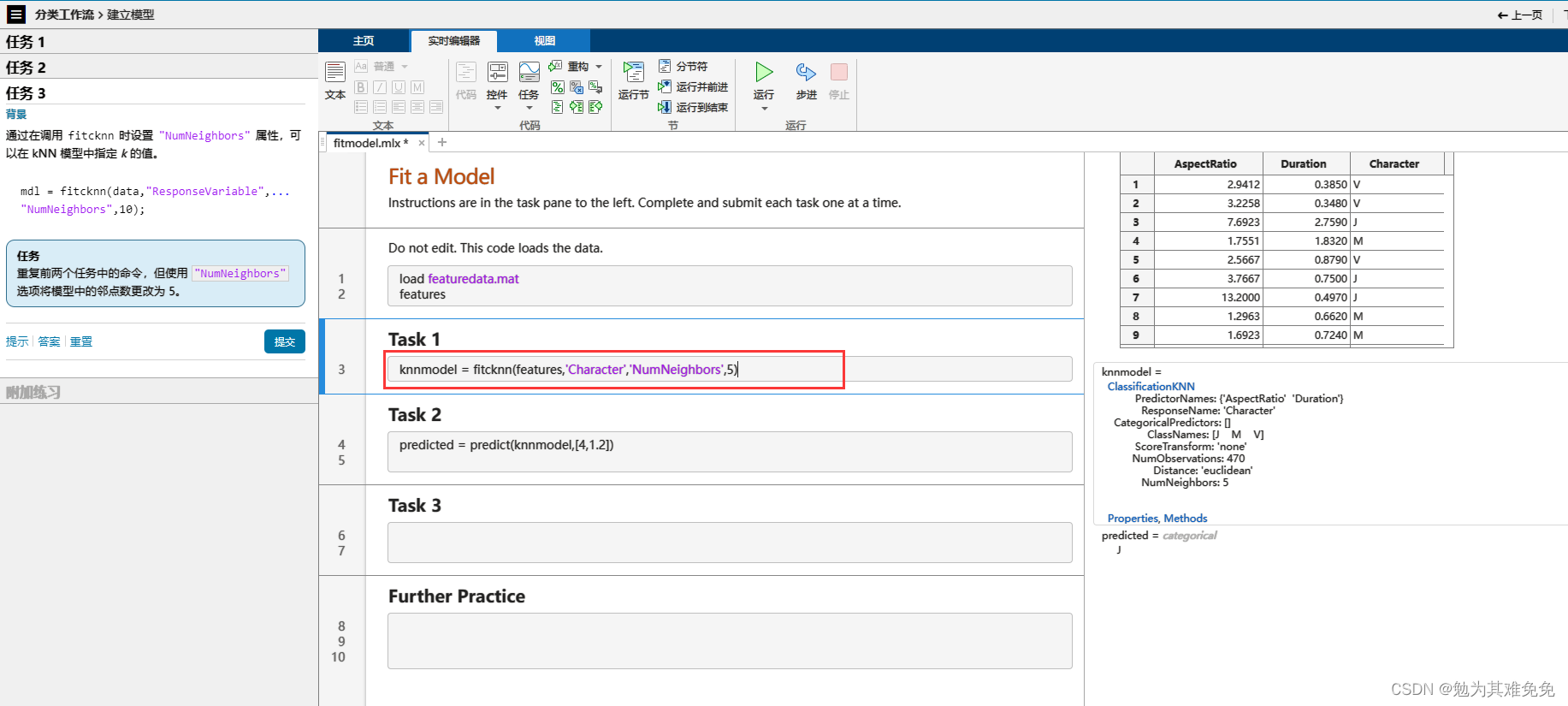
分类工作流(建立模型)

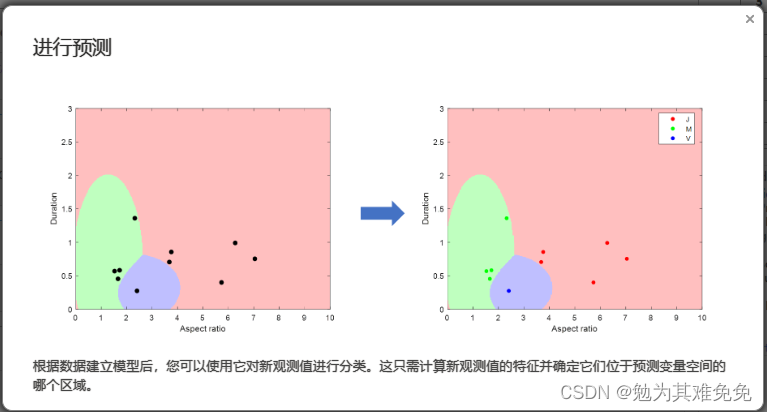

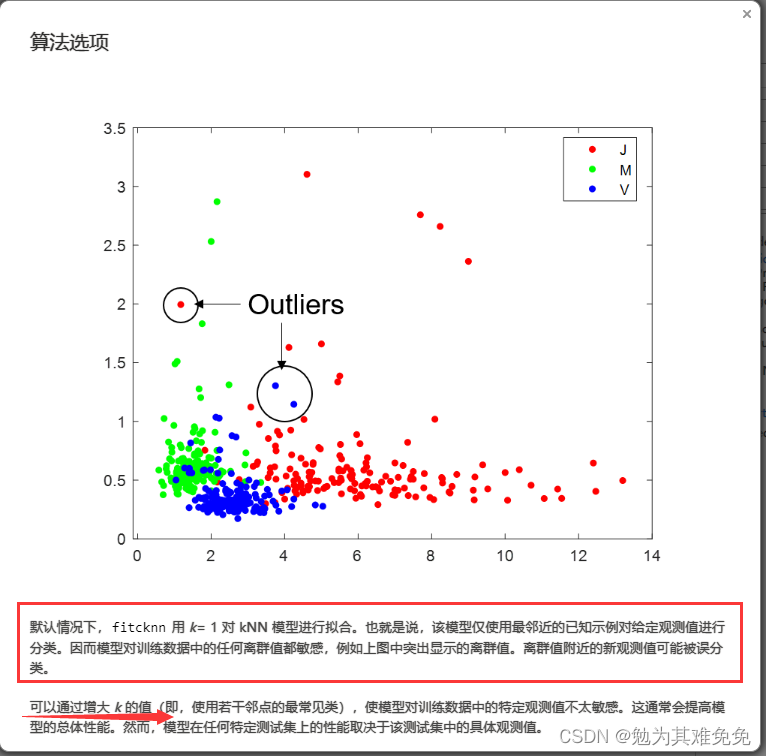
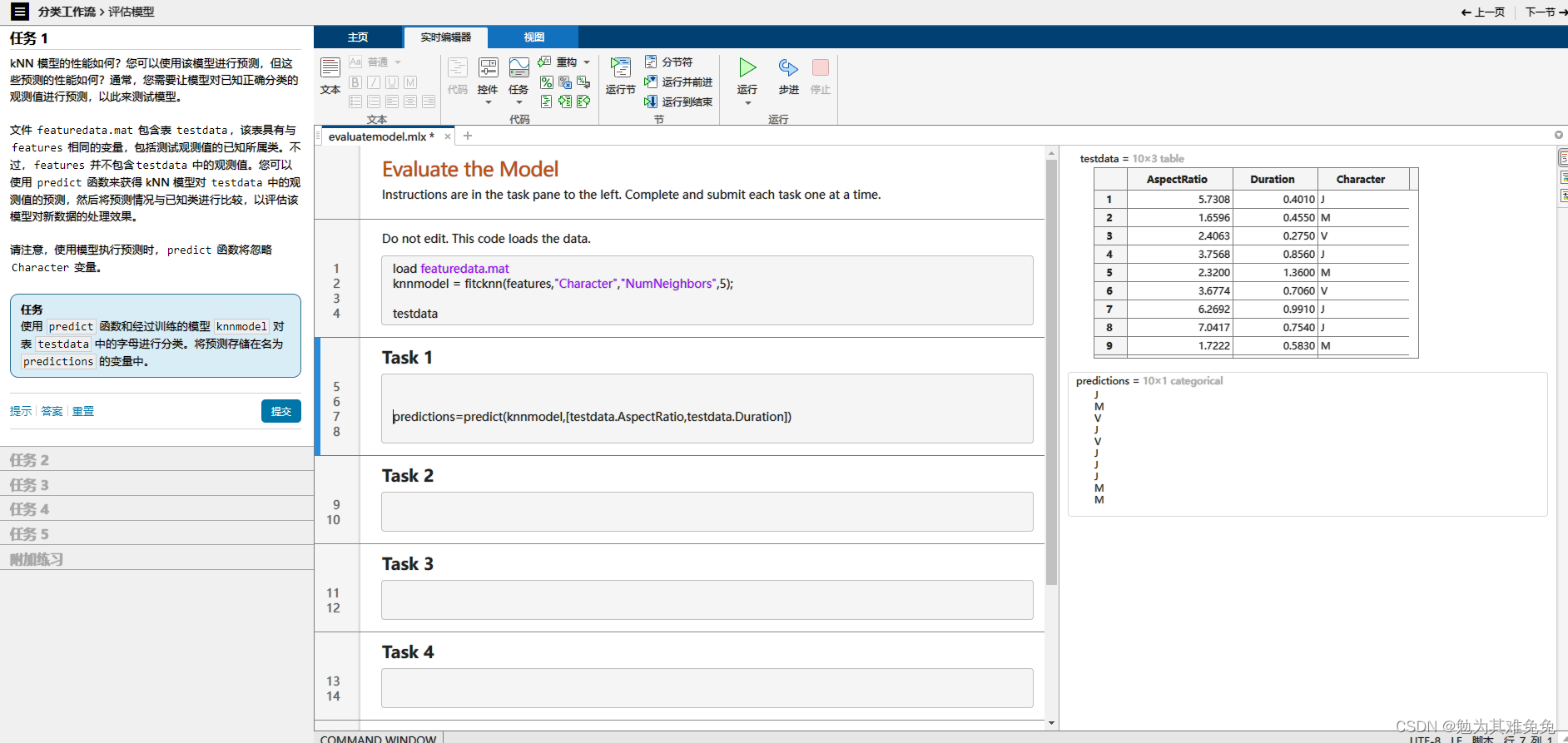
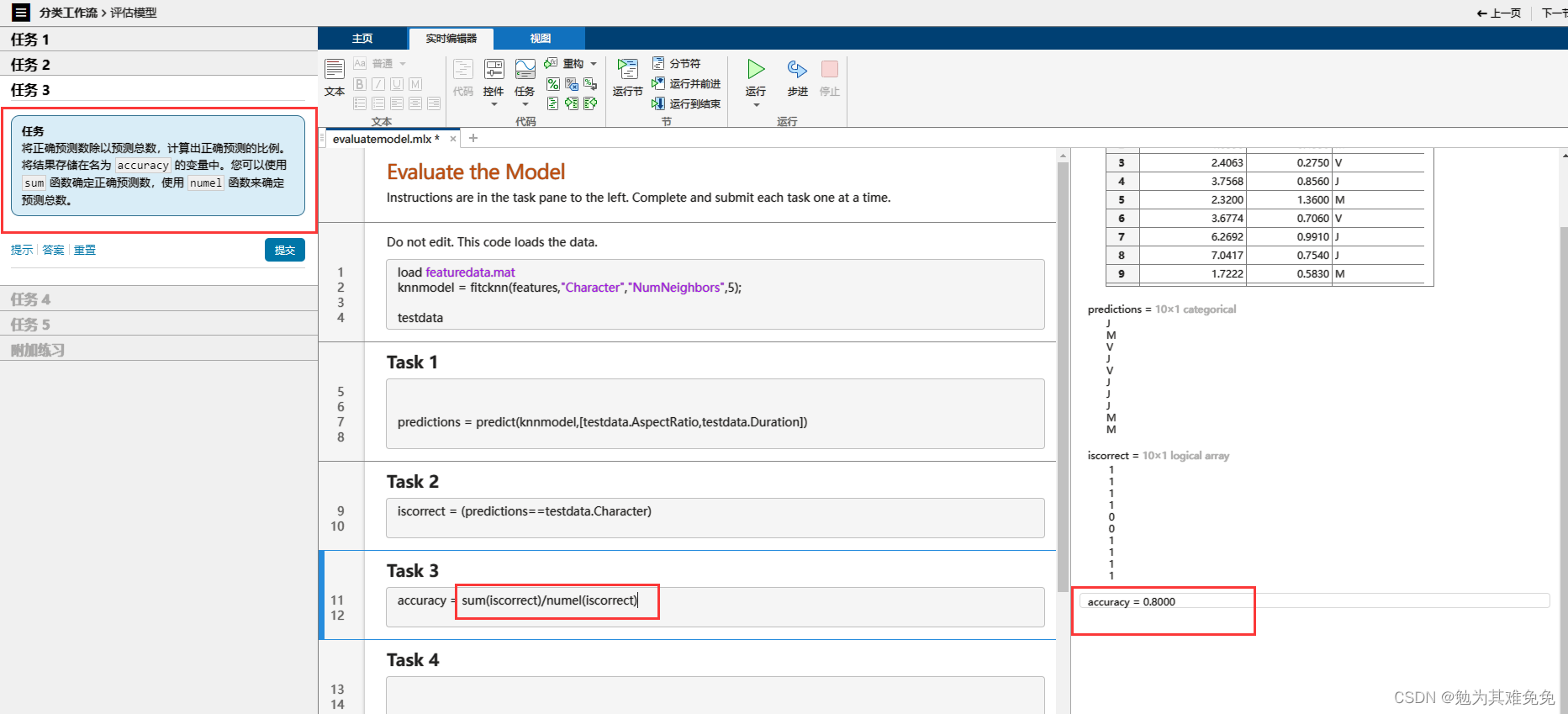
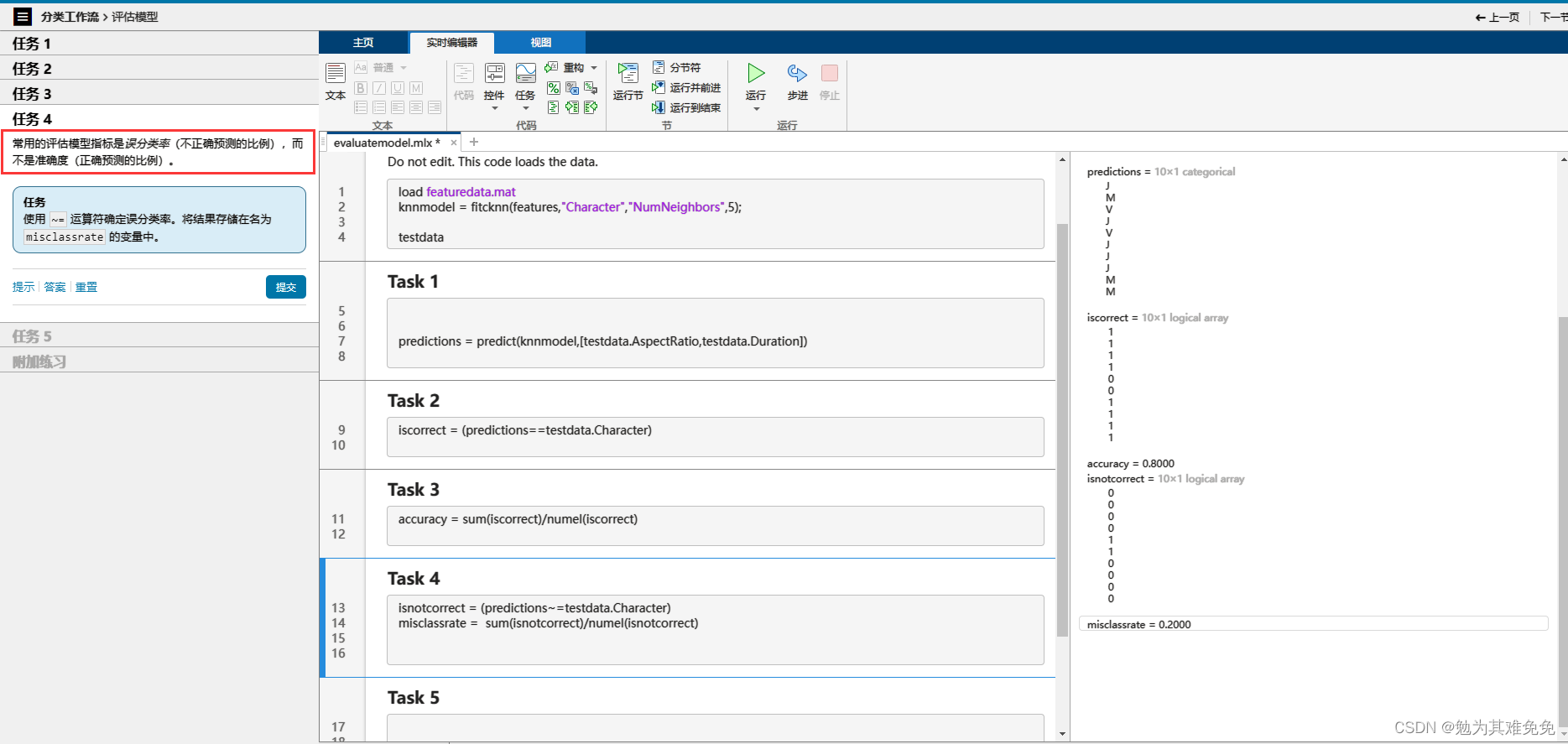
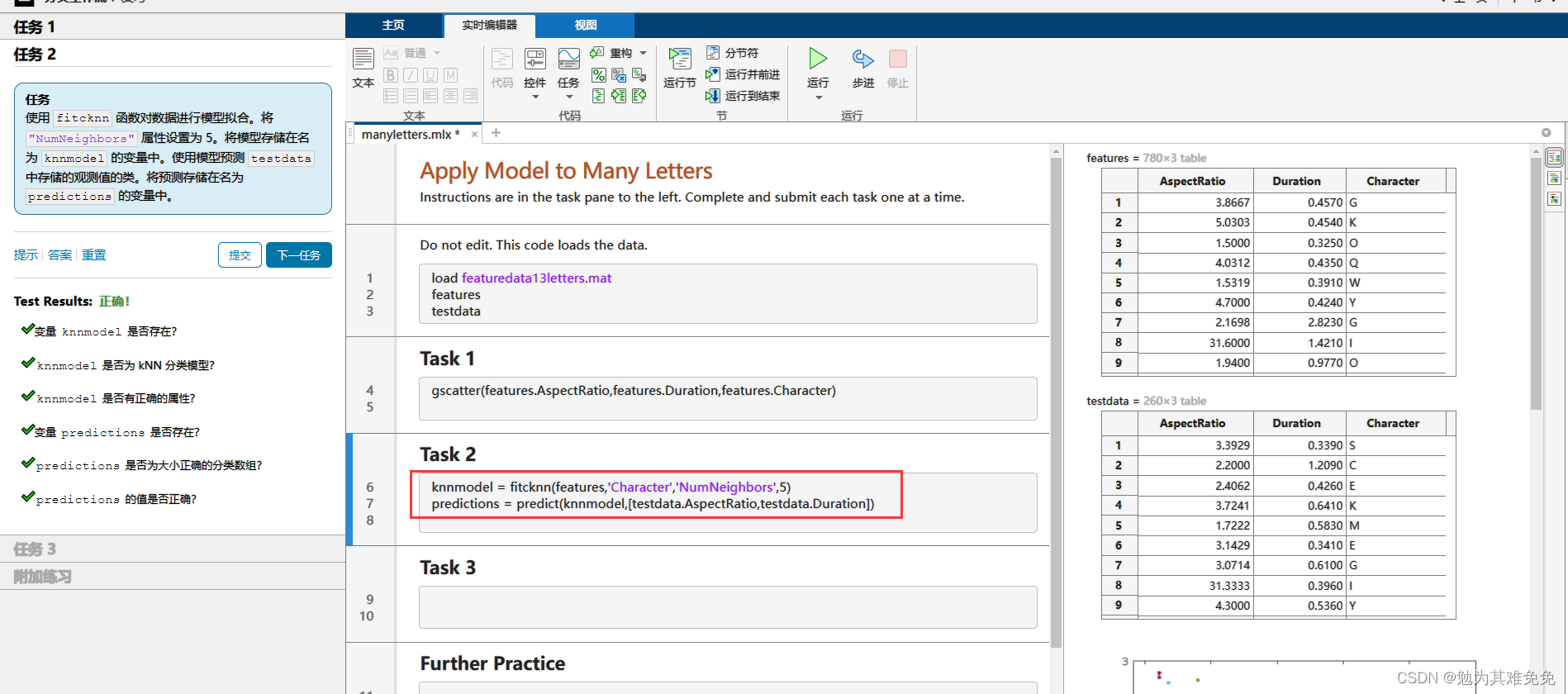
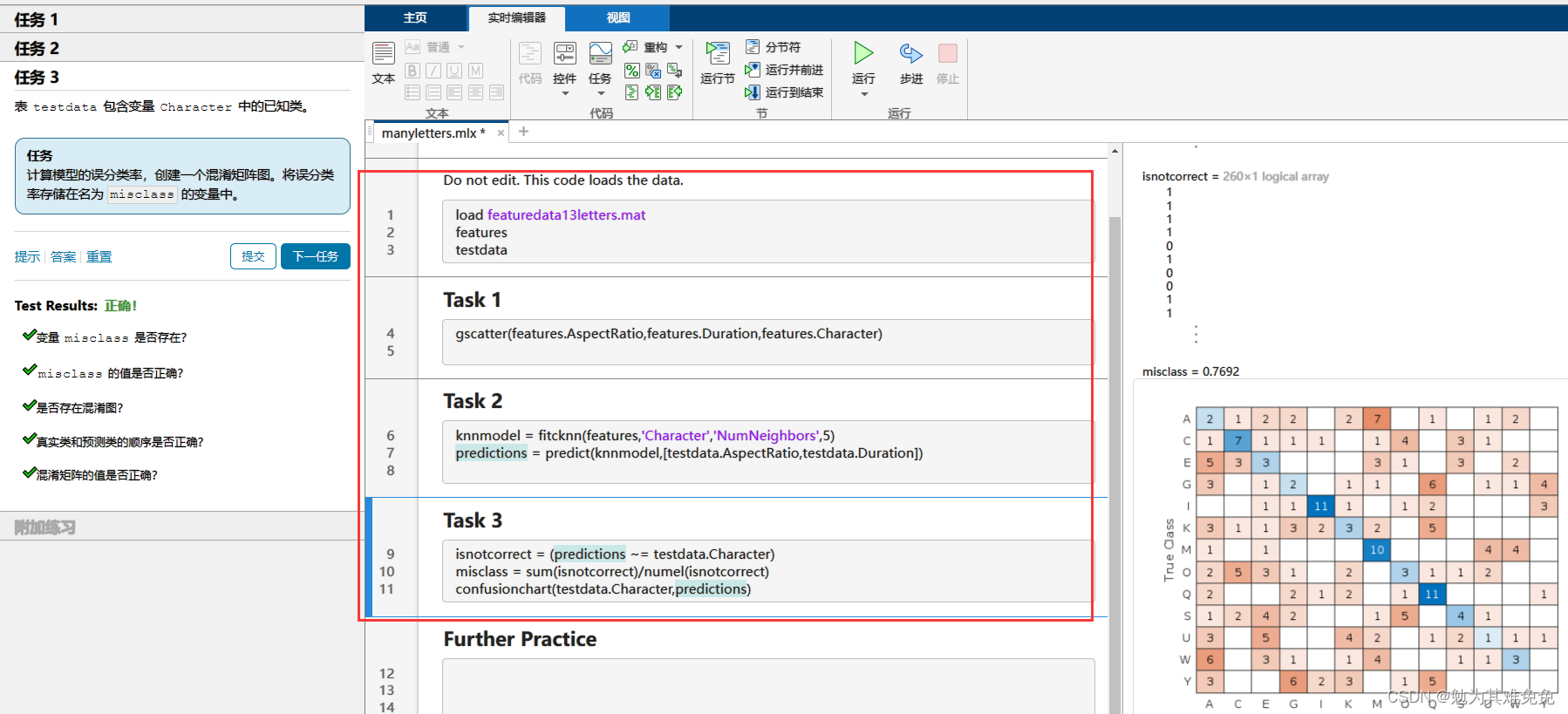
提取特征(评估模型)
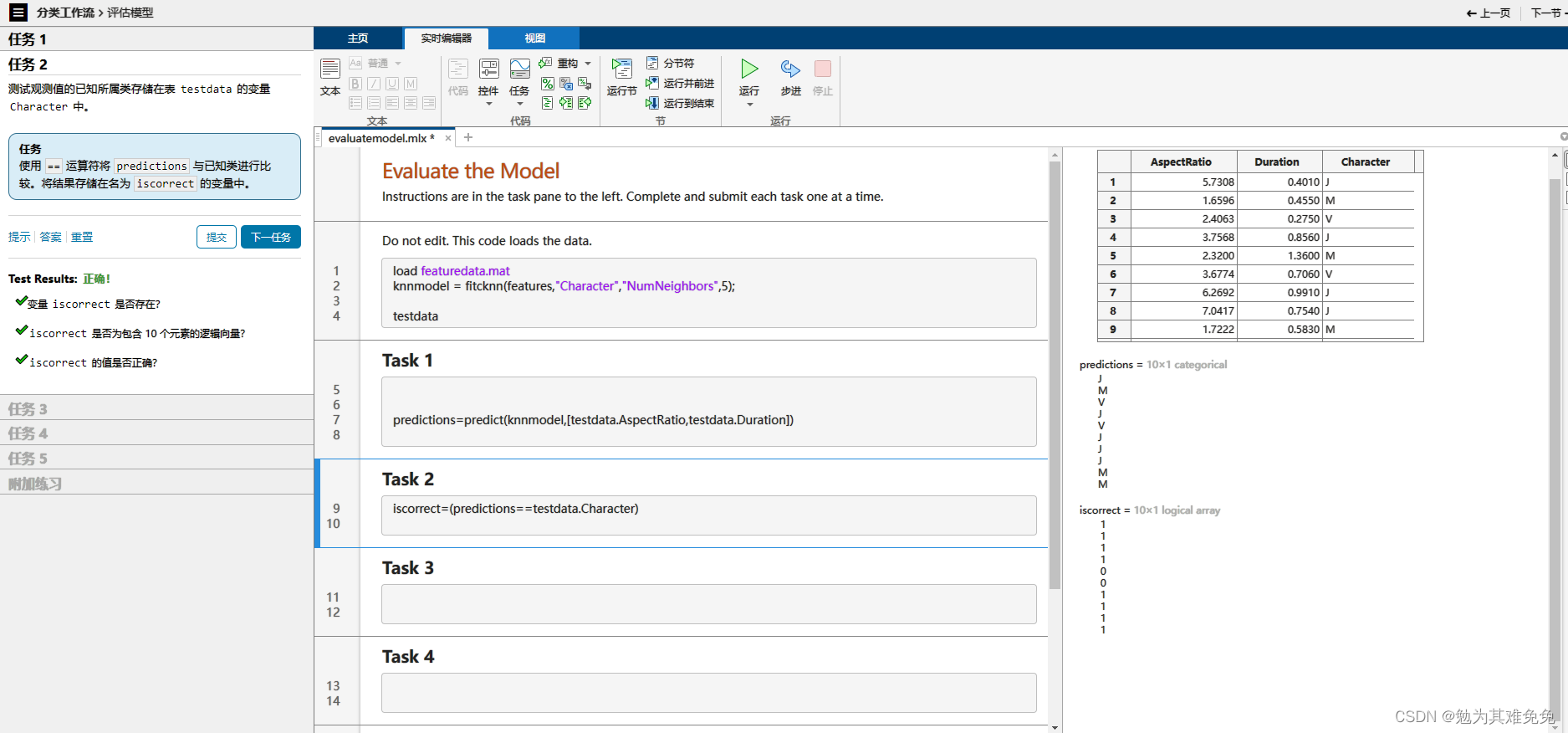
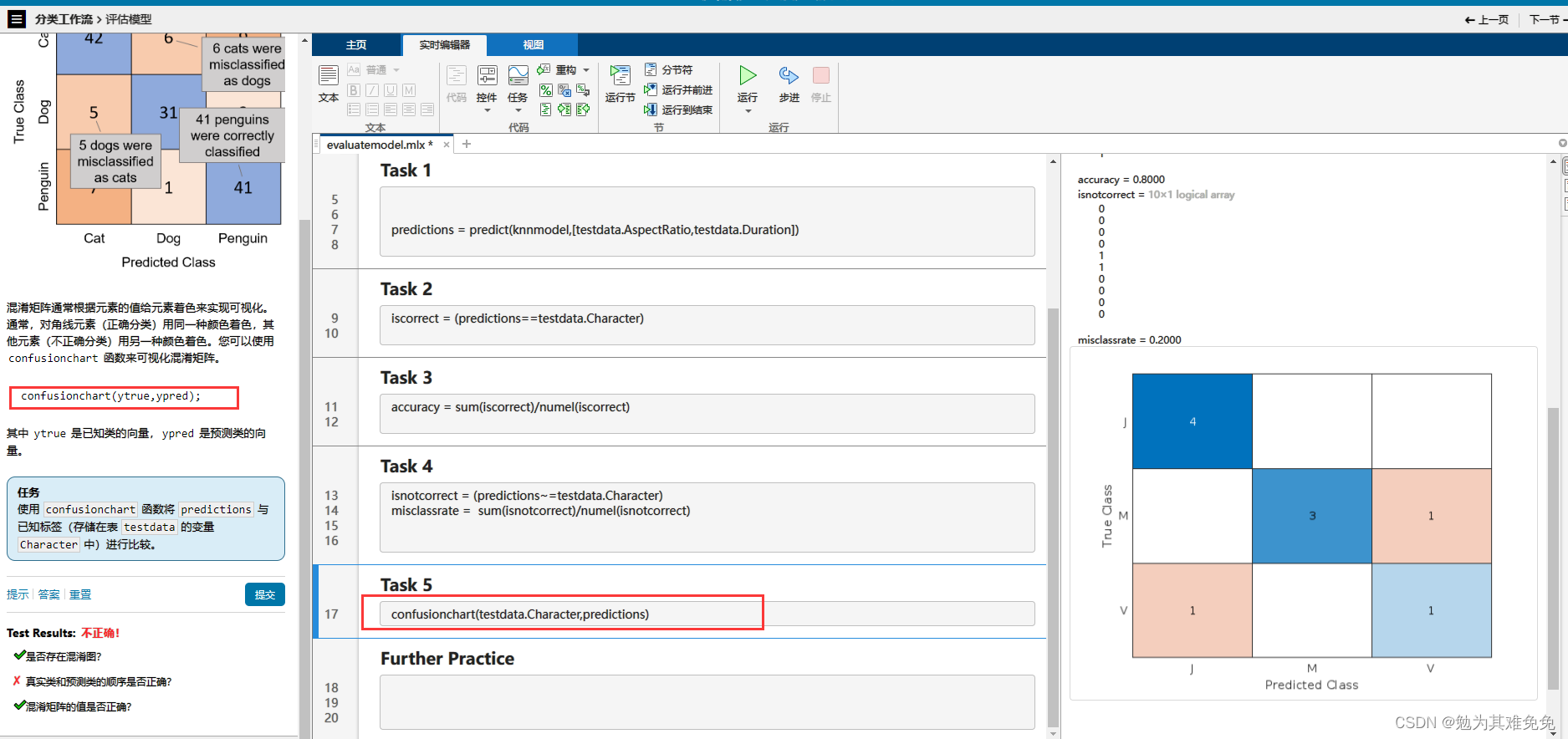
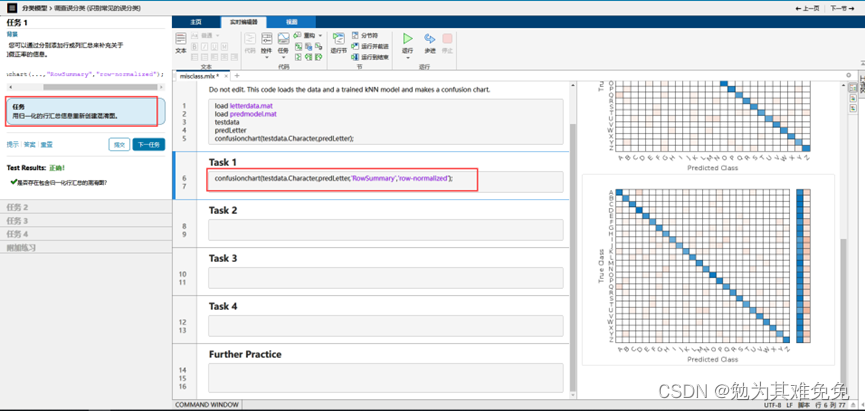
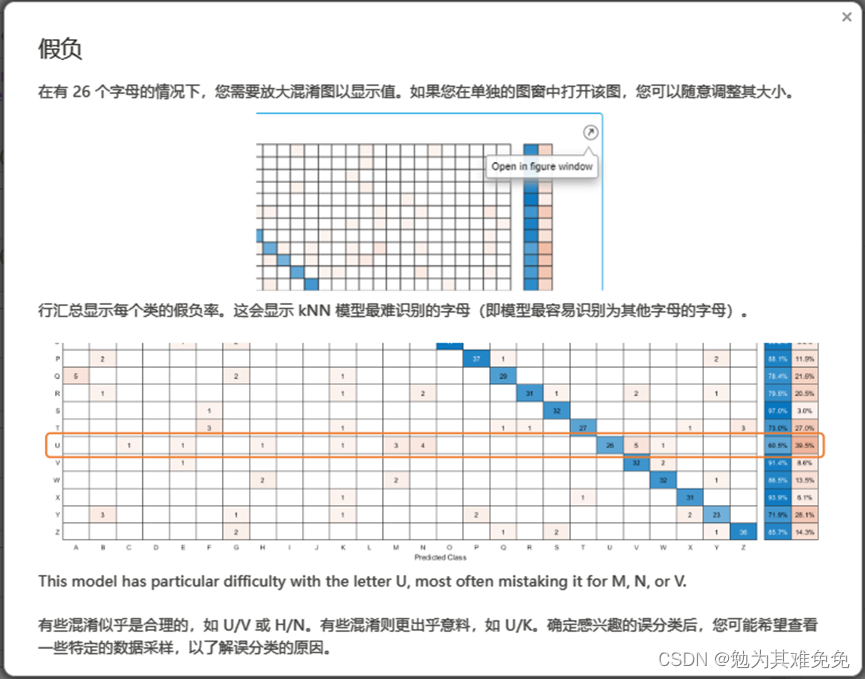
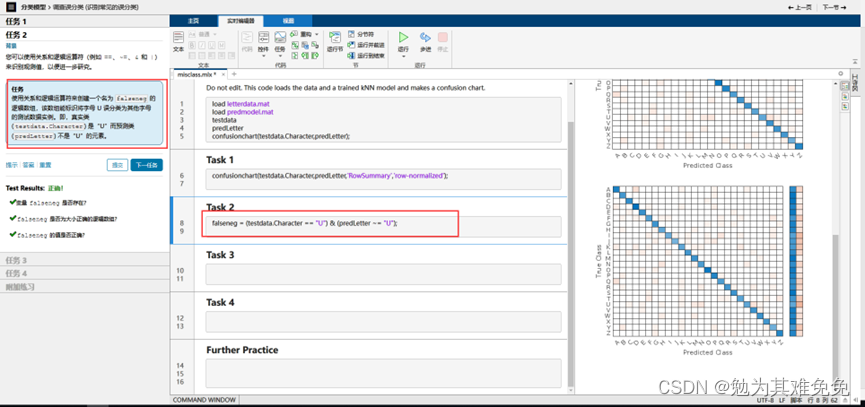
混淆矩阵,一个M被误认为V,一个V被误认为J
复习

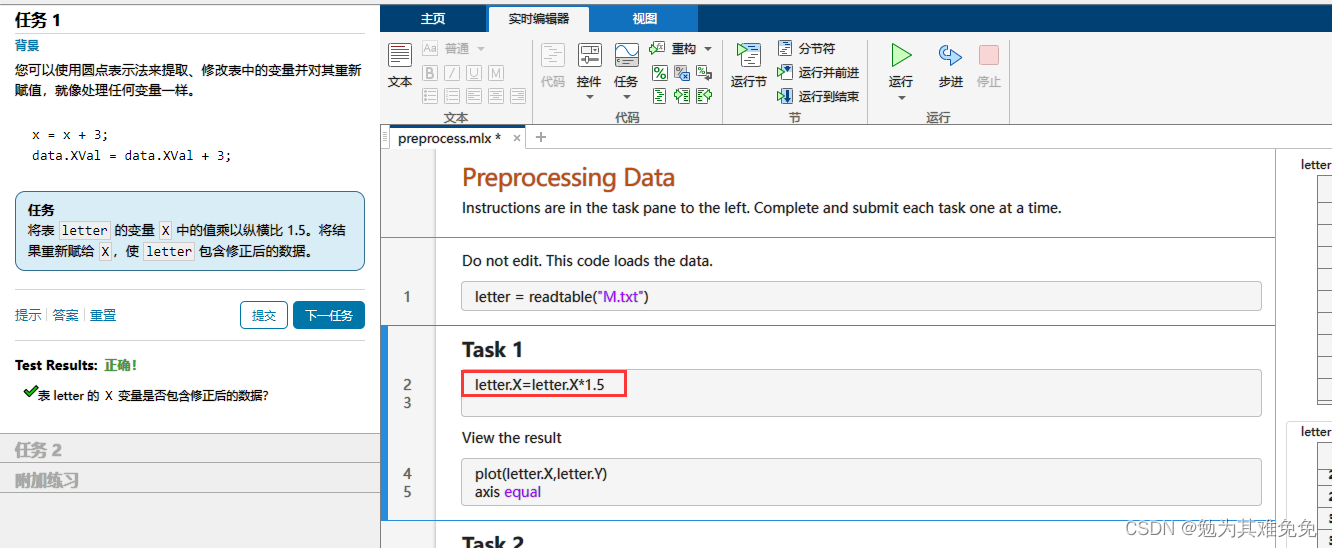
导入和预处理数据
导入和预处理数据(数据文件的组织)
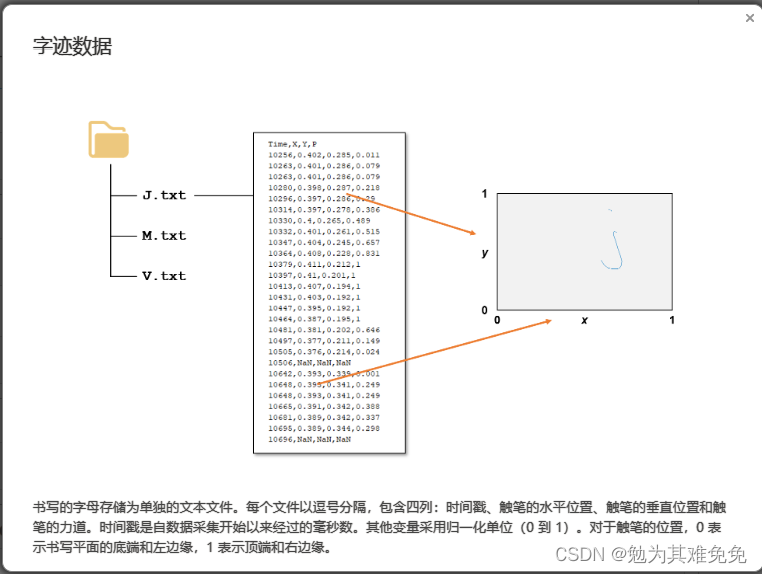
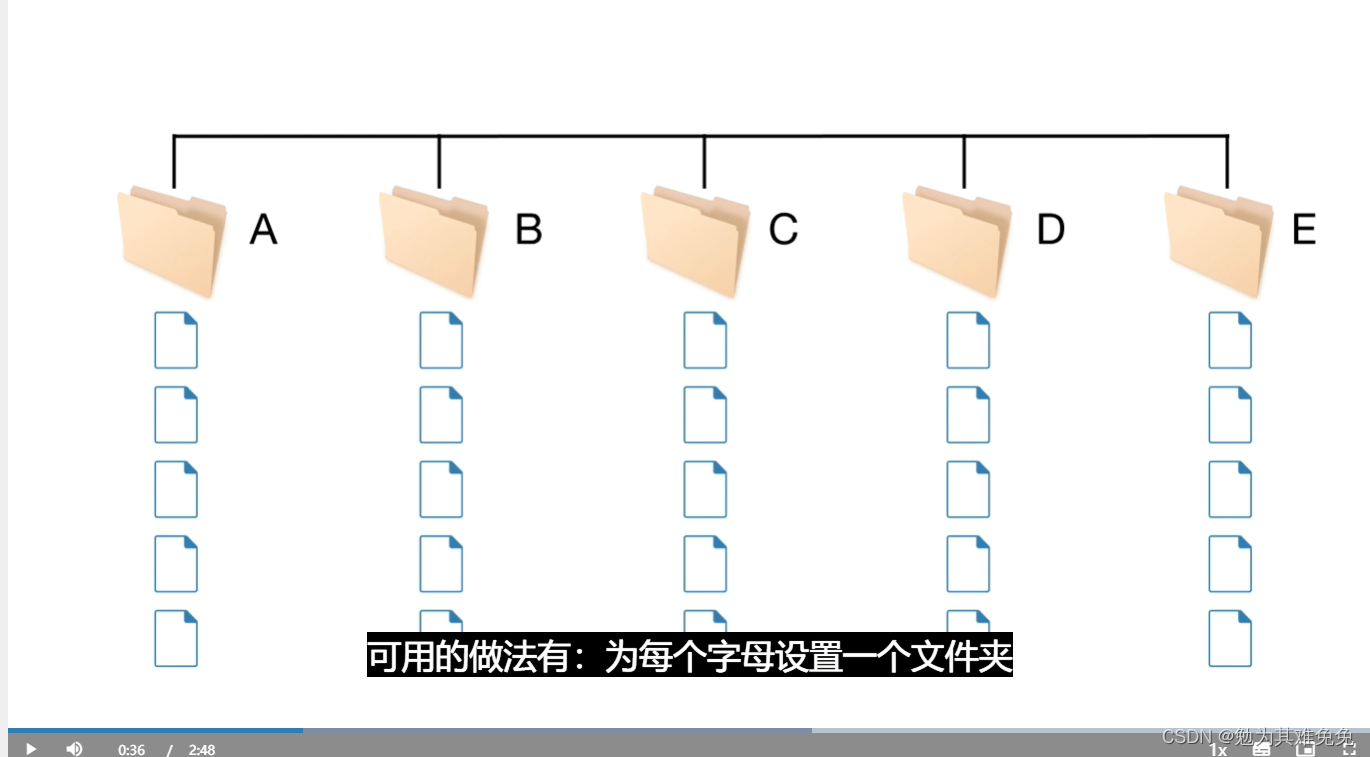
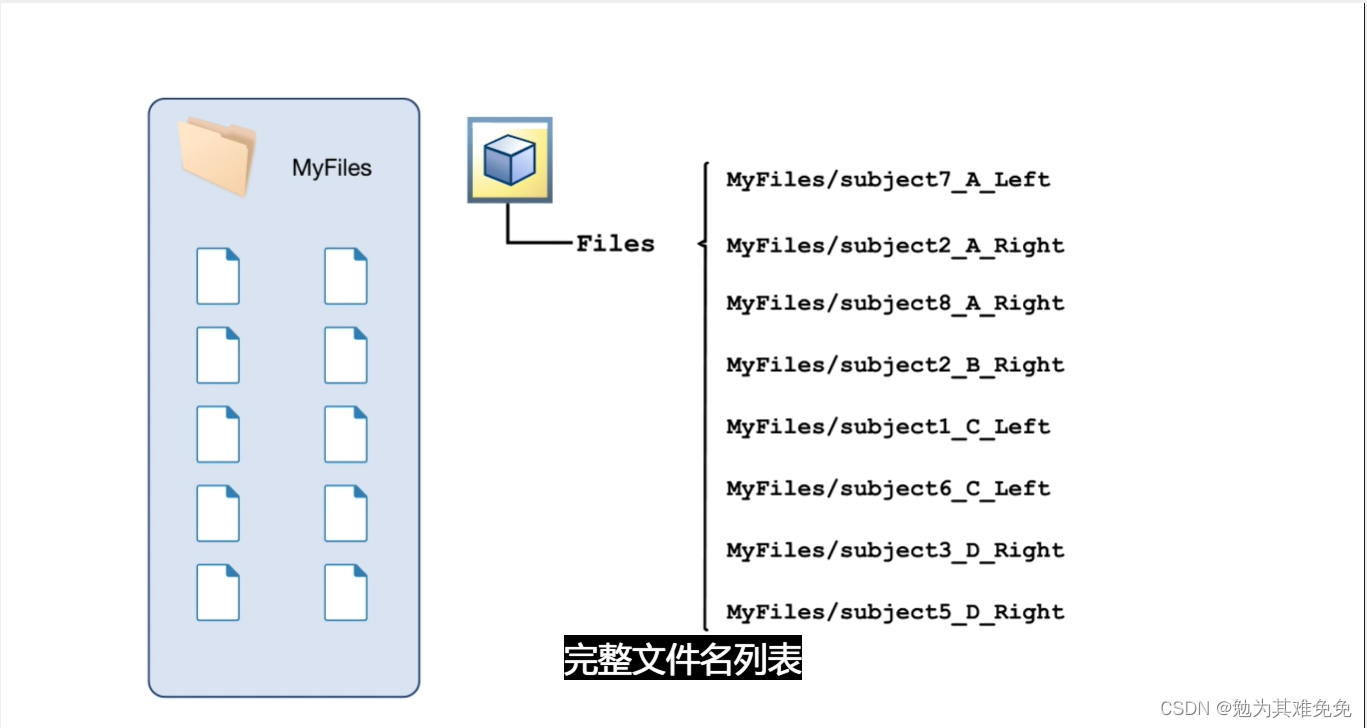
要进行机器学习,你需要数据,要让模型对26个单独字符进行分类,你需要每个字母的多个示例,这就要求成百上千的单独观测值,这些观测值如何存储?一般不会将所有数据放在一个大文件中,对于字迹示例,每个字母的单个示例,都存储再一个单独文件中,如何组织这几百个文件?

你如何区分这几百个文件?你如何知道每个文件中表示的是哪个字母?
可用的做法有:为每个字母设置一个文件夹,或在一个文件中包含所有文件,在文件名中包含所标示的字母,或用一个单独的文件,在其中包含一个查找表,通过查找表定位到文件及其所含字母
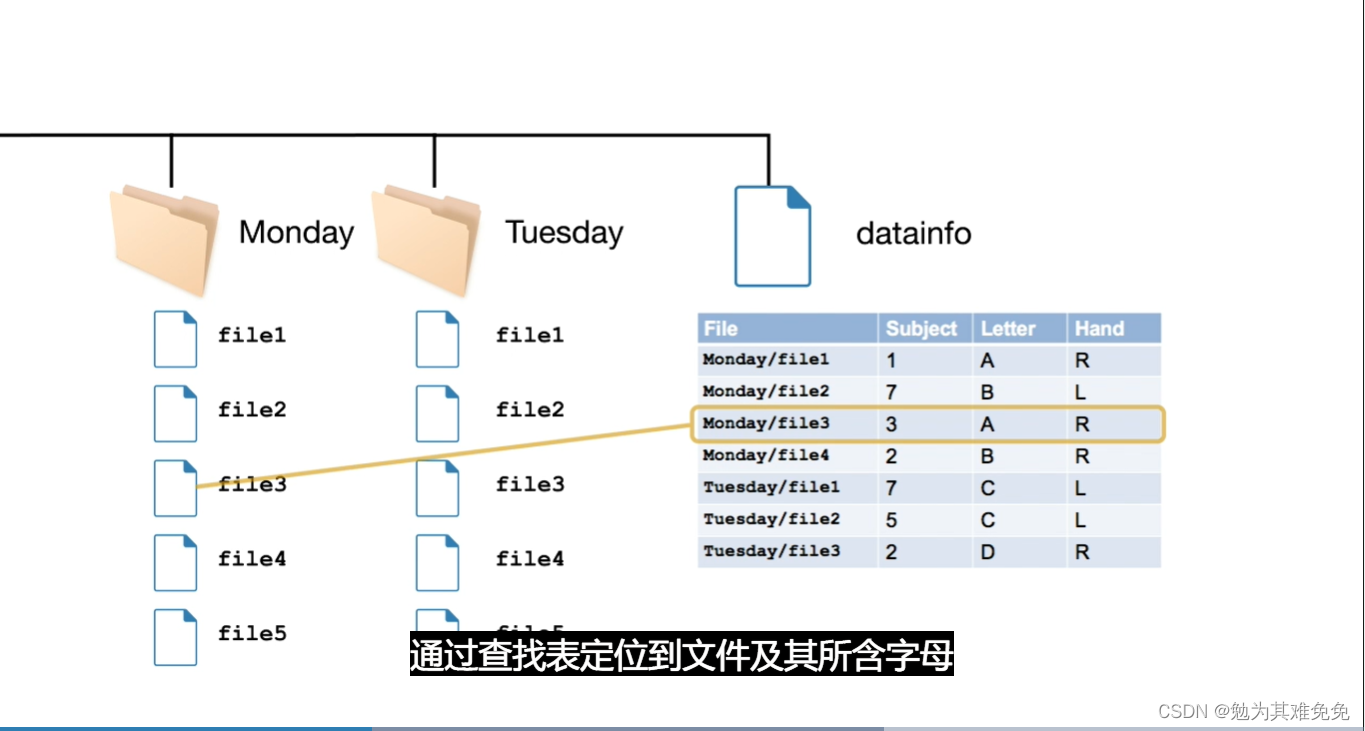
如果你正在处理一个已有数据集,将只能根据数据当前的存储方式对其进行处理,但是如果有可能,最好在采集数据之前考虑一下文件的组织方式,使得数据安排最为合理便捷。
最佳的组织方式取决于你所研究的具体问题,如果要对字母分类,你可以给每个字母设置一个文件夹,
但是如果你要做对比研究,左手书写和右手书写,则可能需要不同的组织方式。

不管你的文件如何组织,数据存储都支持便捷地访问存储在多个文件中的数据。
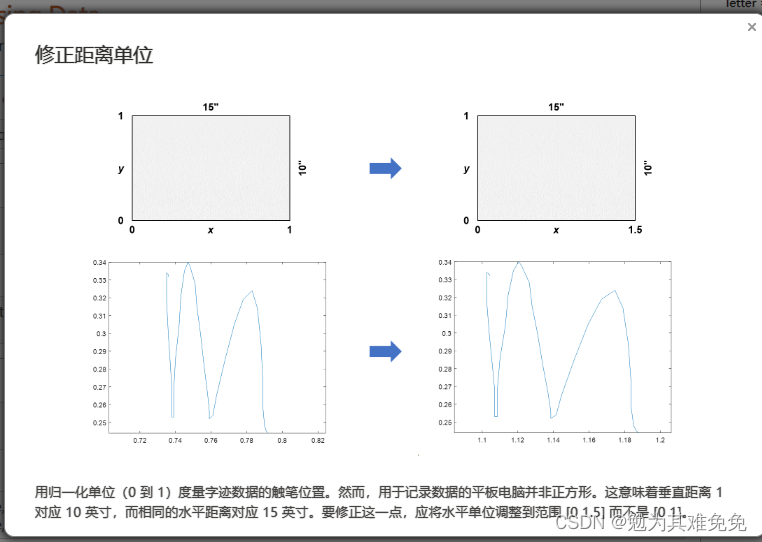
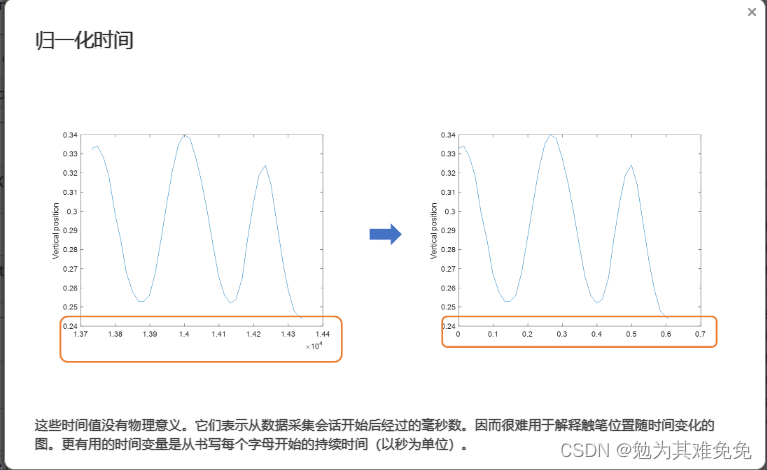
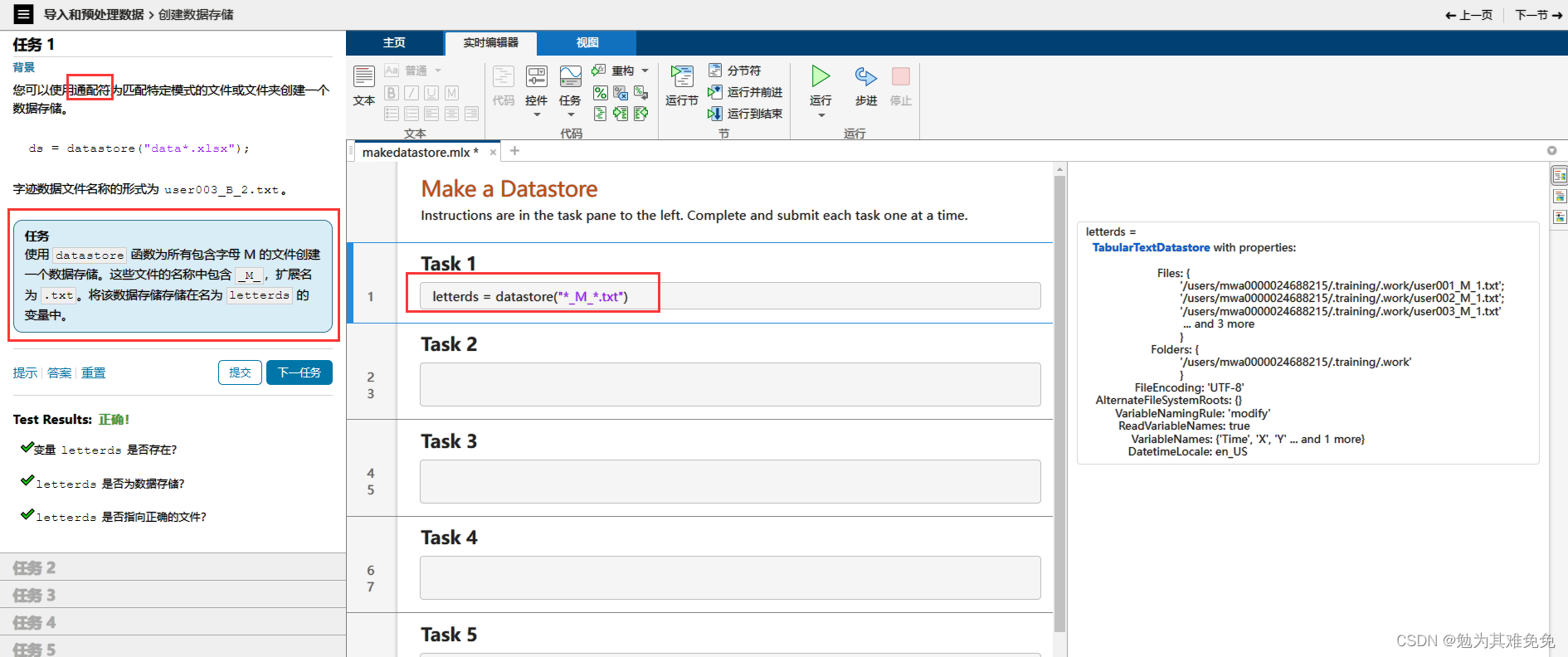
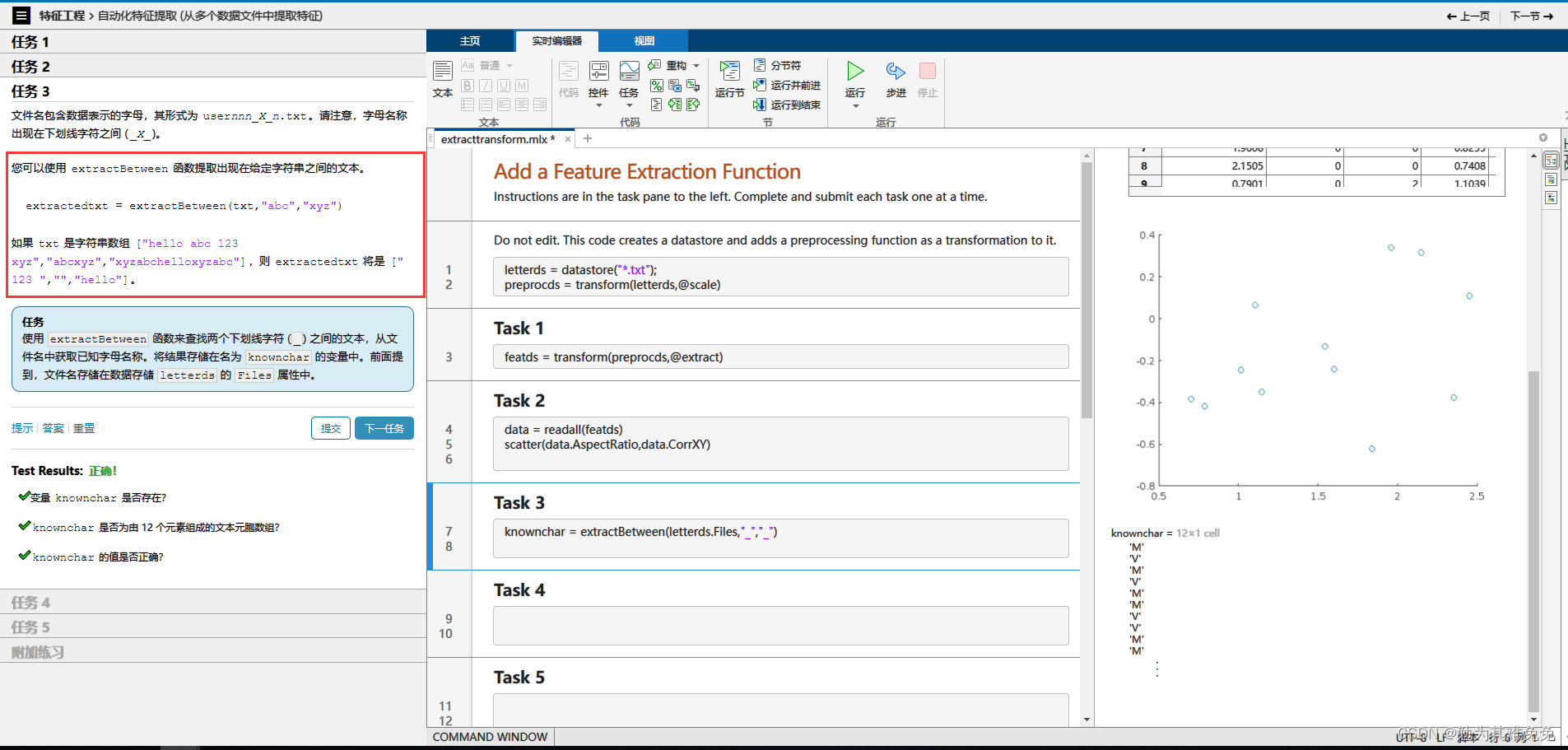
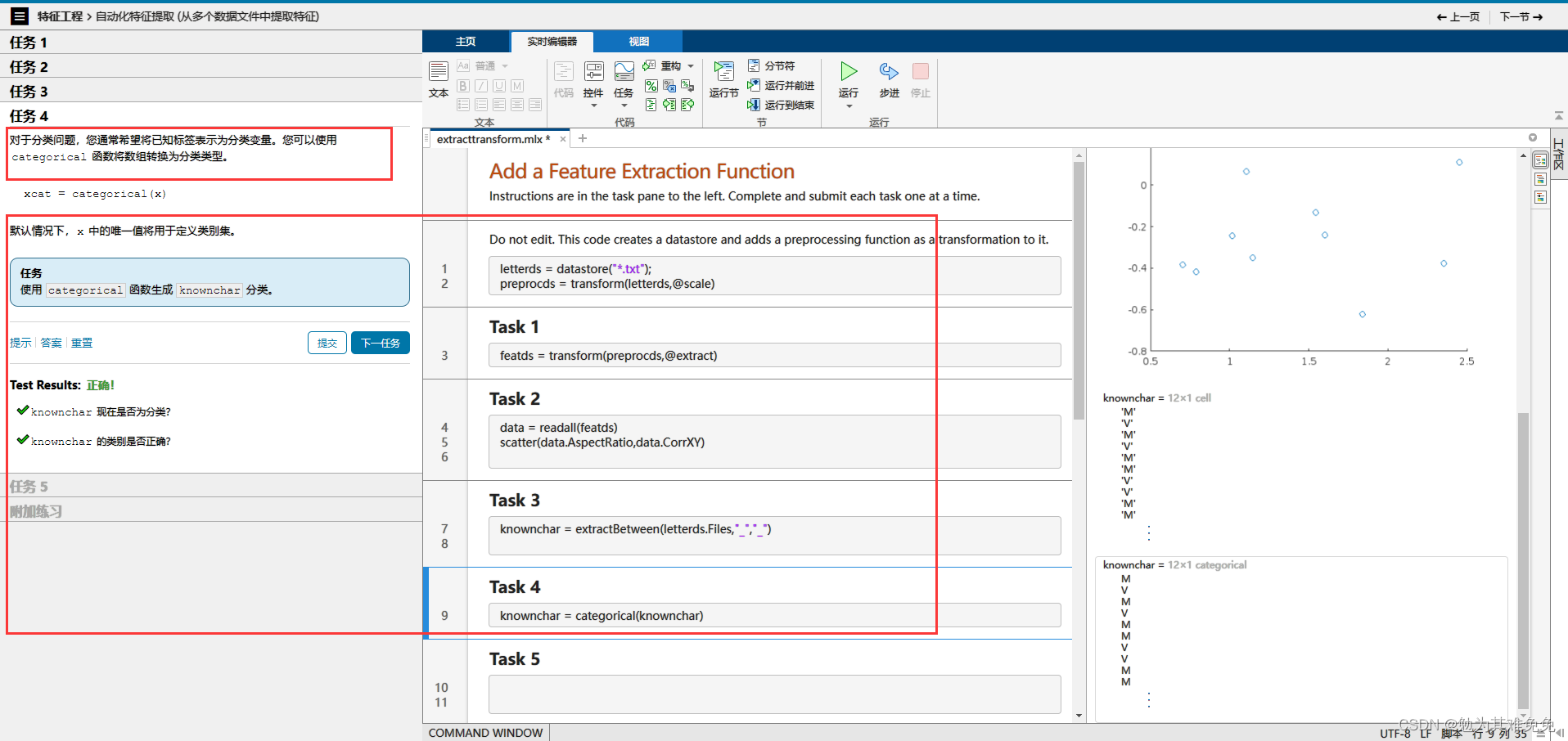
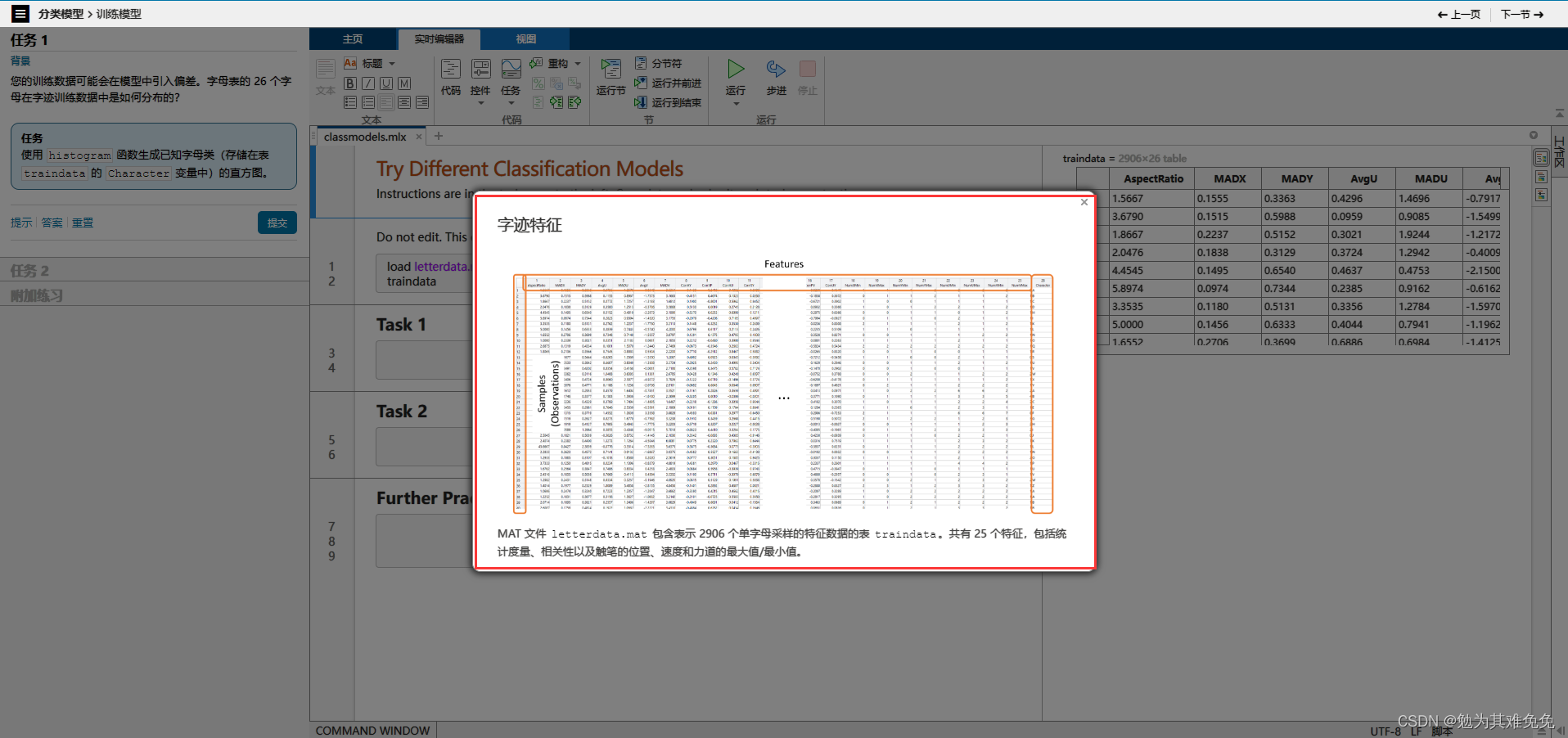
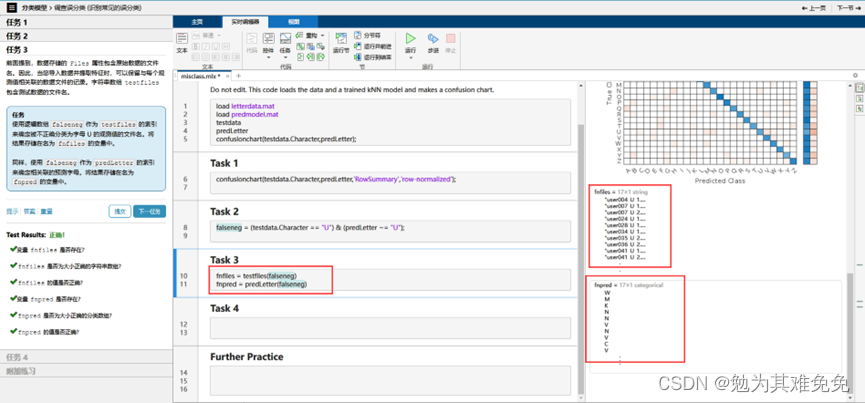
对于导入函数,例如readtable,你只需提供文件名,他就能从文件中返回数据。不过在创建数据存储时,你需要提供数据的位置,然后matlab会查看该位置的所有数据文件并返回一个变量,该变量包含有关文件及其内容格式的信息,由于数据有可能很多,因此只有在你请求这些数据时,才会将他们导入,这样你就可以控制获取数据的时间和内容,数据存储的Files属性,包含所有数据文件的完整文件名列表,很多时候,观测值的信息是路径或者文件名的一部分,在这种情况下,你可以使用extractBetween等字符串函数来查找和提取该信息。如果观测值的信息存储在一个单独的查找表中,你通常会使用readtable等函数来导入他,然后将其联接到关联的数据,字迹数据存储在一个文件夹中,文件名报刊字母信息,在接下的几节中,你将创建一个数据存储,并学习如何导入和处理这些文件中的数据,以准备好从数据中提取信息并构建预测模型。
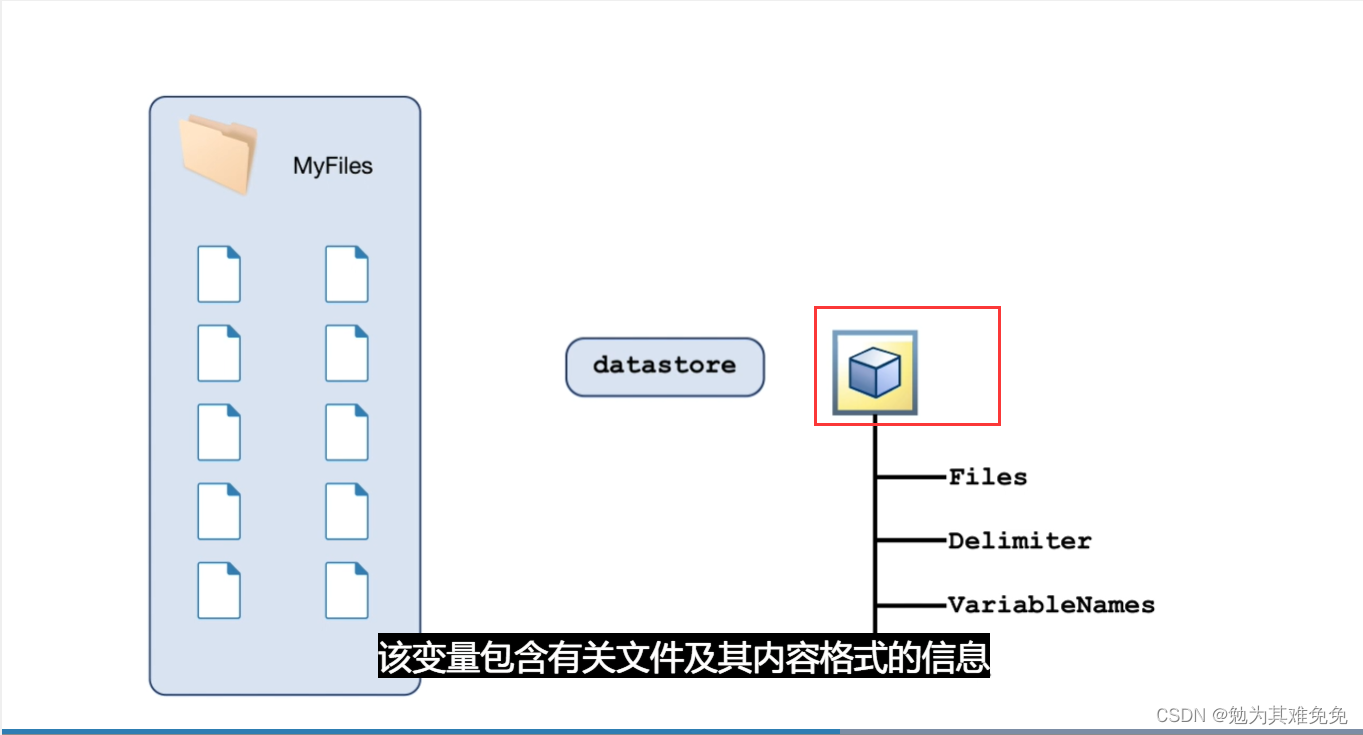
创建数据存储
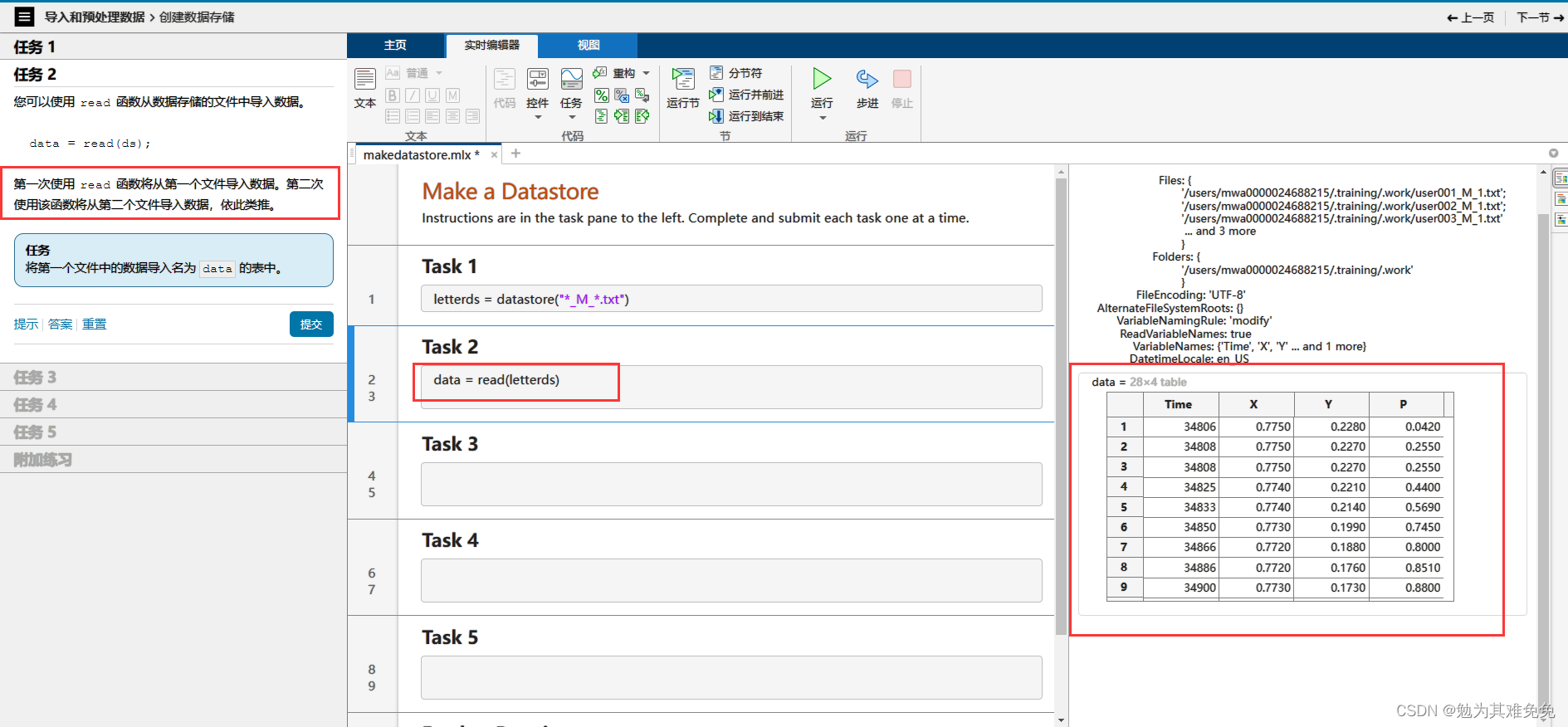
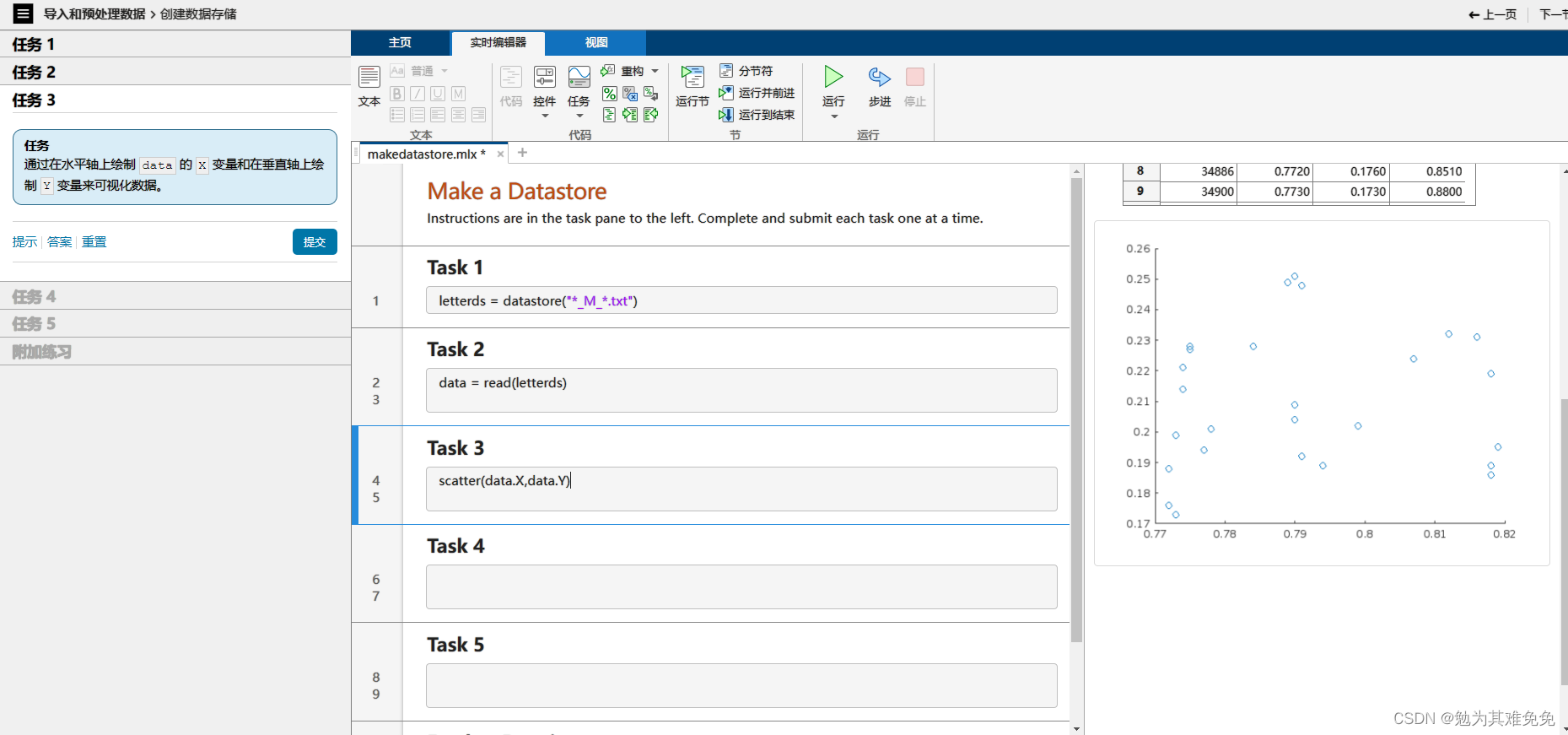
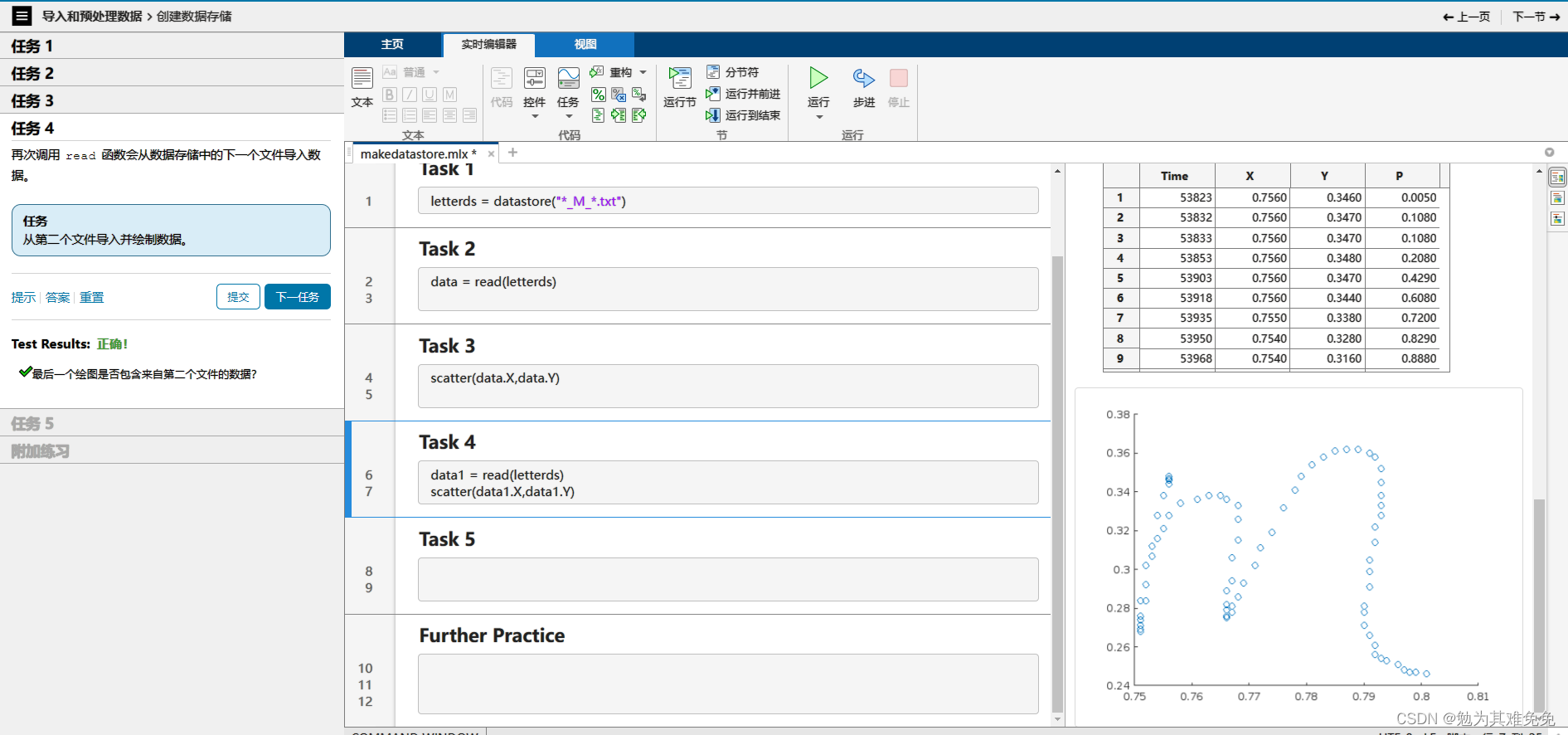
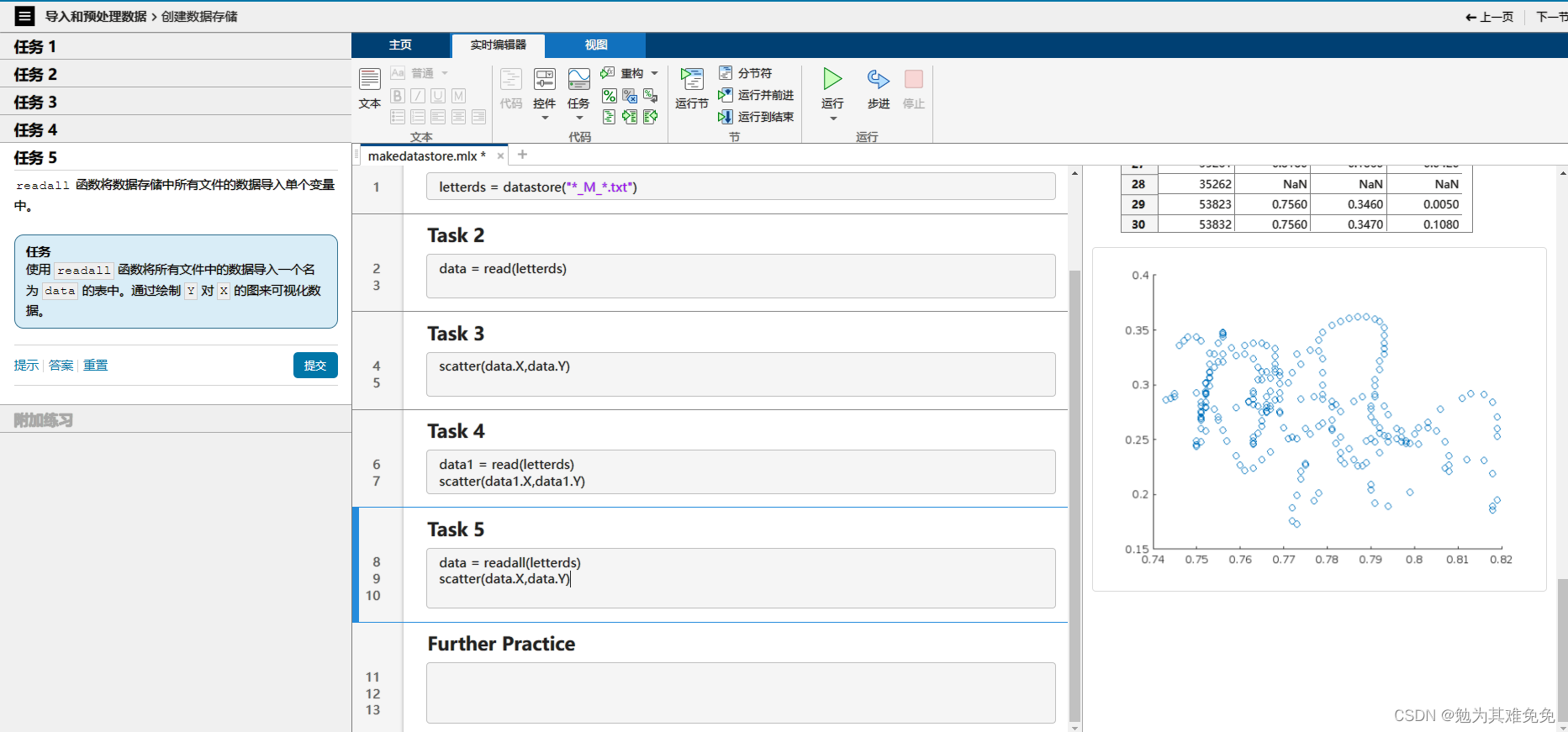
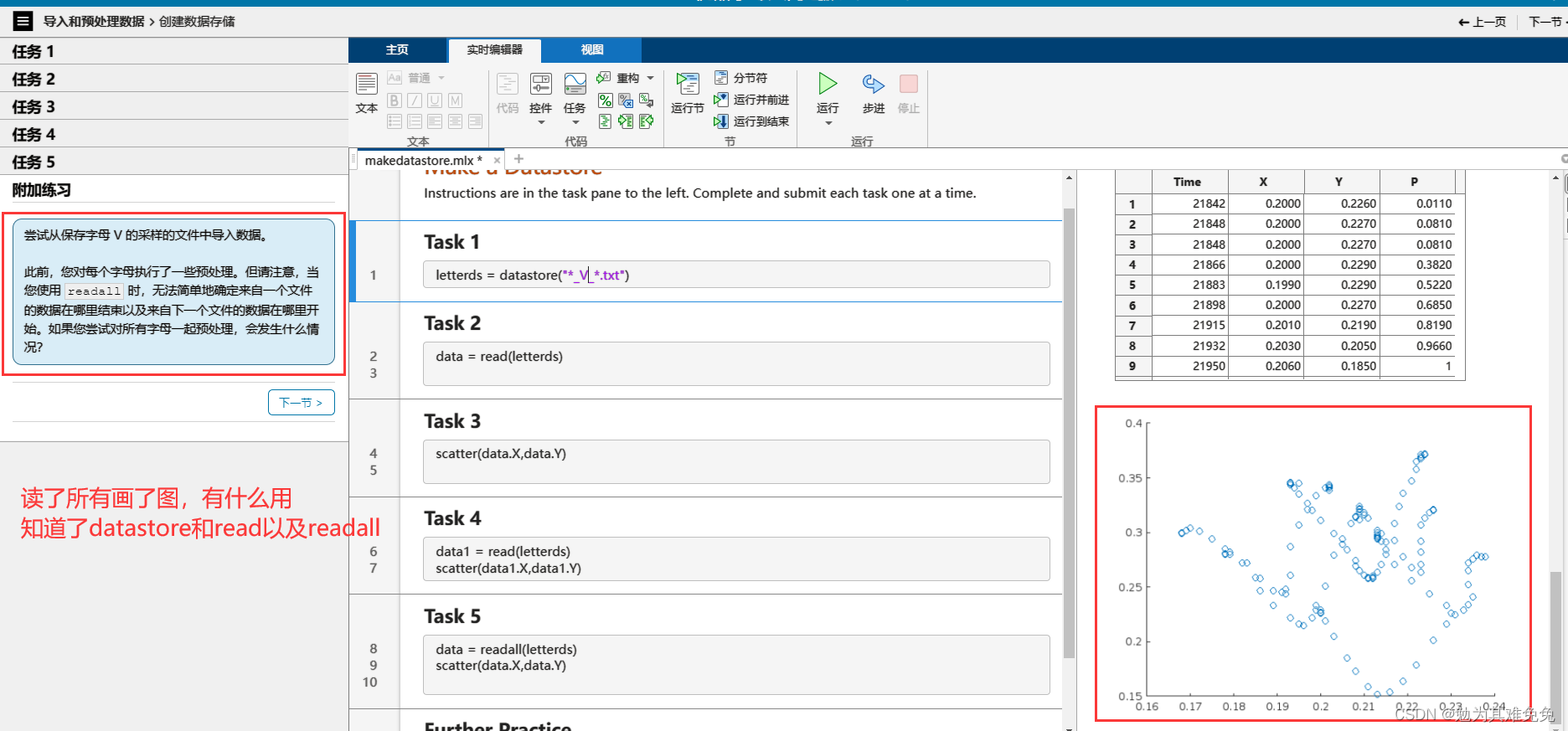
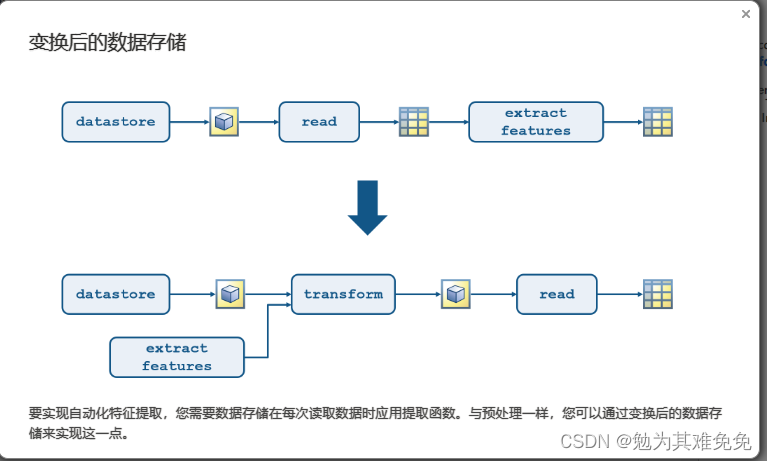
添加数据变化
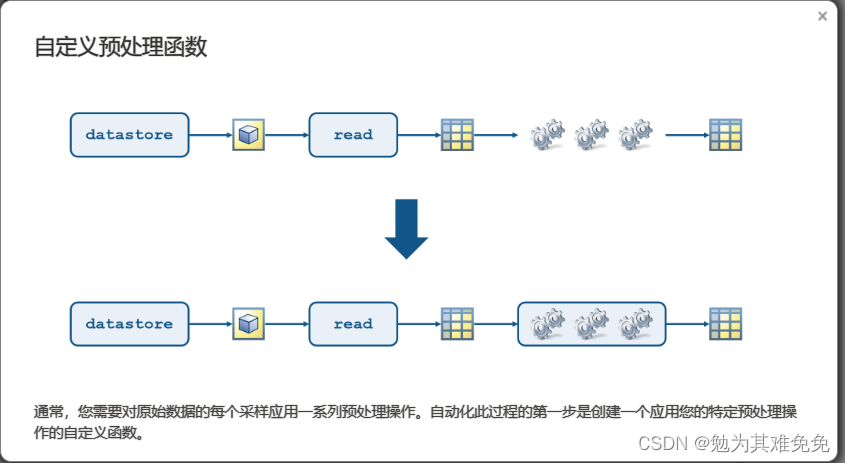
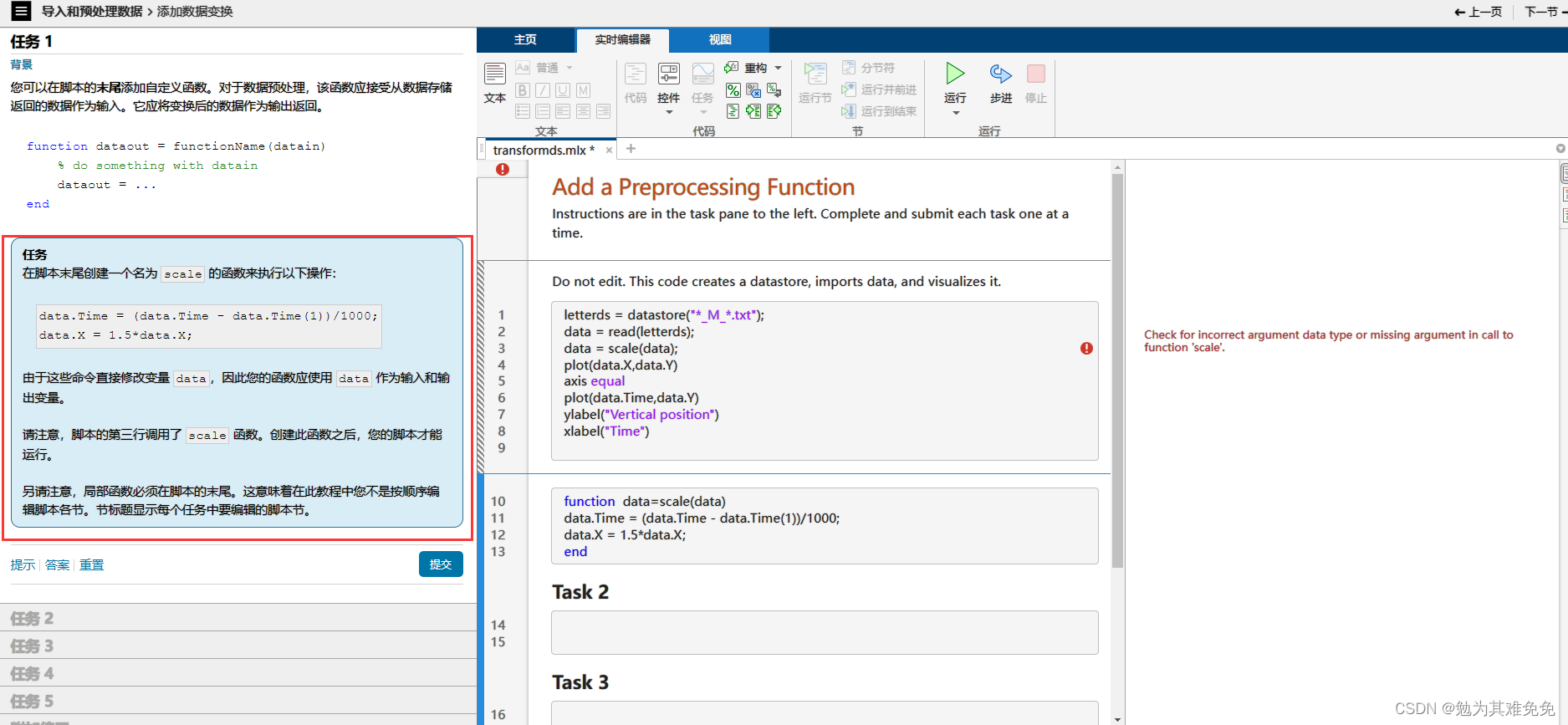

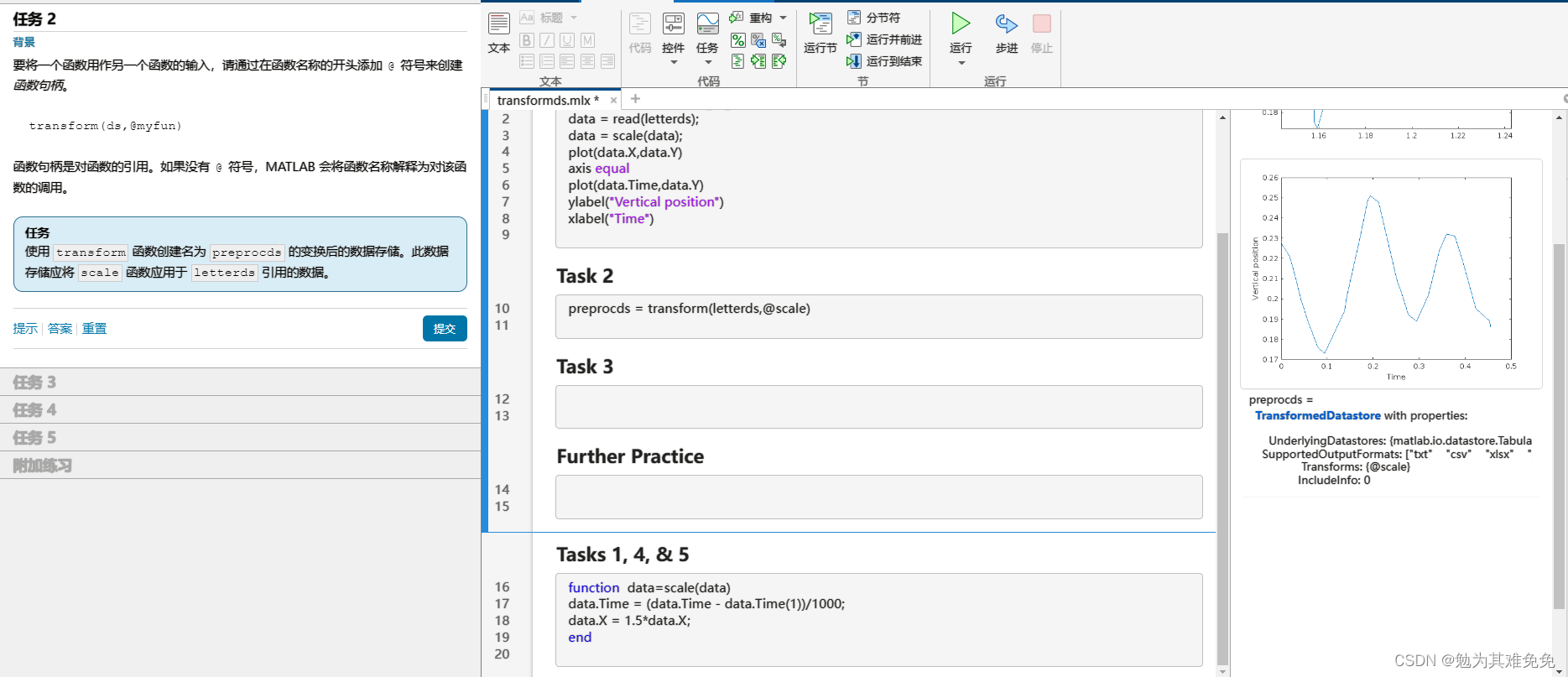
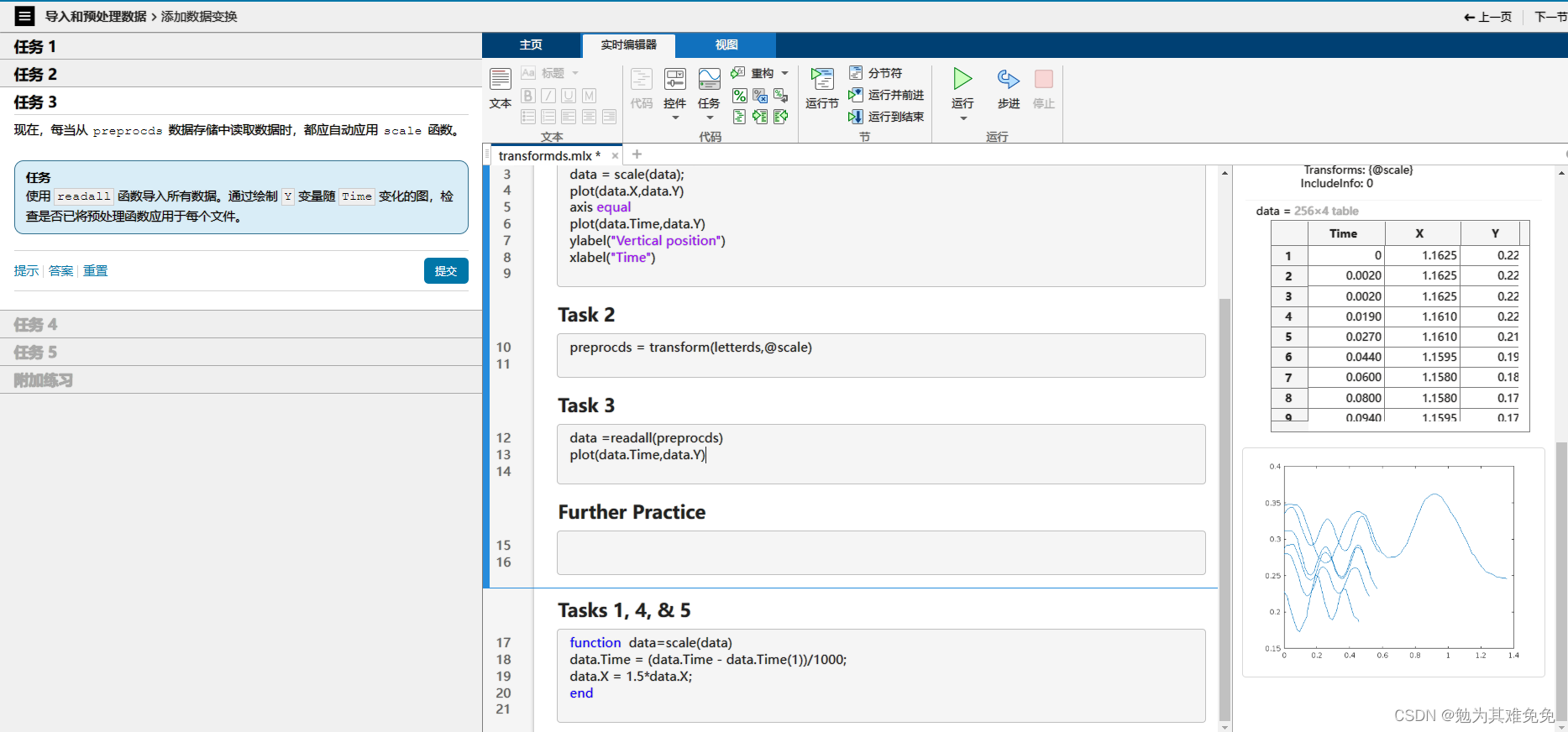
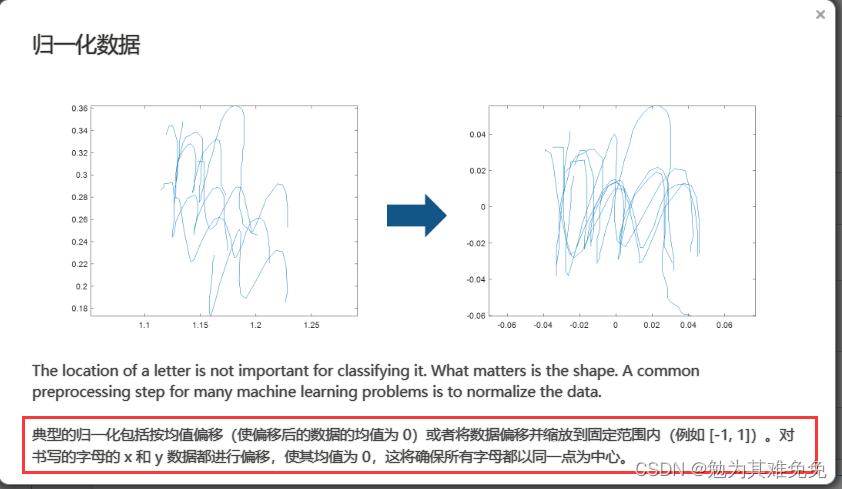
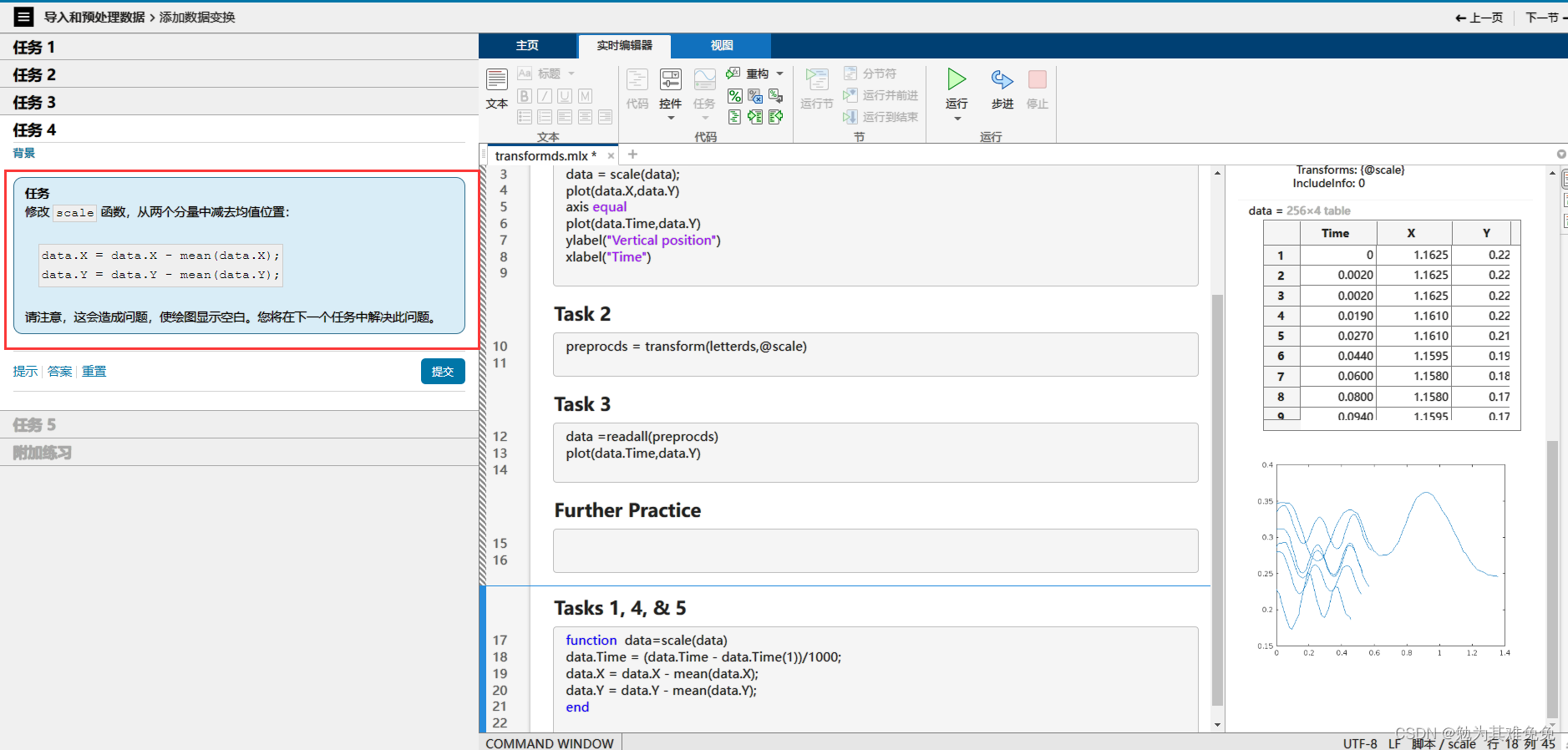
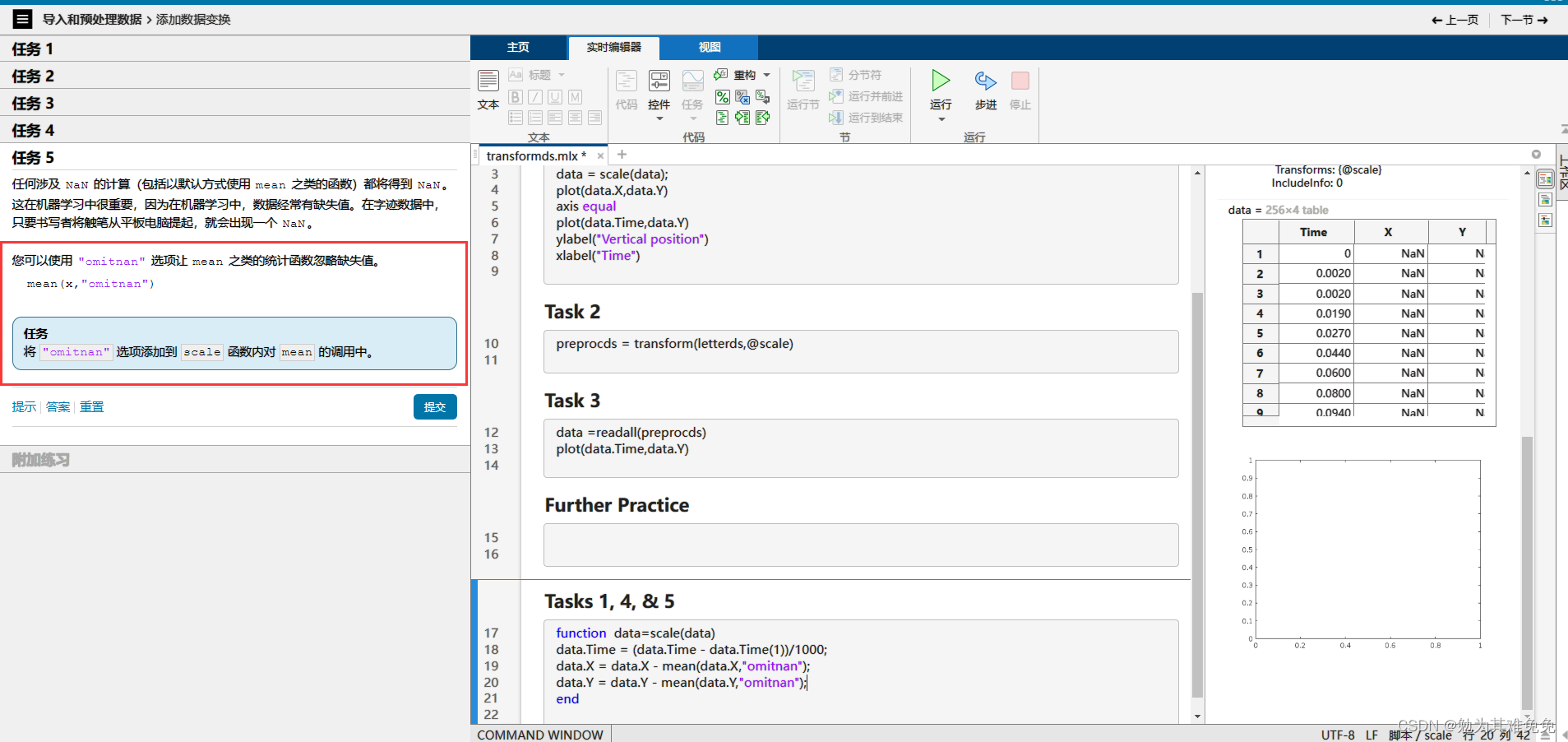
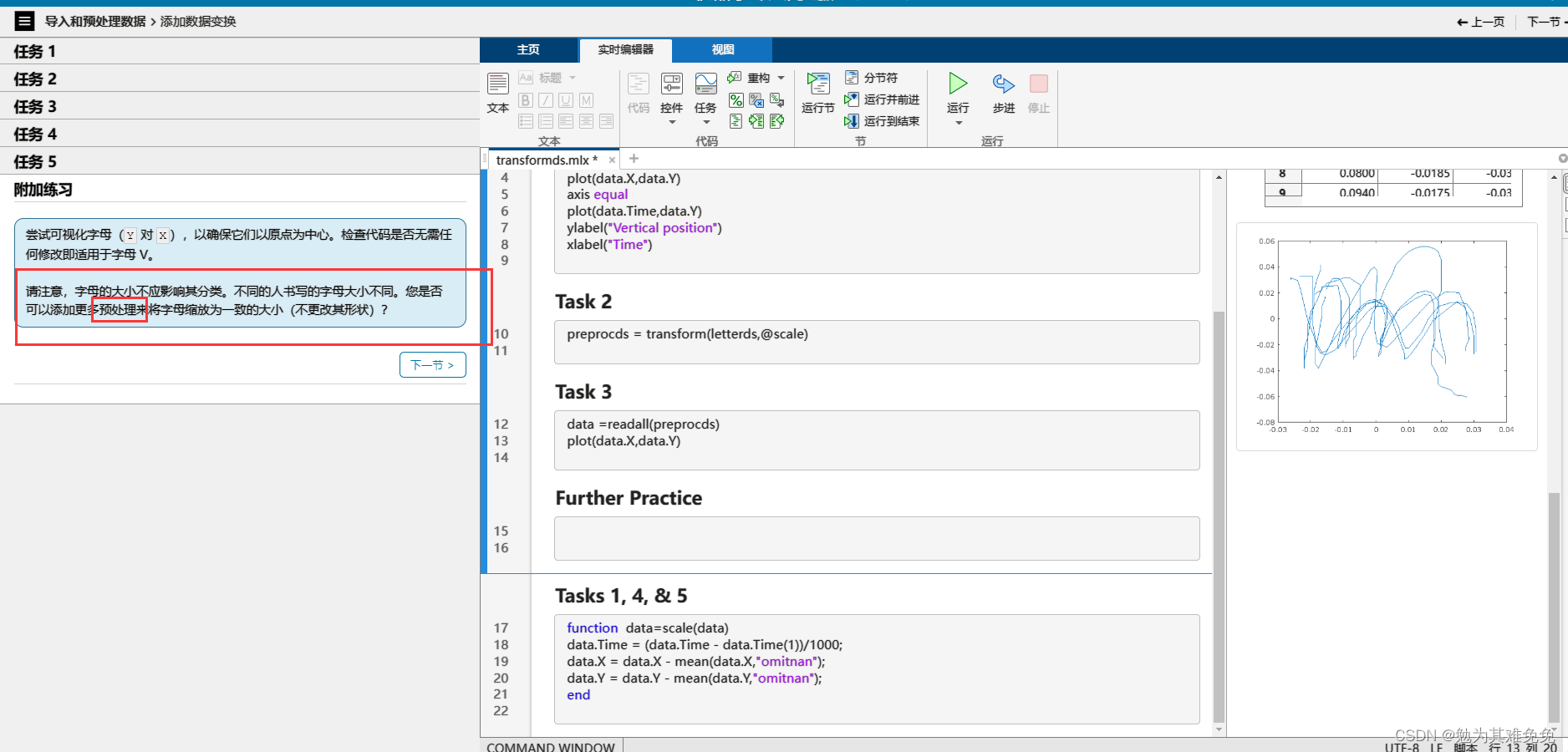
不接着看我没想到这个咋处理,看看下面咋操作把。
特征工程
信号类型
机器学习算法需要特定形式的数据:许多观测值。其中每个观测值包含若干特征,构建预测模型时,这些特征是预测变量,也是模型确定用来确定输出的输入,因此,特征可以是任何能帮助区分不同观测值的测量值,很多问题会采用这种数据形式,例如,预测患者是否可能患有某种疾病,每个观测值是一位患者,这些特征是生物信息和诊断信息,例如年龄、血压、是否吸烟、血液检测结果等。
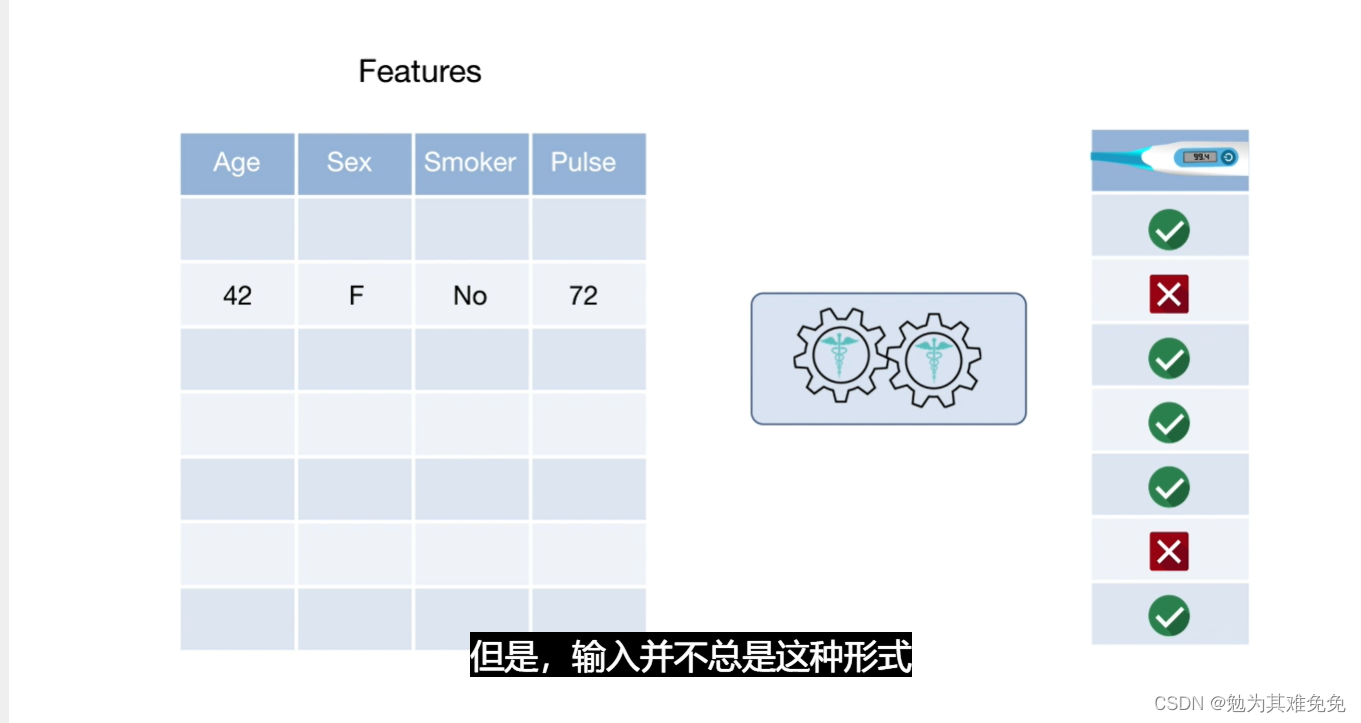
但是输入并不总是这些形式,想象一下,如何根据X光或者MRI等影像资料对患者进行诊断,此时输入时一个像素数组,输入还可能来自传感器,例如EEG或EKG,此时输入时一组基于时间的信号,要将机器学习算法应用于信号,首先需要将原始数据变化为一组特征,你如何找出这些特征?
如果已知信号背后的物理系统,则可以使用这些知识来帮助找出可用于信号区分的特征,如果你不具备这些背景知识,也没关系,认真观察数据集,看能否得到一些启发,这任何时候都值得推荐。
特征可以是整个信号的简单统计度量、形状的度量。例如局部最大值数目或波峰的宽度,相关性的度量或任何数量的其他度量。这些是适用于任何信号的一般特征。
还有一些专门针对声音、震动或者心跳等周期性信号的方法。
通常,这些方法将一个信号分解成若干个简单分量,并确定各分量对整个信号的贡献。你可以将许多周期性信号(如声音)表示为不同频率的正弦和余弦的组合。
matlab和signal processing toolbox包含执行这种分析的工具,以及用于设计滤波器以及平滑处理和清理信号的工具,还提供许多其他信号处理方法。
其他周期性信号,如心跳,更适合建模为称为小波的短脉冲的组合,Wavelet Toolbox将matlab的信号处理能力扩展到这些类型的信号。
字迹信号不是周期性信号,因此本课程不涉及这些方法。在接下来的几节中,介绍如何使用标准matlab函数从这些基于时间的信号中提取一些基本特征。然后将使用特征表来训练分类模型,
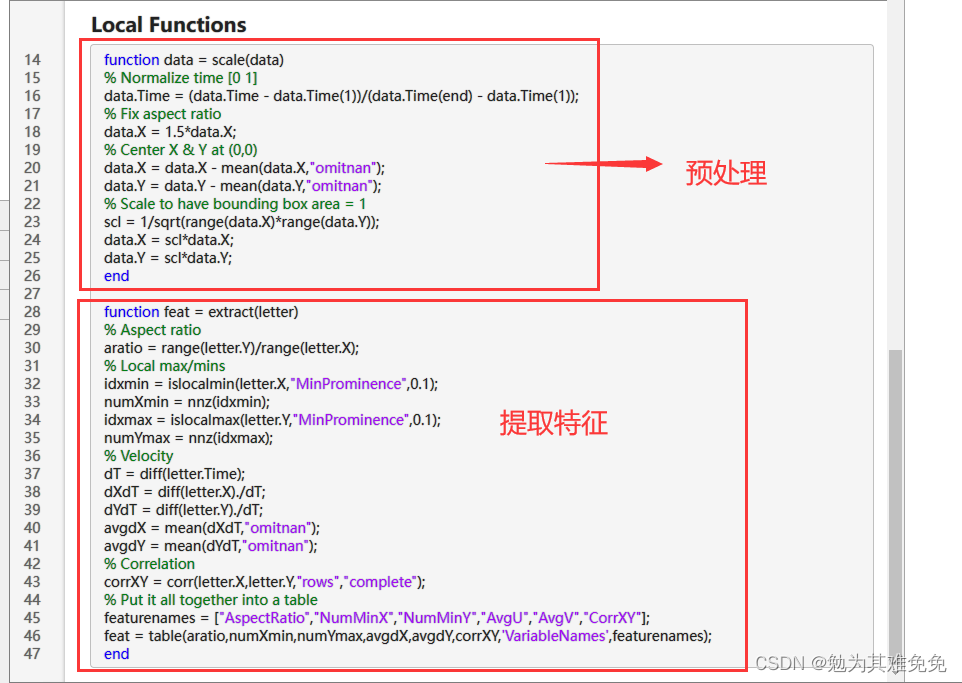
计算汇总统计量
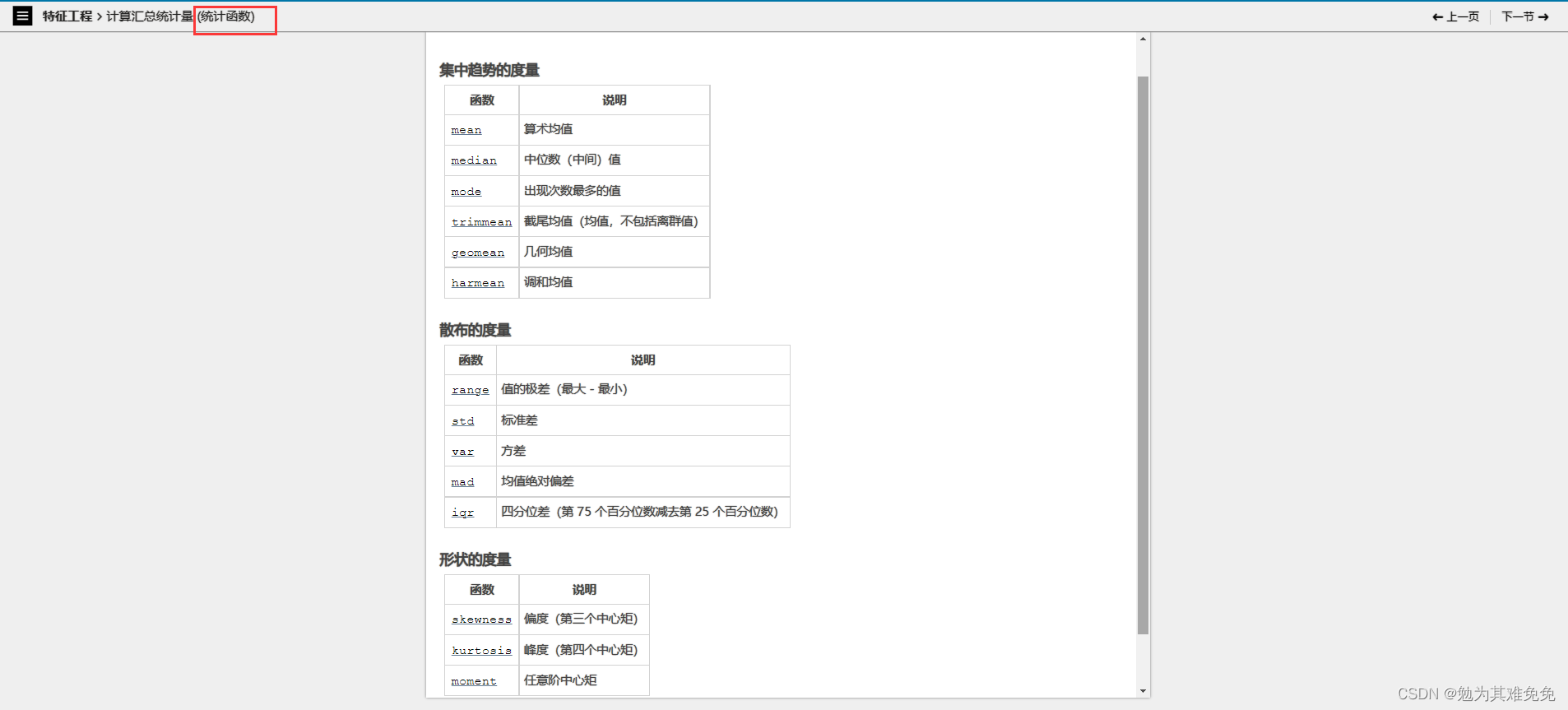
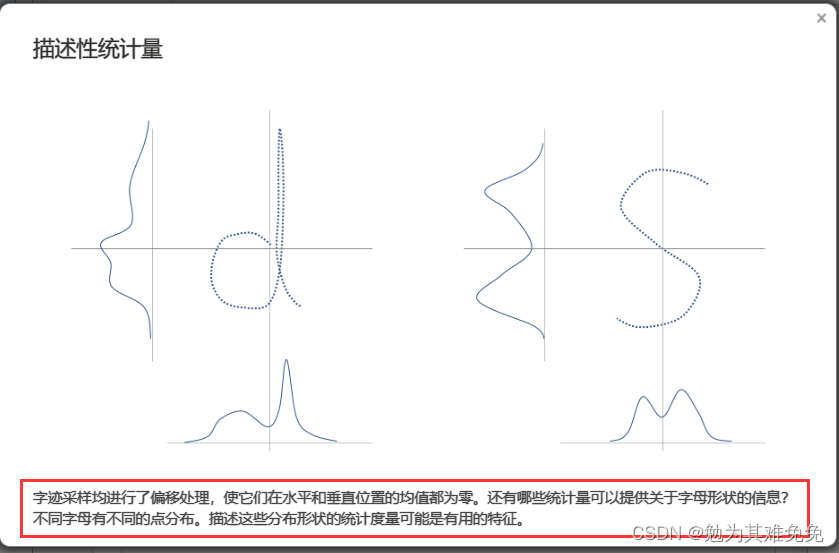
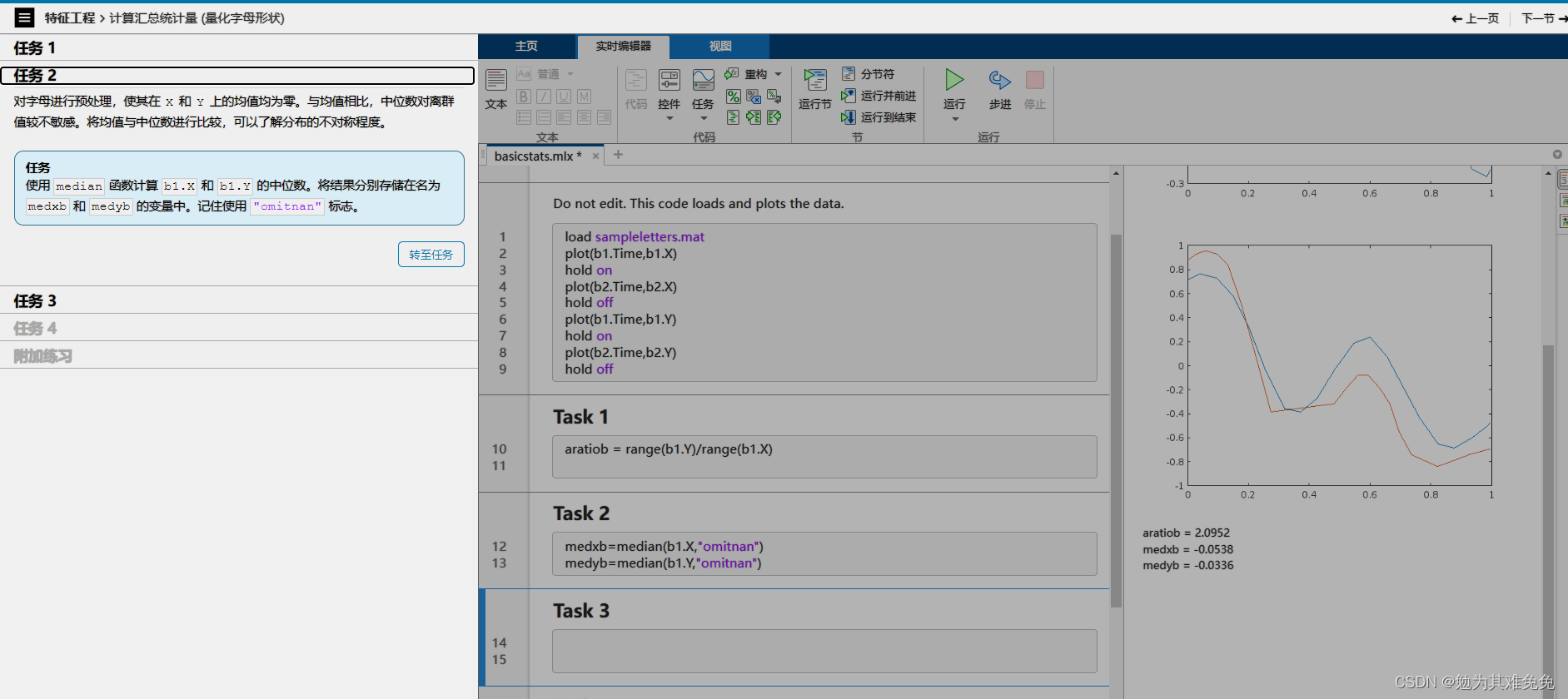
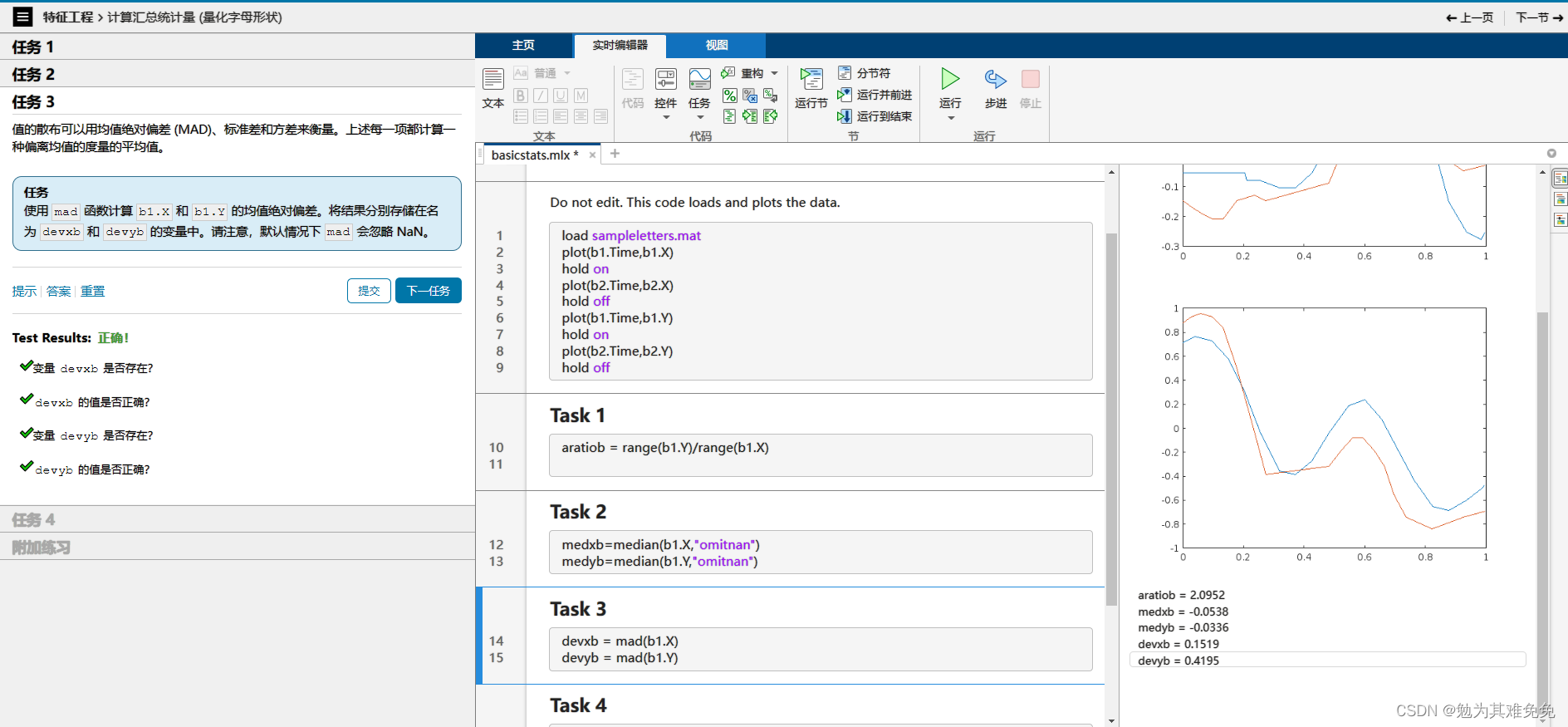
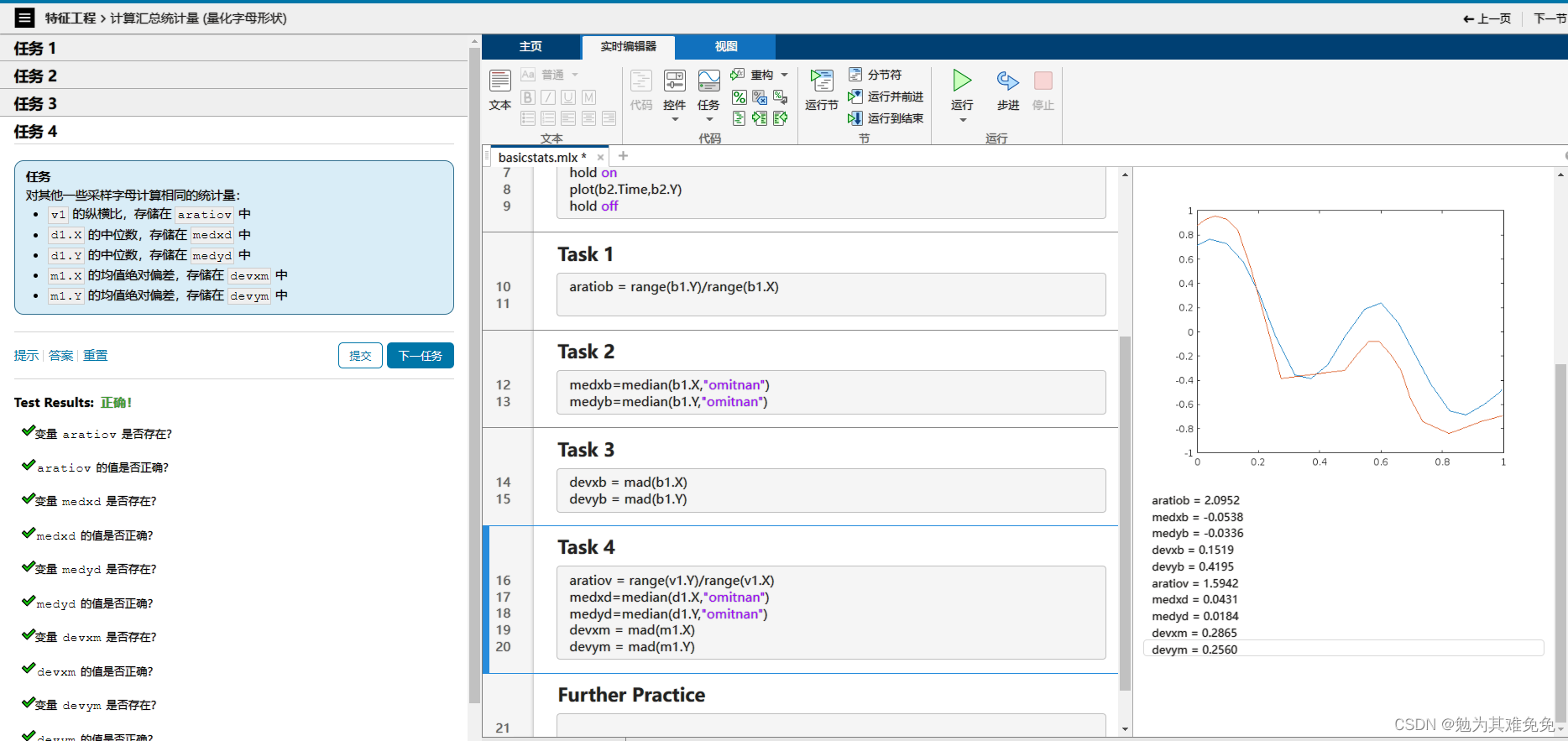
计算汇总统计量(量化字母形状)
查找峰值
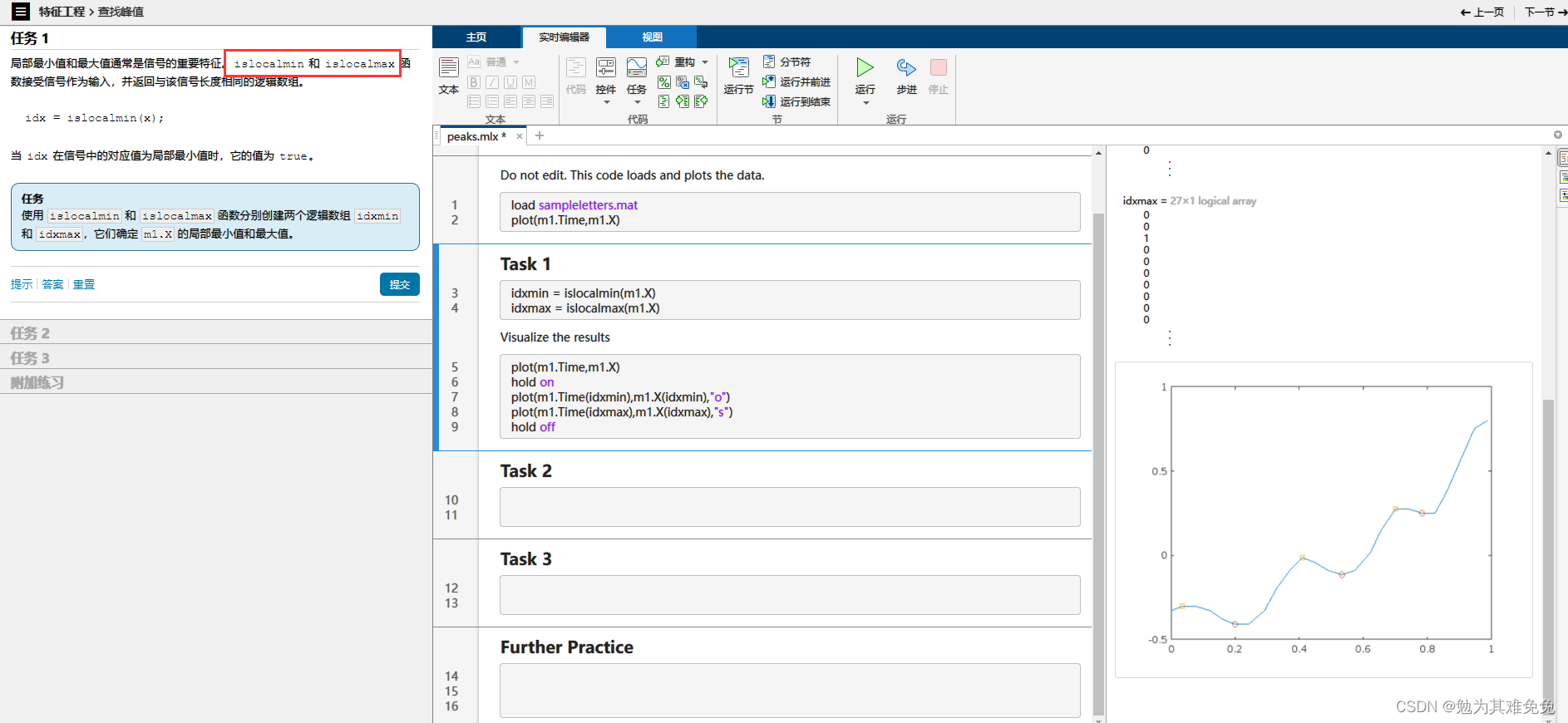
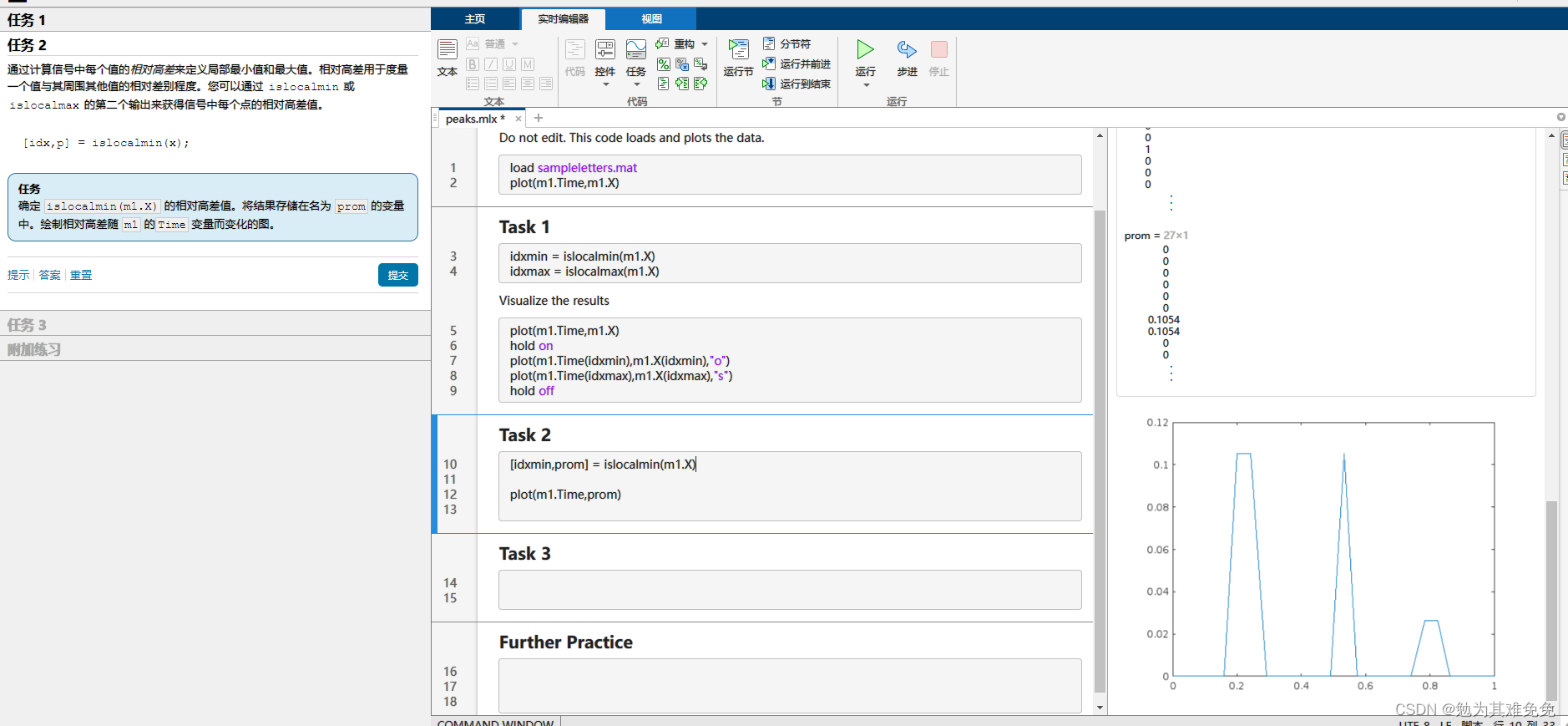

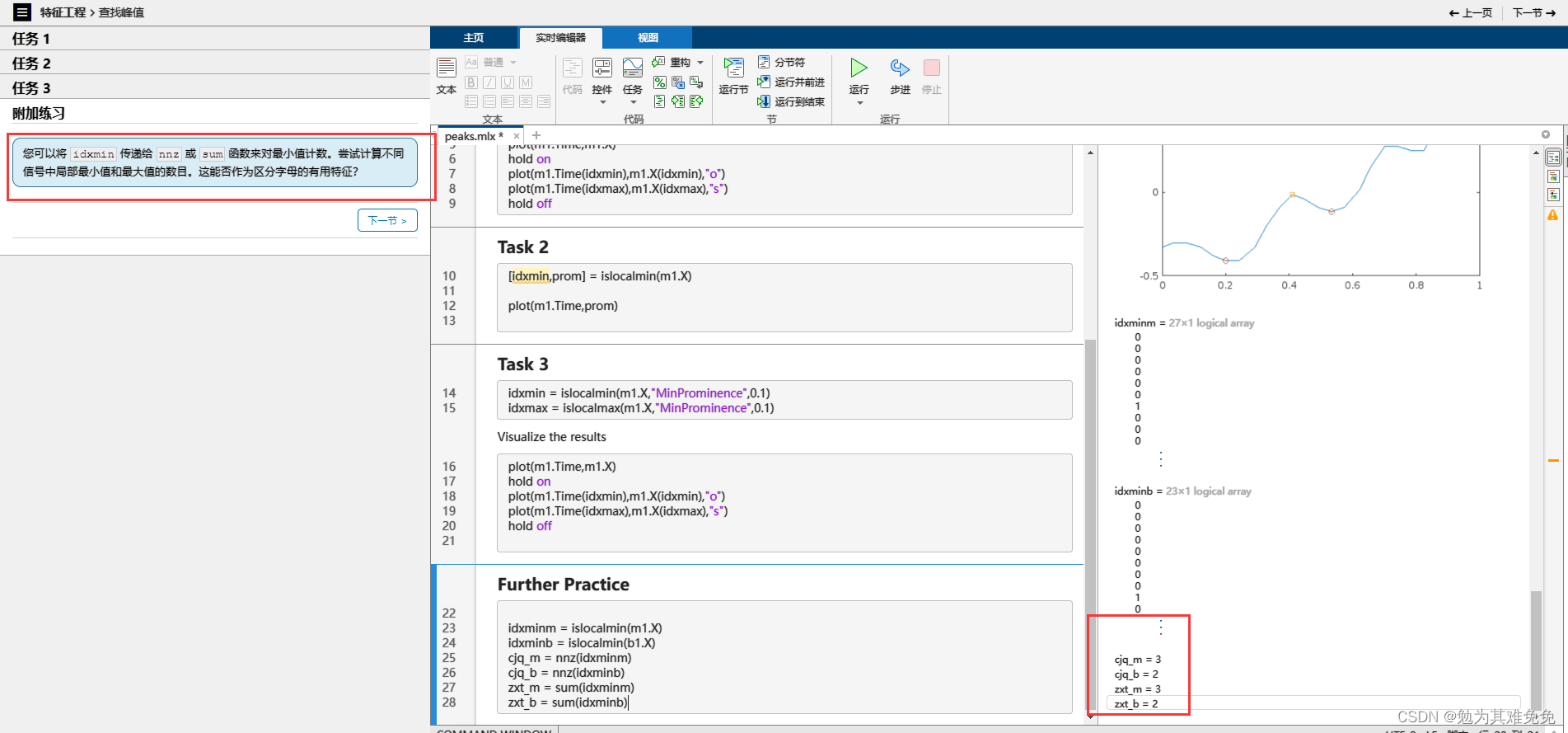
写一个字母,在水平方向上最小值的个数,M三个好理解,B是怎么写出两个的。不过这个好像可以作为区分的依据之一。继续往下看看吧。
计算导数
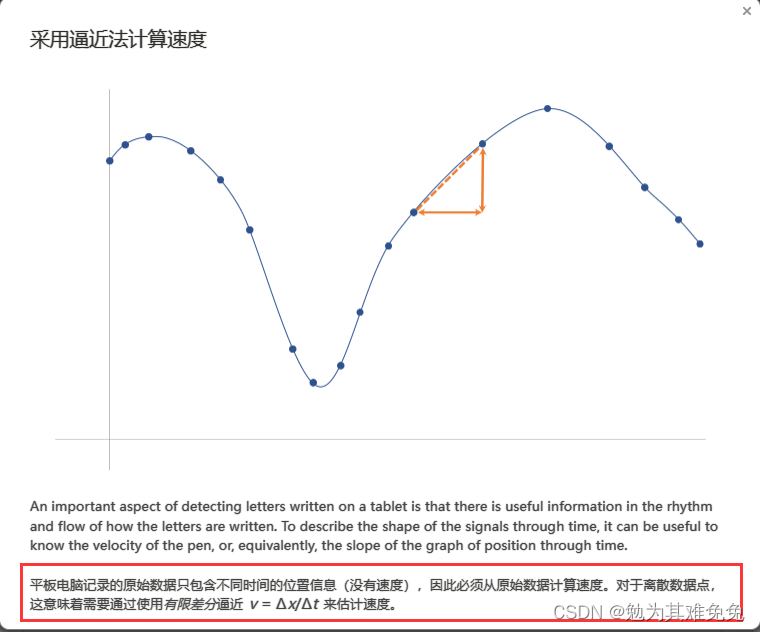
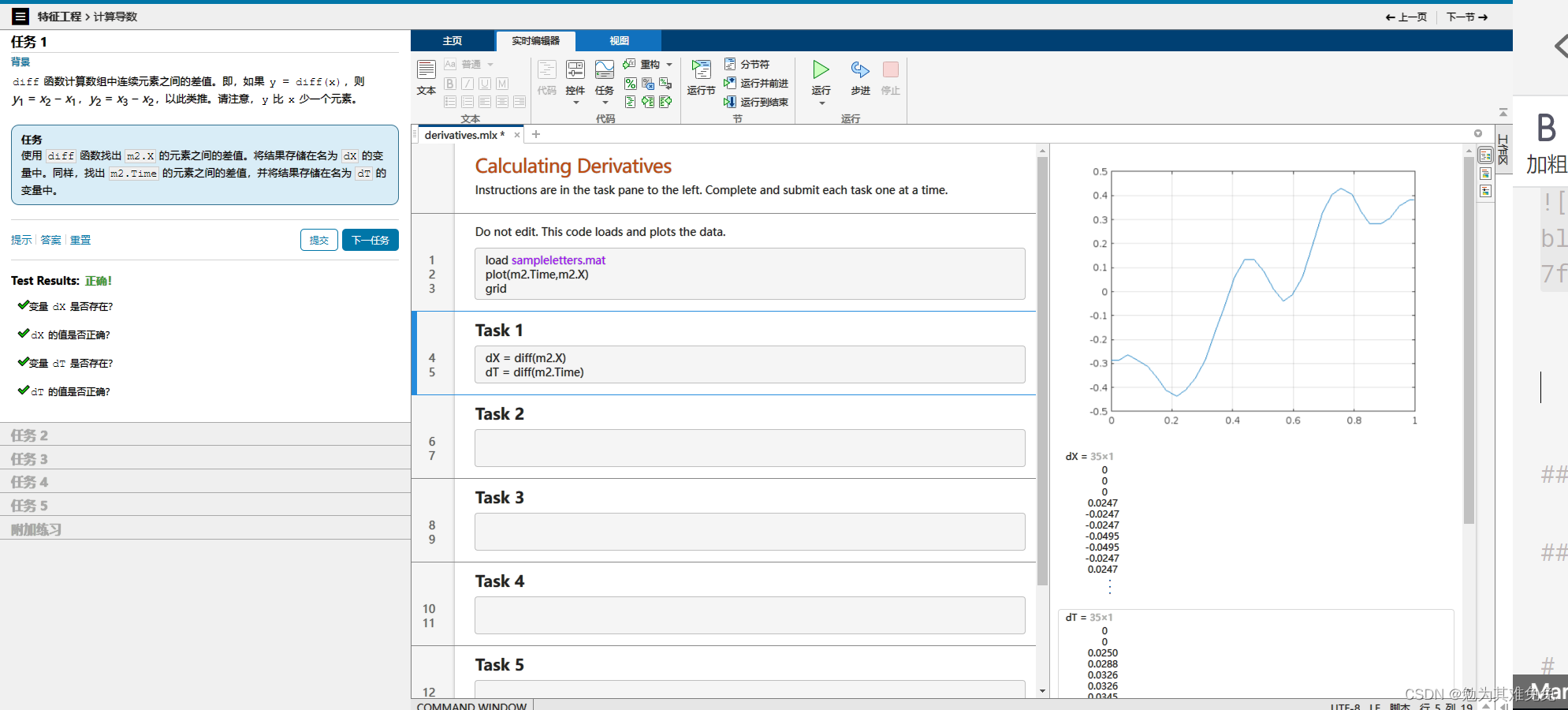
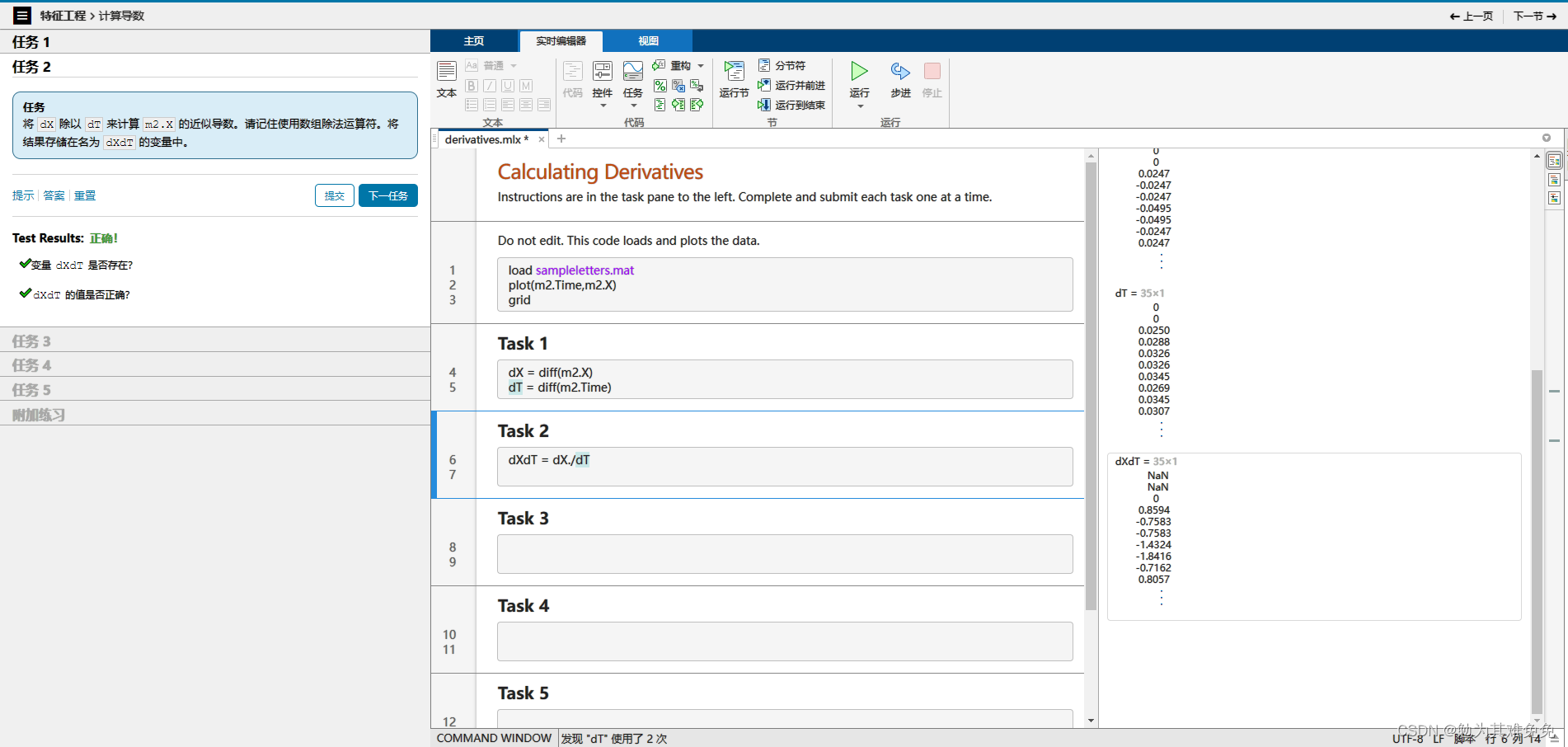

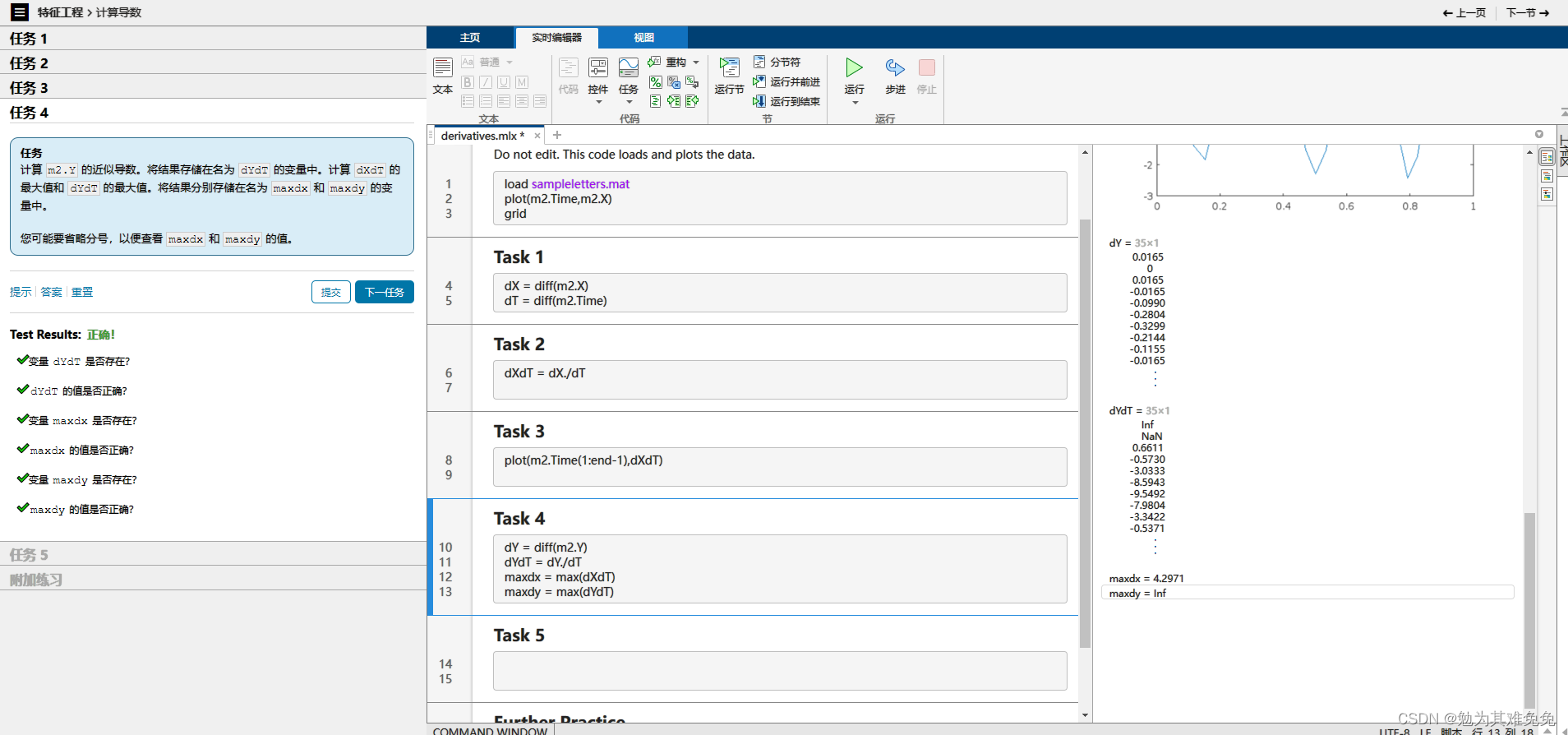
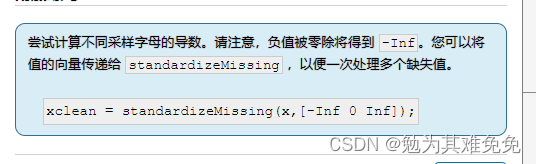
max会忽略NaN,但是不可能忽略inf的
计算相关性

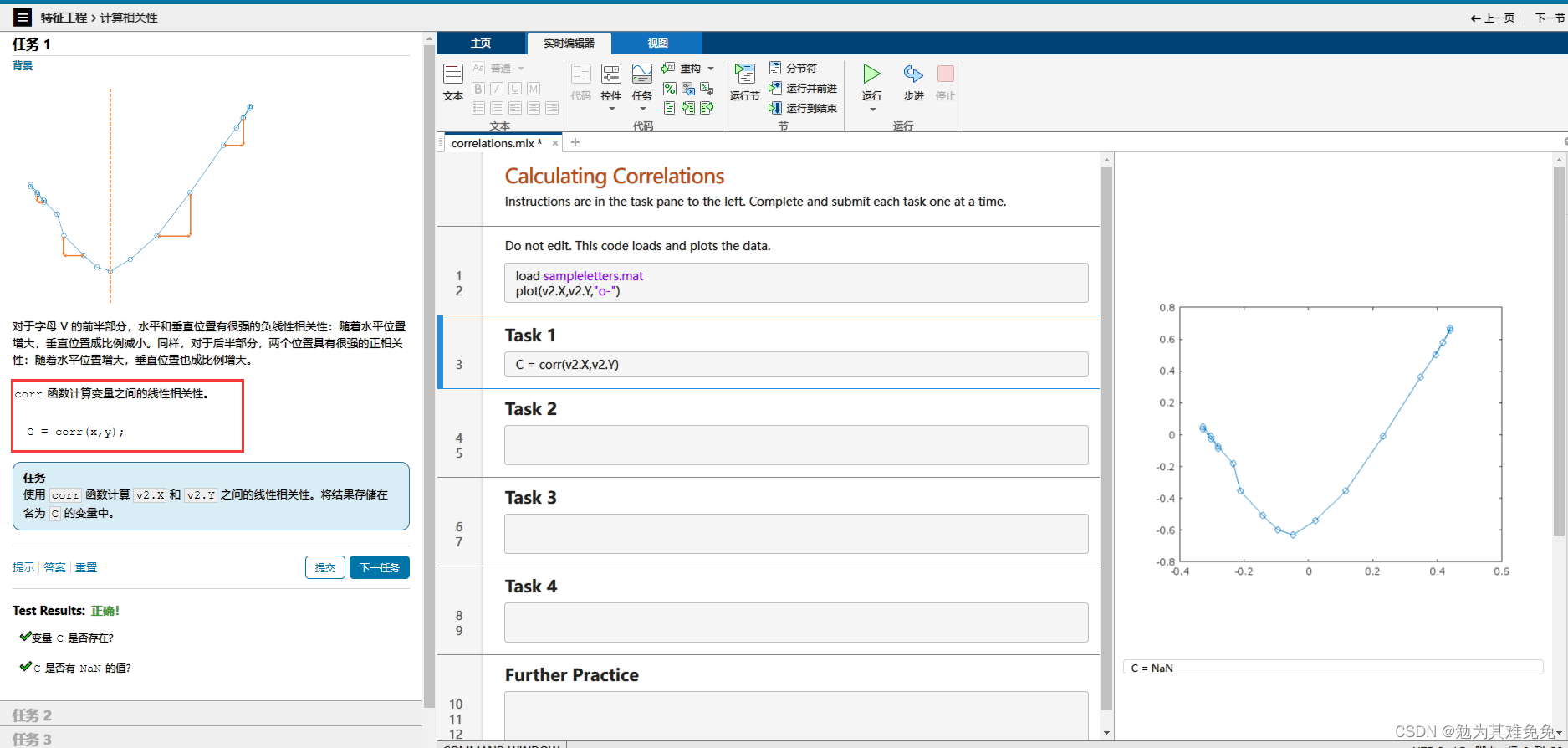
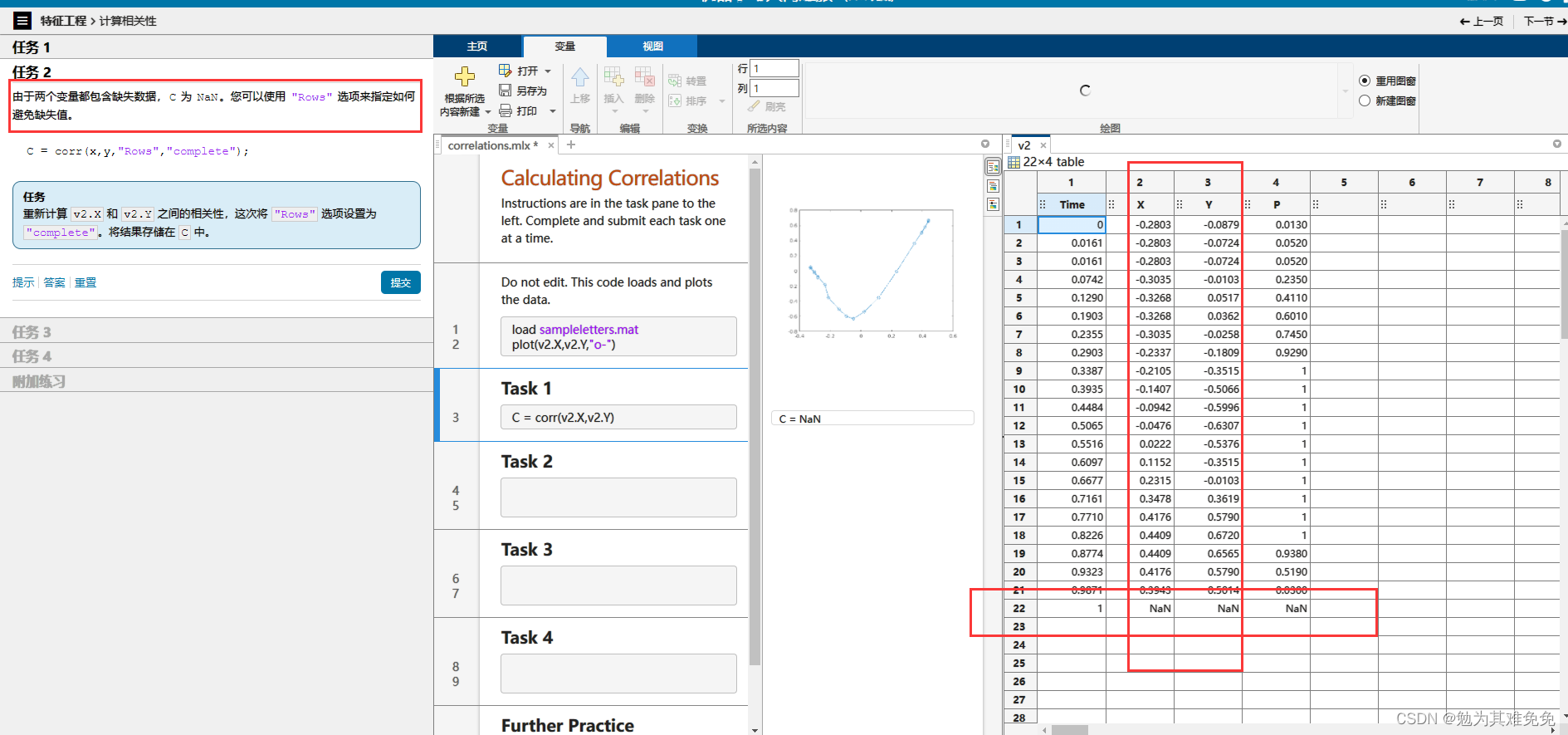
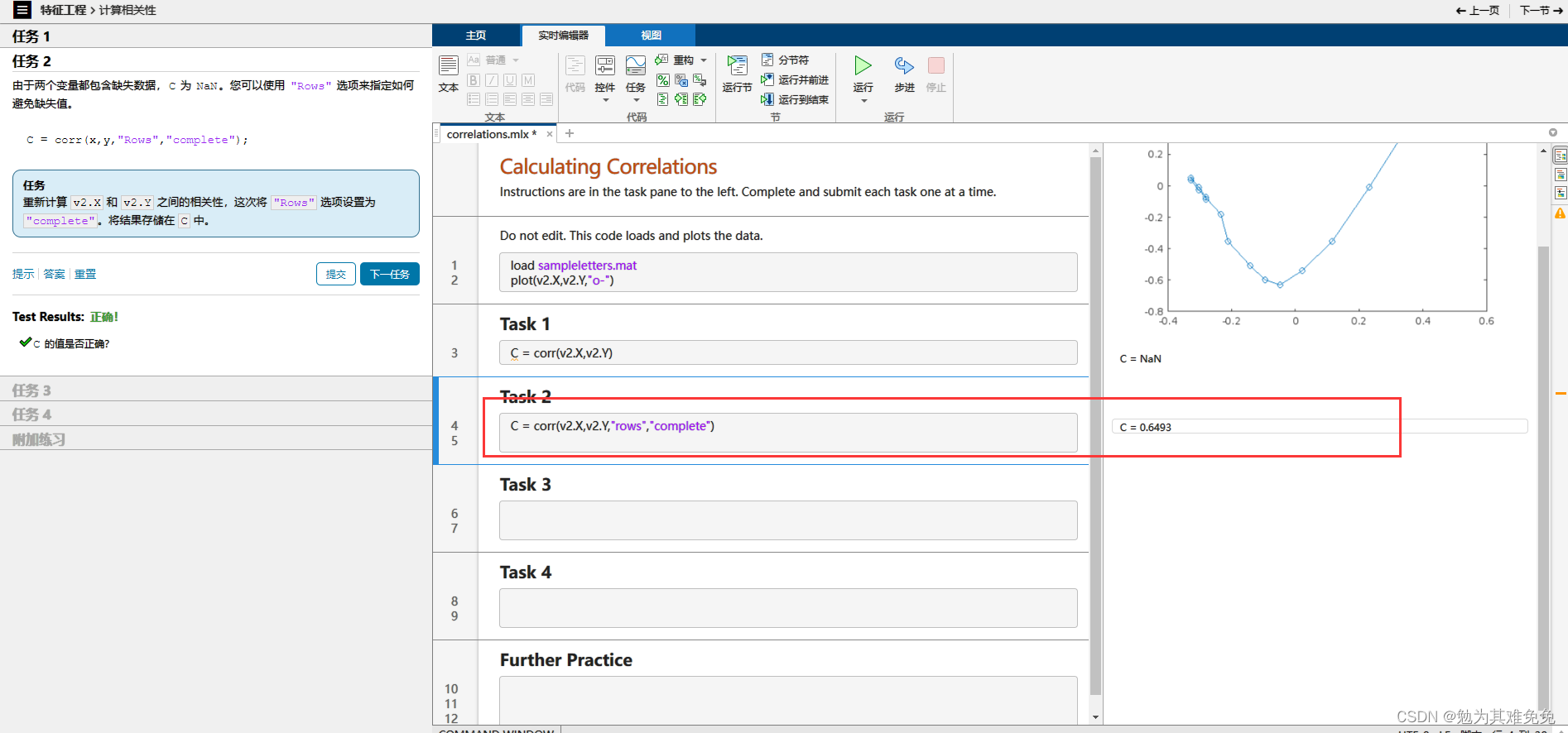
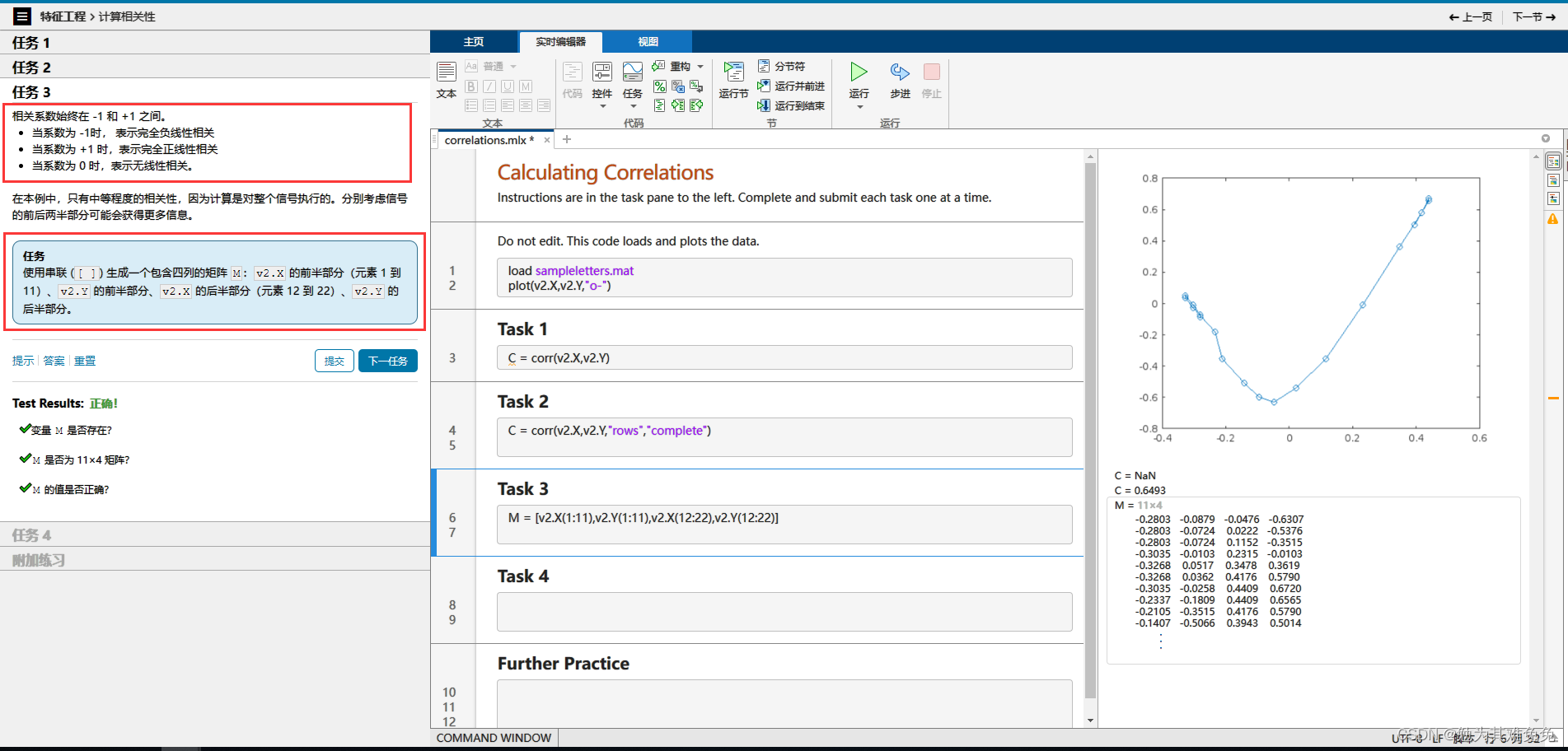
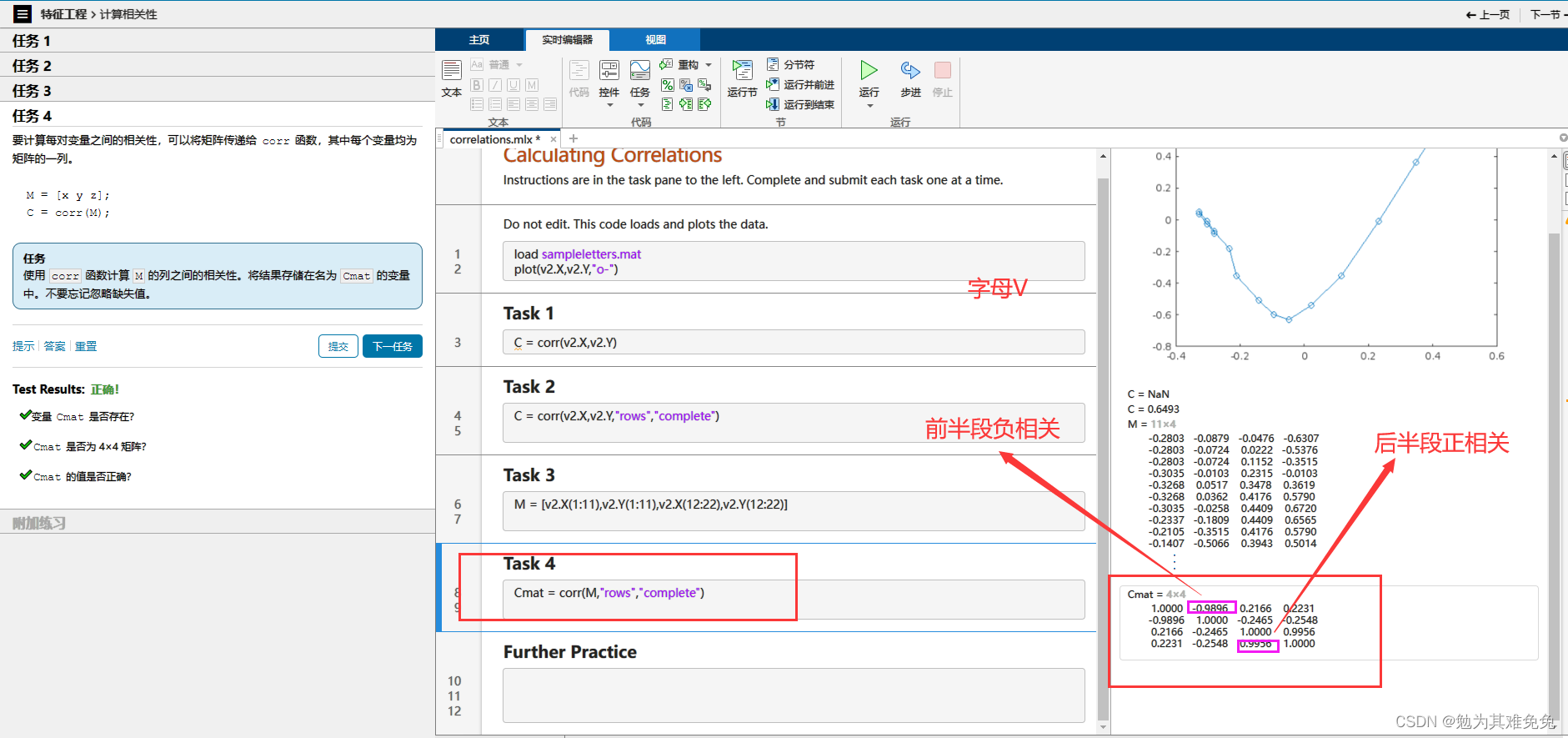
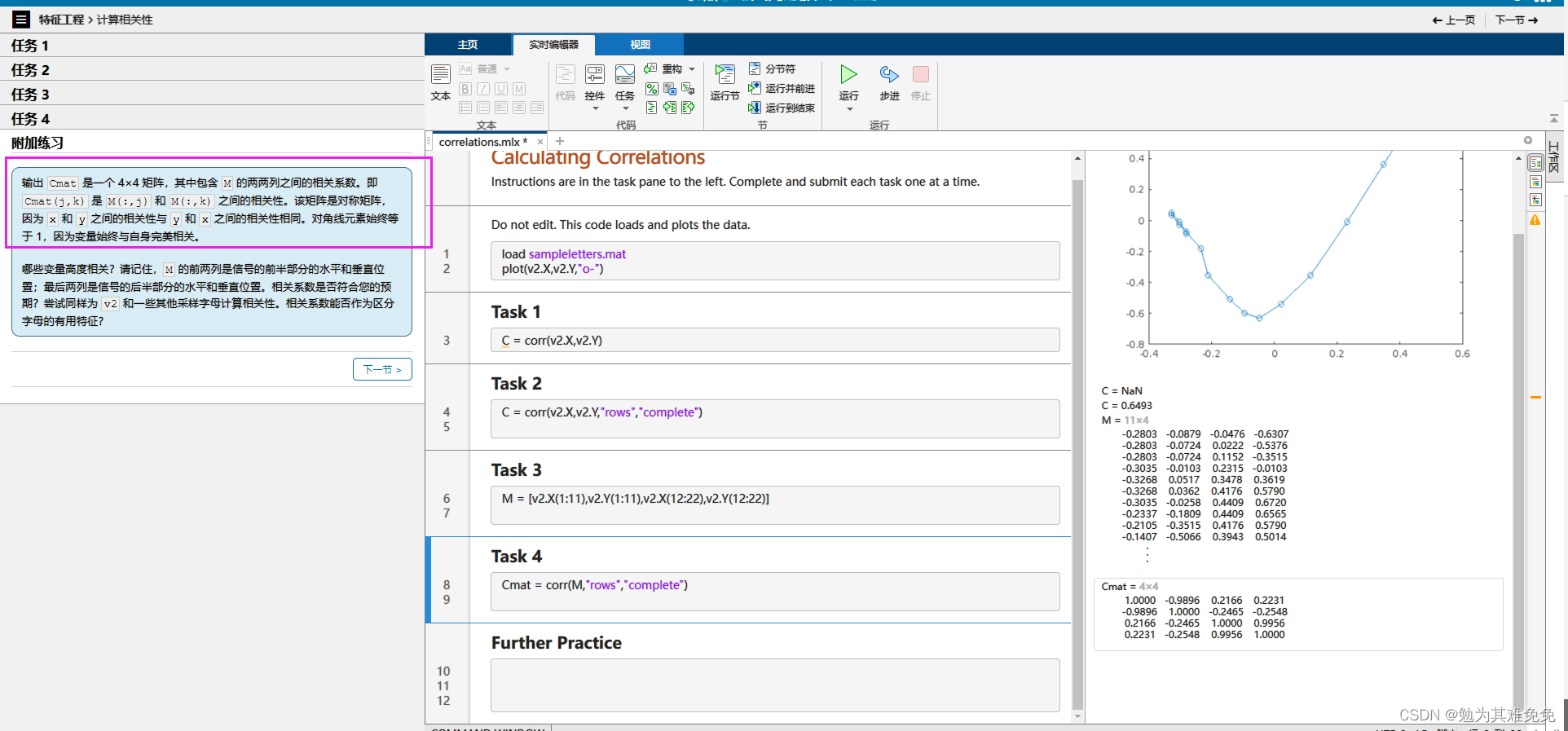
里面的数据只有b d m v b和d的相关性有吗?M一定是有的,正负正负。这需要相关性判断嘛?
自动化特征提取
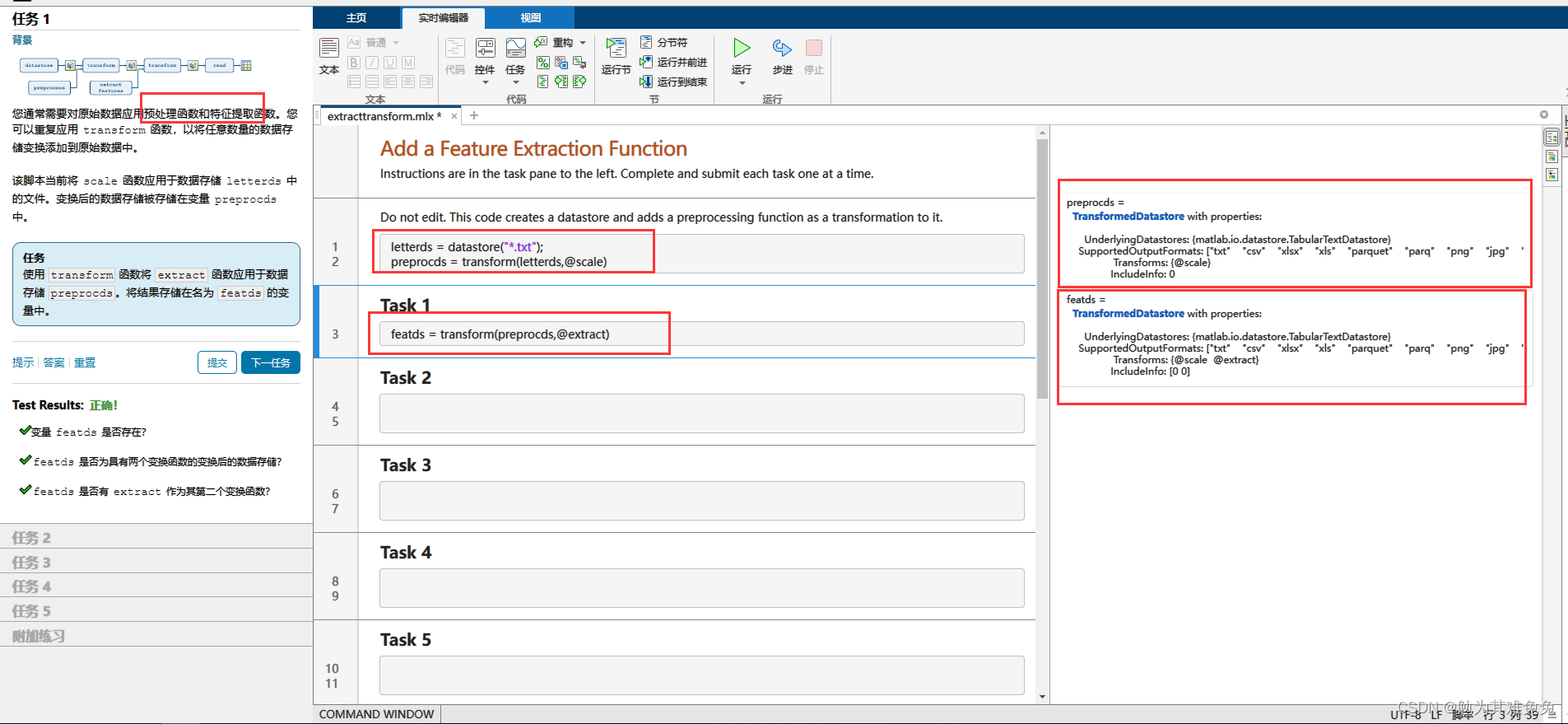
创建特征提取函数
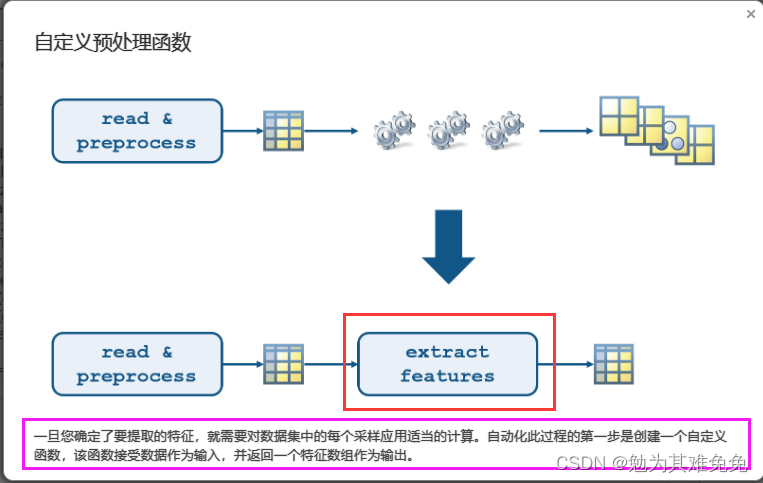
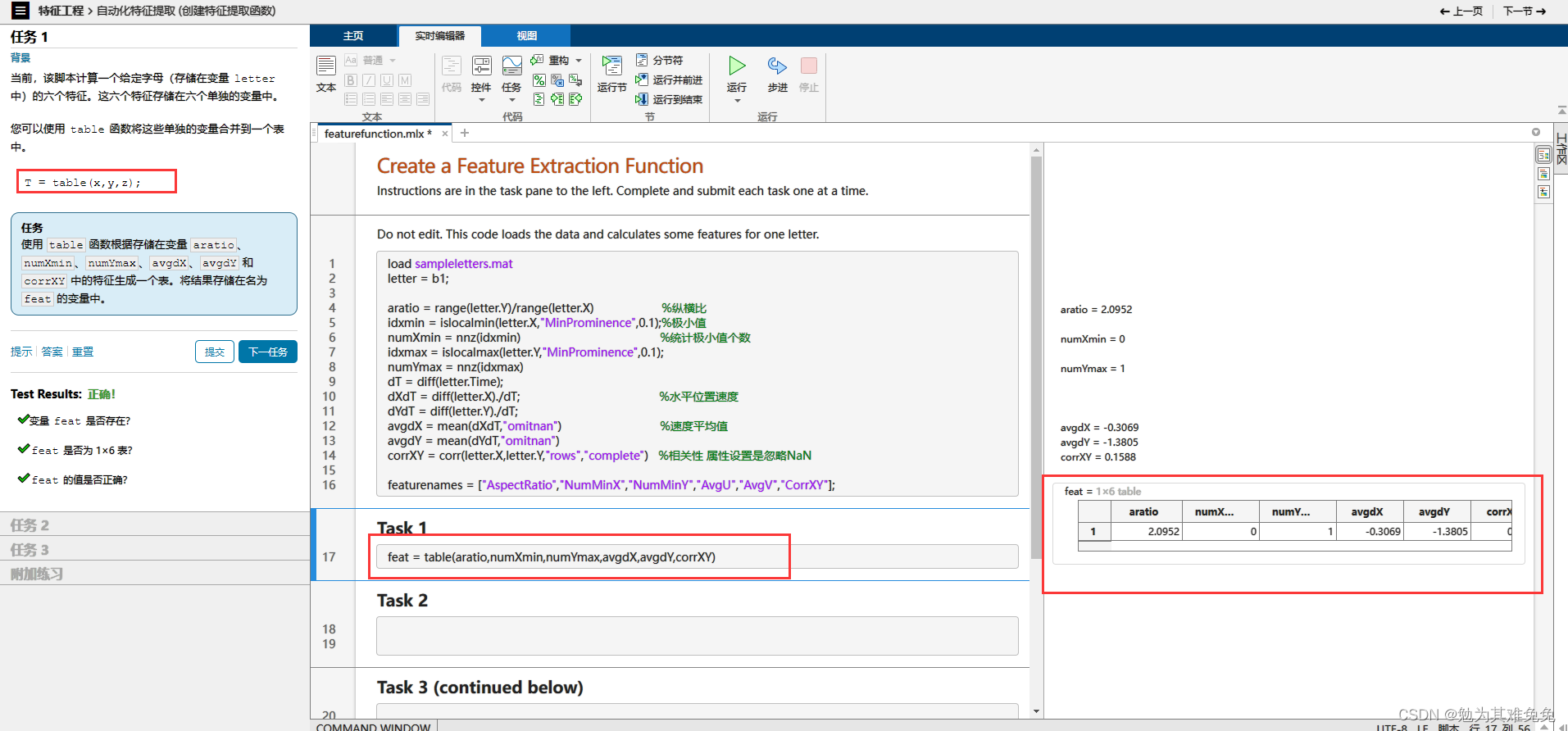
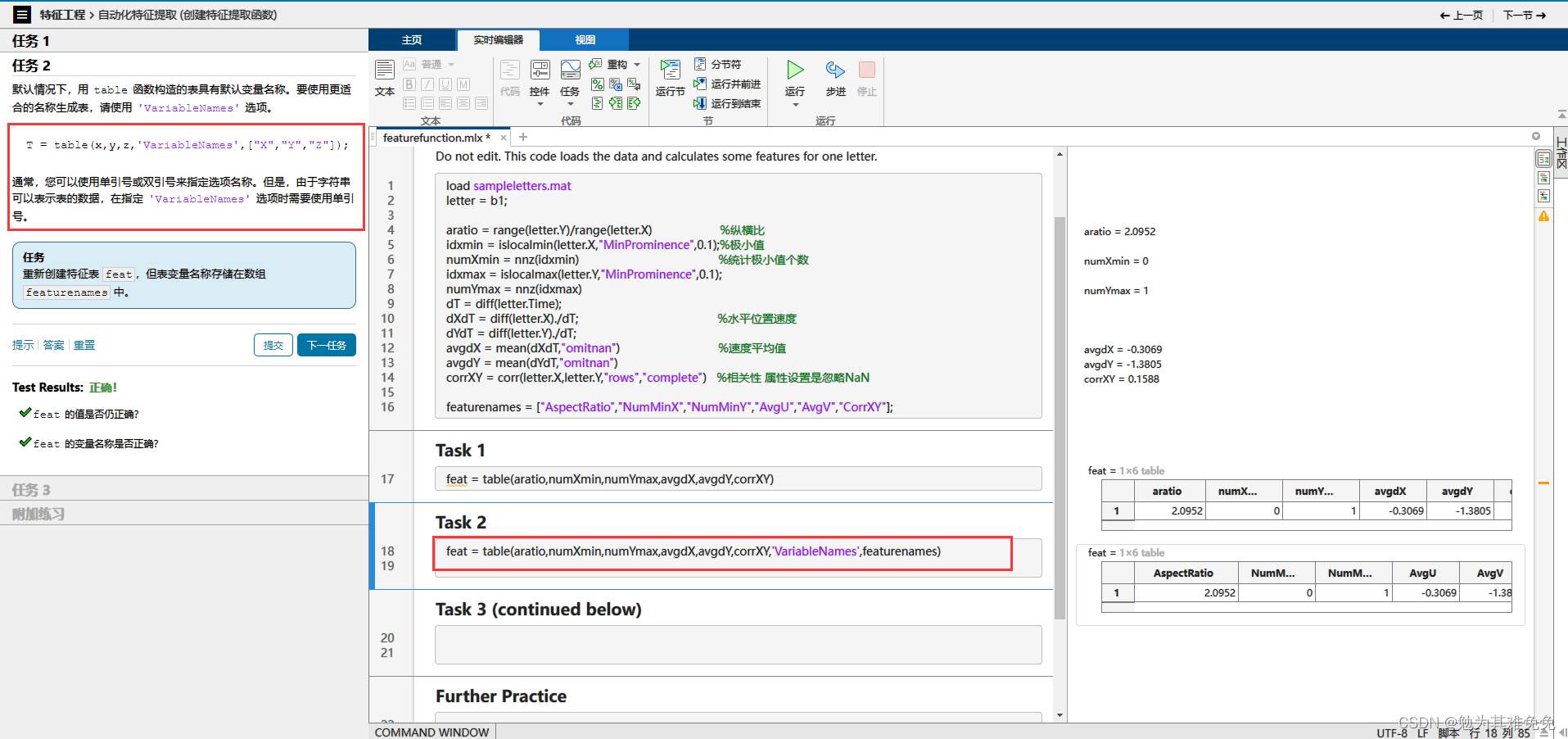
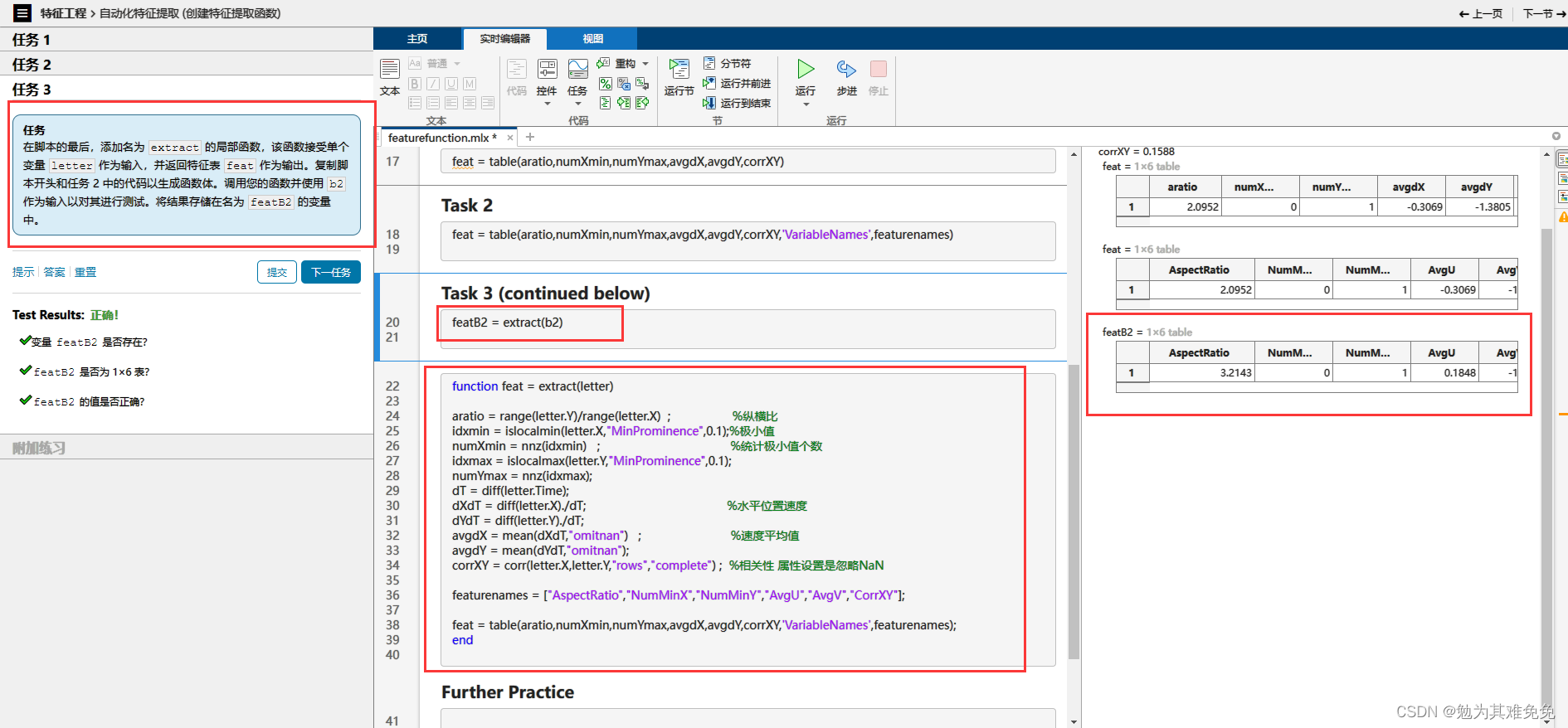
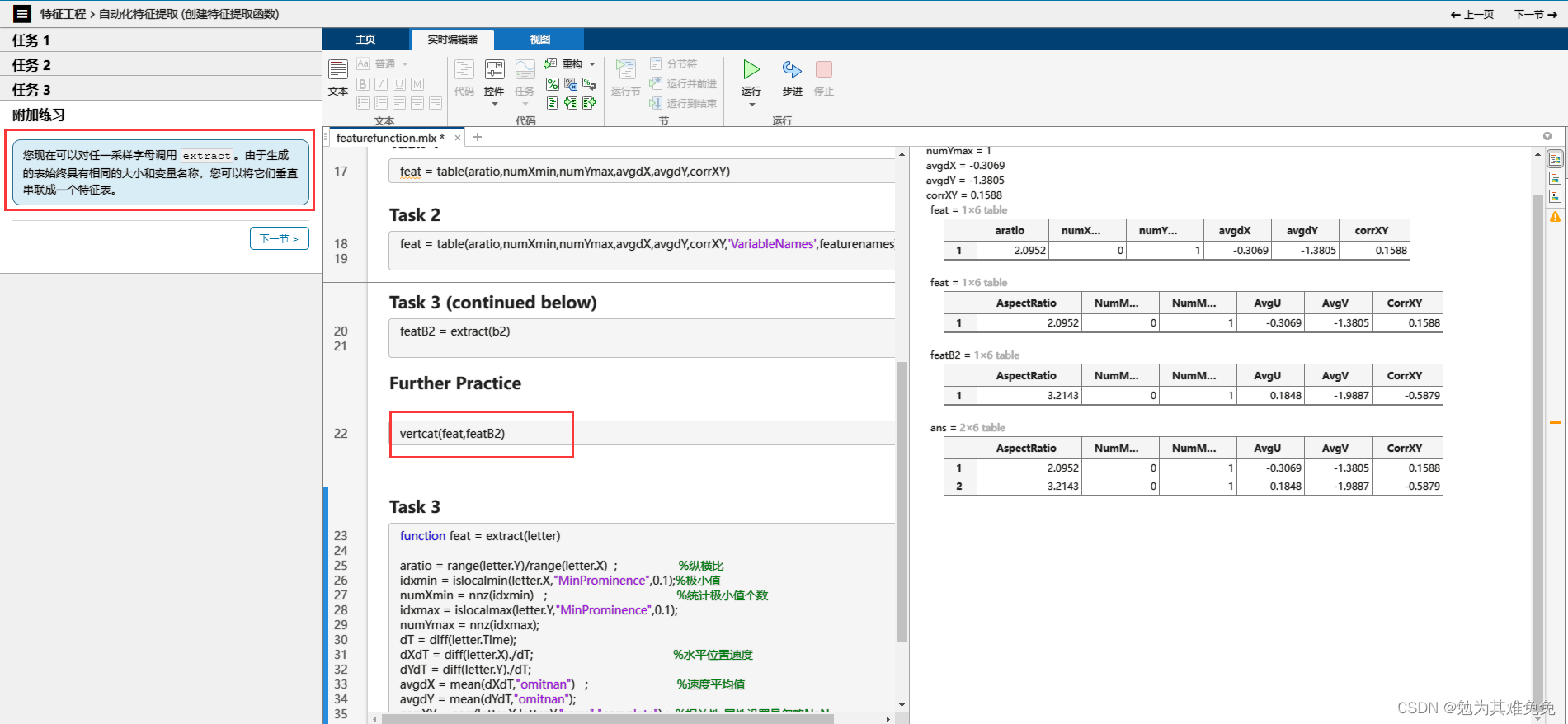
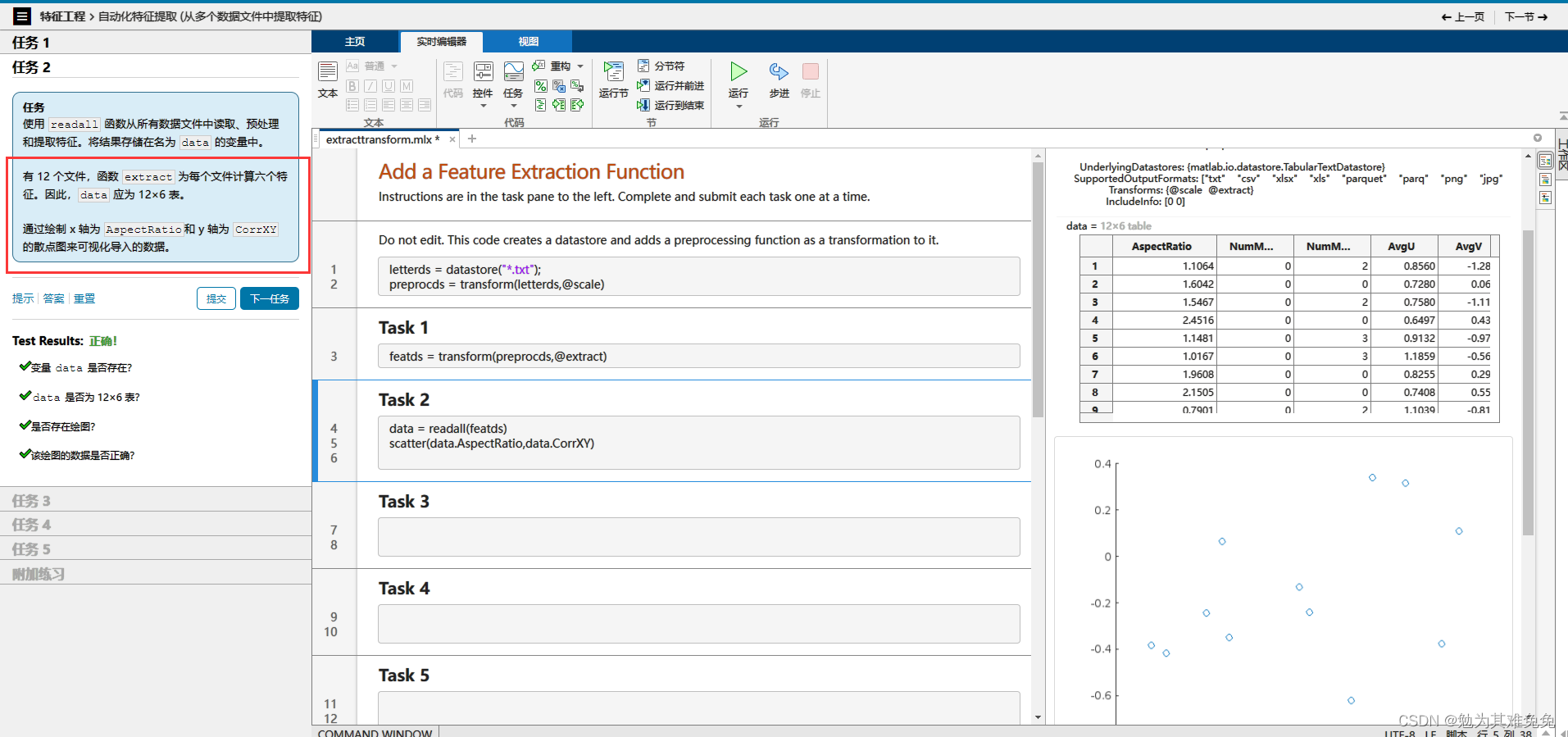
从多个数据文件中提取特征
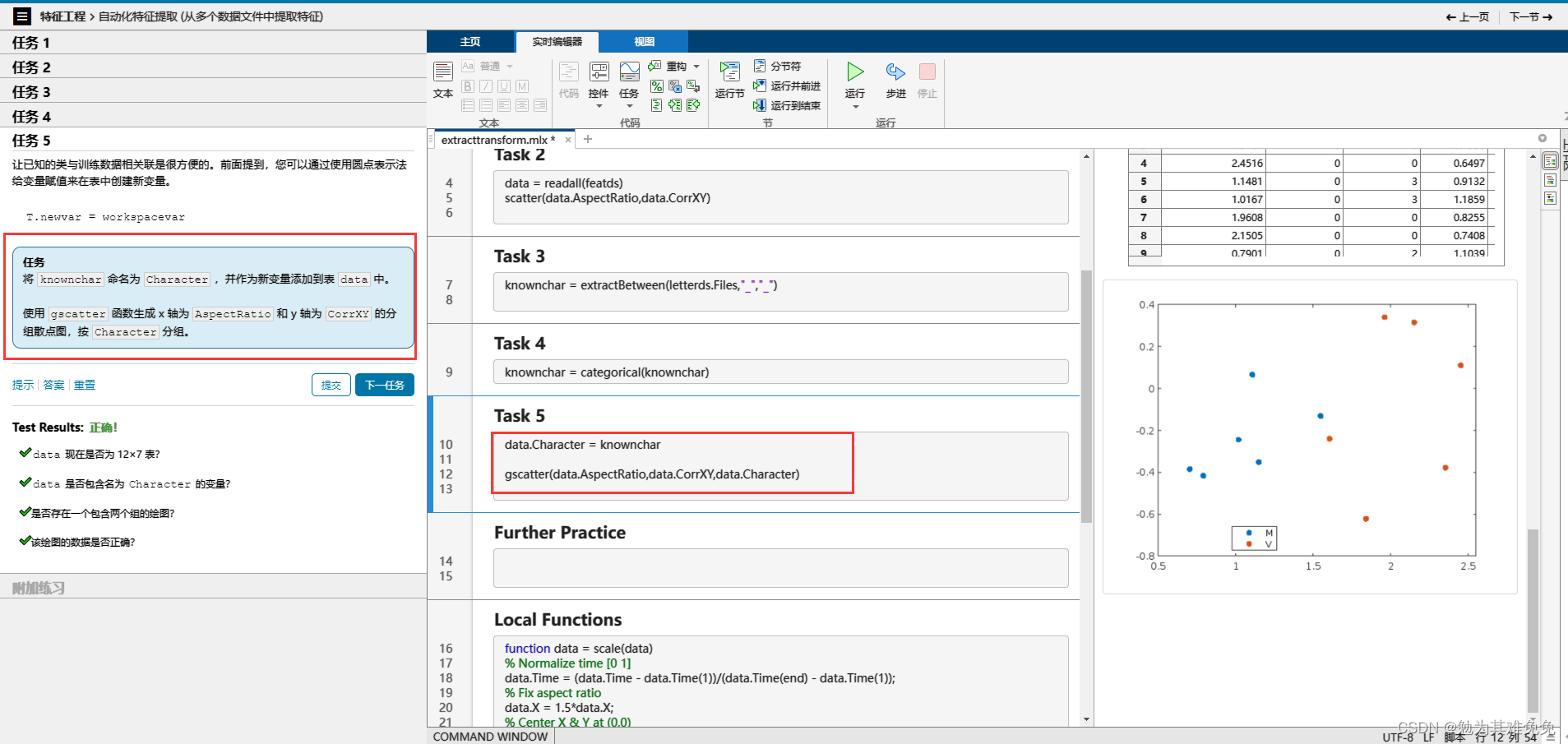
分类模型
训练和预测数据
这些数据包含两个预测变量和两个输出类,你如何为这些数据建立分类模型?

你可能自然地想到一个非常简单的模型
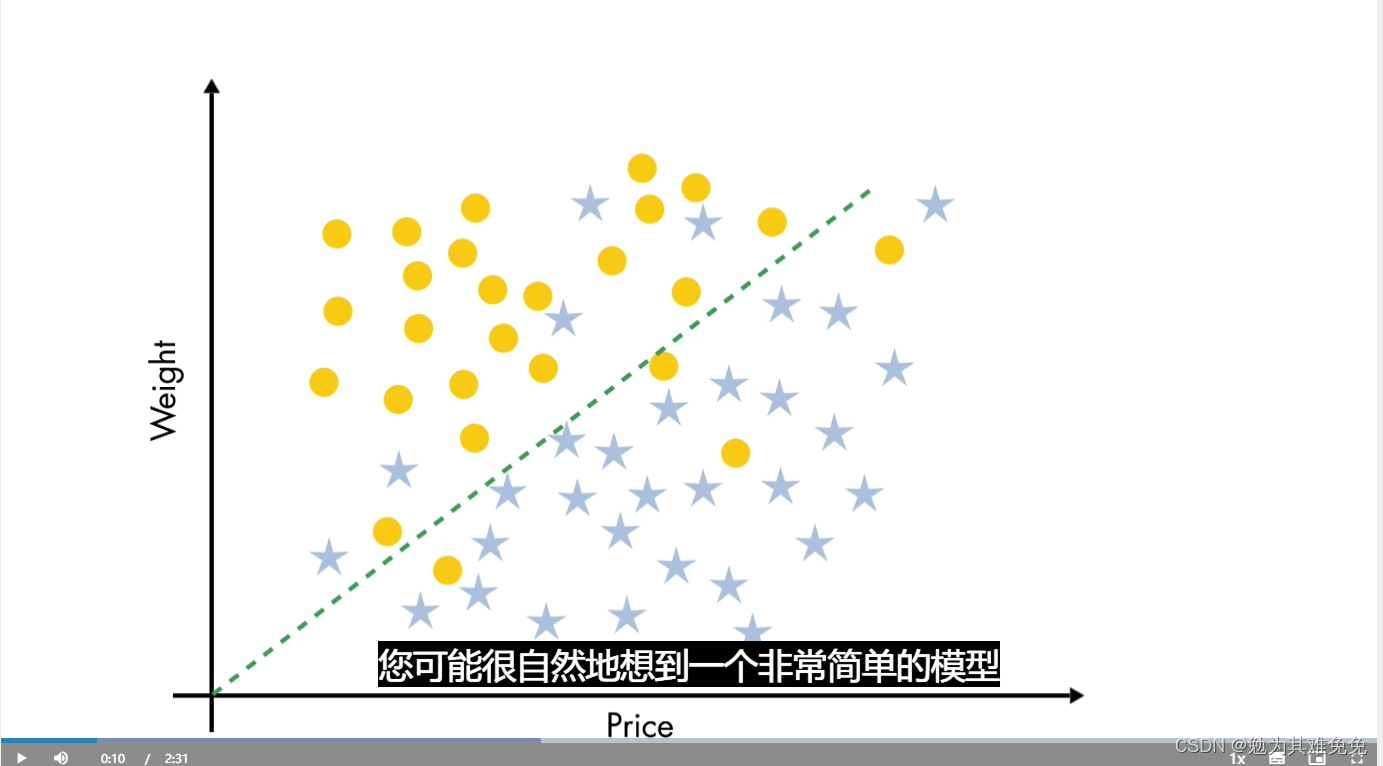
如果价格大于重量,则用五角星表示,否则用圆表示
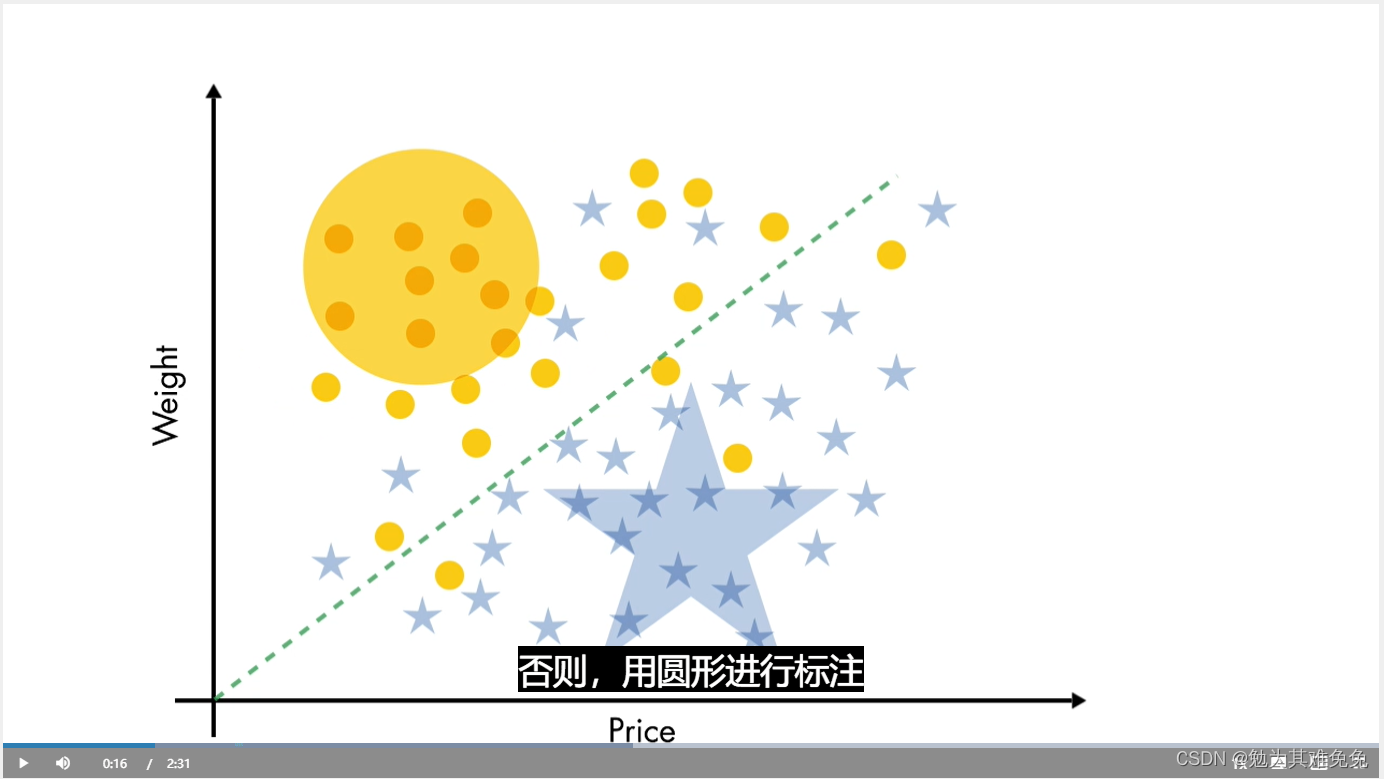
还有另外一种模型,这个模型有点复杂

如果按照他们基于训练数据的准确度打分,第二个模型更好,分类非常完美。第一个模型的分类有些是错误的。但是第二个模型似乎太复杂了,它尝试捕获数据的每个细节,连噪声也不放过。而第一个模型只关注总体趋势,入伙你尝试基于新数据,使用这些模型,可能会发现简单模型的性能不错,复杂模型的性能则一般,或者按照准确度打分时表现得那么好。这是机器学习的一个常见问题,称为过拟合。也就是一个模型,在其训练数据上性能非常好,但无法很好地泛化到新观测值。
如果你使用一些已知正确结果的新数据来预测模型,通常很容易观察到过拟合。但是,从哪里得到这些测试数据呢?通常你会使用已有的数据,而不是从外部获取更多数据,在训练模型之前,请将数据分成训练集和测试集。划分的方法有很多,但最简单的方法是随机选取部分观测值,留作测试集,其余观测值用于训练模型。
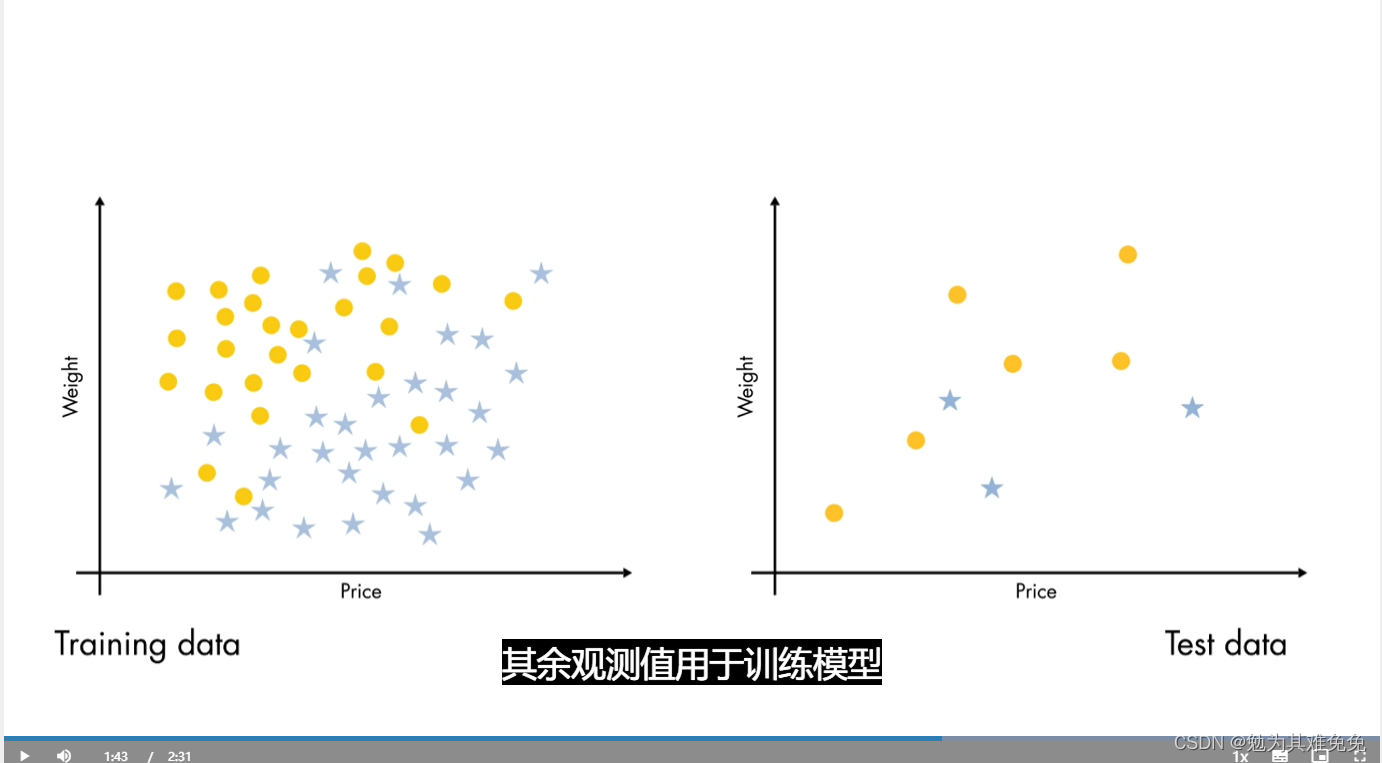
接下来,我们用示例进行尝试,如果我们用一个不同的观测值集训练简单模型,模型没有变化,它仍然有一些误分类,
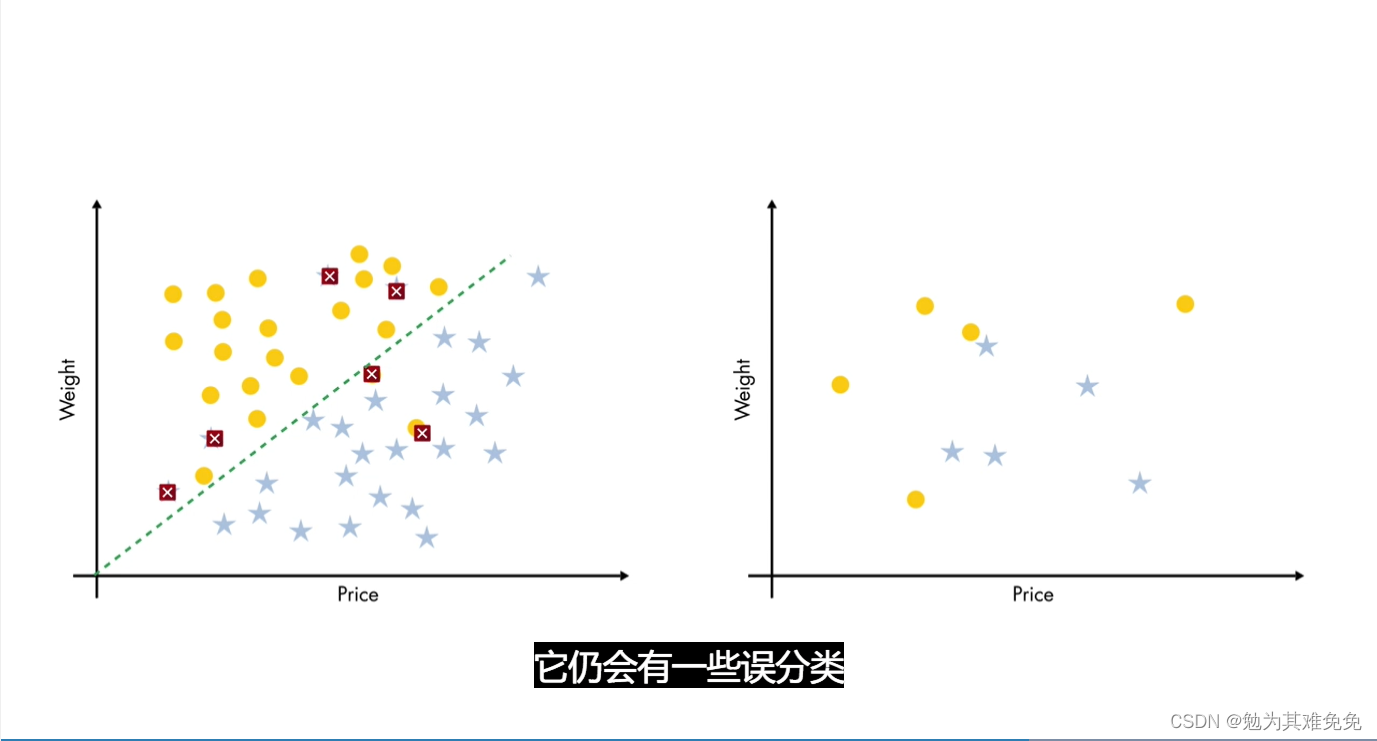
我们用于测试集上,他有个大致的趋势,这是个好现象。
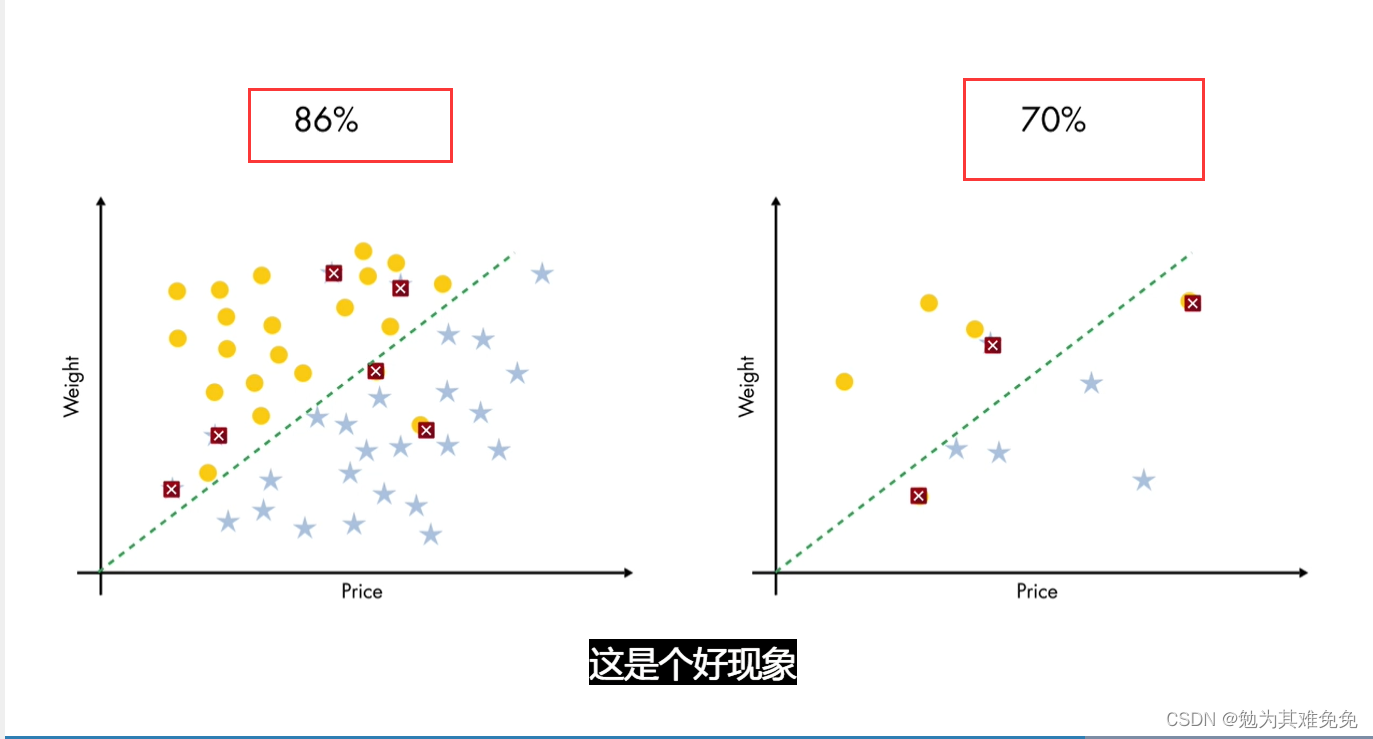
然而,复杂模型在很大程度上依赖用于训练的特定数据,我们对复杂模型进行测试,发现它的性能很差
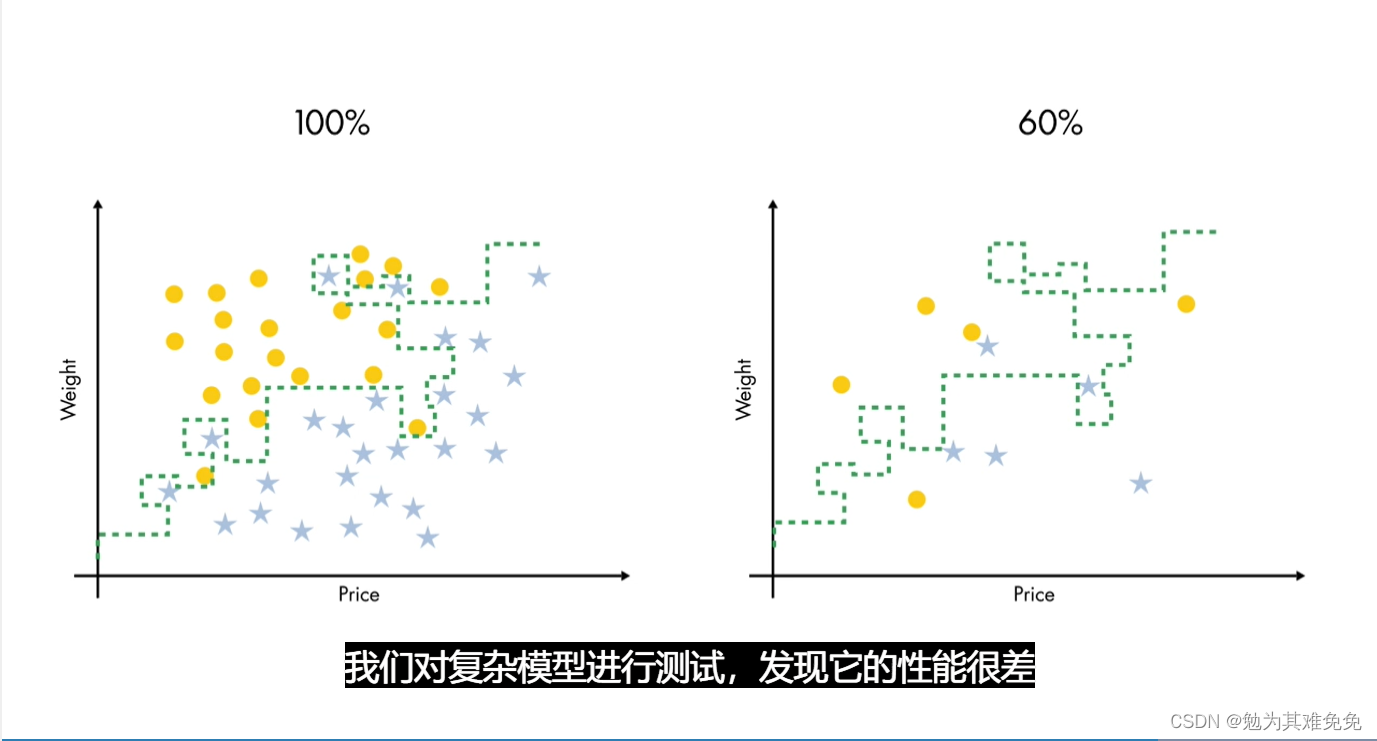
这就是过拟合,这与我们的直觉相符,即简单模型更好。因为它拟合数据的大体模式而不是细节。你应始终使用某种形式的验证,来查看你的模型对新数据的泛化程度,因为这是使用模型的最终目的。

机器学习模型
训练模型
执行预测
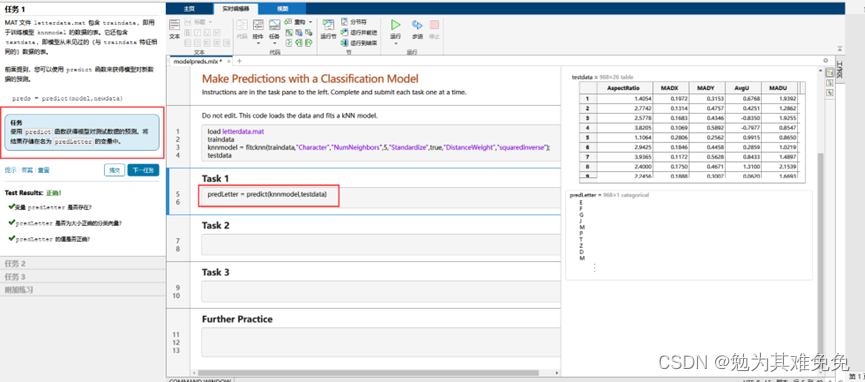
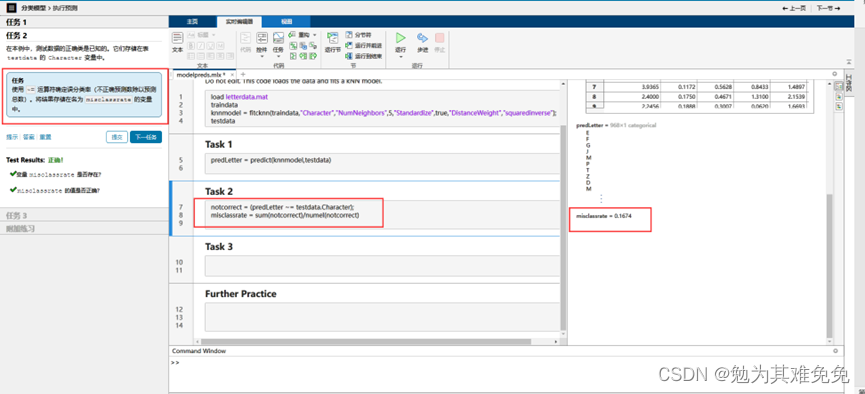
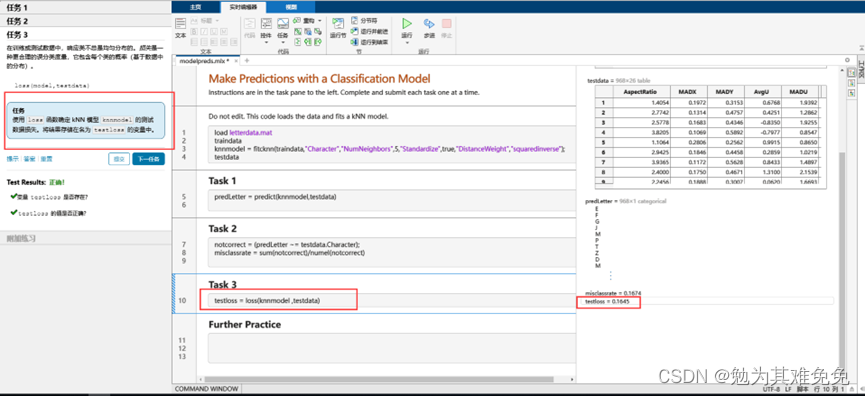

调查误分类
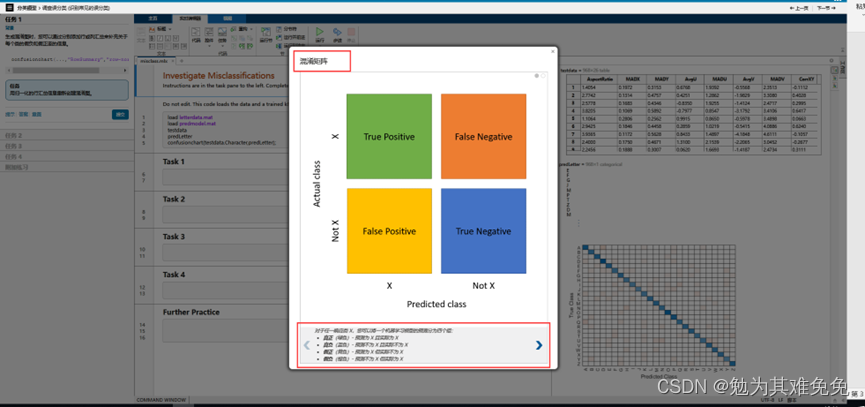

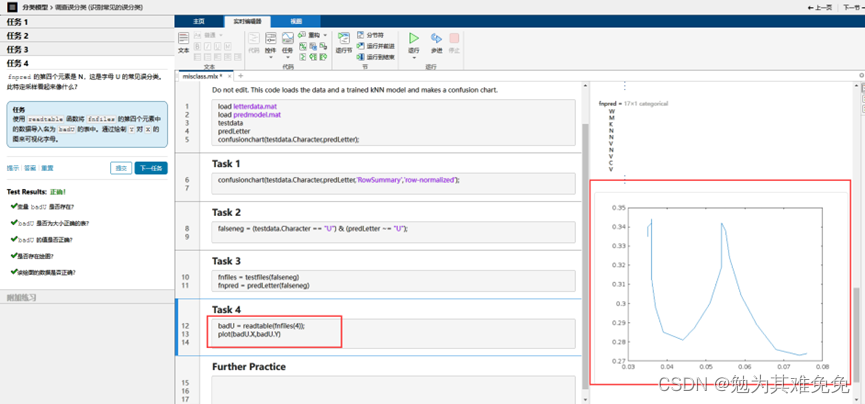
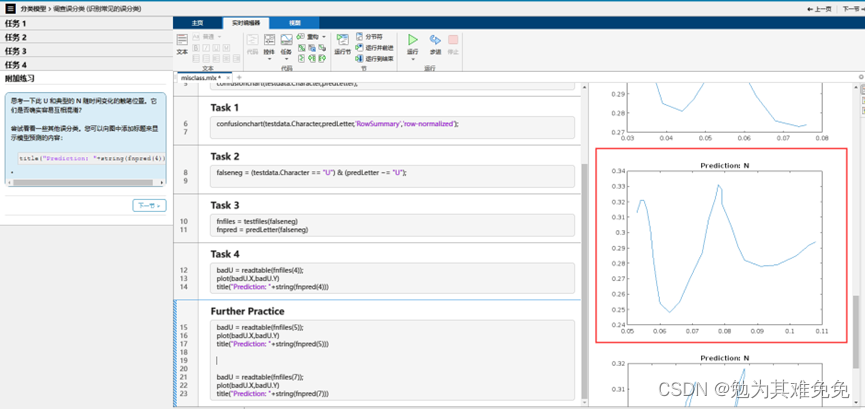
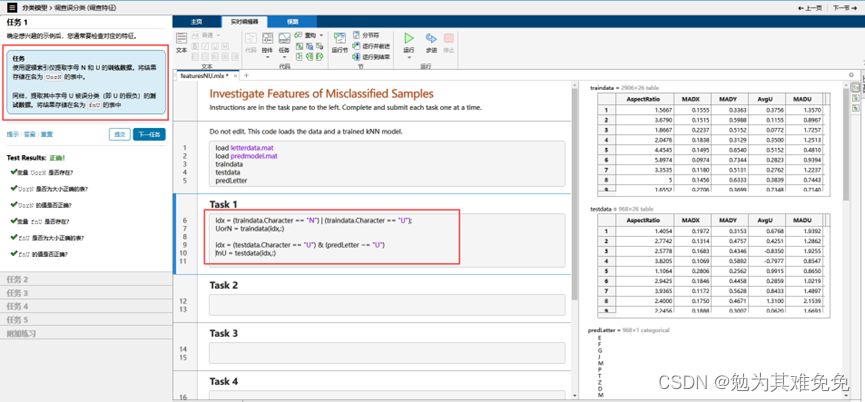
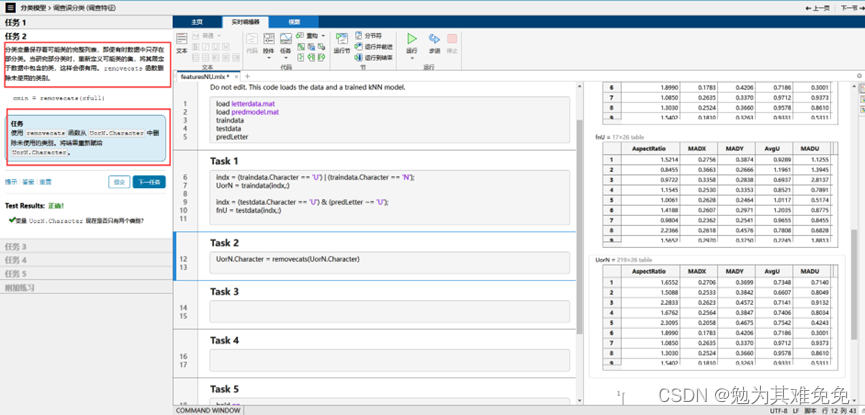
结论
刷完课有些许懵。主要是对手写字母进行分类。用的KNN模型,直接预测了。
我学会了啥,我学会了几个matlab内置函数
1、range 返回数组中的极差
2、gscatter 根据分组变量对点进行着色的散点图
3、fitcknn kNN模型
4、confusionchart 混淆矩阵
5、sum(逻辑值)/numel(逻辑值) 正确率或者错误率
6、datastore 创建数据存储 第一次使用read,将从你存储的第一个文件读取数据,以此类推 readall读所有
7、mean median mode(出现次数最多的数值)
8、islocalmin islocalmax
9、nnz函数 非零矩阵元素的数目
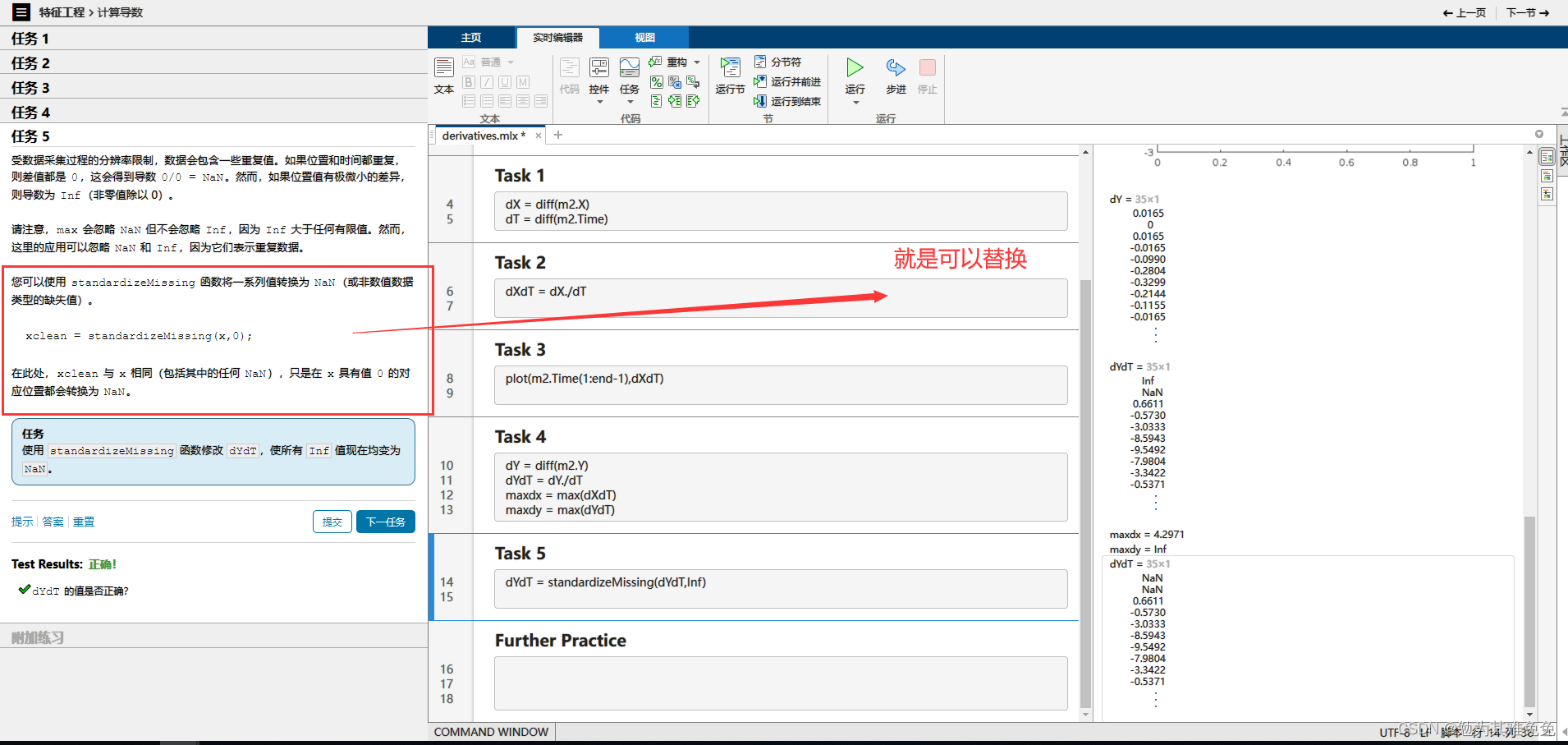
10、standardizeMissing(x,0)将x中0替换为NaN
max不会计算NaN,但是会计算Inf 可以把Inf替换为NaN
11、coor 计算相关性 如果有空值 查属性,可以不计算这个空值的
12、vertcat 拼接
13、transform函数
14、extractBetween函数 提取出现在给定本文中间的文本
15、mean(x,“omitnan”)忽略缺失值 median
仅仅记录学习,建议大家去mathworks看官方教程。















 2112
2112











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











